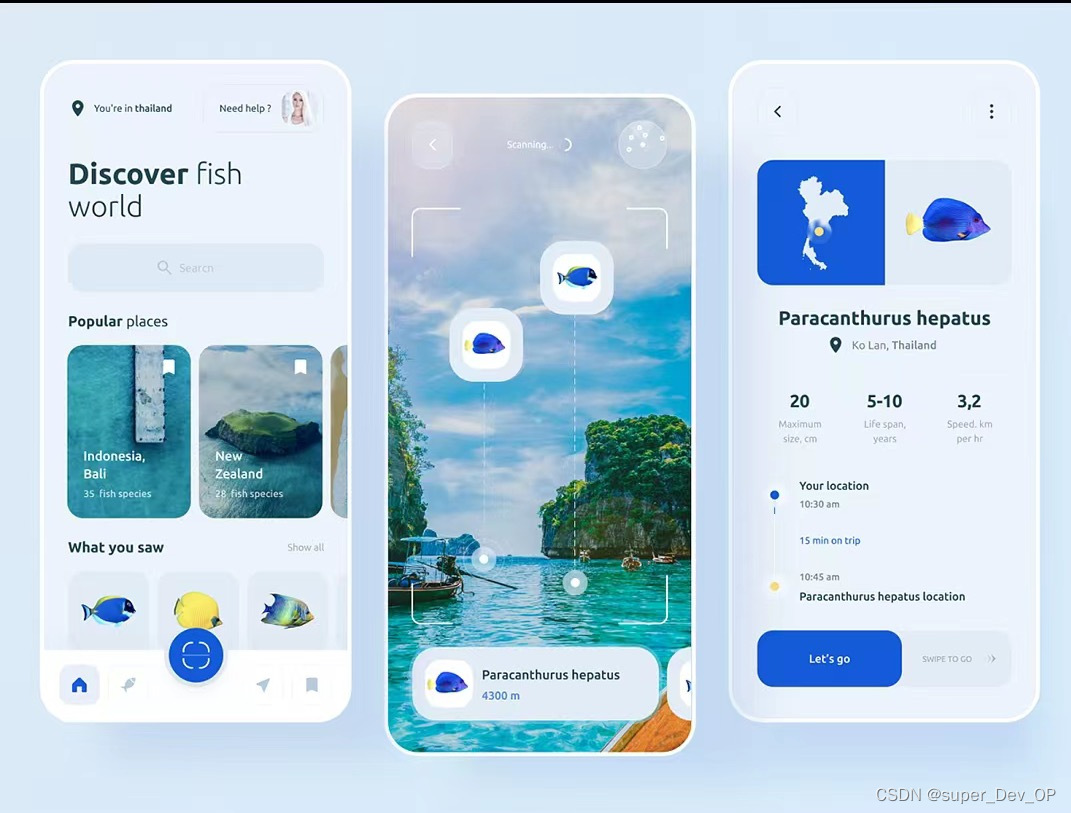
1.对于决策树的概念:
**本质上:**决策树就是模拟树的结构基于 if-else的多层判断

2.目的:
对实例进行分类的树形结构,通过多层判断,将所提供的数据归纳为一种分类规则。
3.优点:
1.计算量小,无需考虑损失函数,运行速度快
2.便于理解
4.缺点:
1.忽略了属性之间的相关性,比如我们的逻辑回归,sigmod函数它考虑了属性之间的相关性,比如是否具有学习兴趣,可能学习动力和学习时间是有一定的关联的,逻辑回归就考虑了相关性,但是决策树就没有考虑。
2.样本类别分布不均匀时,容易影响模型的表现。
2.例子:
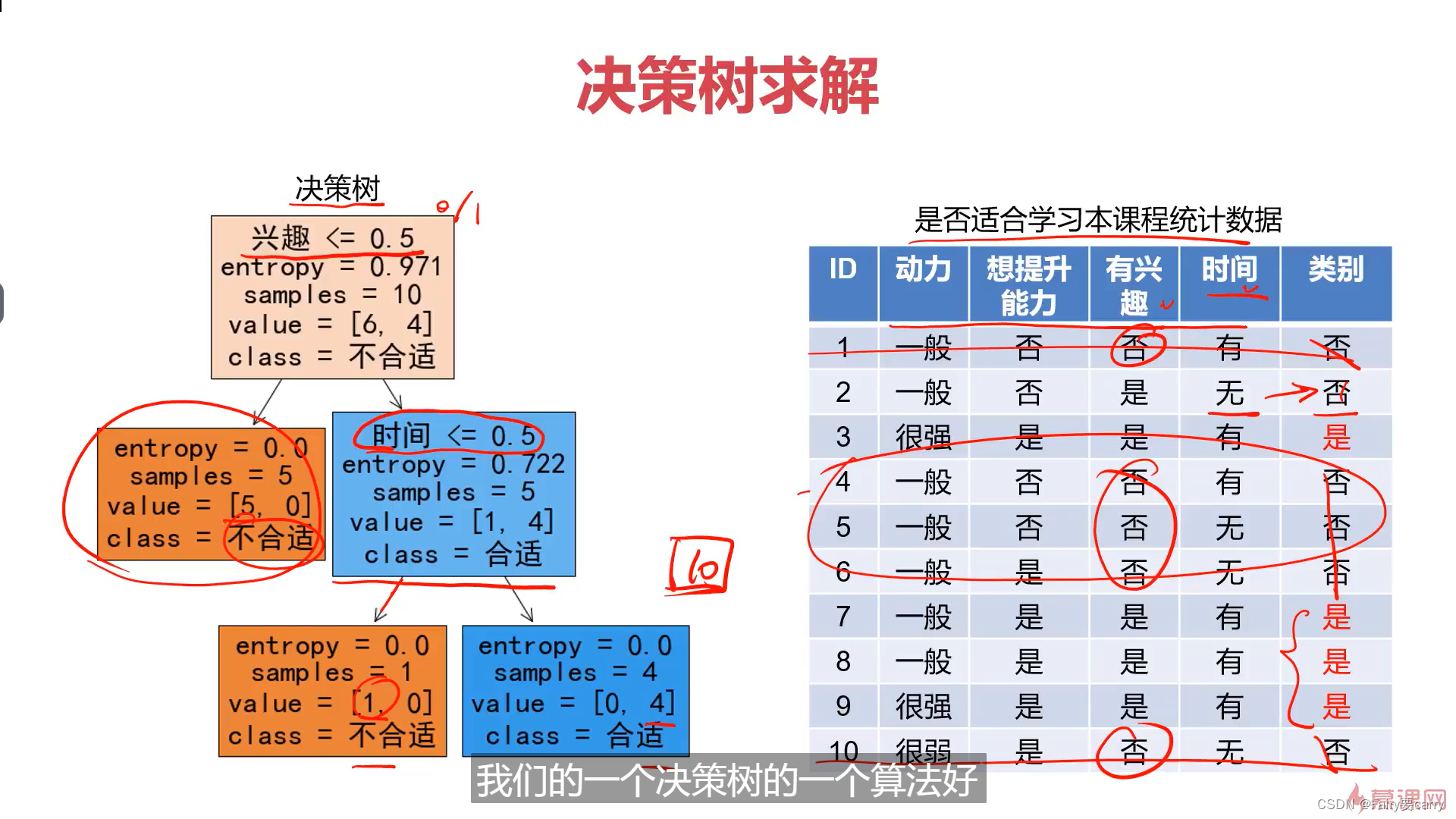
根据特征进行判断,不同特征决定了不同的决策树;
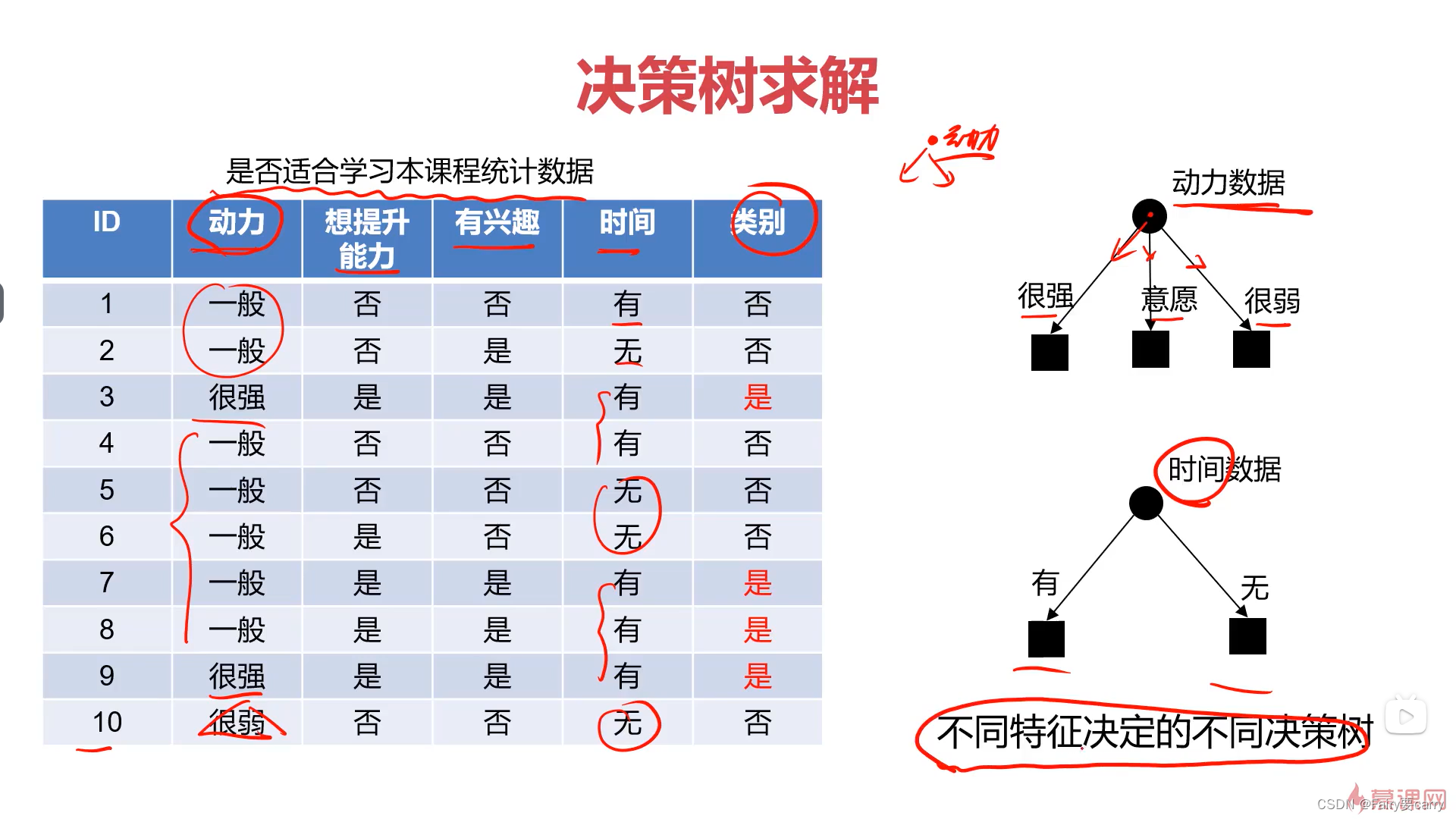
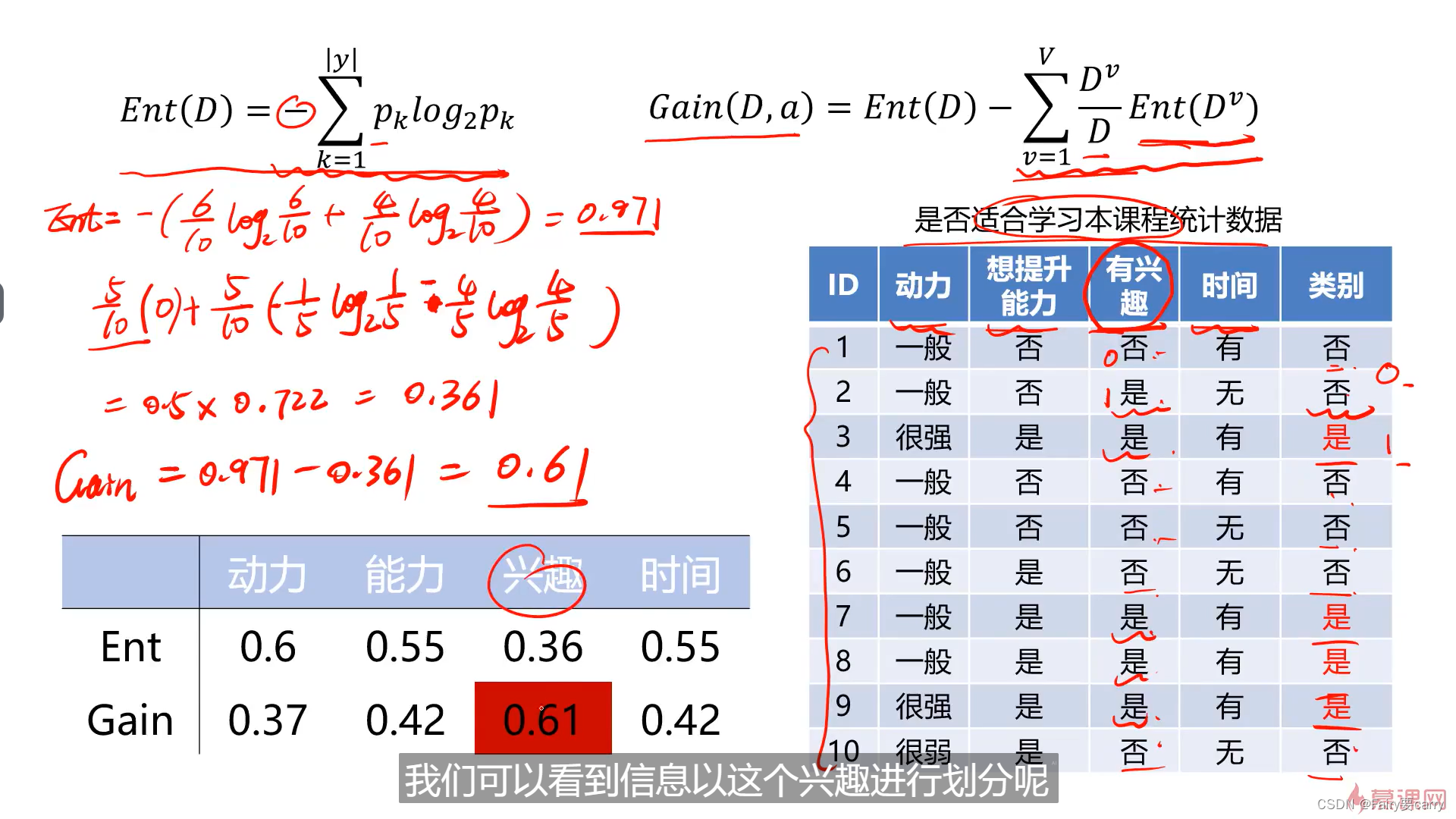
2.1 ID3算法的学习

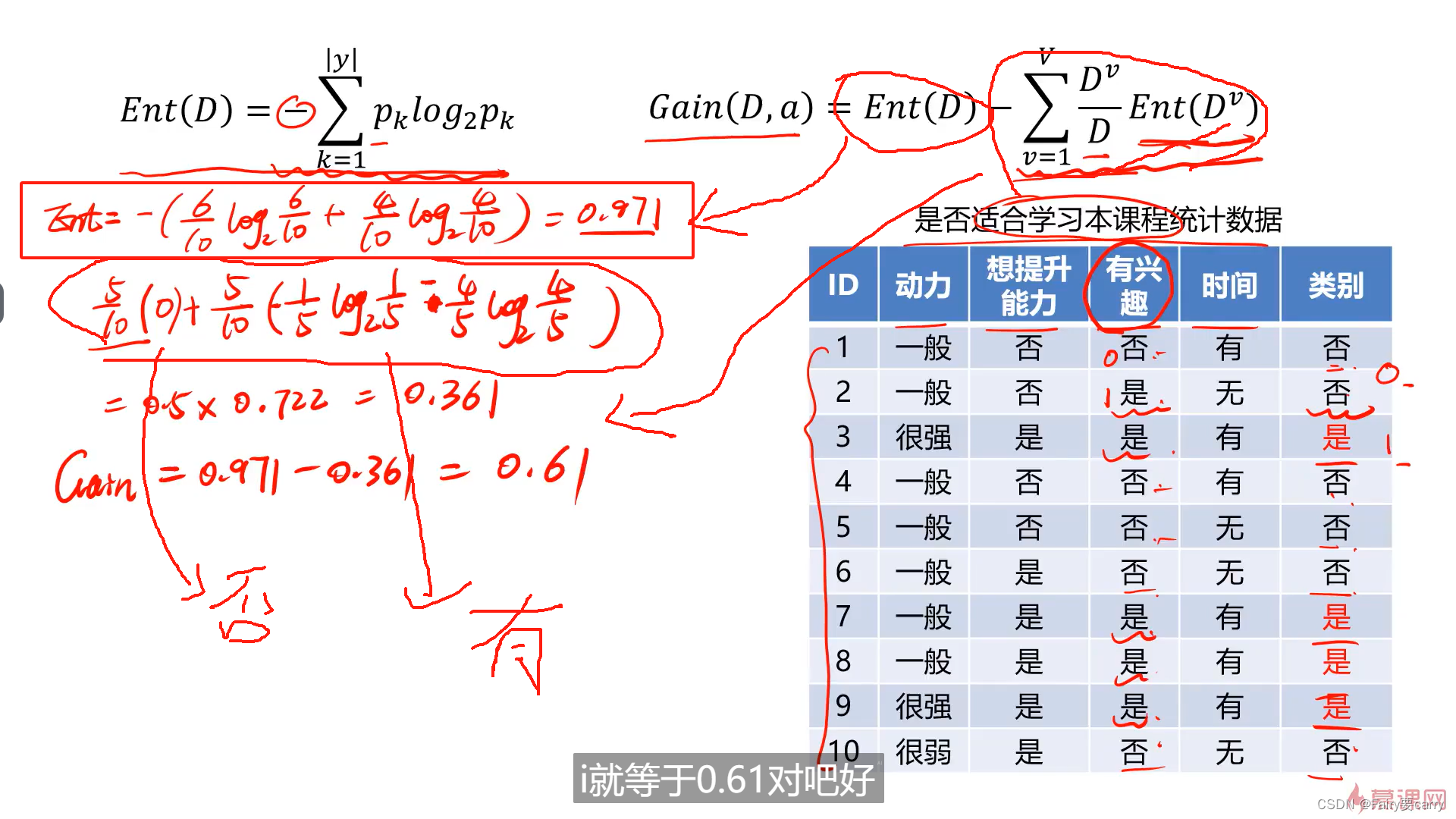
2.2 . 信息熵的概念:
1.决策树的难点在于找到最合适的属性作为我们所判断的信息
2.最合适的判断:在于信息熵,熵越大说明信息的不确定性就越大,而信息熵跟我们的信息增益是直接相关的,信息熵越小,信息增益就越大;

2.信息增益的概念:
信息熵尽可能小,那么我们Gain(D,a)所获取的信息增益就更大。
类别越少,Dv/D就越小,信息增益就越大

2.2 选择哪个属性作为我们的类别:
计算信息增益最大的属性作为我们的第一个节点:
决策树展示: