前言
机器学习作为人工智能领域的核心组成,是计算机程序学习数据经验以优化自身算法、并产生相应的“智能化的“建议与决策的过程。随着大数据和 AI 的发展,越来越多的场景需要 AI 手段解决现实世界中的真实问题,并产生我们所需要的价值。
机器学习的建模流程包括明确业务问题、收集及输入数据、模型训练、模型评估、模型决策一系列过程。对于机器学习工程师而言,他们更擅长的是算法、模型、数据探索的工作,而对于工程化的能力则并不是其擅长的工作。除此之外,机器学习过程中还普遍着存在的 IDE 本地维护成本高、工程部署复杂、无法线上协同等问题,导致建模成本高且效率低下。
概述
Jupyter Notebook介绍:
Jupyter Notebook是一个开源的交互式笔记本,支持超过40种编程语言,能够同时包含实时代码、可视化输出和富文本。它非常适合用于数据分析、机器学习建模、科学研究和教育等领域。除了用于交互式数据分析和编程外,Jupyter Notebook还被广泛应用于数据清洗、数据可视化、机器学习模型的训练和部署,甚至作为教学工具。它的灵活性和强大的功能使得它成为了数据科学家、研究人员和工程师们不可或缺的利器。
R Notebook介绍:
R Notebook是基于R语言的交互式笔记本环境,结合了代码、可视化和文档编写的功能。它能够帮助数据科学家和分析师们在同一个环境中进行数据处理、统计建模、可视化和报告撰写等任务。R Notebook提供了交互式的编程环境,用户可以实时执行R代码,并即时看到结果、生成图表。
PySpark Notebook介绍:
PySpark Notebook是一个基于Python语言和Spark框架的交互式笔记本环境。它结合了Python的简洁性和Spark的强大分布式计算能力,使得用户可以在同一个环境中进行大规模数据处理和分析。PySpark Notebook提供了交互式编程环境,用户可以使用Python编写代码,通过Spark进行分布式数据处理、机器学习和图计算等任务。同时,它还支持可视化和文档编写,方便用户进行数据可视化和报告撰写。通过PySpark Notebook,用户可以轻松处理大数据集,实现高性能的分布式数据处理和分析。
C/C++ Notebook介绍:
C/C++ Notebook是一款专为学习和编写C语言程序设计的笔记工具。它集成了代码编辑、笔记记录和即时运行等功能,使用户能够在编写和调试代码的同时记录学习心得和重要知识点。适合初学者和有经验的程序员,用于学习、教学和项目开发。通过C Notebook,用户可以高效地进行代码编写和学习笔记的同步管理。
特征图

示例
接下来展示不同方式实现的Jupyter Notebook代码示例!
Jupyter Notebook读取文件
import subprocessimport pandas as pdres_list = subprocess.Popen(['ls', '/datasource/testErfenlei'],shell=False,stdout=subprocess.PIPE,stderr=subprocess.PIPE).communicate()for res in res_list:print(res.decode())filenames = res.decode().split() # 将输出结果按空格分割成文件名列表for filename in filenames:if filename == 'erfenl.csv': # 根据实际文件名来判断csv_data = pd.read_csv('/datasource/testErfenlei/' + filename) # 读取CSV文件print(csv_data)

Jupyter Notebook建模-双曲线图

Jupyter Notebook生成PMML文件1
from sklearn.datasets import load_irisfrom sklearn.tree import DecisionTreeClassifierfrom sklearn2pmml import PMMLPipeline, sklearn2pmml# 加载iris数据集iris = load_iris()# 训练决策树模型dt = DecisionTreeClassifier()dt.fit(iris.data, iris.target)# 创建PMMLPipeline对象pmml_pipeline = PMMLPipeline([("classifier", dt)])# 导出模型为PMML文件sklearn2pmml(pmml_pipeline, "iris_decision_tree.pmml")
Jupyter Notebook生成PMML文件2
from sklearn.datasets import load_bostonfrom sklearn.linear_model import LinearRegressionfrom sklearn2pmml import PMMLPipeline, sklearn2pmml# 加载波士顿房价数据集boston = load_boston()# 构建线性回归模型lr = LinearRegression()# 使用 PMMLPipeline 包装模型pipeline = PMMLPipeline([("lr", lr)])# 使用数据拟合模型pipeline.fit(boston.data, boston.target)# 将模型保存为 PMML 文件sklearn2pmml(pipeline, "linear_regression.pmml")
R Notebook建模 - 散点图
# 导入所需的库library(ggplot2)# 创建一个数据框df <- data.frame(x = 1:10,y = c(3, 5, 6, 8, 9, 10, 11, 13, 14, 15))# 绘制散点图ggplot(df, aes(x, y)) +geom_point() +labs(title="Scatter Plot of X and Y", x="X", y="Y")
R Notebook获取训练数据集
setwd(dir=”/datasource”)dir()
PySpark Notebook建模
# 导入所需库from pyspark.sql import SparkSessionfrom pyspark.ml.feature import VectorAssemblerfrom pyspark.ml.regression import LinearRegressionfrom pyspark.ml.evaluation import RegressionEvaluator# 创建 SparkSessionspark = SparkSession.builder.appName("LinearRegression").getOrCreate()# 创建 DataFramedata = [(1.2, 3.4, 5.6), (2.3, 4.5, 6.7), (3.4, 5.6, 7.8), (4.5, 6.7, 8.9)]columns = ["feature1", "feature2", "label"]df = spark.createDataFrame(data, columns)# 将特征列组合到向量中assembler = VectorAssembler(inputCols=["feature1", "feature2"], outputCol="features")df = assembler.transform(df)# 拆分数据集为训练集和测试集train_df, test_df = df.randomSplit([0.7, 0.3], seed=42)# 创建线性回归模型并拟合训练集lr = LinearRegression(featuresCol="features", labelCol="label")model = lr.fit(train_df)# 在测试集上进行预测并计算其平均误差predictions = model.transform(test_df)# mse = predictions.agg({"prediction": "mean_squared_error"}).collect()[0][0]# mse = predictions.agg(mean_squared_error(predictions["label"], predictions["prediction"])).collect()[0][0]evaluator = RegressionEvaluator(predictionCol="prediction", labelCol="label", metricName="mse")mse = evaluator.evaluate(predictions)# 显示结果print(f"Mean Squared Error on Test Set: {mse}")# 停止 SparkSessionspark.stop()

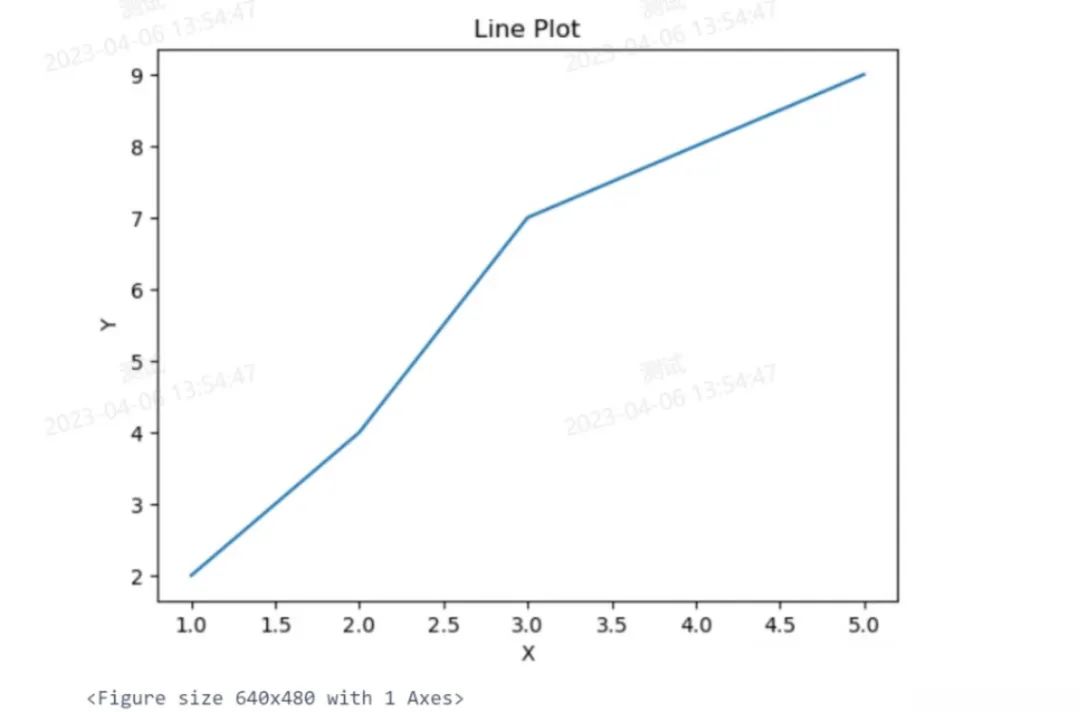
PySpark Notebook建模 -折线图
# 导入所需库和模块import matplotlib.pyplot as pltfrom pyspark.sql.functions import colfrom pyspark.sql import SparkSession# 创建 SparkSessionspark = SparkSession.builder.appName("LinePlot").getOrCreate()# 创建 DataFramedata = [(1, 2), (2, 4), (3, 7), (4, 8), (5, 9)]columns = ["x", "y"]df = spark.createDataFrame(data, columns)# 提取 x 和 y 列并将其转换为 Pandas 数据框pandas_df = df.select("x", "y").orderBy("x").toPandas()# 绘制折线图plt.plot(pandas_df["x"], pandas_df["y"])# 添加标题和轴标签plt.title("Line Plot")plt.xlabel("X")plt.ylabel("Y")# 显示图形plt.show()# 停止 SparkSessionspark.stop()
C语言Notebook 建模
#include <stdio.h>int main() {int arr[] = {3, 7, 1, 9, 5};int size = sizeof(arr) / sizeof(arr[0]);// 找到最大值,以便缩放柱状图int max_value = arr[0];for (int i = 1; i < size; i++) {if (arr[i] > max_value) {max_value = arr[i];}}// 打印柱状图printf("Bar chart:\n");for (int i = max_value; i > 0; i--) {for (int j = 0; j < size; j++) {if (arr[j] >= i) {printf("* ");} else {printf(" ");}}printf("\n");}// 打印横轴标签for (int i = 0; i < size; i++) {printf("%d ", arr[i]);}printf("\n");return 0;}

C++Notebook 建模
#include <iostream>using namespace std;int f1(){std::cout <<"hello world1\n";return 1;}int a = 110;cout << f1() << endl;cout <<1010<<endl;
PytorchNotebook建模
import torchimport torch.nn as nnimport torch.optim as optim# 定义一个简单的神经网络模型class SimpleNet(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(SimpleNet, self).__init__()self.fc1 = nn.Linear(input_size, hidden_size)self.relu = nn.ReLU()self.fc2 = nn.Linear(hidden_size, output_size)def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 准备数据input_size = 10hidden_size = 20output_size = 5batch_size = 32input_data = torch.randn(batch_size, input_size)target_data = torch.randn(batch_size, output_size)# 实例化模型model = SimpleNet(input_size, hidden_size, output_size)# 定义损失函数和优化器criterion = nn.MSELoss()optimizer = optim.SGD(model.parameters(), lr=0.1)# 训练模型num_epochs = 100for epoch in range(num_epochs):# 前向传播output = model(input_data)loss = criterion(output, target_data)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()# 打印训练信息if (epoch+1) % 10 == 0:print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item()))

TensorFlowNotebook建模
import tensorflow as tf# 检查是否有可用的GPU设备if tf.test.is_gpu_available():print('GPU 设备可用')else:print('GPU 设备不可用')# 创建一个简单的神经网络模型model = tf.keras.models.Sequential([tf.keras.layers.Dense(64, activation='relu', input_shape=(784,)),tf.keras.layers.Dense(64, activation='relu'),tf.keras.layers.Dense(10, activation='softmax')])# 准备数据(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()# 数据预处理x_train = x_train.reshape(-1, 784).astype('float32') / 255.0x_test = x_test.reshape(-1, 784).astype('float32') / 255.0y_train = tf.keras.utils.to_categorical(y_train, num_classes=10)y_test = tf.keras.utils.to_categorical(y_test, num_classes=10)# 编译模型model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])# 在GPU上训练模型with tf.device('/GPU:0'):model.fit(x_train, y_train, batch_size=128, epochs=10, validation_split=0.2)# 在GPU上评估模型with tf.device('/GPU:0'):test_loss, test_acc = model.evaluate(x_test, y_test)print('Test accuracy:', test_acc)

总结
在这个数据驱动的时代,机器学习已经成为了帮助我们解决复杂问题和实现智能化决策的关键工具。而本指南中的Jupyter Notebook实战将带你踏上一段精彩而充满挑战的旅程。通过深入学习和实践,你将掌握从数据清理、特征提取到模型训练和评估的全套流程。不仅如此,Jupyter Notebook作为交互式开发环境,将激发你的创造力和探索精神,让你能够灵活地调试和优化模型。
无论你是初学者还是已经有一定经验的专业人士,这个指南都将帮助你提升技能、拓宽视野,并在机器学习领域迈出坚实的步伐。现在就加入我们,一起探索机器学习的无限可能吧!