文章目录
- 1. 先写出第一步
- 2.将其封装成函数
- 3. pytorch版
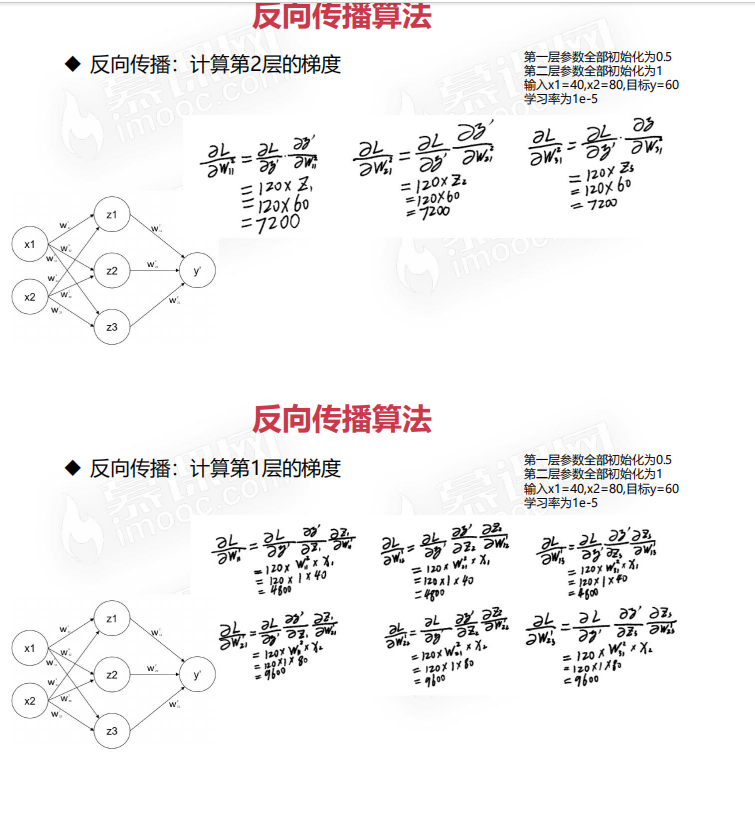
1. 先写出第一步
# 定义输入值和期望输出
x_1 = 40.0
x_2 = 80.0
expected_output = 60.0
'''
初始化
'''
# 定义权重
w_1_11 = 0.5
w_1_12 = 0.5
w_1_13 = 0.5
w_1_21 = 0.5
w_1_22 = 0.5
w_1_23 = 0.5
w_2_11 = 1.0
w_2_21 = 1.0
w_2_31 = 1.0
'''前向传播
'''
z_1 = x_1 * w_1_11 + x_2 * w_1_21
z_2 = x_1 * w_1_12 + x_2 * w_1_22
z_3 = x_1 * w_1_13 + x_2 * w_1_23
y_pred = z_1 * w_2_11 + z_2 * w_2_21 + z_3 * w_2_31
# print(z_1, z_2, z_3, y_pred)
print("前向传播预测值为: ", y_pred)
# 计算损失函数值(L2损失)
loss = 0.5 * (expected_output - y_pred) ** 2
print("当前的loss值为:",loss)
'''
开始计算梯度
'''
# 计算输出层关于损失函数的梯度
d_loss_predicted_output = -(expected_output - y_pred)
# print(d_loss_predicted_output)
#
# 计算权重关于损失函数的梯度
d_loss_w_2_11 = d_loss_predicted_output * z_1
d_loss_w_2_21 = d_loss_predicted_output * z_2
d_loss_w_2_31 = d_loss_predicted_output * z_3
# print(d_loss_w_2_11,d_loss_w_2_21,d_loss_w_2_31)
d_loss_w_1_11 = d_loss_predicted_output * w_2_11 * x_1
# print(d_loss_w_1_11)
d_loss_w_1_21 = d_loss_predicted_output * w_2_11 * x_2
# print(d_loss_w_1_21)
d_loss_w_1_12 = d_loss_predicted_output * w_2_21 * x_1
# print(d_loss_w_1_12)
d_loss_w_1_22 = d_loss_predicted_output * w_2_21 * x_2
# print(d_loss_w_1_22)
d_loss_w_1_13 = d_loss_predicted_output * w_2_31 * x_1
# print(d_loss_w_1_13)
d_loss_w_1_23 = d_loss_predicted_output * w_2_31 * x_2
# print(d_loss_w_1_23)
# 使用梯度下降法更新权重
learning_rate = 1e-5
w_2_11 -= learning_rate * d_loss_w_2_11
w_2_21 -= learning_rate * d_loss_w_2_21
w_2_31 -= learning_rate * d_loss_w_2_31
w_1_11 -= learning_rate * d_loss_w_1_11
w_1_12 -= learning_rate * d_loss_w_1_12
w_1_13 -= learning_rate * d_loss_w_1_13
w_1_21 -= learning_rate * d_loss_w_1_21
w_1_22 -= learning_rate * d_loss_w_1_22
w_1_23 -= learning_rate * d_loss_w_1_23
'''前向传播
'''
z_1 = x_1 * w_1_11 + x_2 * w_1_21
z_2 = x_1 * w_1_12 + x_2 * w_1_22
z_3 = x_1 * w_1_13 + x_2 * w_1_23
y_pred = z_1 * w_2_11 + z_2 * w_2_21 + z_3 * w_2_31
print("Final: ",y_pred)
# print("前向传播预测值为: ", y_pred)
loss = 0.5 * (expected_output - y_pred) ** 2
print("当前的loss值为:",loss)
2.将其封装成函数
def forward_propagation(layer_1_list, layer_2_list):
w_1_11, w_1_12, w_1_13, w_1_21, w_1_22, w_1_23 = layer_1_list
w_2_11, w_2_21, w_2_31 = layer_2_list
z_1 = x_1 * w_1_11 + x_2 * w_1_21
z_2 = x_1 * w_1_12 + x_2 * w_1_22
z_3 = x_1 * w_1_13 + x_2 * w_1_23
y_pred = z_1 * w_2_11 + z_2 * w_2_21 + z_3 * w_2_31
return y_pred
def compute_loss(y_true, y_pred):
loss = 0.5 * (y_true - y_pred) ** 2
return loss
def backward_propagation(layer_1_list,layer_2_list,learning_rate):
w_1_11, w_1_12, w_1_13, w_1_21, w_1_22, w_1_23 = layer_1_list
w_2_11, w_2_21, w_2_31 = layer_2_list
z_1 = x_1 * w_1_11 + x_2 * w_1_21
z_2 = x_1 * w_1_12 + x_2 * w_1_22
z_3 = x_1 * w_1_13 + x_2 * w_1_23
# 计算输出层关于损失函数的梯度
d_loss_predicted_output = -(y_true - y_pred)
# 计算权重关于损失函数的梯度
d_loss_w_2_11 = d_loss_predicted_output * z_1
d_loss_w_2_21 = d_loss_predicted_output * z_2
d_loss_w_2_31 = d_loss_predicted_output * z_3
d_loss_w_1_11 = d_loss_predicted_output * w_2_11 * x_1
d_loss_w_1_21 = d_loss_predicted_output * w_2_11 * x_2
d_loss_w_1_12 = d_loss_predicted_output * w_2_21 * x_1
d_loss_w_1_22 = d_loss_predicted_output * w_2_21 * x_2
d_loss_w_1_13 = d_loss_predicted_output * w_2_31 * x_1
d_loss_w_1_23 = d_loss_predicted_output * w_2_31 * x_2
# 使用梯度下降法更新权重
w_2_11 -= learning_rate * d_loss_w_2_11
w_2_21 -= learning_rate * d_loss_w_2_21
w_2_31 -= learning_rate * d_loss_w_2_31
w_1_11 -= learning_rate * d_loss_w_1_11
w_1_12 -= learning_rate * d_loss_w_1_12
w_1_13 -= learning_rate * d_loss_w_1_13
w_1_21 -= learning_rate * d_loss_w_1_21
w_1_22 -= learning_rate * d_loss_w_1_22
w_1_23 -= learning_rate * d_loss_w_1_23
layer_1_list = [w_1_11, w_1_12, w_1_13, w_1_21, w_1_22, w_1_23]
layer_2_list = [w_2_11, w_2_21, w_2_31]
return layer_1_list,layer_2_list
def parm_init():
# 初始化定义权重
w_1_11 = 0.5
w_1_12 = 0.5
w_1_13 = 0.5
w_1_21 = 0.5
w_1_22 = 0.5
w_1_23 = 0.5
w_2_11 = 1.0
w_2_21 = 1.0
w_2_31 = 1.0
layer_1_list = [w_1_11,w_1_12,w_1_13,w_1_21,w_1_22,w_1_23]
layer_2_list = [w_2_11,w_2_21,w_2_31]
return layer_1_list, layer_2_list
if __name__ == '__main__':
# 定义输入值和期望输出
x_1 = 40.0
x_2 = 80.0
y_true = 60.0
learning_rate = 1e-5
epoch = 100
'''
初始化
'''
# 初始化定义权重
layer_1_list, layer_2_list = parm_init()
for i in range(epoch):
# 正向传播
y_pred = forward_propagation(layer_1_list,layer_2_list)
# 计算损失
loss = compute_loss(y_true, y_pred)
print(f"第{i}次 预测值为: ", y_pred, " 误差为: ",loss)
# 反向传播
layer_1_list,layer_2_list = backward_propagation(layer_1_list,layer_2_list,learning_rate)
3. pytorch版
import torch
import torch.optim as optim
def forward_propagation(x_1, x_2, layer_1_list, layer_2_list):
w_1_11, w_1_12, w_1_13, w_1_21, w_1_22, w_1_23 = layer_1_list
w_2_11, w_2_21, w_2_31 = layer_2_list
z_1 = x_1 * w_1_11 + x_2 * w_1_21
z_2 = x_1 * w_1_12 + x_2 * w_1_22
z_3 = x_1 * w_1_13 + x_2 * w_1_23
y_pred = z_1 * w_2_11 + z_2 * w_2_21 + z_3 * w_2_31
return y_pred
def compute_loss(y_true, y_pred):
loss = 0.5 * (y_true - y_pred) ** 2
return loss
def backward_propagation(layer_1_list, layer_2_list, optimizer):
# 清零梯度
optimizer.zero_grad()
# 反向传播
loss.backward()
# 使用优化器更新权重
optimizer.step()
# 返回更新后的权重
return layer_1_list, layer_2_list
def parm_init():
# 初始化定义权重
w_1_11 = torch.tensor(0.5, requires_grad=True)
w_1_12 = torch.tensor(0.5, requires_grad=True)
w_1_13 = torch.tensor(0.5, requires_grad=True)
w_1_21 = torch.tensor(0.5, requires_grad=True)
w_1_22 = torch.tensor(0.5, requires_grad=True)
w_1_23 = torch.tensor(0.5, requires_grad=True)
w_2_11 = torch.tensor(1.0, requires_grad=True)
w_2_21 = torch.tensor(1.0, requires_grad=True)
w_2_31 = torch.tensor(1.0, requires_grad=True)
layer_1_list = [w_1_11, w_1_12, w_1_13, w_1_21, w_1_22, w_1_23]
layer_2_list = [w_2_11, w_2_21, w_2_31]
return layer_1_list, layer_2_list
if name == ‘main’:
# 定义输入值和期望输出
x_1 = torch.tensor([40.0])
x_2 = torch.tensor([80.0])
y_true = torch.tensor([60.0])
learning_rate = 1e-5
epoch = 100
'''
初始化
'''
# 初始化定义权重
layer_1_list, layer_2_list = parm_init()
# 使用SGD优化器进行权重更新
optimizer = optim.SGD(layer_1_list + layer_2_list, lr=learning_rate)
for i in range(epoch):
# 正向传播
y_pred = forward_propagation(x_1, x_2, layer_1_list, layer_2_list)
# 计算损失
loss = compute_loss(y_true, y_pred)
# 反向传播
layer_1_list, layer_2_list = backward_propagation(layer_1_list, layer_2_list, optimizer)
print(f"第{i}次 预测值为: ", y_pred.item(), " 误差为: ",loss.item())







![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-16讲 EPIT定时器](https://img-blog.csdnimg.cn/direct/2c1364a5c1894b57b6167b3832854144.png)