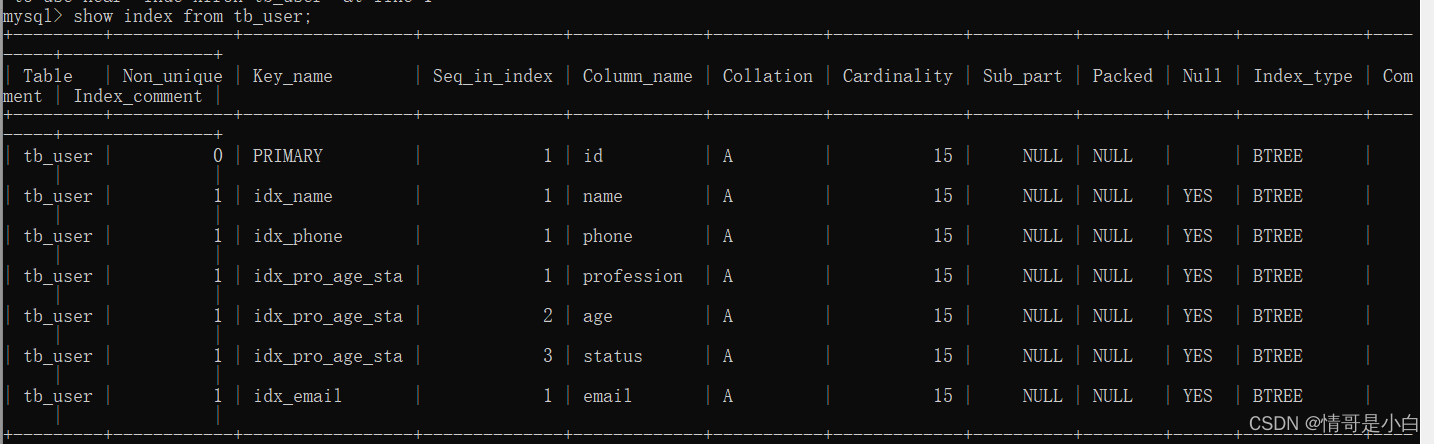
前言:
上篇文章使用Scrapy框架简单爬取并下载了某瓣Top250首页的排名前25个电影的电影名。
太寒酸了,这篇文章咱就来仔细搞一搞,搞到更加详细的信息!!!
目录:
- 1.分析
- 2.使用scrapy shell提取电影详细信息
- 2.1 终端进入scrapy shell交互式界面命令:
- 2.2 首先,确认下最开始的分析是否正确(每个电影的信息都藏在class属性值为info的div中)
- 2.3 分析如何获取到电影名字
- 2.3.1 首先尝试获取第一个电影名字。结合源码使用xpath匹配:
- 2.2 一个电影名字获取成功,使用循环尝试能否成功获取到25个电影名字:
- 2.4 分析如何获取到电影主演
- 2.5 分析如何获取电影的评分:
- 2.5.1 首先,尝试获取第一个电影的评分。结合源码使用xpath匹配:
- 2.5.2 一个电影的评分获取成功,使用循环尝试能否成功获取总得25个电影的评分:
- 2.6 总结:
1.分析
我们知道提取的数据是在spider爬虫文件里的parse函数下进行解析的!
(这个parse函数本来就是来解析和提取数据的!!!)
- 那么,既然我们要获取更加详细的信息,我们就要来分析网页源码:(经过简单观察之后,我们发现,这25个电影各自的所有信息都分别放在了class属性值为info的div标签里,那么,我们提取出这些电影信息的话,就要首先提取到这些特定的div标签,然后再对这些个div标签进行操作即可!)
网页源码剖析:
<div class="info">
<div class="hd">
<a href="https://迫不得已打码/subject/1292052/" class="">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
<span class="playable">[可播放]</span>
</div>
<div class="bd">
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br>
1994 / 美国 / 犯罪 剧情
</p>
<div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.7</span>
<span property="v:best" content="10.0"></span>
<span>1983356人评价</span>
</div>
<p class="quote">
<span class="inq">希望让人自由。</span>
</p>
</div>
</div>
2.使用scrapy shell提取电影详细信息
既然要分析如何分别匹配到各个电影的详细的信息,那么我们就考虑使用scrapy shell来十分方便快捷的进行各种尝试
2.1 终端进入scrapy shell交互式界面命令:
scrapy shell 还是上篇的start_urls
2.2 首先,确认下最开始的分析是否正确(每个电影的信息都藏在class属性值为info的div中)

这就说明咱的分析是没得错的!
2.3 分析如何获取到电影名字
2.3.1 首先尝试获取第一个电影名字。结合源码使用xpath匹配:

2.2 一个电影名字获取成功,使用循环尝试能否成功获取到25个电影名字:
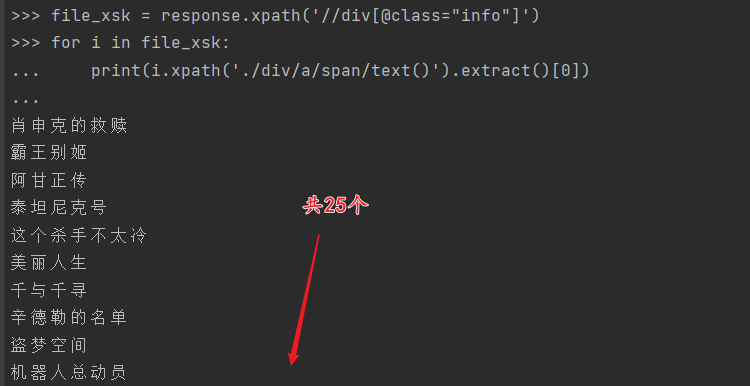
会发现灰常的成功哦!
2.4 分析如何获取到电影主演
① 观察网页源码可知:主演所在的标签里面非常混乱,所以,先尝试匹配出25个电影的主演所在的标签:
- 包含电影主演的标签:

 也是非常的成功!!!
也是非常的成功!!!
②第二步:我们要想办法匹配到每一个电影的主演的名字,但是!观察刚刚匹配到25个电影的包含主演的标签的text信息可知,这里面有坑哦!有些电影不一定有主演:

③所以,咱再匹配这25个电影的主演名字的时候,一定要注意使用判断避坑!(见下:)
if "主" in con_star_name:
star_name=re.findall("主演?:? ?(.*)",con_star_name)[0]
else:
star_name="空"
2.5 分析如何获取电影的评分:
2.5.1 首先,尝试获取第一个电影的评分。结合源码使用xpath匹配:

又是美好的成功哦!
2.5.2 一个电影的评分获取成功,使用循环尝试能否成功获取总得25个电影的评分:

非常的完美!
2.6 总结:
def parse(self, response): #解析和提取数据
# 获取电影信息数据
# films_name=response.xpath('//div[@class="info"]/div/a/span[1]/text()').extract()
node_list=response.xpath('//div[@class="info"]') #25个
for node in node_list:
# 电影名字
film_name=node.xpath('./div/a/span[1]/text()').extract()[0]
# 主演 拿标签内容,再正则表达式匹配
con_star_name=node.xpath('./div/p[1]/text()').extract()[0]
if "主" in con_star_name:
star_name=re.findall("主演?:? ?(.*)",con_star_name)[0]
else:
star_name="空"
#评分
score=node_list.xpath('./div/div/span[@property="v:average"]/text()').extract()[0]