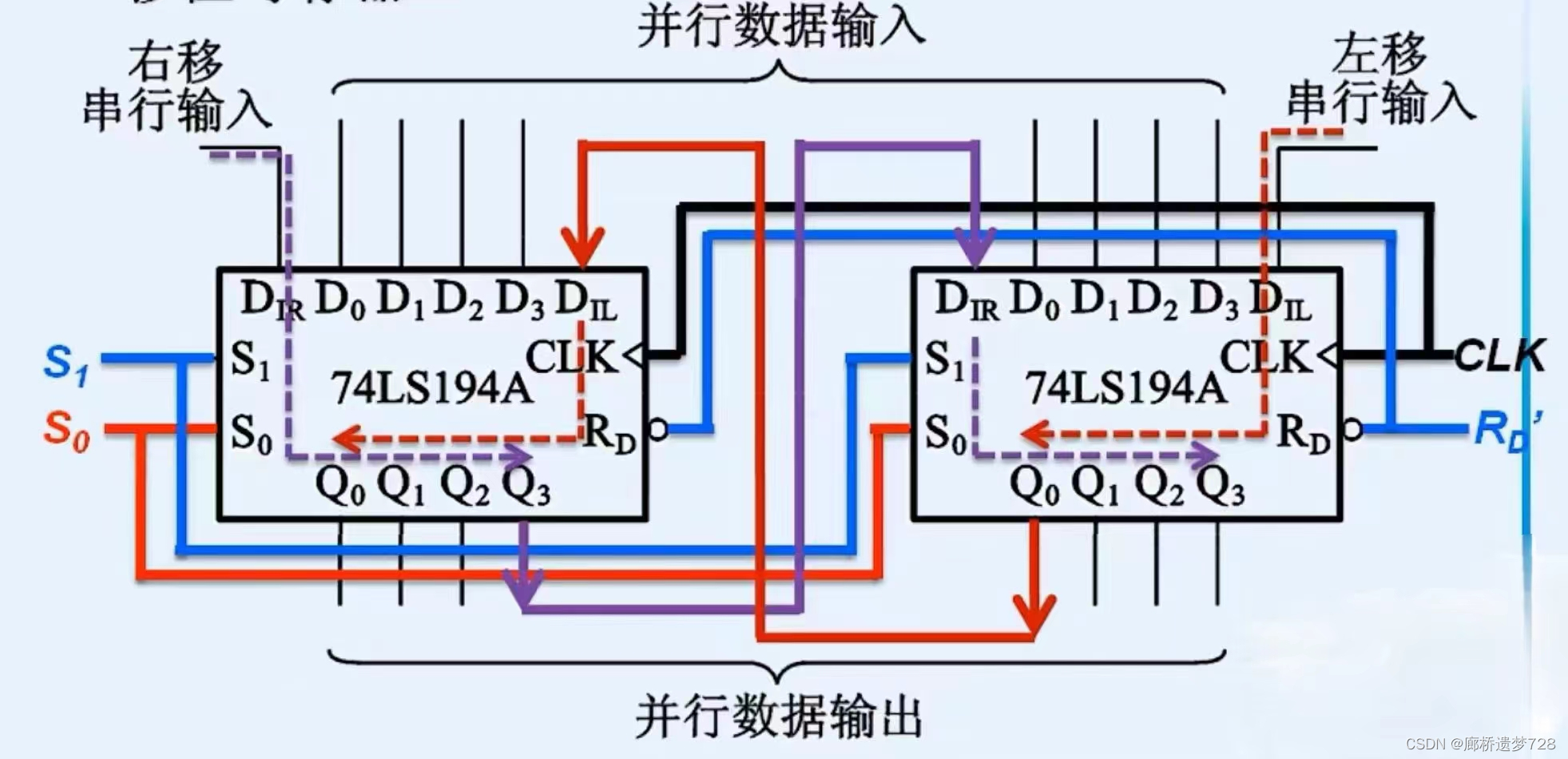
文章目录
- 前言
- 1. Druid 应用场景
- 2. IdentityHashMap 特性
- 3. IdentityHashMap 同步化
- 4. IdentityHashMap 处理key为空值
- 后记
前言
最近有兴趣看一下 Druid 连接池怎么做连接管理的,看到一个类 IdentityHashMap ,这里记录一下使用场景。
1. Druid 应用场景
- 定义
protected final Map<DruidPooledConnection, Object> activeConnections
= new IdentityHashMap<DruidPooledConnection, Object>();
- 最外层调用
if (url.startsWith("/activeConnectionStackTrace-") && url.endsWith(".json")) {
Integer id = StringUtils.subStringToInteger(url, "activeConnectionStackTrace-", ".");
// 内部从IdentityHashMap的容器中取值
return returnJSONActiveConnectionStackTrace(id);
}
- 用法概括
Druid 的特点就是做监控,每一个连接,也就是DruidPooledConnection都对应一个调用栈的详情。
这些连接的调用栈信息保存到IdentityHashMap<DruidPooledConnection, Object>
中,对外提供查询服务。
2. IdentityHashMap 特性
观察一下 IdentityHashMap 的 key的hash值,来自于该对象的应用地址。
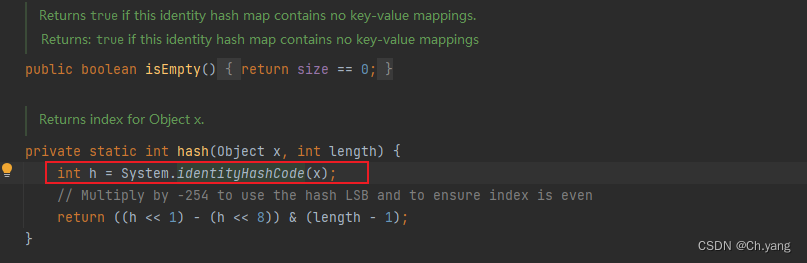
言下之意是:IdentityHashMap 的 key ,无论属性如何改变都不影响容器的寻址
Druid 就是用这个特性保留连接的堆栈记录
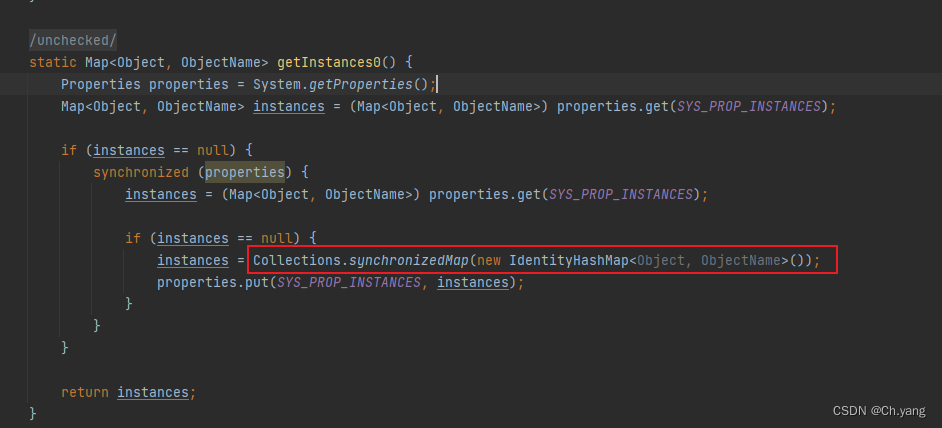
3. IdentityHashMap 同步化
Collections.synchronizedMap(new IdentityHashMap<Object, ObjectName>());
- Druid 内部线程安全的用法
- 外层使用
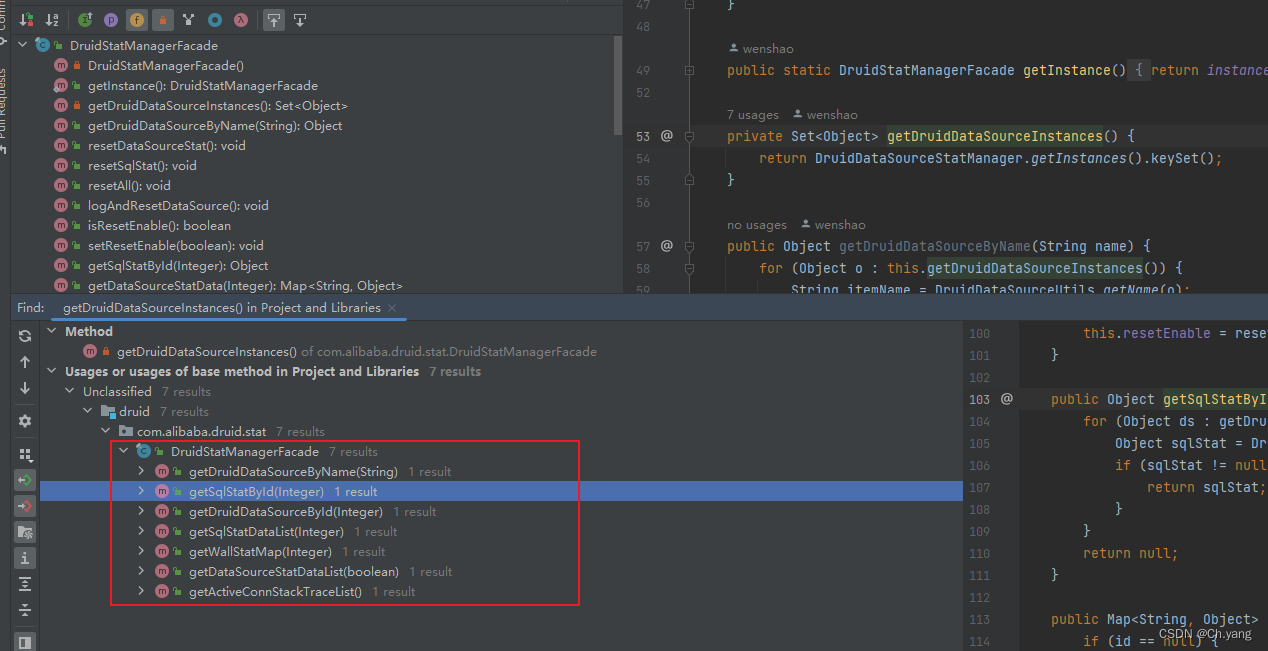
前文一直疑惑为什么把value泛型指定为 Object,这里倒是看懂了,这个容器有很多统计类型数据。感慨一下这个泛化的map也太多地方用了吧,业务代码这么写会被吐槽吧。
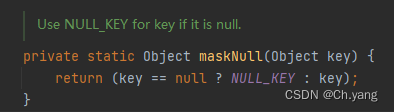
4. IdentityHashMap 处理key为空值
类比一下 HashMap,可以存储 null 的 key,是把 null 映射为 0

而 IdentityHashMap 将 null 映射为空对象

后记
如果有池化管理对象的需求(比如连接池),且考虑将对象作为某个容器的key,此时可以考虑使用 IdentityHashMap


![[图解]企业应用架构模式2024新译本讲解01-事务脚本](https://img-blog.csdnimg.cn/direct/57300217c7594ec984f76eaec7ba632a.png)





![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-24.1,2 SPI驱动实验-SPI协议介绍](https://img-blog.csdnimg.cn/direct/91371c8093dd458fa226b48400691891.png)