背景
想钻研一下项目组件,找找之后的学习方向。不能自以为是,所以借着网开源项目网站上公布的项目内容看一下,那些是我可以努力去学习的(入门的)。首先需要获取相关内容,于是爬取整理。
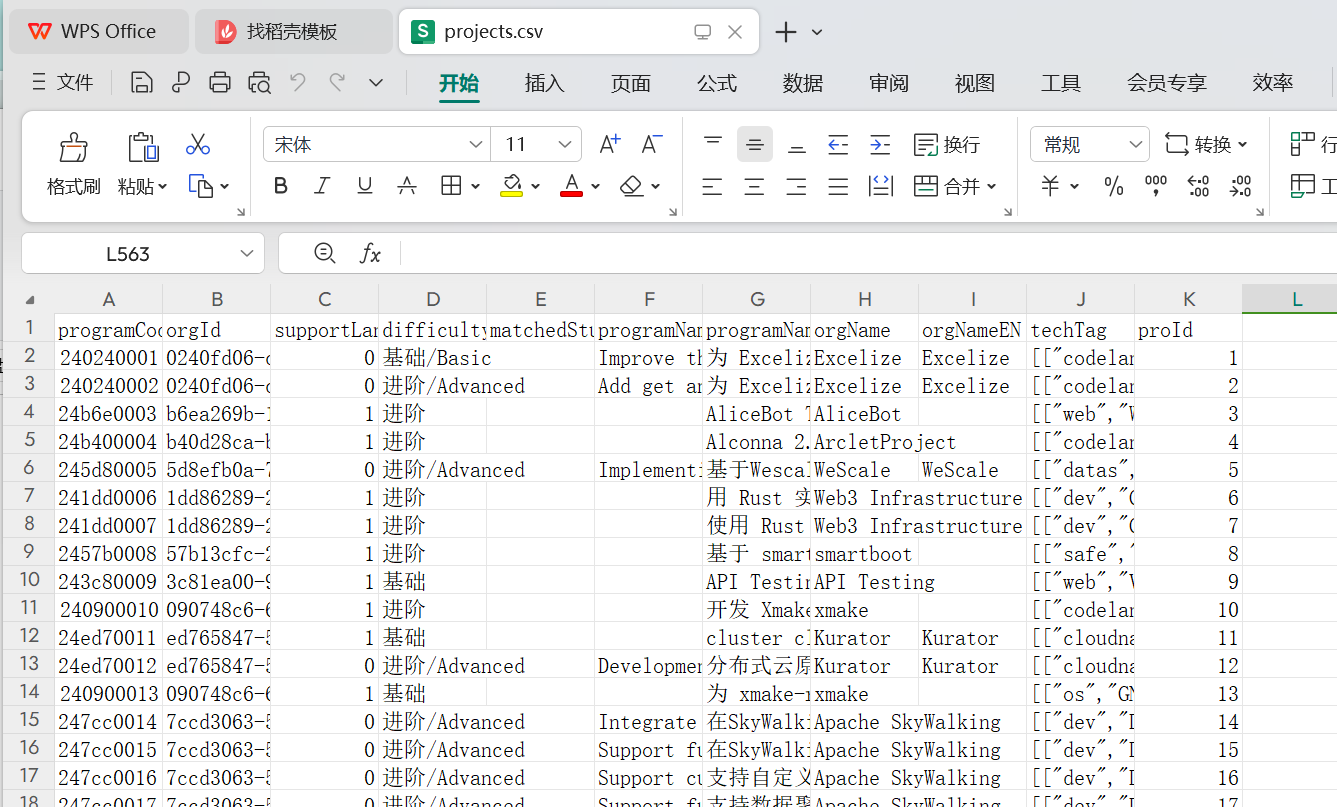
任务1:爬一个项目网站上的项目列表。
展示
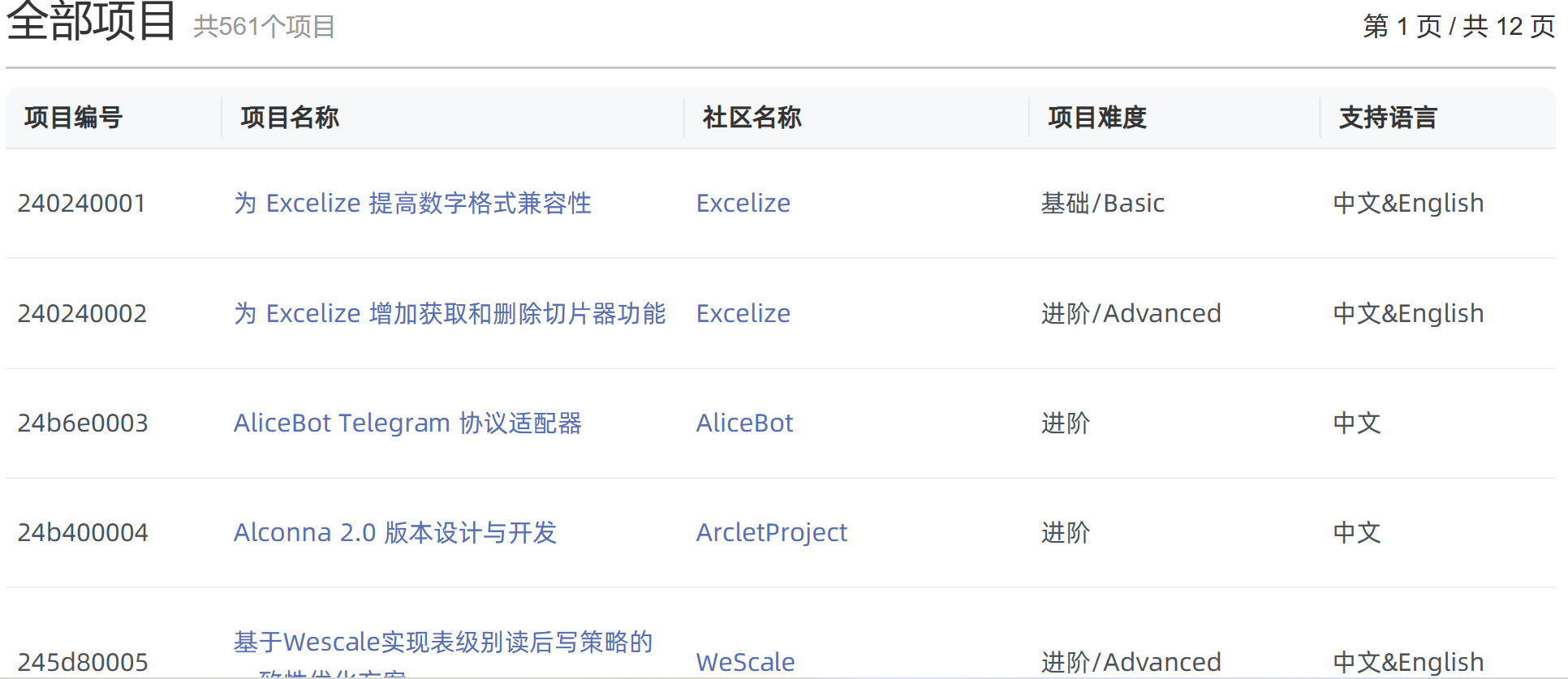
过程:
-
开始是想着借助kimi chat去解析前端页面然后编写代码,但是发现生成的代码,总是跑不起来。
-
去b站上学习了一下。gpt辅助爬虫
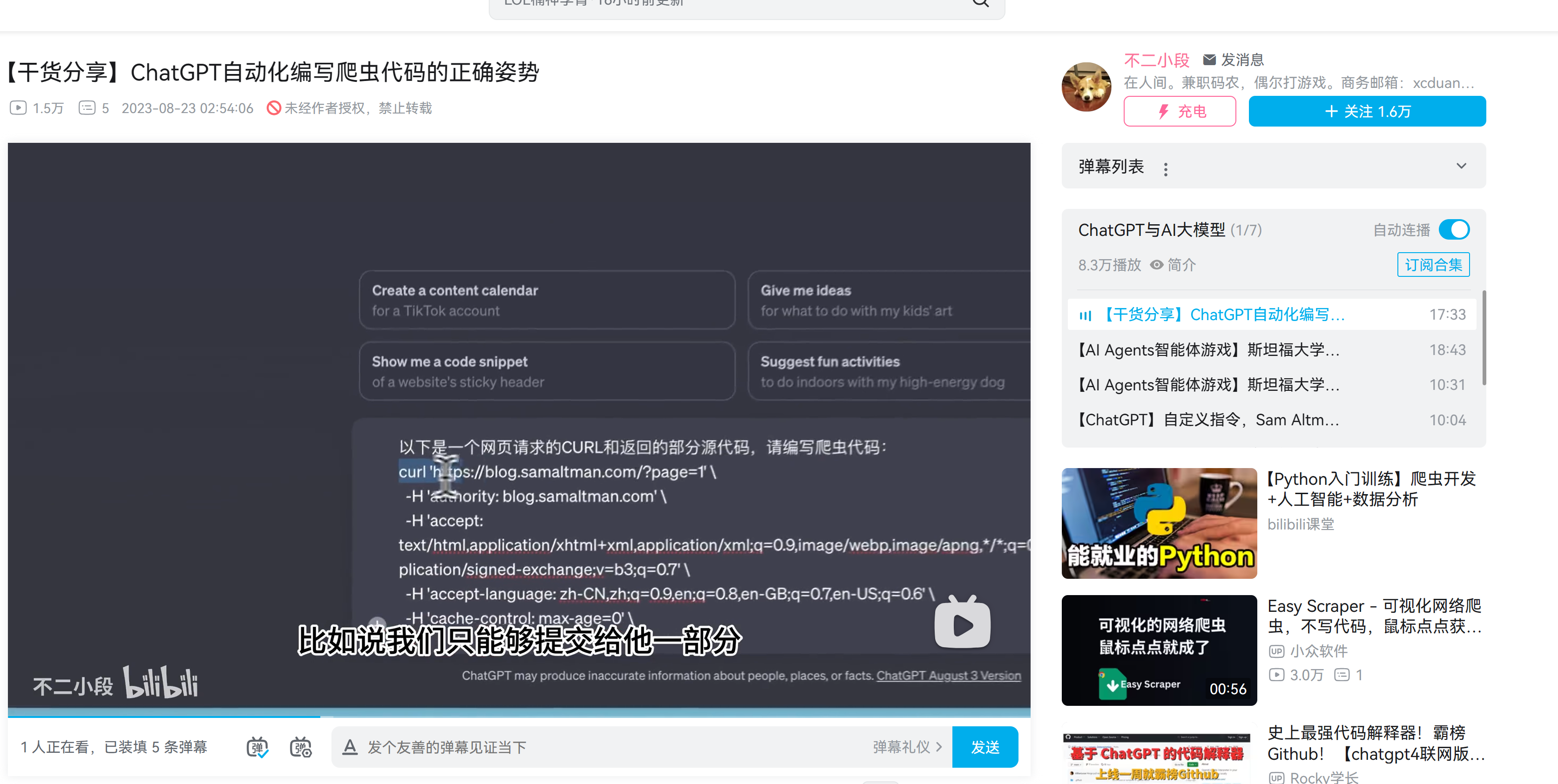
- curl(包含所有信息,header啥的) 和 har(所有操作记录)
- 还了解到一个curl convert
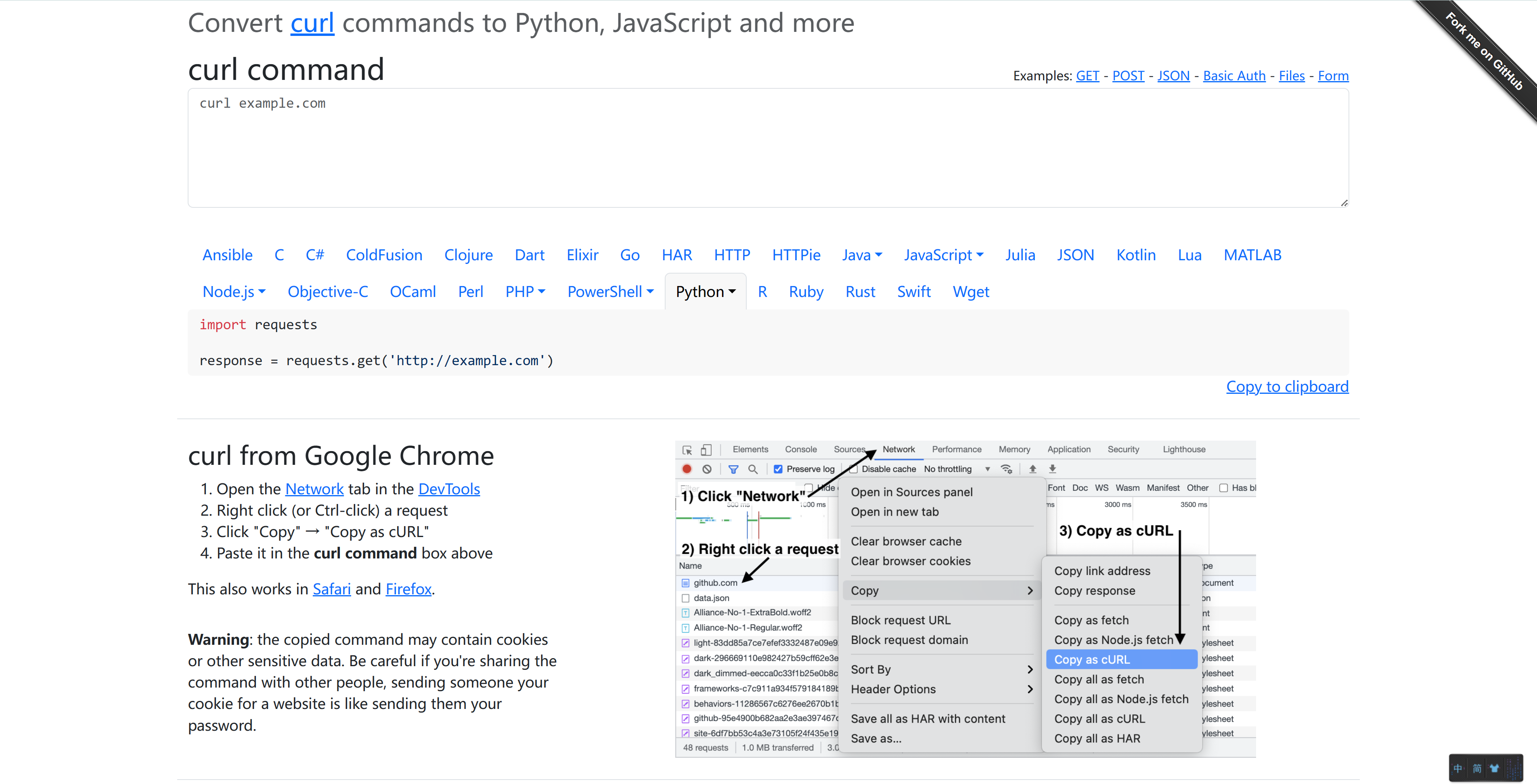
- 看到评论区,选择直接
- 复制粘贴完整的curl指令,
- 喂给kimi chat(不登录网站没有cookie的话,请求访问就是空。)
- 进一步的需求
- 出现报错,给他说一下

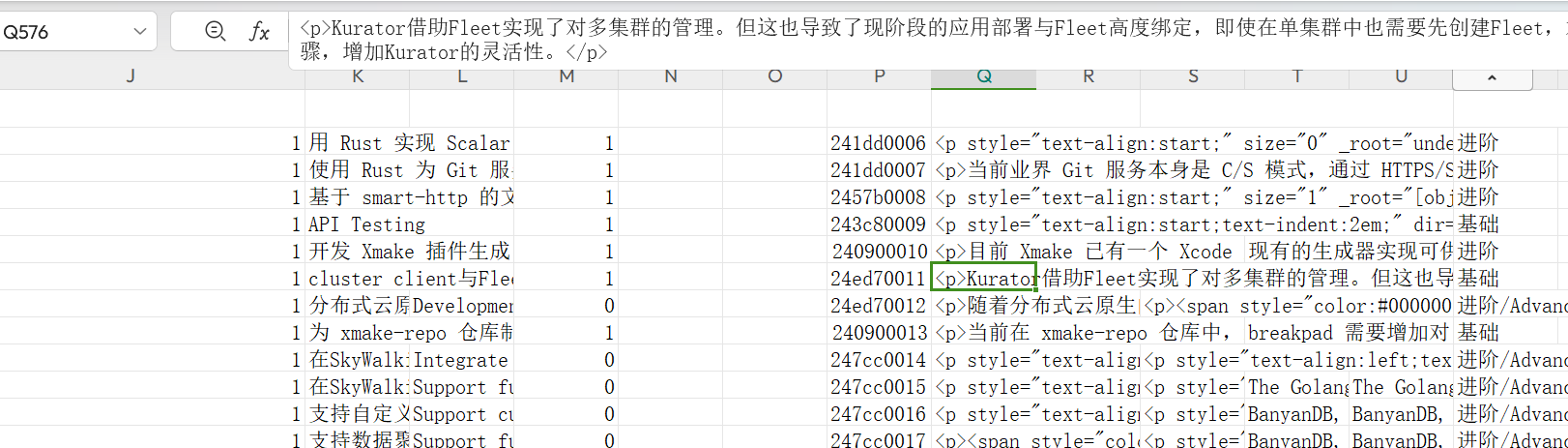
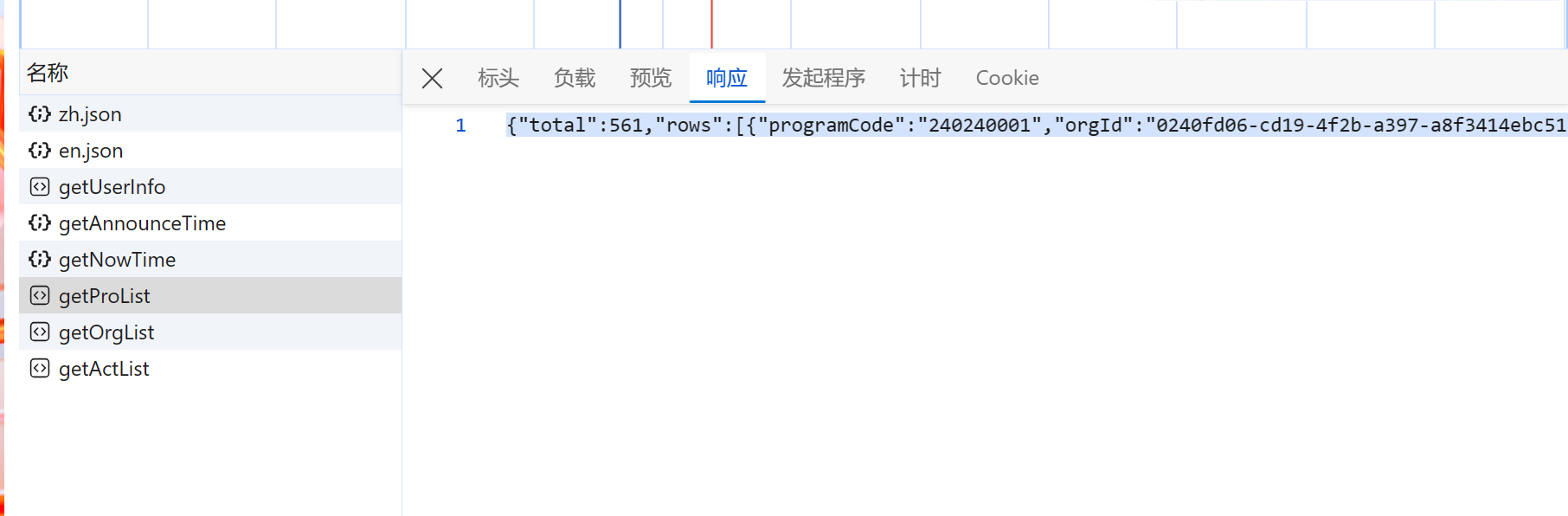
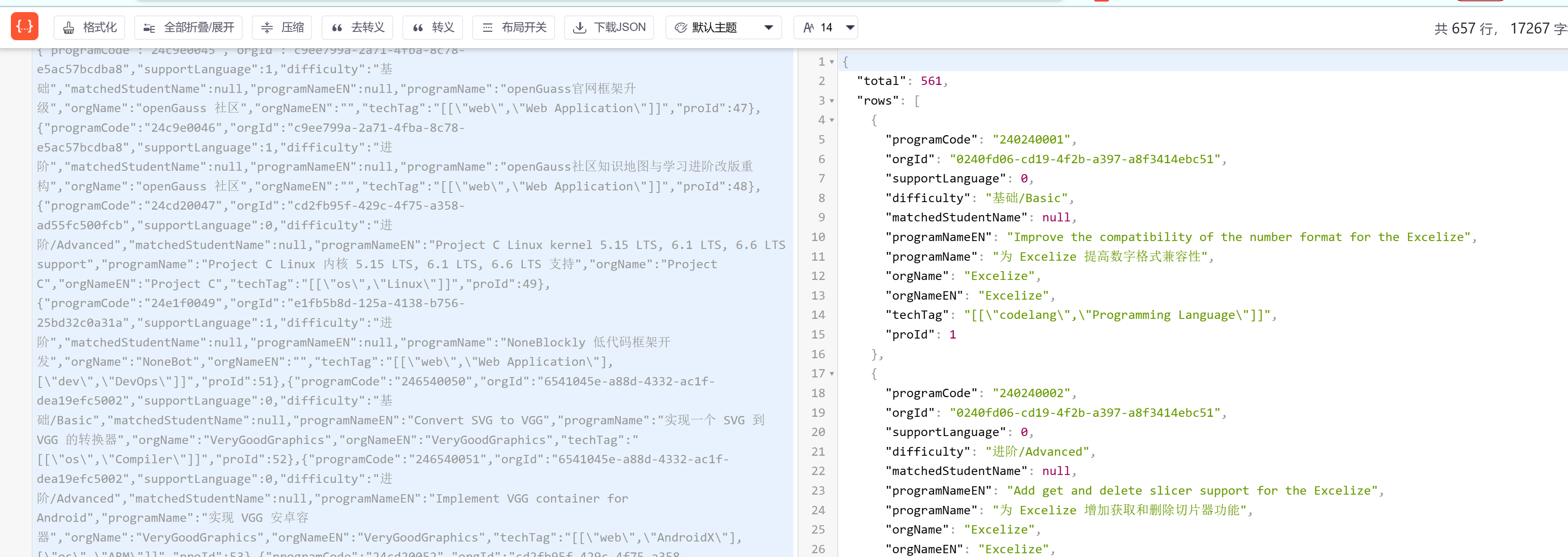
- 爬取效果
任务2:补充项目详情
内容展示
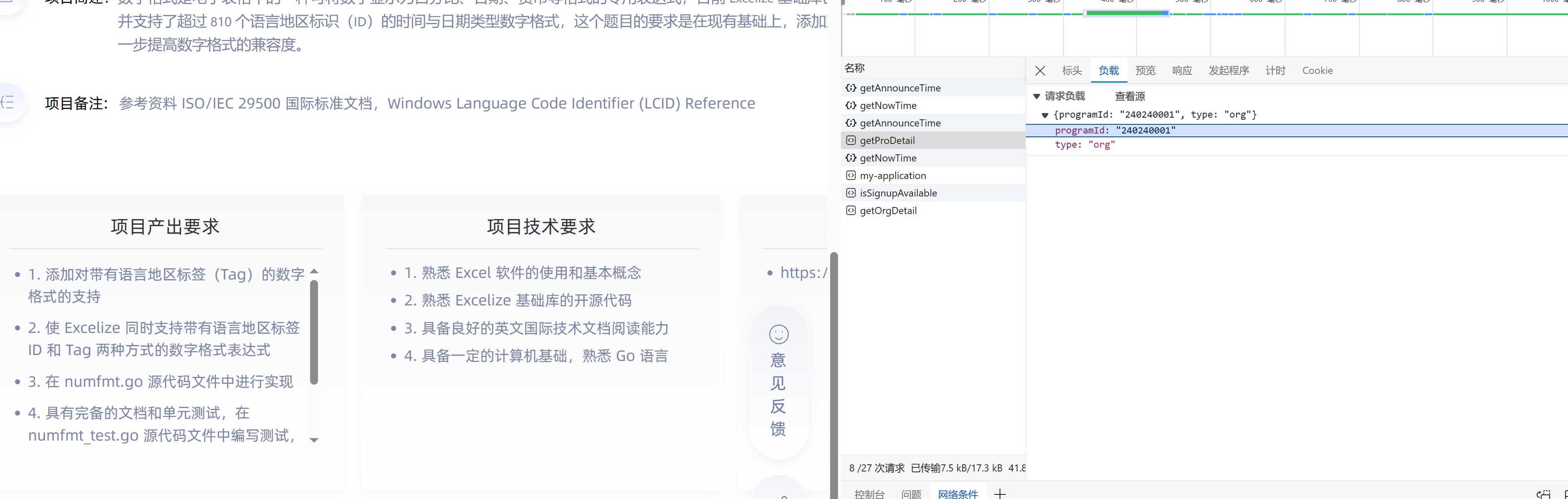
过程
那这个和上面,过程大同(爬取请求)小异(从之前的csv文件中读取 项目ID,然后请求)
- 粘贴curl请求
- 突然想到我这样的请求是不是要加个间隔,要不 算什么恶意访问。
import time
time.sleep(0.5) # 休眠500毫秒
- 效果如下