一、简介
什么是HDFS的Shell操作?
很简单,就是在Linux的终端,通过命令来操作HDFS。
如果,你们学习过git、docker、k8s,应该会发现,这些命令的特点和shell命令非常相似
二、常用命令
1、准备工作相关命令
启动集群
sbin/start-dfs.sh
sbin/start-yarn.sh
查看命令帮助
hadoop fs -help rm
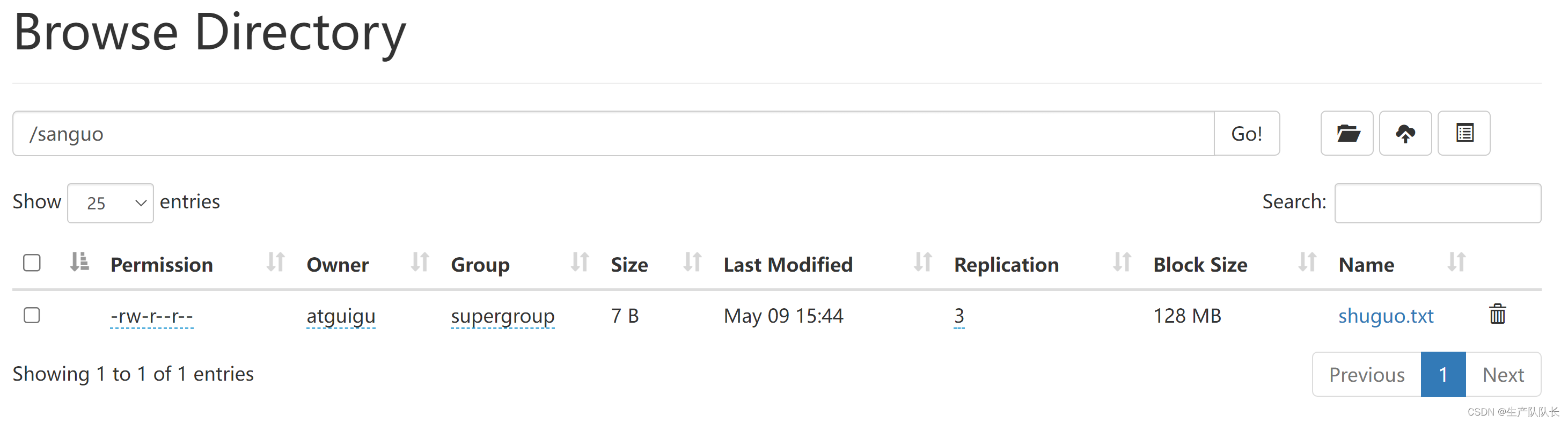
创建/sanguo文件夹
hadoop fs -mkdir /sanguo
2、上传
1、-moveFromLocal:从本地剪切粘贴到HDFS
hadoop fs -moveFromLocal ./shuguo.txt /sanguo

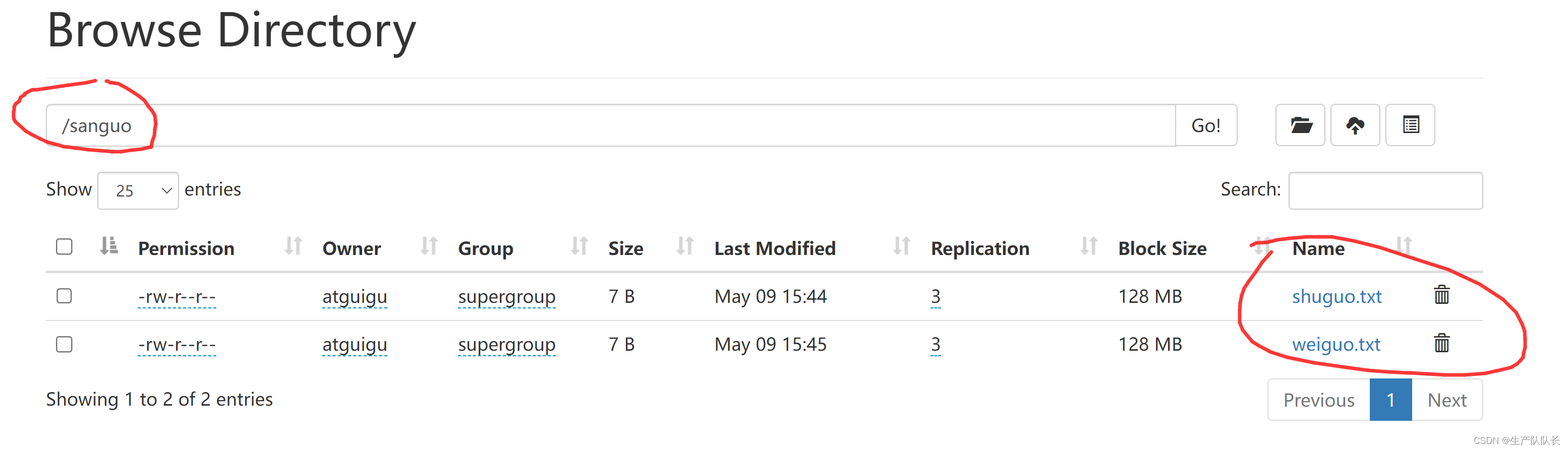
2、-copyFromLocal:从本地拷贝文件到HDFS指定路径中
hadoop fs -copyFromLocal ./weiguo.txt /sanguo

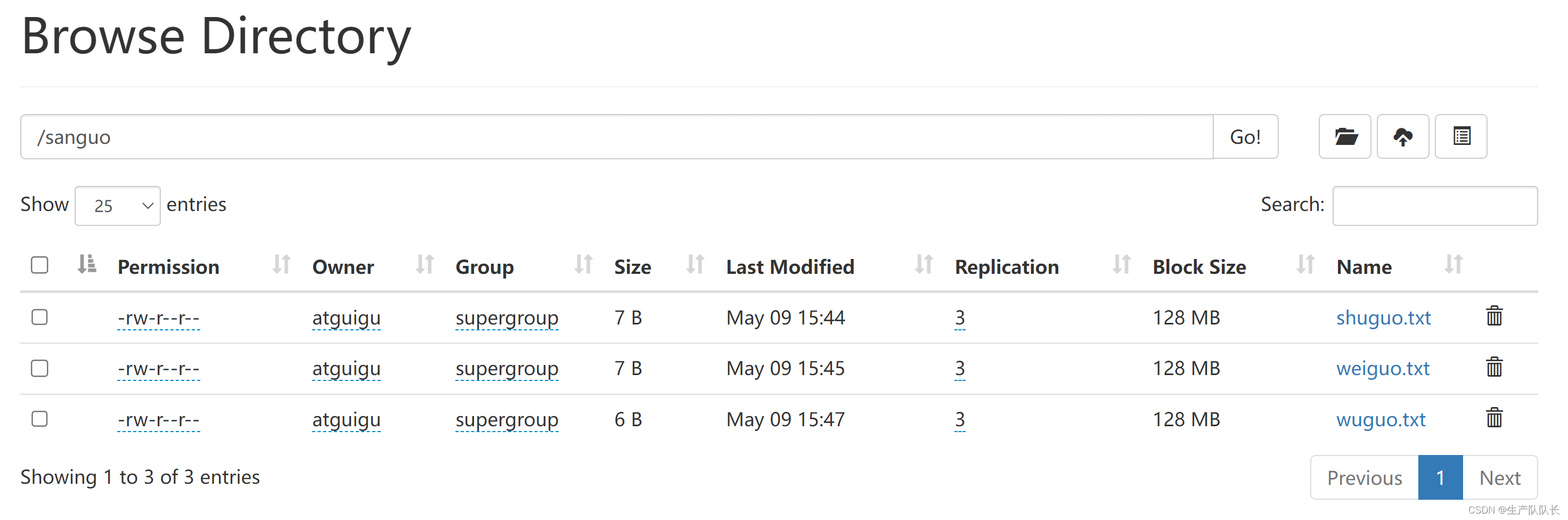
3、-put:等同于 copyFromLocal,生产环境更习惯用 put
hadoop fs -put ./wuguo.txt /sanguo

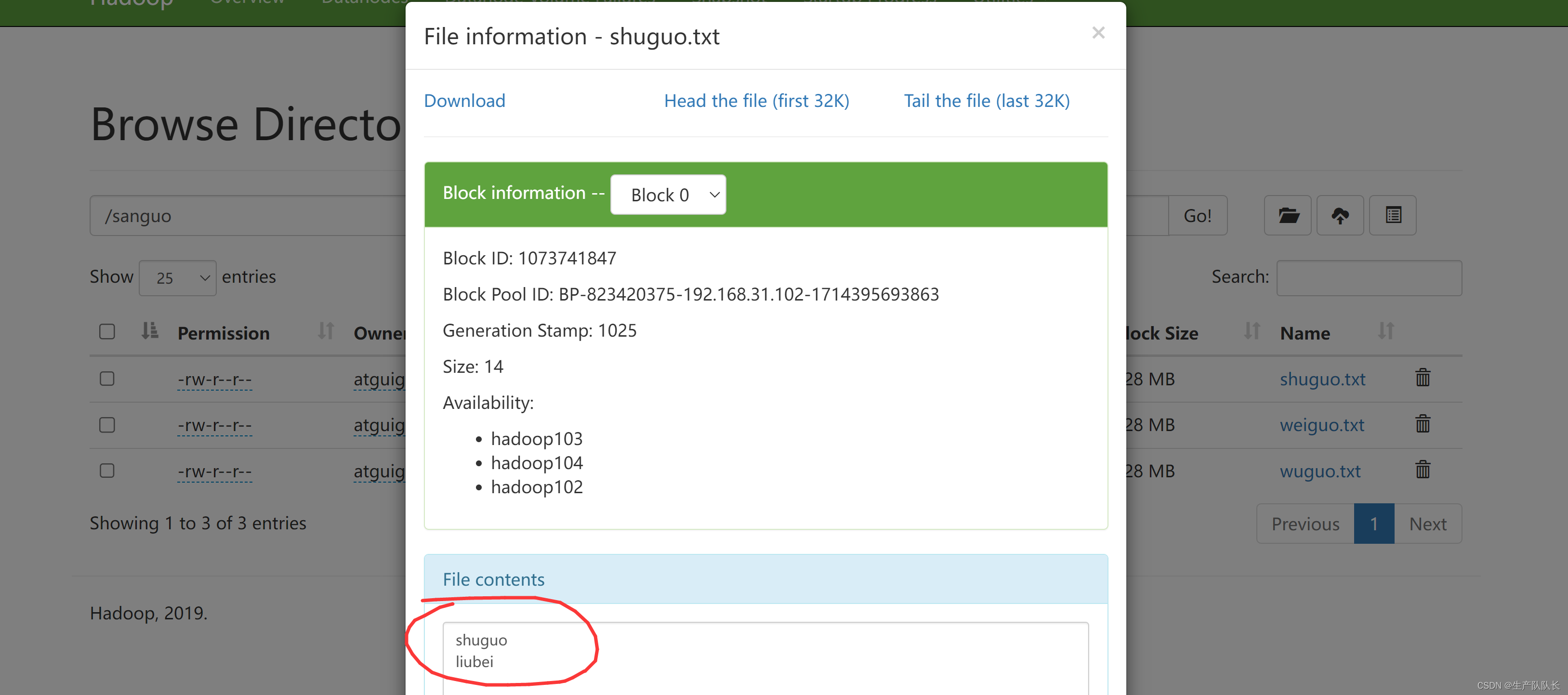
4、-appendToFile:追加一个文件中的内容到HDFS中已经存在的文件末尾
hadoop fs -appendToFile liubei.txt /sanguo/shuguo.txt

注意
此命令可能遇到的错误
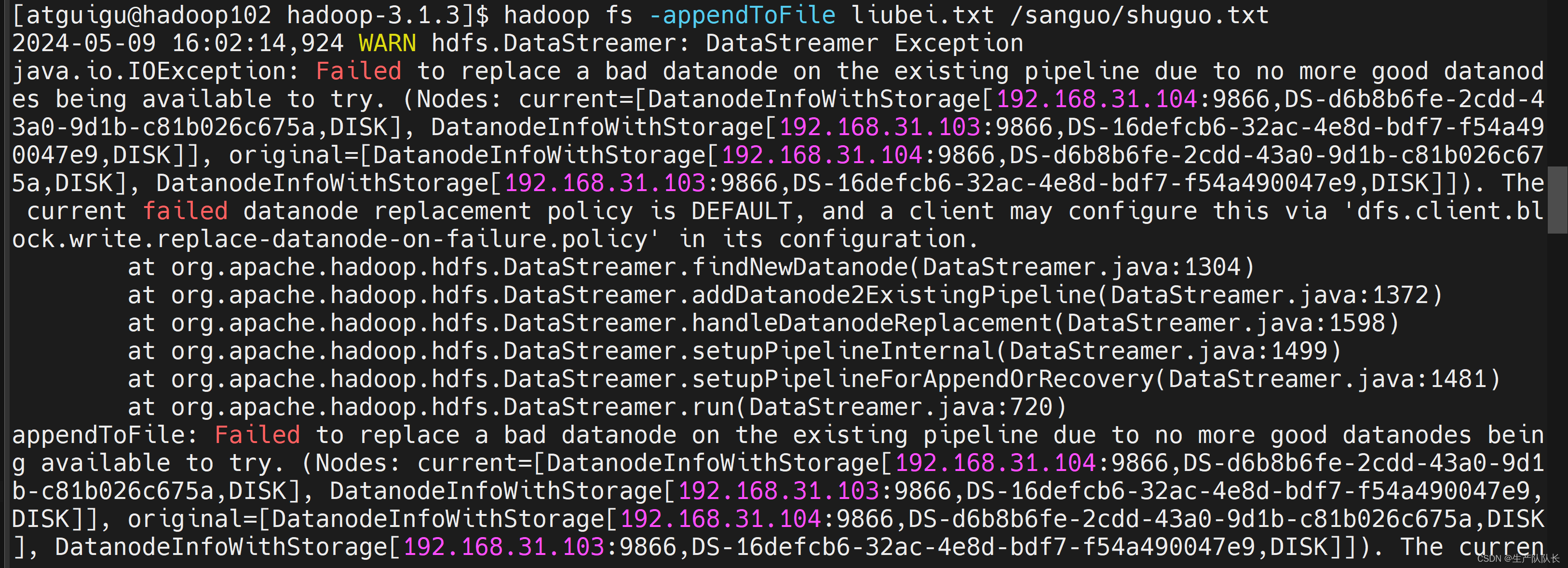
解决办法
在hdfs-site.xml文件中添加如下配置,重启Hadoop集群即可
<property>
<name>dfs.client.block.write.replace-datanode-on-failure.policy</name>
<value>NEVER</value>
</property>
参考:Hadoop的append命令报错的解决办法
3、下载
1、-copyToLocal:从HDFS拷贝到本地
hadoop fs -copyToLocal /sanguo/shuguo.txt ./

2、-get:等同于 copyToLocal,生产环境更习惯用 get
hadoop fs -get /sanguo/shuguo.txt ./shuguo2.txt

4、文件的常用操作
1、-ls: 显示目录信息
hadoop fs -ls /sanguo

2、-cat:显示文件内容
hadoop fs -cat /sanguo/shuguo.txt

3、-chgrp、 -chmod、 -chown :同Linux文件系统中的用法一样,修改文件所属权限
hadoop fs -chmod 777 /sanguo/shuguo.txt
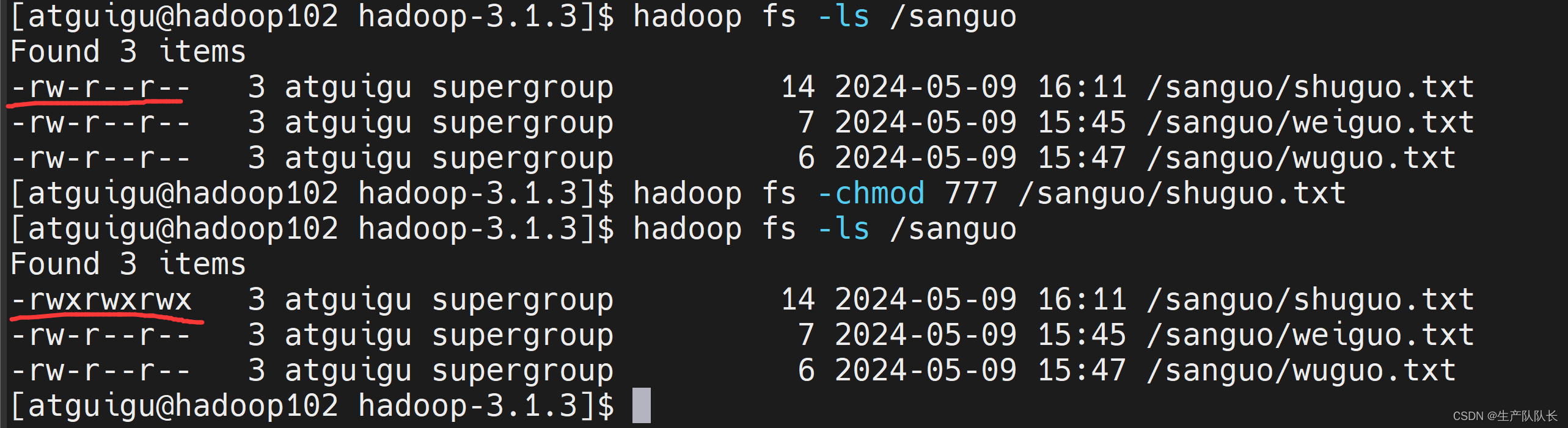
4、-mkdir:创建路径
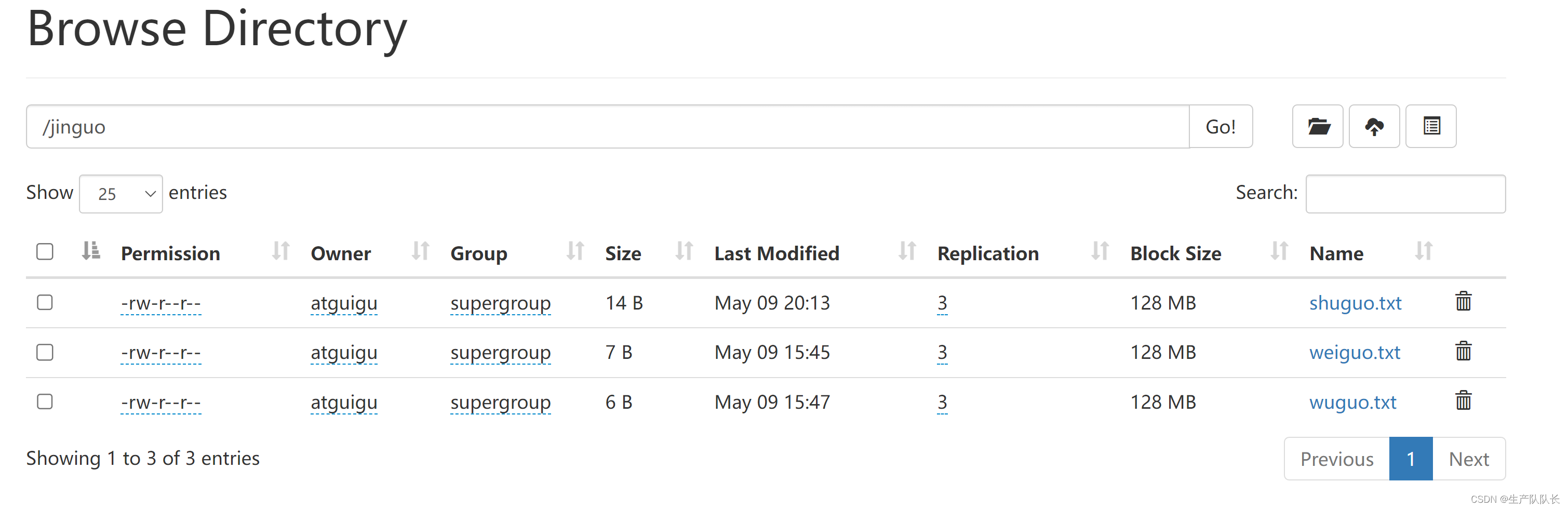
hadoop fs -mkdir /jinguo
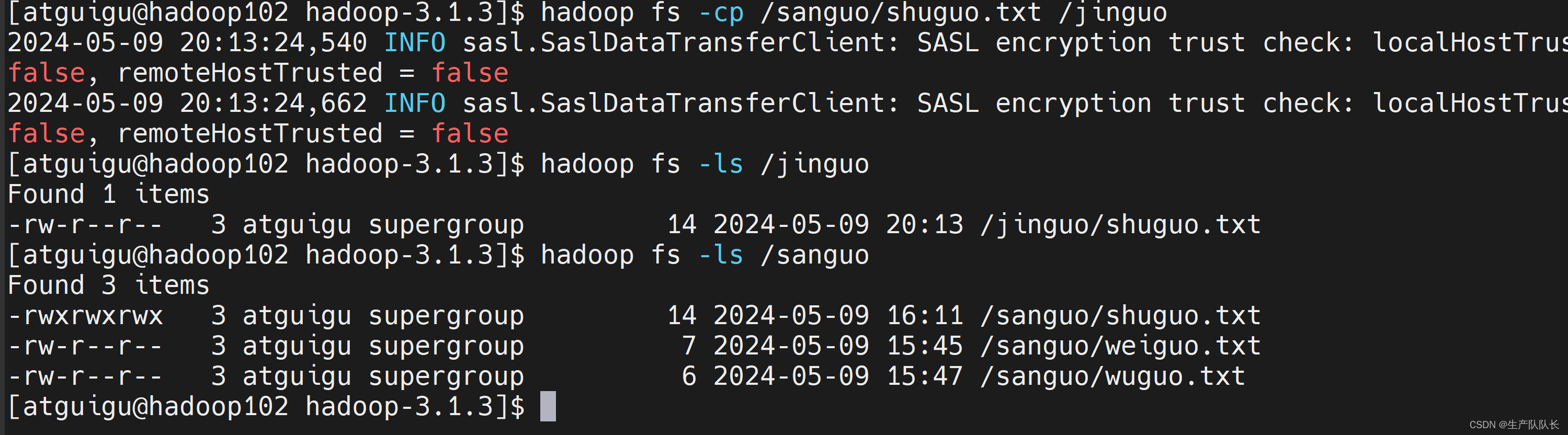
5、-cp:从HDFS的一个路径拷贝到HDFS的另一个路径
hadoop fs -cp /sanguo/shuguo.txt /jinguo
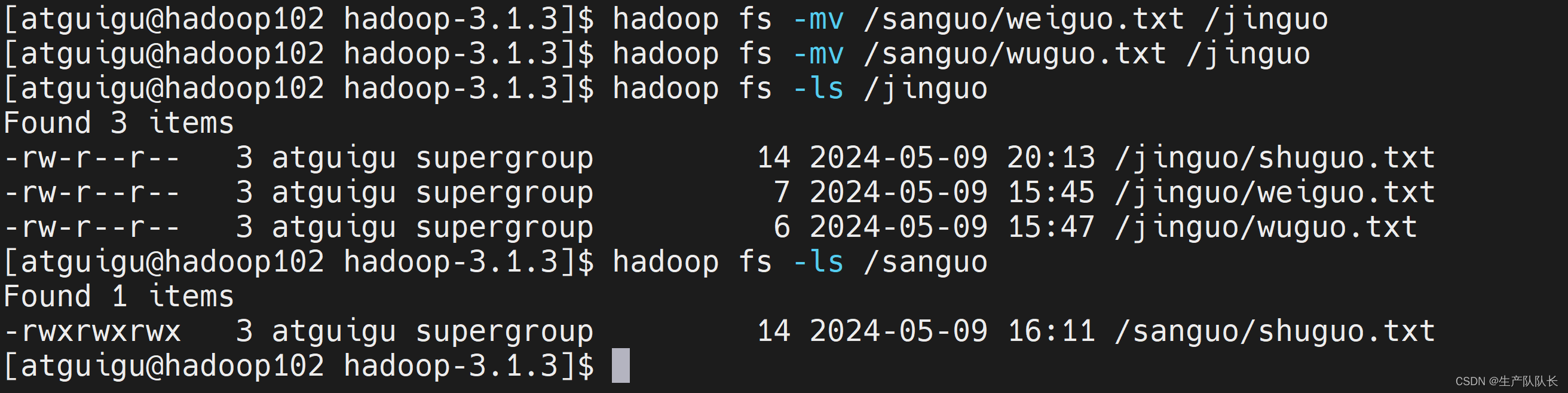
6、-mv:在HDFS目录中移动(剪切)文件
hadoop fs -mv /sanguo/weiguo.txt /jinguo
7、-tail:显示一个文件的末尾1kb的数据
hadoop fs -tail /jinguo/shuguo.txt

8、-rm:删除文件或文件夹
hadoop fs -rm /sanguo/shuguo.txt

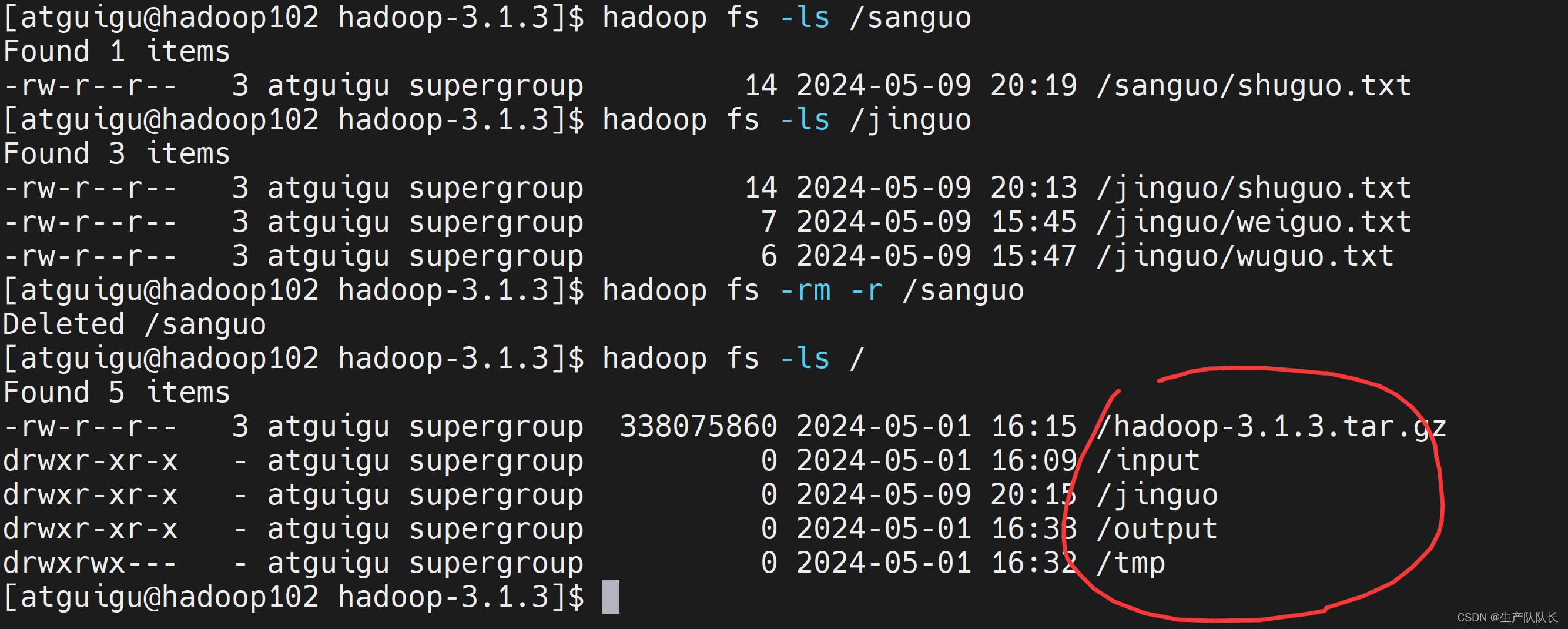
9、-rm -r 递归删除目录及目录里面的文件
hadoop fs -rm -r /sanguo
10、-du统计文件夹的大小信息
hadoop fs -du -s -h /jinguo
hadoop fs -du -h /jinguo

说明: 27表示一个节点上文件大小;81表示27*3个副本的总大小;/jinguo表示查看的目录
11、-setrep:设置HDFS中文件的副本数量
hadoop fs -setrep 10 /jinguo/shuguo.txt

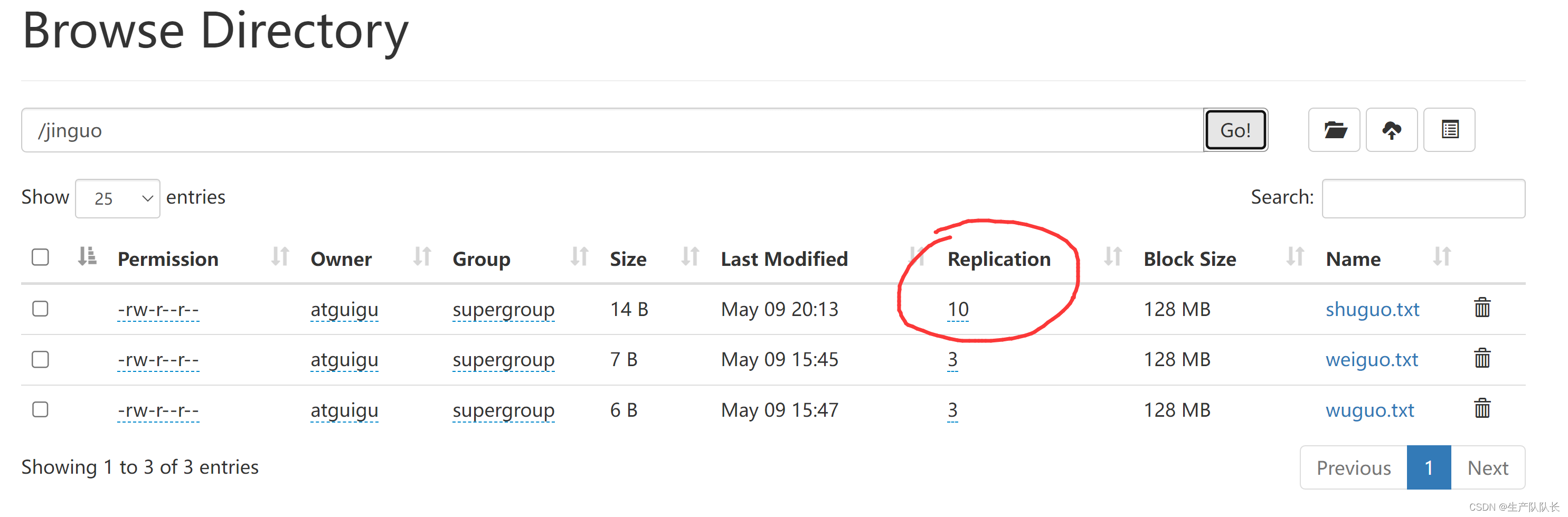
这里设置的副本数只是记录在NameNode的元数据中,是否真的会有这么多副本,还得看DataNode的数量。因为目前只有 3台 设备,最多也就 3个 副本,只有节点数的增加到10台时副本数才能达到10个,当然,节点数超过10个,副本数也只能是10个。