一、K8s FileBeat + ELK 介绍
ELK,即Elasticsearch、Logstash和Kibana三个开源软件的组合,是由Elastic公司提供的一套完整的日志管理解决方案。Elasticsearch是一个高度可扩展的开源全文搜索和分析引擎,它允许你快速地、近乎实时地存储、搜索和分析大量数据。Logstash是一个服务器端数据处理管道,它能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如Elasticsearch等存储库中。Kibana则允许你通过Elasticsearch使用图表和表格直观地展示数据。
ELK主要解决了如何有效地收集、处理、存储和可视化大量的日志数据。优势在于它能够处理和分析大量的日志数据,提供实时的搜索和分析能力,同时它的分布式设计使其具有很高的扩展性。但劣势在于它的配置和维护相对复杂,特别是Logstash,需要编写复杂的配置文件,对系统资源的要求也相对较高。
然而,直接使用ELK栈在数据收集方面可能存在一些问题。例如,Logstash是一个重量级的工具,它在数据收集过程中可能会消耗大量的系统资源,这对于资源有限的环境来说可能是一个问题。此外,Logstash的配置也相对复杂,需要编写大量的配置文件,这对于一些简单的日志收集任务来说可能显得过于繁琐。
为了解决这些问题,Elastic公司推出了Filebeat。Filebeat是一个轻量级的日志传输工具,它可以安装在需要收集日志的服务器上,实时读取日志文件,并将这些日志数据发送到指定的输出,如Logstash、Elasticsearch、kafka。它的优势在于轻量级设计,对系统资源的消耗极低,同时它的配置也相对简单,易于管理和维护。通过接入Filebeat,可以有效地解决Logstash在数据收集方面的问题,提高整个ELK栈的性能和稳定性。
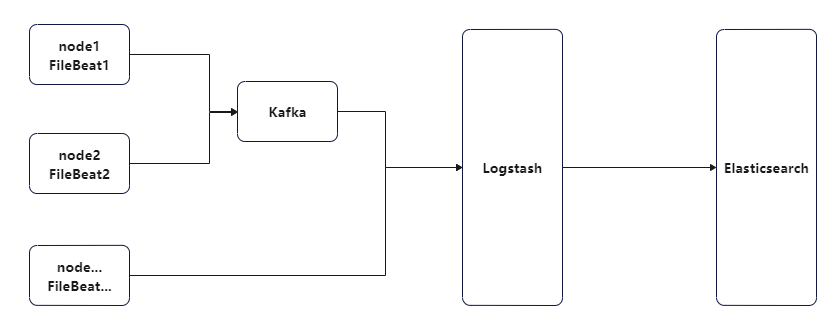
K8s 环境中的 ELK
随着 k8s 的越来越普及化,很多应用都被部署在了 k8s 中,如何在 k8s 中进行 ELK 日志管理呢?首先要搞清楚 k8s 中的日志都存在了哪里,可以主要从下面三个目录入手:
-
/var/lib/docker/containers/ :是
Docker守护进程用于存储容器元数据和日志数据的地方。每个容器的日志文件通常以<container_ID>-json.log的形式存储在这个目录下的相应子目录中。这些日志文件包含了容器的stdout和stderr输出,并且是以JSON格式存储的。Filebeat可以直接读取这些文件来收集容器的日志。 -
/var/log/containers/ :是
k8s为了便于日志管理而创建的符号链接(symlink)目录。它包含了到/var/lib/docker/containers/目录中日志文件的链接。每个符号链接的名称通常是由Pod名称、容器名称和实例编号组成的。Filebeat可以通过这个目录轻松地访问和收集容器的日志,而不需要直接访问Docker的内部目录。 -
/var/log/pods/ :是
K8s用于存储Pod日志的地方。每个Pod都会在这个目录下有一个以Pod UID命名的子目录,Pod内的每个容器又有各自以容器名称命名的日志文件。这些日志文件包含了容器的stdout和stderr输出,但是它们是以文本格式而不是JSON格式存储的。这个目录的结构有助于保持Pod和容器日志的隔离性,便于管理和访问。
因此我们可以主要从 /var/log/containers/ 目录入手,Filebeat 以 DaemonSet的方式部署在k8s集群中。DaemonSet可以确保每个节点上都有一个Filebeat实例在运行,通过读取宿主机上的日志文件来收集k8s的日志。
在 Filebeat 中已经内置了 k8s 的支持,我们可以通过配置 processors.add_kubernetes_metadata 来增强日志数据,将Kubernetes的元数据添加到日志事件中,比如Pod名称、Namespace、容器名称等:
processors:
- add_kubernetes_metadata:
default_indexers.enabled: true
default_matchers.enabled: true
matchers:
- logs_path:
logs_path: "/var/log/containers/"
当数据发送给到 logstash 时,直接可以通过 [kubernetes][namespace] 或 [kubernetes][container][name] 获取到 k8s 中的元数据信息,因此可以利用 logstash 动态创建不同应用的动态日志索引,针对每个命名空间下不同的应用创建单独的索引记录日志,这样更便于后期对日志的排查。例如 logstash.conf 可以这样配置:
output {
if [kubernetes][namespace] and [kubernetes][container][name] {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "k8s-%{[kubernetes][namespace]}-%{[kubernetes][container][name]}-%{+YYYY.MM.dd}"
}
} else {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "k8s-%{+YYYY.MM.dd}"
}
}
}
下面开始实践在 k8s 中部署 FileBeat+ELK 分布式日志系统,实验采用版本均为 7.14.0 。
创建命名空间
这里首先创建一个命名空间,后续所有操作均在该空间下:
kubectl create ns elk
创建测试服务
在开始前这里创建一个 SpringBoot 项目,项目名称为 elk-demo ,用来打印不同级别的日志,用来验证是否能被收集,以及收集的索引是否动态创建。
创建测试接口:
@Slf4j
@RestController
public class TestController {
@GetMapping("/t1")
public void t1() {
log.info("this is test, level: info");
log.warn("this is test, level: warn");
log.debug("this is test, level: debug");
log.error("this is test, level: err", new RuntimeException("Err detail!"));
}
}
编写 Dockerfile 文件:
FROM java:8
MAINTAINER bxc
WORKDIR /app
ENV TZ=Asia/Shanghai
ADD target/elk-demo-0.0.1-SNAPSHOT.jar /app/app.jar
CMD ["java", "-jar", "app.jar"]
构建镜像并上传至私服 harbor 中,如果没有 harbor 仓库也可以将镜像上传至每个 k8s node 节点中,然后使用 docker load 到本地镜像仓库中。
# 打包成 jar 包
mvn clean package
# 构建镜像
cd elk-demo
docker build -t elk-demo:1.0 .
# 上传至 harbor
docker tag elk-demo:1.0 11.0.1.150/image/elk-demo:1.0 .
docker push 11.0.1.150/image/elk-demo:1.0
k8s 部署测试服务
vi elk-demo.yml
apiVersion: v1
kind: Service
metadata:
name: elk-demo
namespace: elk
labels:
app: elk-demo
spec:
type: NodePort
ports:
- port: 8080
name: client
nodePort: 31880
targetPort: 8080
selector:
app: elk-demo
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: elk-demo
namespace: elk
spec:
replicas: 3
selector:
matchLabels:
app: elk-demo
template:
metadata:
labels:
app: elk-demo
spec:
containers:
- name: elk-demo
image: elk-demo:1.0
ports:
- containerPort: 8080
name: server
env:
- name: TZ
value: Asia/Shanghai
kubectl apply -f elk-demo.yml
二、K8s 部署 FileBeat+ELK
2.1 部署 ES 集群和 Kibana
ES 集群和 kibana 的部署过程可以参考下面这篇文章:
K8s 部署 elasticsearch-7.14.0 集群 及 kibana 客户端
这里我 ES 的 Service 名称为 elasticsearch ,所以后面 ES 的访问地址可以写成 :http://elasticsearch:9200
2.2 部署 logstach
vi logstach.yml
apiVersion: v1
kind: Service
metadata:
name: logstash
namespace: elk
labels:
app: logstash
spec:
ports:
- port: 5044
name: logstash
targetPort: 5044
selector:
app: logstash
type: ClusterIP
---
apiVersion: v1
kind: ConfigMap
metadata:
name: logstash-conf
namespace: elk
data:
logstash.conf: |-
input {
beats {
port => 5044
}
}
filter {
grok {
match => { "message" => "(%{TIMESTAMP_ISO8601:logdatetime} %{LOGLEVEL:level} %{GREEDYDATA:logmessage})|%{GREEDYDATA:logmessage}" }
remove_field => [ "logmessage" ]
}
}
output {
if [kubernetes][namespace] and [kubernetes][container][name] {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "k8s-%{[kubernetes][namespace]}-%{[kubernetes][container][name]}-%{+YYYY.MM.dd}"
}
} else {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "k8s-%{+YYYY.MM.dd}"
}
}
}
---
apiVersion: v1
kind: ConfigMap
metadata:
name: logstash-yml
namespace: elk
labels:
type: logstash
data:
logstash.yml: |-
http.host: "0.0.0.0"
xpack.monitoring.elasticsearch.hosts: http://elasticsearch:9200
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: logstash
namespace: elk
spec:
selector:
matchLabels:
app: logstash
template:
metadata:
labels:
app: logstash
spec:
containers:
- image: elastic/logstash:7.14.0
name: logstash
ports:
- containerPort: 5044
name: logstash
command:
- logstash
- '-f'
- '/usr/share/logstash/config/logstash.conf'
volumeMounts:
- name: config-volume
mountPath: /usr/share/logstash/config/logstash.conf
subPath: logstash.conf
- name: config-yml-volume
mountPath: /usr/share/logstash/config/logstash.yml
subPath: logstash.yml
resources:
limits:
cpu: 1000m
memory: 2048Mi
requests:
cpu: 512m
memory: 128Mi
volumes:
- name: config-volume
configMap:
name: logstash-conf
- name: config-yml-volume
configMap:
name: logstash-yml
kubectl apply -f logstach.yml
查看启动 pod:
kubectl get pods -n elk

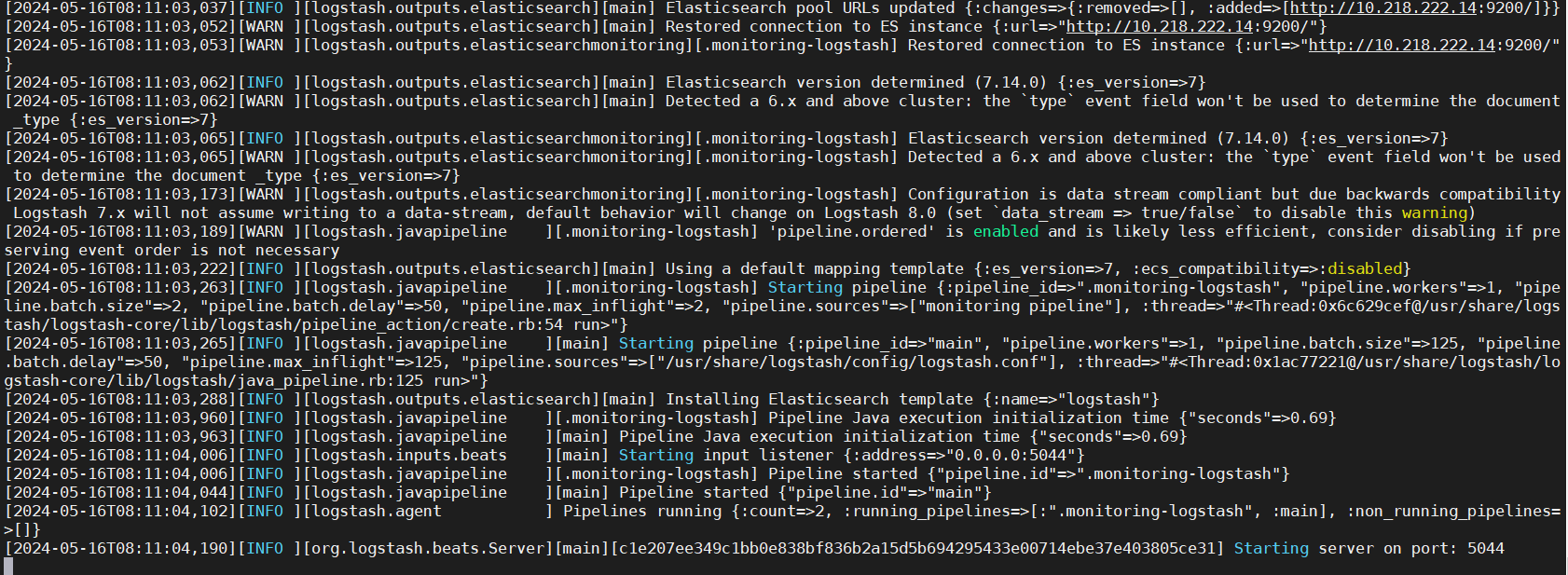
观察 logstash 日志,是否启动成功:
kubectl logs -f logstash-84d8d7cd55-rcfgs -n elk
2.3 部署 filebeta
注意,由于 filebeta 需要获取 k8s 中的信息,这里需要创建 ServiceAccount 并授权获取信息的权限。
vi filebeta.yml
apiVersion: v1
kind: ServiceAccount
metadata:
name: filebeat-account
namespace: elk
labels:
app: filebeat
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: filebeat-cr
labels:
app: filebeat
rules:
- apiGroups: [""]
resources:
- namespaces
- pods
- nodes
verbs: ["get", "watch", "list"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: filebeat-crb
subjects:
- kind: ServiceAccount
name: filebeat-account
namespace: elk
roleRef:
kind: ClusterRole
name: filebeat-cr
apiGroup: rbac.authorization.k8s.io
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: elk
data:
filebeat.yml: |-
filebeat.inputs:
- type: container
enable: true
paths:
- /var/log/containers/*.log
multiline:
pattern: '^\d{4}-\d{1,2}-\d{1,2}'
negate: true
match: after
max_lines: 100
timeout: 5s
processors:
- add_kubernetes_metadata:
default_indexers.enabled: true
default_matchers.enabled: true
matchers:
- logs_path:
logs_path: "/var/log/containers/"
output.logstash:
hosts: ["logstash:5044"]
enabled: true
#output.kafka: # 输出到 kafka 示例
# hosts: ["kafka-01:9092", "kafka-02:9092", "kafka-03:9092"]
# topic: 'topic-log'
# version: 2.0.0
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: filebeat
namespace: elk
labels:
app: filebeat
spec:
selector:
matchLabels:
app: filebeat
template:
metadata:
labels:
app: filebeat
spec:
serviceAccountName: filebeat-account
containers:
- name: filebeat
image: elastic/filebeat:7.14.0
args: [
"-c", "/etc/filebeat.yml",
"-e", "-httpprof","0.0.0.0:6060"
]
securityContext:
runAsUser: 0
# If using Red Hat OpenShift uncomment this:
#privileged: true
resources:
limits:
memory: 1000Mi
cpu: 1000m
requests:
memory: 100Mi
cpu: 128m
volumeMounts:
- name: filebeat-config
mountPath: /etc/filebeat.yml
subPath: filebeat.yml
- name: filebeat-data
mountPath: /usr/share/filebeat/data
- name: docker-containers
mountPath: /var/lib/docker/containers
readOnly: true
- name: pods-log
mountPath: /var/log/pods
readOnly: true
- name: containers-log
mountPath: /var/log/containers
readOnly: true
volumes:
- name: filebeat-config
configMap:
name: filebeat-config
- name: filebeat-data
hostPath:
path: /data/filebeat-data
type: DirectoryOrCreate
- name: docker-containers
hostPath:
path: /var/lib/docker/containers
- name: pods-log
hostPath:
path: /var/log/pods
- name: containers-log
hostPath:
path: /var/log/containers
kubectl apply -f filebeta.yml
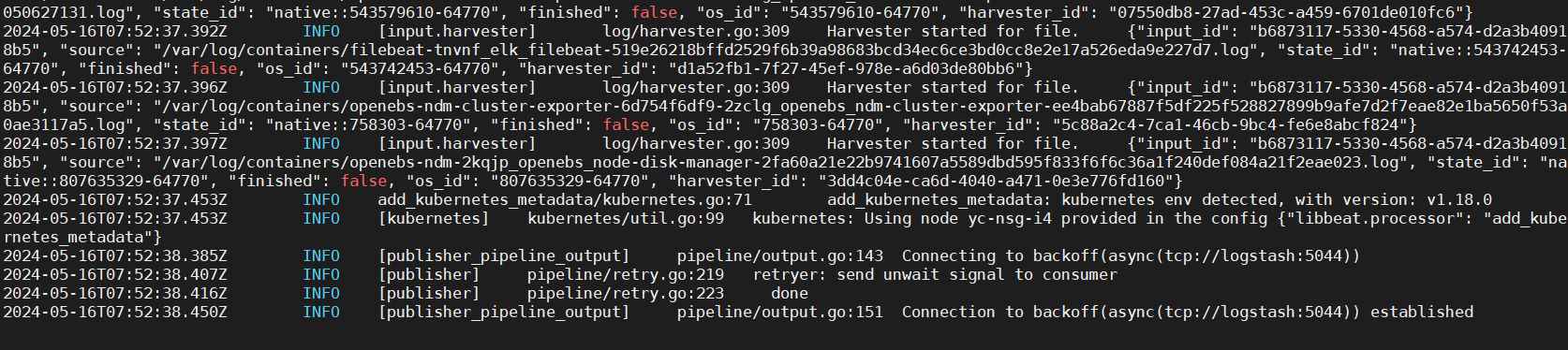
查看 Pod:

由于我测试环境的 k8s node 有三台,所以这里起了三个 filebeat。
观察其中某个 filebeta 日志,是否启动成功:
三、ELK 环境测试
访问测试服务,产生日志:http://{k8s node ip}:31880/t1 。
然后查询当下所有 k8s 开头的索引:
GET /_cat/indices/k8s*?h=index
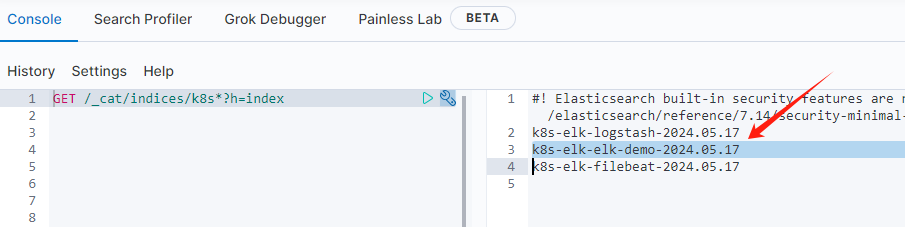
可以看到测试服务的索引已经生成。
3.1 kibana 日志查询
-
点击侧边栏
Discover:
-
然后在
Index patterns下Create an index pattern: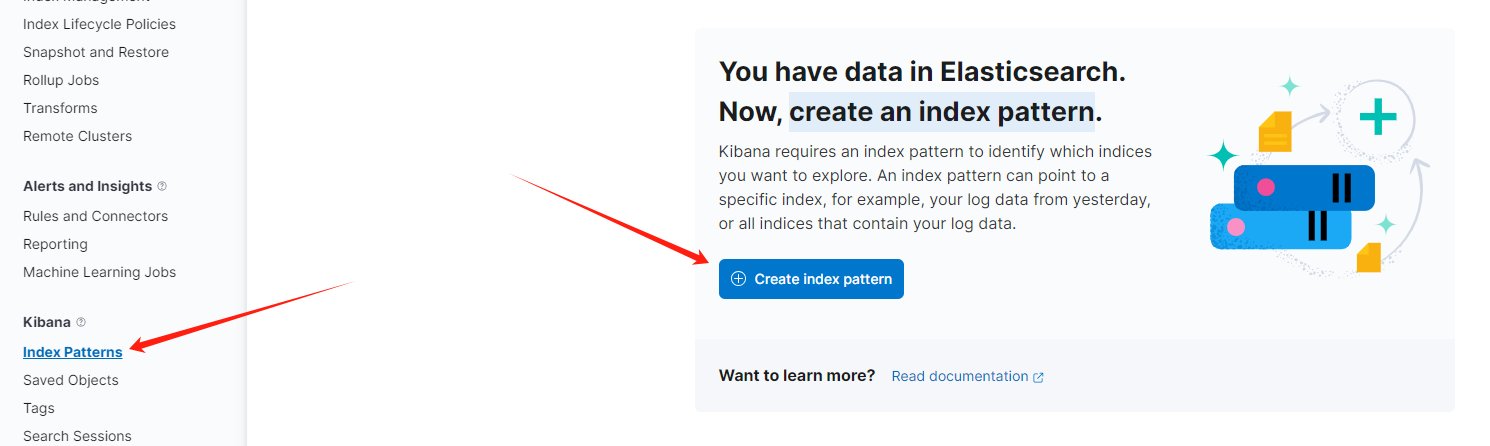
-
这里输入测试服务的索引
k8s-elk-elk-demo-2024.05.17,注意改成你环境下的名字,然后点击Next step: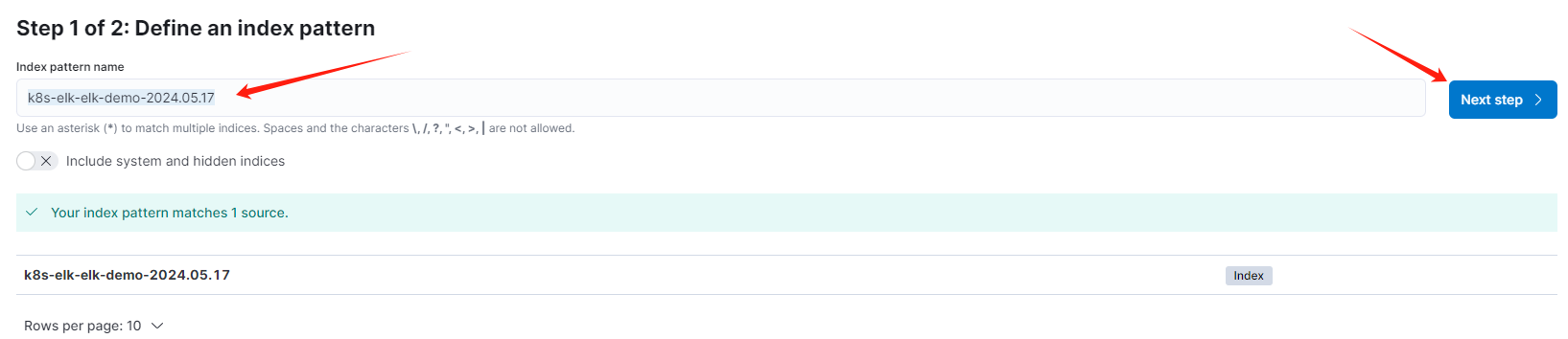
-
然后时间字段可以选择
@timestamp: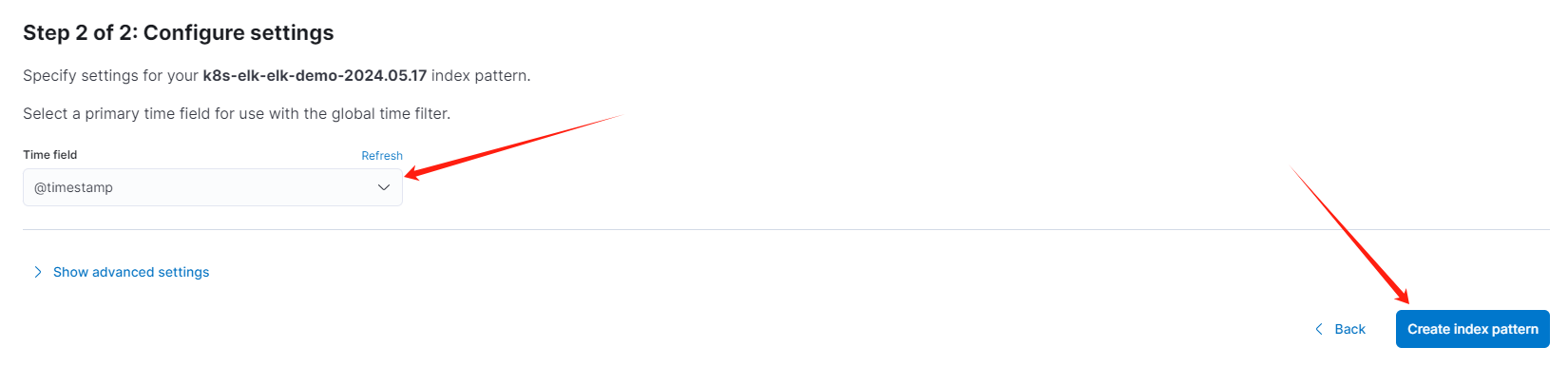
-
然后再次点击侧边栏
Discover进到查询页面,使用介绍如下: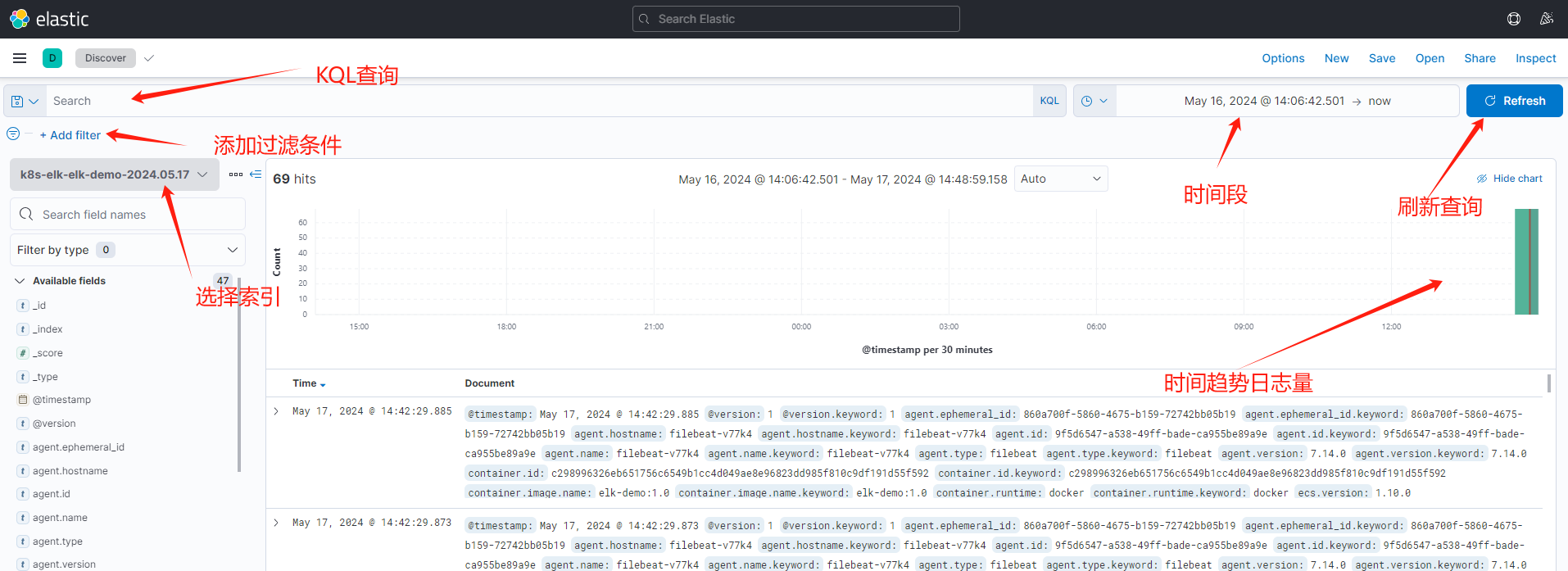
-
例如查询包含
ERROR的日志: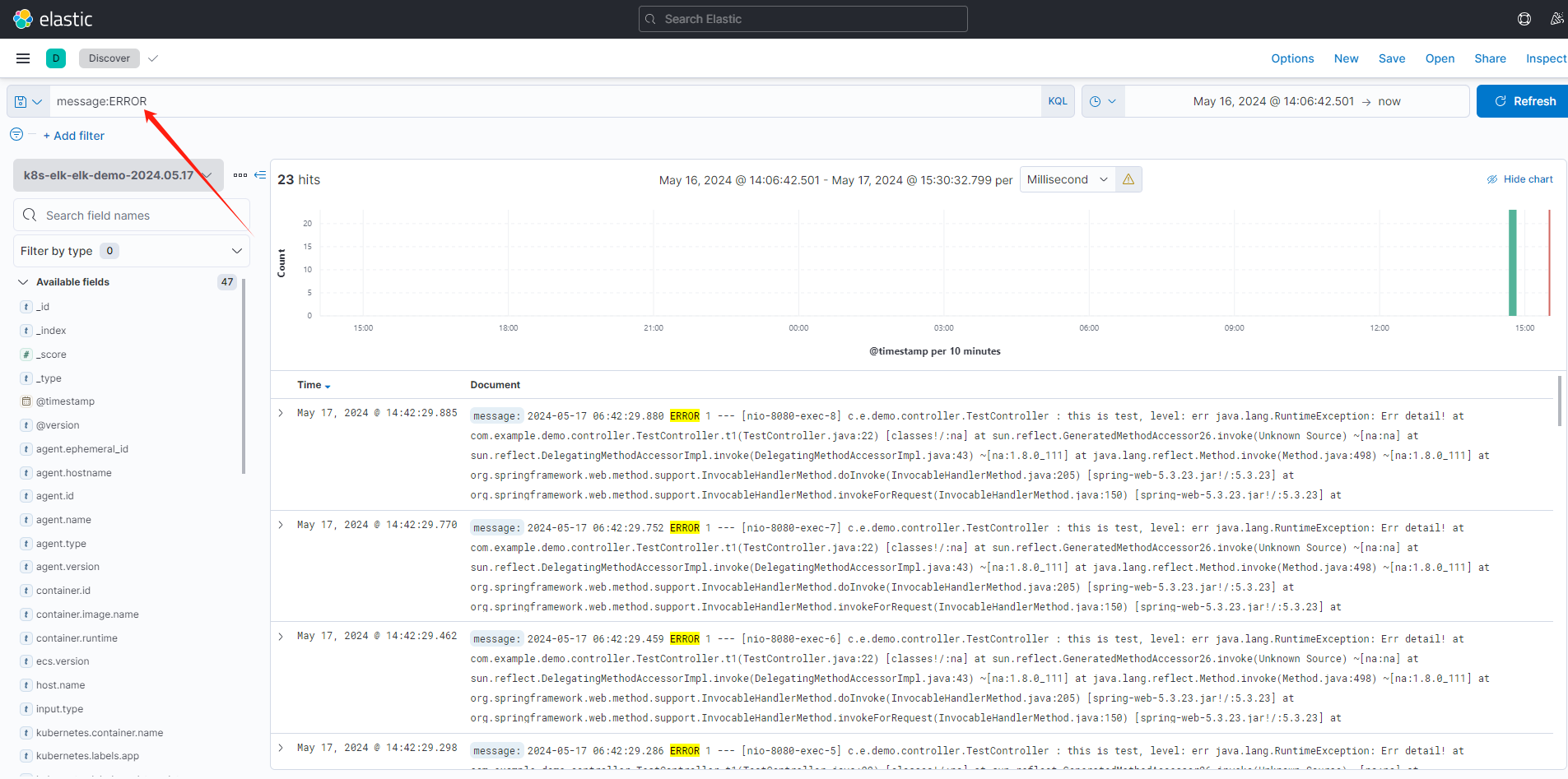
这里的
KQL语法,在文章最后给了出常用语法说明。
3.2 kibana 日志监测
-
点击侧边栏
logs:
-
点击修改配置:

-
增加
k8s-*的监测,然后点击最后的Apply:
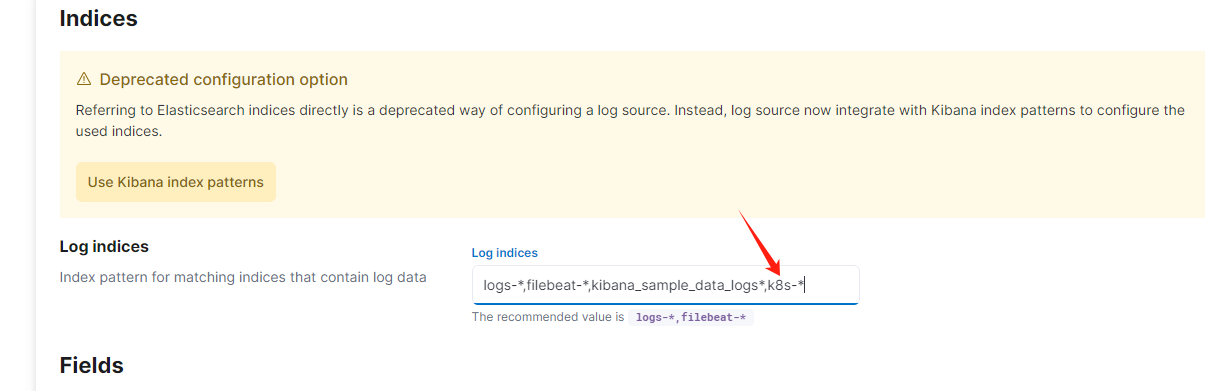
-
然后在
Stream中可以查看日志: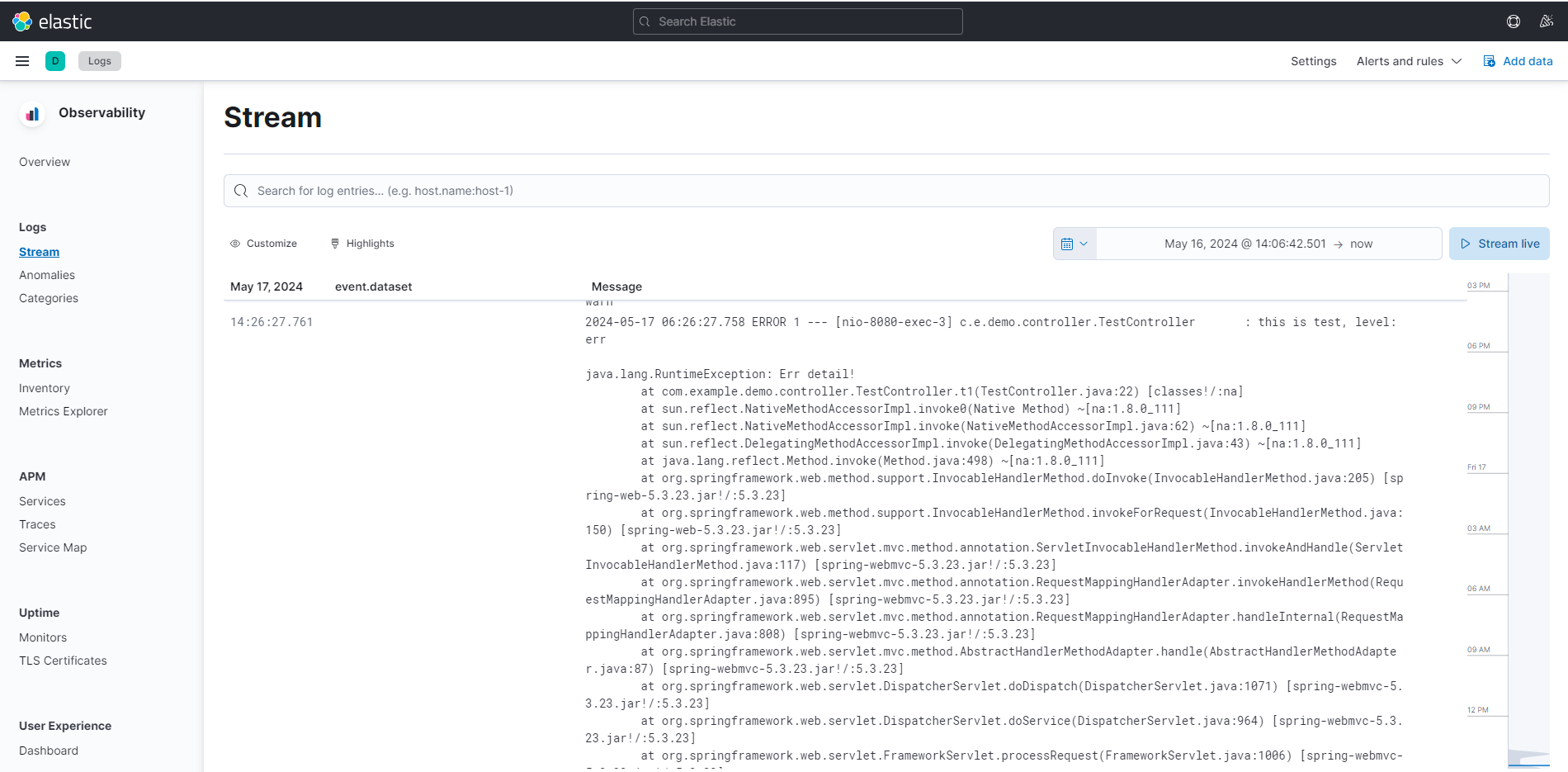
3.3 kibana 使用 ES DSL 查询日志
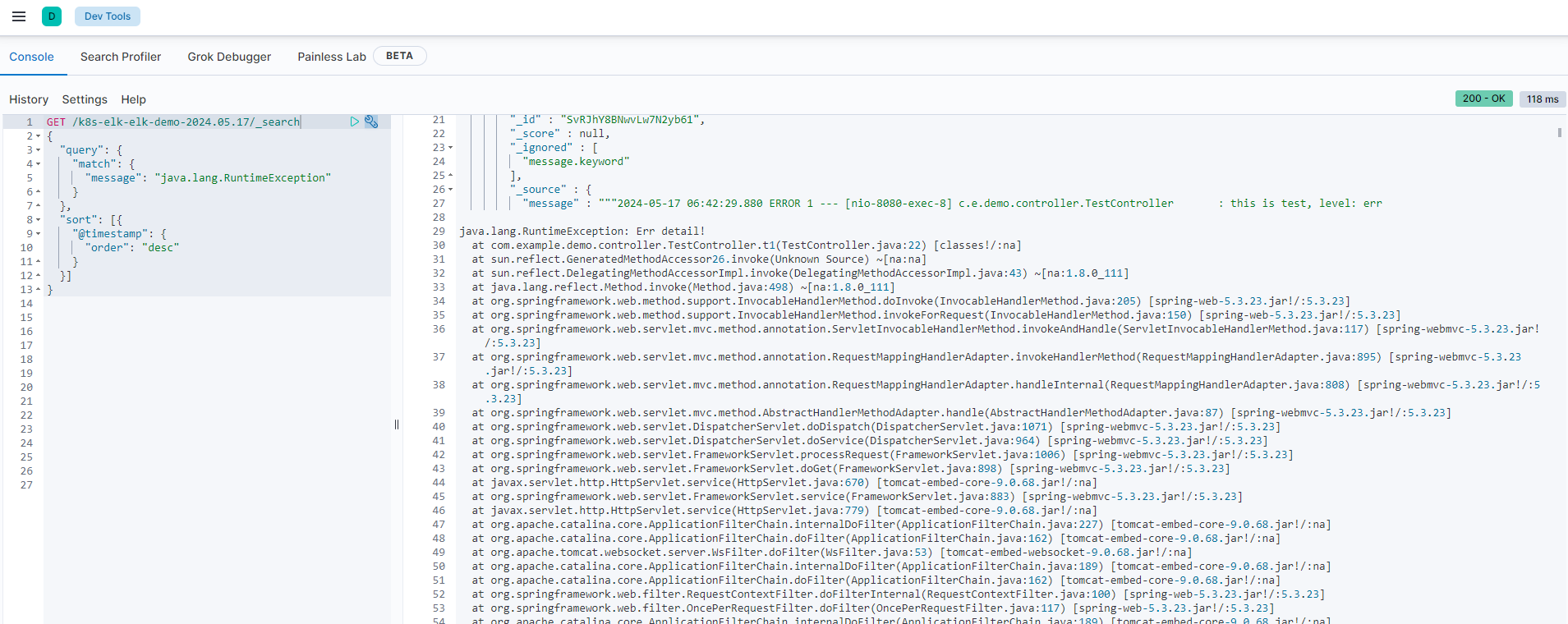
查询错误日志:
GET /k8s-elk-elk-demo-2024.05.17/_search
{
"query": {
"match": {
"message": "java.lang.RuntimeException"
}
},
"sort": [{
"@timestamp": {
"order": "desc"
}
}]
}
四、KQL 语法介绍
KQL(Kibana Query Language)是Kibana中用于搜索和过滤数据的查询语言。它是一种简单的、易于学习的语法,允许用户在不熟悉Elasticsearch的复杂查询DSL的情况下,也能够执行有效的数据搜索和过滤操作。
注意:KQL默认是大小写不敏感的。
4.1 关键字查询
例如:查询 message 字段中包括 hello word 的:
message:"hello word"
如果想要分词,可以不加双引号,这样包含 hello 或 word 的也可以被检索出来:
message:hello word
4.2 逻辑查询
支持 or 、and 、not查询,and的优先级高于or:
message:error and kubernetes.pod.name: "elk-demo-6f8b4b7fd7-4xskf"
message:error and (kubernetes.node.hostname:node1 or kubernetes.node.name:node1)
4.3 范围查询
支持对数字和日志类型使用 < <= > >=:
log.offset > 881576
4.4 Wildcard 查询
message:*error*
4.5 字段存在查询
message:*
4.6 字段不存在
not _exists_:level
或者
not level:*