需要源码和数据集请点赞关注收藏后评论区留言~~~
一、背景
极端天气情况一直困扰着人们的工作和生活。部分企业或者工种对极端天气的要求不同,但是目前主流的天气推荐系统是直接将天气信息推送给全部用户。这意味着重要的天气信息在用户手上得不到筛选,降低用户的满意度,甚至导致用户的经济损失。我们计划开发一个基于图神经网络的天气靶向模型,根据用户的历史交互行为,判断不同天气对他的利害程度。如果有必要,则将该极端天气情况推送给该用户,让其有时间做好应对准备。该模型能够减少不必要的信息传递,提高用户的体验感。
二、模型介绍
四、模型介绍
(一)数据集共有三个txt文件,分别是user.txt,weather.txt,rating.txt。这些文件一共包含900名用户,1600个天气状况,95964条用户的历史交互记录。
- user.txt
用户的信息记录在user.txt中。格式如下:
用户ID\t年龄\t性别\t职业\t地理位置
- weather.txt
天气的信息记录在weather.txt中。格式如下:
天气ID\t天气类型\t温度\t湿度\t风速
- rating.txt
用户的历史交互记录在rating.txt中。格式如下:
用户ID\t天气ID\t评分
三、项目结构
如下图 data里面存放了数据集
四、运行结果
开始训练 可以看到第一行显示了一些训练的基本配置内容 包括用的设备cpu 训练批次 学习率等等

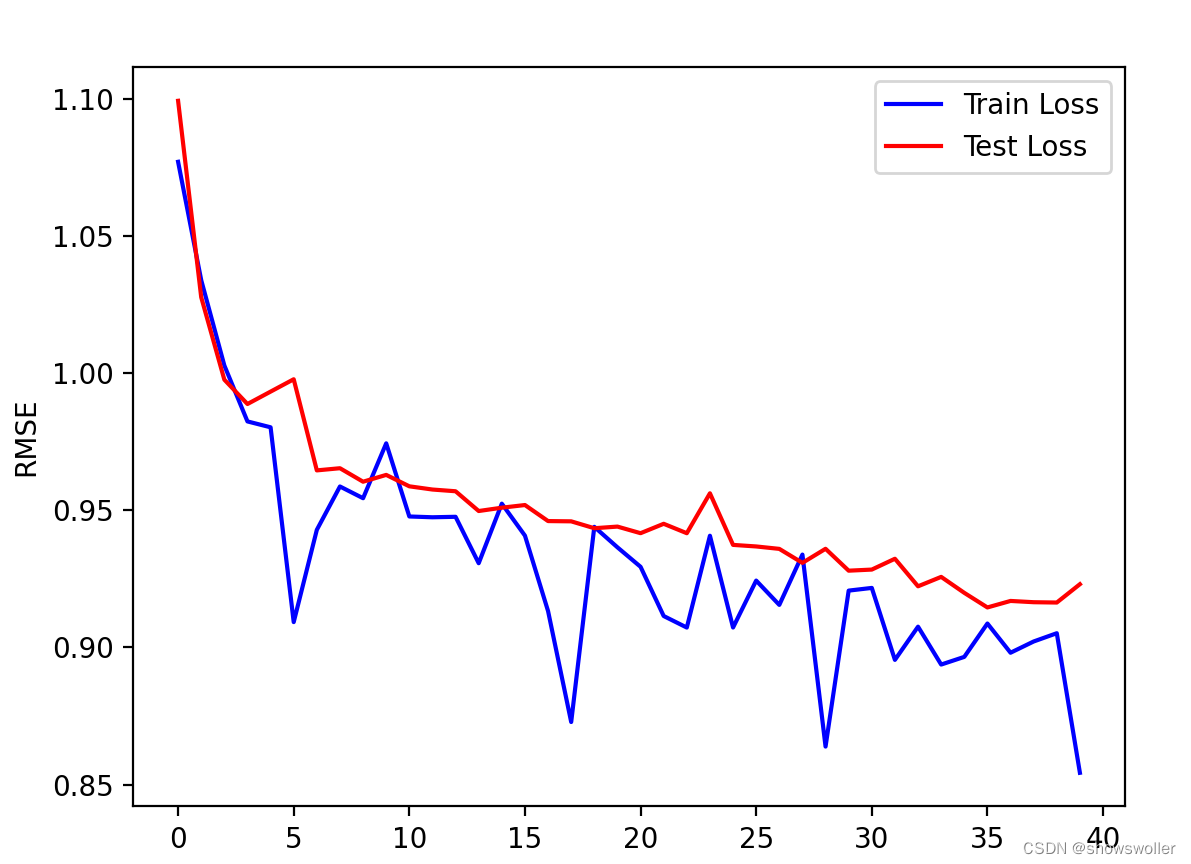
可以看出随着训练次数的增加 损失率在不断降低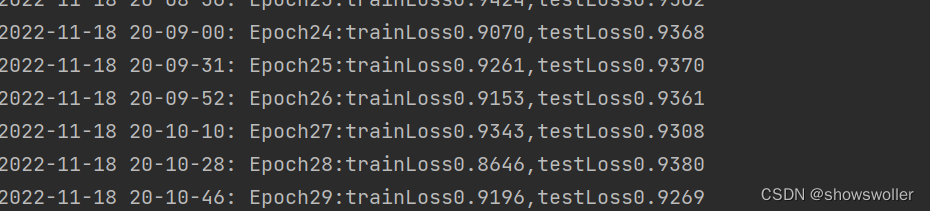
最后会自动选出一个最佳的测试和训练集的损失值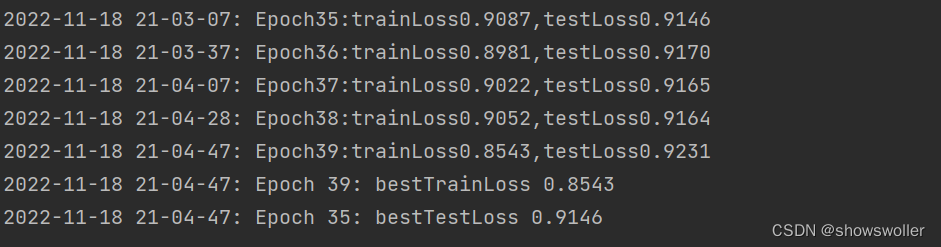
结果可视化如下
五、代码
部分源码如下
train类
import pandas as pd
import time
from utils import fix_seed_torch, draw_loss_pic
import argparse
from model import GCN
from Logger import Logger
from mydataset import MyDataset
import torch
from torch.nn import MSELoss
from torch.optim import Adam
from torch.utils.data import DataLoader, random_split
import sys
import os
os.environ['KMP_DUPLICATE_LIB_OK']='TRUE'
# 固定随机数种子
fix_seed_torch(seed=2021)
# 设置训练的超参数
parser = argparse.ArgumentParser()
parser.add_argument('--gcn_layers', type=int, default=2, help='the number of gcn layers')
parser.add_argument('--n_epochs', type=int, default=20, help='the number of epochs')
parser.add_argument('--embedSize', type=int, default=64, help='dimension of user and entity embeddings')
parser.add_argument('--batch_size', type=int, default=1024, help='batch size')
parser.add_argument('--lr', type=float, default=0.001, help='learning rate')
parser.add_argument('--ratio', type=float, default=0.8, help='size of training dataset')
args = parser.parse_args()
# 设备是否支持cuda
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
args.device = device
# 读取用户特征、天气特征、评分
user_feature = pd.read_csv('./data/user.txt', encoding='utf-8', sep='\t')
item_feature = pd.read_csv('./data/weather.txt', encoding='utf-8', sep='\t')
rating = pd.read_csv('./data/rating.txt', encoding='utf-8', sep='\t')
# 构建数据集
dataset = MyDataset(rating)
trainLen = int(args.ratio * len(dataset))
train, test = random_split(dataset, [trainLen, len(dataset) - trainLen])
train_loader = DataLoader(train, batch_size=args.batch_size, shuffle=True, pin_memory=True)
test_loader = DataLoader(test, batch_size=len(test))
# 记录训练的超参数
start_time = '{}'.format(time.strftime("%m-%d-%H-%M", time.localtime()))
logger = Logger('./log/log-{}.txt'.format(start_time))
logger.info(' '.join('%s: %s' % (k, str(v)) for k, v in sorted(dict(vars(args)).items())))
# 定义模型
model = GCN(args, user_feature, item_feature, rating)
model.to(device)
# 定义优化器
optimizer = Adam(model.parameters(), lr=args.lr, weight_decay=0.001)
# 定义损失函数
loss_function = MSELoss()
train_result = []
test_result = []
# 最好的epoch
best_loss = sys.float_info.max
# 训练
for i in range(args.n_epochs):
model.train()
for batch in train_loader:
optimizer.zero_grad()
prediction=model(batch[0].to(device),batch[1].to(device))
train_loss=torch.sqrt(loss_function(batch[2].float().to(device),prediction))
train_loss.backward()
optimizer.step()
train_result.append(train_loss.item())
model.eval()
for data in test_loader:
prediction=model(data[0].to(device),data[1].to(device))
test_loss=torch.sqrt(loss_function(data[2].float().to(device),prediction))
test_loss=test_loss.item()
if best_loss>test_loss:
best_loss=test_loss
torch.save(model.state_dict(),'./model/bestModeParms-{}.pth'.format(start_time))
test_result.append(test_loss)
logger.info("Epoch{:d}:trainLoss{:.4f},testLoss{:.4f}".format(i,train_loss,test_loss))
else:
model.load_state_dict(torch.load("./model/bestModeParms-11-18-19-47.pth"))
user_id=input("请输入用户id")
item_num=rating['itemId'].max()+1
u=torch.tensor([int(user_id)for i in range(item_num)],dtype=float)
气ID".format(user_id))
print(i[0]for i in result)
# 画图
draw_loss_pic(train_result, test_result)
Logger类
import sys
import os
import logging
class Logger(object):
def __init__(self, filename):
self.logger = logging.getLogger(filename)
self.logger.setLevel(logging.DEBUG)
formatter = logging.Formatter('%(asctime)s: %(message)s',
datefmt='%Y-%m-%d %H-%M-%S')
# write into file
fh = logging.FileHandler(filename)
fh.setLevel(logging.DEBUG)
fh.setFormatter(formatter)
# show on console
ch = logging.StreamHandler(sys.stdout)
ch.setLevel(logging.DEBUG)
ch.setFormatter(formatter)
# add to Handler
self.logger.addHandler(fh)
self.logger.addHandler(ch)
def _flush(self):
for handler in self.logger.handlers:
handler.flush()
def info(self, message):
self.logger.info(message)
self._flush()model类
import numpy as np
import torch.nn
import torch.nn as nn
from utils import *
from torch.nn import Module
import scipy.sparse as sp
class GCN_Layer(Module):
def __init__(self,inF,outF):
super(GCN_Layer,self).__init__()
self.W1=torch.nn.Linear(in_features=inF,out_features=outF)
self.W2=torch.nn.Linear(in_features=inF,out_features=outF)
def forward(self,graph,selfLoop,features):
part1=self.W1(torch.sparse.mm(graph+selfLoop,features))
part2 = self.W2(torch.mul(torch.sparse.mm(graph,features),features))
return nn.LeakyReLU()(part1+part2)
######################
# 请你补充代码 #
######################
class GCN(Module):
def __init__(self, args, user_feature, item_feature, rating):
super(GCN, self).__init__()
self.args = args
self.device = args.device
self.user_feature = user_feature
self.item_feature = item_feature
self.rating = rating
self.num_user = rating['user_id'].max() + 1
self.num_item = rating['item_id'].max() + 1
# user embedding
self.user_id_embedding = nn.Embedding(user_feature['id'].max() + 1, 32)
self.user_age_embedding = nn.Embedding(user_feature['age'].max() + 1, 4)
self.user_gender_embedding = nn.Embedding(user_feature['gender'].max() + 1, 2)
self.user_occupation_embedding = nn.Embedding(user_feature['occupation'].max() + 1, 8)
self.user_location_embedding = nn.Embedding(user_feature['location'].max() + 1, 18)
# item embedding
self.item_id_embedding = nn.Embedding(item_feature['id'].max() + 1, 32)
self.item_type_embedding = nn.Embedding(item_feature['type'].max() + 1, 8)
self.item_temperature_embedding = nn.Embedding(item_feature['temperature'].max() + 1, 8)
self.item_humidity_embedding = nn.Embedding(item_feature['humidity'].max() + 1, 8)
self.item_windSpeed_embedding = nn.Embedding(item_feature['windSpeed'].max() + 1, 8)
# 自循环
self.selfLoop = self.getSelfLoop(self.num_user + self.num_item)
# 堆叠GCN层
self.GCN_Layers = torch.nn.ModuleList()
for _ in range(self.args.gcn_layers):
self.GCN_Layers.append(GCN_Layer(self.args.embedSize, self.args.embedSize))
self.graph = self.buildGraph()
self.transForm = nn.Linear(in_features=self.args.embedSize * (self.args.gcn_layers + 1),
out_features=self.args.embedSize)
def getSelfLoop(self, num):
i = torch.LongTensor(
[[k for k in range(0, num)], [j for j in range(0, num)]])
val = torch.FloatTensor([1] * num)
return torch.sparse.FloatTensor(i, val).to(self.device)
def buildGraph(self):
rating=self.rating.values
graph=sp.coo_matrix(
(rating[:,2],(rating[:,0],rating[:,1])),shape=(self.num_user,self.num_item)).tocsr()
graph=sp.bmat([[sp.csr_matrix((graph.shape[0],graph.shape[0])),graph],
[graph.T,sp.csr_matrix((graph.shape[1],graph.shape[1]))]])
row_sum_sqrt=sp.diags(1/(np.sqrt(graph.sum(axis=1).A.ravel())+1e-8))
col_sum_sqrt = sp.diags(1 / (np.sqrt(graph.sum(axis=0).A.ravel()) + 1e-8))
graph=row_sum_sqrt@graph@col_sum_sqrt
graph=graph.tocoo()
values=graph.data
indices=np.vstack((graph.row,graph.col))
graph=torch.sparse.FloatTensor(torch.LongTensor(indices),torch.FloatTensor(values),torch.Size(graph.shape))
return graph.to(self.device)
######################
# 请你补充代码 #
######################
def getFeature(self):
# 根据用户特征获取对应的embedding
user_id = self.user_id_embedding(torch.tensor(self.user_feature['id']).to(self.device))
age = self.user_age_embedding(torch.tensor(self.user_feature['age']).to(self.device))
gender = self.user_gender_embedding(torch.tensor(self.user_feature['gender']).to(self.device))
occupation = self.user_occupation_embedding(torch.tensor(self.user_feature['occupation']).to(self.device))
location = self.user_location_embedding(torch.tensor(self.user_feature['location']).to(self.device))
user_emb = torch.cat((user_id, age, gender, occupation, location), dim=1)
# 根据天气特征获取对应的embedding
item_id = self.item_id_embedding(torch.tensor(self.item_feature['id']).to(self.device))
item_type = self.item_type_embedding(torch.tensor(self.item_feature['type']).to(self.device))
temperature = self.item_temperature_embedding(torch.tensor(self.item_feature['temperature']).to(self.device))
humidity = self.item_humidity_embedding(torch.tensor(self.item_feature['humidity']).to(self.device))
windSpeed = self.item_windSpeed_embedding(torch.tensor(self.item_feature['windSpeed']).to(self.device))
item_emb = torch.cat((item_id, item_type, temperature, humidity, windSpeed), dim=1)
# 拼接到一起
concat_emb = torch.cat([user_emb, item_emb], dim=0)
return concat_emb.to(self.device)
def forward(self, users, items):
features=self.getFeature()
final_emb=features.clone()
for GCN_Layer in self.GCN_Layers:
features=GCN_Layer(self.graph,self.selfLoop,features)
final_emb=torch.cat((final_emb,features.clone()),dim=1)
user_emb,item_emb=torch.split(final_emb,[self.num_user,self.num_item])
user_emb=user_emb[users]
item_emb=item_emb[items]
user_emb=self.transForm(user_emb)
item_emb=self.transForm(item_emb)
prediction=torch.mul(user_emb,item_emb).sum(1)
return prediction
######################
# 请你补充代码 #
######################
mydataset类
from torch.utils.data import Dataset
import pandas as pd
class MyDataset(Dataset):
def __init__(self, rating):
super(Dataset, self).__init__()
self.user = rating['user_id']
self.weather = rating['item_id']
self.rating = rating['rating']
def __len__(self):
return len(self.rating)
def __getitem__(self, item):
return self.user[item], self.weather[item], self.rating[item]
utils类
from torch.utils.data import Dataset
import pandas as pd
class MyDataset(Dataset):
def __init__(self, rating):
super(Dataset, self).__init__()
self.user = rating['user_id']
self.weather = rating['item_id']
self.rating = rating['rating']
def __len__(self):
return len(self.rating)
def __getitem__(self, item):
return self.user[item], self.weather[item], self.rating[item]
创作不易 觉得有帮助请点赞关注收藏~~~






![[附源码]SSM计算机毕业设计足球队管理系统JAVA](https://img-blog.csdnimg.cn/3461cef089a4476891a08733ffc54e40.png)
![[附源码]java毕业设计企业记账系统](https://img-blog.csdnimg.cn/5e361241c0ba4f9db4245c44d63309b2.png)