Python中的多线程、多进程、协程
一、概述
1. 多线程Thread (threading):
- 优点:同一个进程中可以启动多个线程,充分利用
IO时,cpu进行等待的时间 - 缺点:相对于进程,多线程只能并发执行,不能利用多
CPU,相对于协程,多线程的启动数目有限 ,占用内存资源,并且有线程切换的时间开销 - 使用场景:
IO密集型计算、同时运行的任务数据要求不多
2. 多进程Process(multiprocessing):
- 优点:可以利用多核
CPU进行并行计算 - 缺点:占用资源最多,可启动的数目比线程少
- 使用场景:
CPU密集型计算
3. 协程Coroutine(asyncio):
- 优点:内存开销最少、启动协程的数量最多
- 缺点:支持的库有限制 (
request对用的能使用协程的库为:aiohttp)、代码实现复杂 - 使用场景:
IO密集型计算、超多任务运行、有现成的库支持的场景
4. Python比C/C++/Java速度慢的原因:
Python是动态类型语言,边解释边执行。GIL,无法利用多核CPU并发 执行。
5. GIL
GIL名为:全局解释器锁(Global Interpreter Lock 缩写为: GIL),是计算机程序设计语言解释器用于同步线程的一种机制,它使得任何时刻仅有一个线程在执行,即便在多核心处理器上,使用GIL的解释器也只允许同一时刻执行一个线程。这是为了解决多线程之间数据完整性的状态同步问题。
6. 创建工具代码:
这个代码是一个基本的爬虫代码,创建这个代码的目的时为了下面实现多线程或多进程的时候让代码显的更加简洁,进而能更清晰的观察到多线程或多进程的实现方式。
utils.blog_spider.py
import requests
from bs4 import BeautifulSoup
urls = [
f'https://www.cnblogs.com/#p{page}'
for page in range(1, 50 + 1)
]
# 请求url,得到html
def craw(url):
r = requests.get(url)
# print(url, len(r.text))
return r.text
# 解析html
def parse(html):
soup = BeautifulSoup(html, "html.parser")
links = soup.find_all("a", class_="post-item-title")
return [(link['href'], link.get_text()) for link in links]
if __name__ == '__main__':
for restult in parse(craw(urls[2])):
print(restult)
二、多线程
1. 创建多线程的一般流程:
准备一个函数
def my_func(a, b): doing(a, b)创建一个线程
import threading # 导入线程包 t = threading.Threading(target=my_func, args=(100, 200)) # 第一个参数为一个函数名,第二个参数时传入函数的参数启动线程
t.start()等待结束
t.join()
代码示例:
# 多线程爬虫
import threading
import time
import utils.blog_spider as bg
def signal_thread():
for url in bg.urls:
bg.craw(url)
def multi_thread():
threads = []
for url in bg.urls:
threads.append(threading.Thread(target=bg.craw, args=(url,))) # 添加线程
for thread in threads:
thread.start()
for thread in threads:
thread.join()
if __name__ == '__main__':
start = time.time()
signal_thread()
end = time.time()
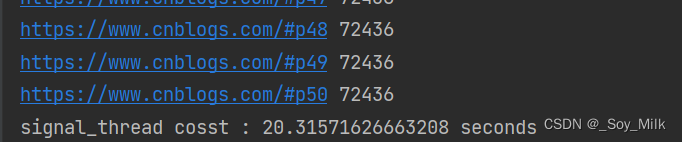
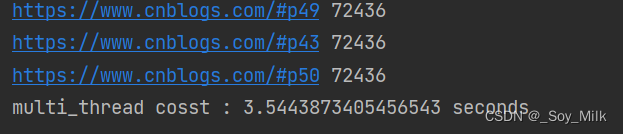
print("signal_thread cosst :", end - start, "seconds")
start = time.time()
multi_thread()
end = time.time()
print("multi_thread cosst :", end - start, "seconds")
输出结果:
2. 多线程之间的数据通信queue.Queue
queue.Queue可以用于多线程之间、线程安全的数据通信。
具体流程如下 :
导入队列库
import queue创建
Queueq = queue.Queue()添加元素
q.put(item)获取元素
item = q.get()查询状态
# 查看元素的多少 q.qsize() # 判断是否为空 q.empty() # 判断是否已满 q.full()
代码示例:
# 多线程数据通信
import queue
import utils.blog_spider as bg
import time
import random
import threading
def do_craw(url_queue: queue.Queue, html_queue: queue.Queue):
while True:
url = url_queue.get()
html = bg.craw(url)
html_queue.put(html) # 加入队列
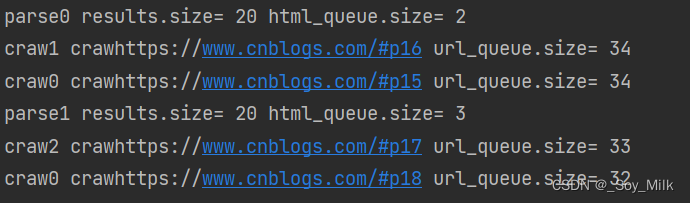
print(threading.current_thread().name, f"craw{url}", "url_queue.size=", url_queue.qsize())
time.sleep(random.randint(1, 2)) # 进行随机休眠
def do_parse(html_queue: queue.Queue, fout):
while True:
html = html_queue.get() # 从队列中取数据
results = bg.parse(html)
for result in results:
fout.write(str(result) + '\n')
print(threading.current_thread().name, "results.size=", len(results), "html_queue.size=", html_queue.qsize())
time.sleep(random.randint(1, 2))
if __name__ == '__main__':
url_queue = queue.Queue()
html_queue = queue.Queue()
for url in bg.urls:
url_queue.put(url)
for idx in range(3):
t = threading.Thread(target=do_craw, args=(url_queue, html_queue), name=f"craw{idx}")
t.start()
fout = open("data.txt", "w")
for idx in range(2):
t = threading.Thread(target=do_parse, args=(html_queue, fout), name=f"parse{idx}")
t.start()
3. 线程安全
由于线程的执行随时会切换,这会造成不可预料的结果,出现线程不安全的情况。
Lock用于解决线程安全问题,对线程进行加锁,这样会使得该线程运行结束之后在切换线程。
用法1:try-finally模式
import threading
lock = threading.Lock() # 设置线程锁
lock.acquire() # 获得锁
try:
# do something
finally:
lock.realse() # 释放锁
用法2:with模式
import threading
lock = threading.Lock()
with lock:
# do something
sleep语句一定会导致当前线程阻塞,会进行线程的切换(加锁则不会进行进程的切换)。
代码示例:
# 线程安全
import threading
import time
lock = threading.Lock()
class Account:
def __init__(self, balance):
self.balance = balance
def draw(account, amount):
with lock:
if account.balance >= amount:
time.sleep(0.1)
print(threading.current_thread().name, "取钱成功")
account.balance -= amount
print(threading.current_thread().name, "余额", account.balance)
else:
print(threading.current_thread().name, "取钱失败,余额不足")
if __name__ == '__main__':
account = Account(1000)
ta = threading.Thread(name="ta", target=draw, args=(account, 800))
tb = threading.Thread(name='tb', target=draw, args=(account, 800))
ta.start()
tb.start()

4. 线程池
线程池中有一些线程,新来的任务放在任务队列中,在线程池中的线程空闲的时候会自动处理任务队列里的任务。
使用线程池的好处:
- 提升性能
因为减去了大量新建、终止线程的开销,重用了线程资源;- 使用场景
适合处理突发性大量请求或需要大量线程完成任务,但实际任务处理时间较短。- 防御功能
能有效避免系统因为创建线程过多,而导致系统负荷过大相应变慢的问题。- 代码优势
使用线程池的语法比自己新建线程执行线程更加简洁。
使用方法:
-
用法1:
map函数,注意map的结果和入参是顺序对应的。from concurrent.futures import ThreadPoolExecutor, as_completed with ThreadPoolExecutor() as pool: results = pool.map(craw, urls) for result in results: print(result) -
用法2:
future模式更强大,注意如果用as_complete方法,这样的线程执行顺序是不固定的,但是相应的效率会更高。(as_completed方法是不管哪个线程先执行完了,都会直接返回,不用按照顺序返回)with ThreadPoolExecutor() as pool: futures = [pool.submit(craw, url) for url in urls] for future in futures: print(future.result()) for future in as_complated(futures): print(future.result())
代码示例:
import concurrent.futures
import utils.blog_spider as bg
# 进行爬取html
with concurrent.futures.ThreadPoolExecutor() as pool:
htmls = pool.map(bg.craw, bg.urls) # 加入线程池
htmls = list(zip(bg.urls, htmls))
for url, html in htmls:
print(url, len(html))
print("craw over")
# 进行解析html
with concurrent.futures.ThreadPoolExecutor() as pool:
futures = {}
for url, html in htmls:
future = pool.submit(bg.parse, html) # 加入线程池
futures[future] = url
for future, url in futures.items():
print(url, future.result())
# 顺序不定
# for future in concurrent.futures.as_completed(futures):
# url = futures[future]
# print(url, future.result())
三、多进程
CPU密集型计算线程的自动的切换反而变成了负担,多线程甚至减慢了运行速度。multiprocessing模块就是Python为了解决GIL缺陷引入的一个模块,原理是用多进程在多CPU上并行执行。
多进程multiprocessing知识梳理(对比多线程threading)
多线程:
-
引入模块
from threading import Thread -
新建
t = Thread(target=func, args=(100, )) -
启动
t.start() -
等待结束
t.join() -
数据通信
import queue q = queue.Queue() q.put(item) item = q.get() -
线程安全加锁
from threading import Lock lock = Lock() with lock: # do something -
池化技术
from concurrent.futures import ThreadPoolExecutor with ThreadPoolExecutor() as executor: # 方法1 results = executor.map(func, [1, 2, 3]) # 方法2 future = executor.submit(func, 1) result = future.result()
多进程:
-
引入模块:
from multiprocessing import Process -
新建
p = process(target=f, args=('bob', )) -
启动
p.start() -
等待结束
p.join() -
数据通信
from multiprocessing import Queue q = Queue() q.put([42, None, 'hello']) item = q.get() -
线程安全加锁
from multiprocessing import Lock lock = Lock() with lock: # do something -
池化技术
from concurrent.futures import ProcessPoolExecutor with ProcessPoolExecutor() as executor: # 方法1: results = executor.map(func, [1, 2, 3]) # 方法2: future = executor.submit(func, 1) result = funture.result()
代码示例:
import math
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor # 导入线程池与进程池
import time
PRIMES = [112272535095293] * 100
def is_prime(n):
'''
判断一个数是否是素数
:param n:
:return:
'''
if n < 2:
return False
if n == 2:
return True
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
def signal_thread():
'''
单线程
:return:
'''
for number in PRIMES:
is_prime(number)
def multi_thread():
'''
多线程
:return:
'''
with ThreadPoolExecutor() as pool:
pool.map(is_prime, PRIMES)
def multi_process():
'''
多进程
:return:
'''
with ProcessPoolExecutor() as pool:
pool.map(is_prime, PRIMES)
if __name__ == '__main__':
start = time.time()
signal_thread()
end = time.time()
print("signal_thread, cost:", end - start, "seconds")
start = time.time()
multi_thread()
end = time.time()
print("multi_thread, cost:", end - start, "seconds")
start = time.time()
multi_process()
end = time.time()
print("multi_process, cost:", end - start, "seconds")
输出结果:

四、协程
协程是在单线程内实现并发
- 核心原理:用一个超级循环(其实就是
while Treu)循环 - 配合
IO多路复用原理(IO时CPU可以干其他事情)
异步IO库介绍:asyncio
1. 创建协程的一般流程:
导入库
import asyncio获取事件循环
loop = asyncio.get_enent_loop()定义协程
async def myfunc(url): await get_url(url)创建
task任务列表task = [loop.create_task(myfunc(url)) for url in urls]执行爬虫事件列表
loop.run_until_complete(asyncio.wait(tasks))
注意:要用在异步IO编程中,依赖的库必须支持异步IO特性,爬虫引用中:requests不支持异步,需要用aiohttp
代码示例:
import asyncio
import aiohttp
import utils.blog_spider as bg # 该模块是工具代码中的模块
import time
async def async_craw(url):
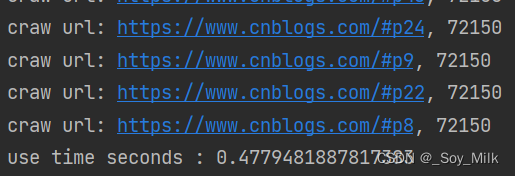
print("craw url:", url)
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
result = await resp.text()
print(f"craw url: {url}, {len(result)}")
loop = asyncio.get_event_loop()
tasks = [loop.create_task(async_craw(url=url)) # 添加任务
for url in bg.urls]
start = time.time()
loop.run_until_complete(asyncio.wait(tasks)) # 启动协程
end = time.time()
print("use time seconds :", end - start)
2. 控制协程的并发度
可以使用信号量(semaphore)来控制并发度
实现方式1:
sem = asyncio.Semaphore(10)
# later
async with sem:
# work with shared resource
实现方式2:
sem = asyncio.Semaphore(10)
# later
await sem.acquire()
try:
# work with shared resource
finally:
sem.release()