2024年5月4日
问题来源
解决方案



 回顾2023年7月14日自己写的爬虫代码
回顾2023年7月14日自己写的爬虫代码
import requests
import re
import pandas as pd
texts=[]
def getData(page):
#每页评论的网址
url='https://item.jd.com/51963318622.html#comment'
#添加headers,伪装成浏览器
headers={'User-Agent':''}
#获取响应信息
response=requests.get(url,headers)
page_text=response.text
#通过requests获得了网页的源代码,就可以对源代码字符串使用正则表达式来提取文本信息
#定义正则,获取商品信息,py的正则表达式模块为re(regular expression)
ex='"guid":.*?,"content":"(.*?)"'
result=re.findall(ex,page_text)
#把获取到的评论放入之前创建的空列表中
texts.extend(result)
#创建一个空的数据表,保存成excel
df=pd.DataFrame()
#导入数据到excel并保存
df['评论']=texts
df.to_excel('京东商品评论.xlsx')
#爬第一页和第二页,重复执行主函数中的gatData函数
if __name__=="_main_":
for i in range(0,3):
getData(i)数据处理(设计器和python )基本都会遇到的知识点:(实训笔记)
1.循环:设计器:计次循环=for i in range(在计次之前需要设置一个变量)
2.变量
通过re和??进行数据解析,解析的方法是正则表达式
正则表达式会隐藏在文件中的对应请求中
respons就是一个字典,根据键获取对应的值
写入excel或者数据库,
创建游标的方式执行SQL语句,就是insert INto、、插入
尝试根据去年的代码实现小行星数据抓取:BS4-
Beautiful Soup4是Python第三方库,用来从HTML和XML中提取数据
from bs4 import BeautifulSoup
#解析源代码生成BeautifulSoup对象:
soup=BeautifulSoup(网页源代码,'解析器')
#eg: soup=BeautifulSoup(source,'html.parser')
# soup=BeautifulSoup(source,'lxml')查找内容
info=soup.find(class='test')plus:HTML基础
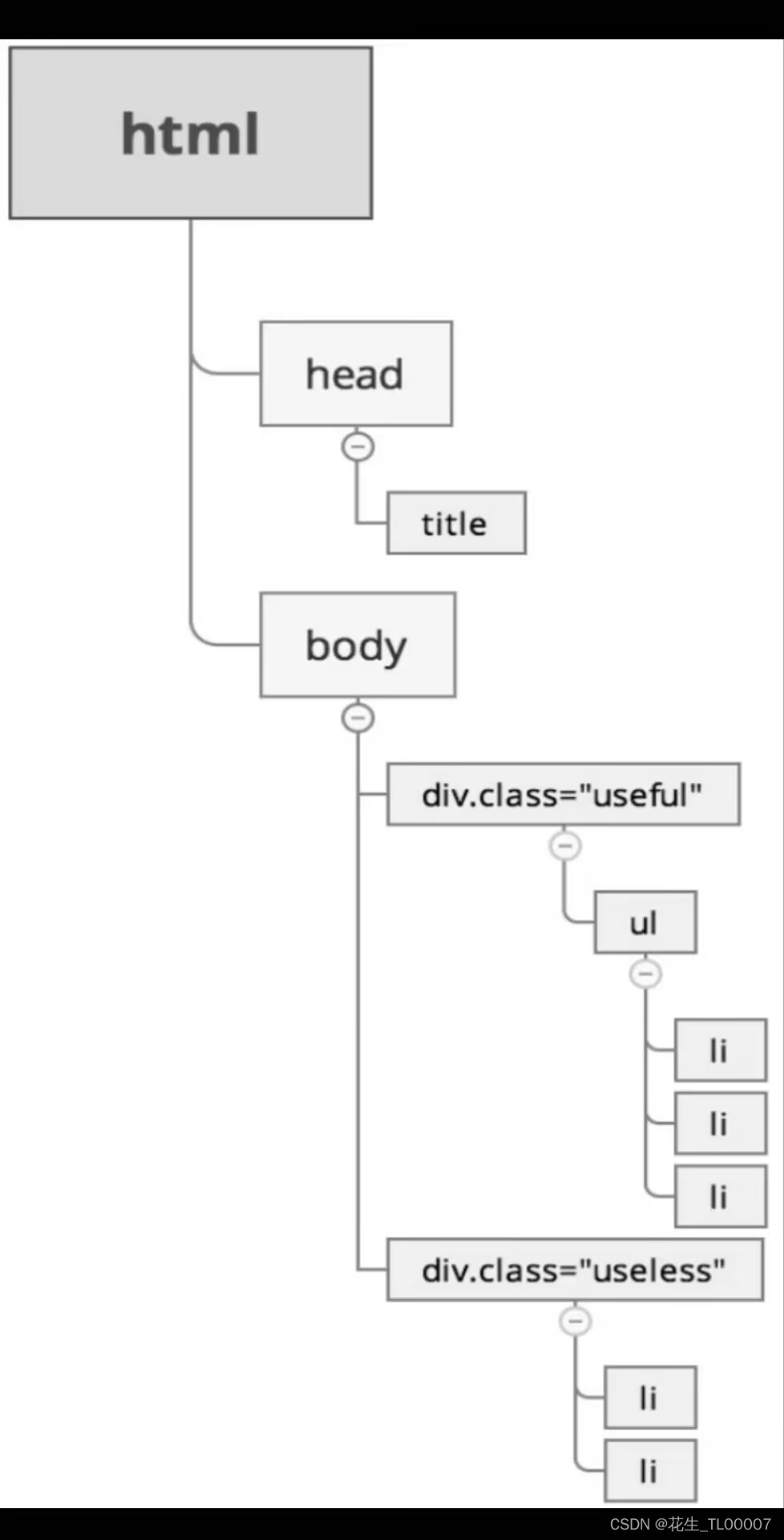
HTML 就是网页源代码,是一种结构化的标记语言。HTML可以描述一个网页的结构信息。
HTML与CSS(层叠样式表),JavaScript一起构成了现代互联网的基石。
来看一段html的示例代码:
<html>
<head>
<title>测试</title>
</head>
<body>
<div class="useful">
<ul>
<li class="info">我需要的信息1</li>
<li class="info">我需要的信息2</li>
<li class="info">我需要的信息3</li>
</ul>
</div>
<div class="useless">
<ul>
<li class="info">垃圾1</li>
<li class="info">垃圾2</li>
</ul>
</div>
</body>
</html>html的层级关系
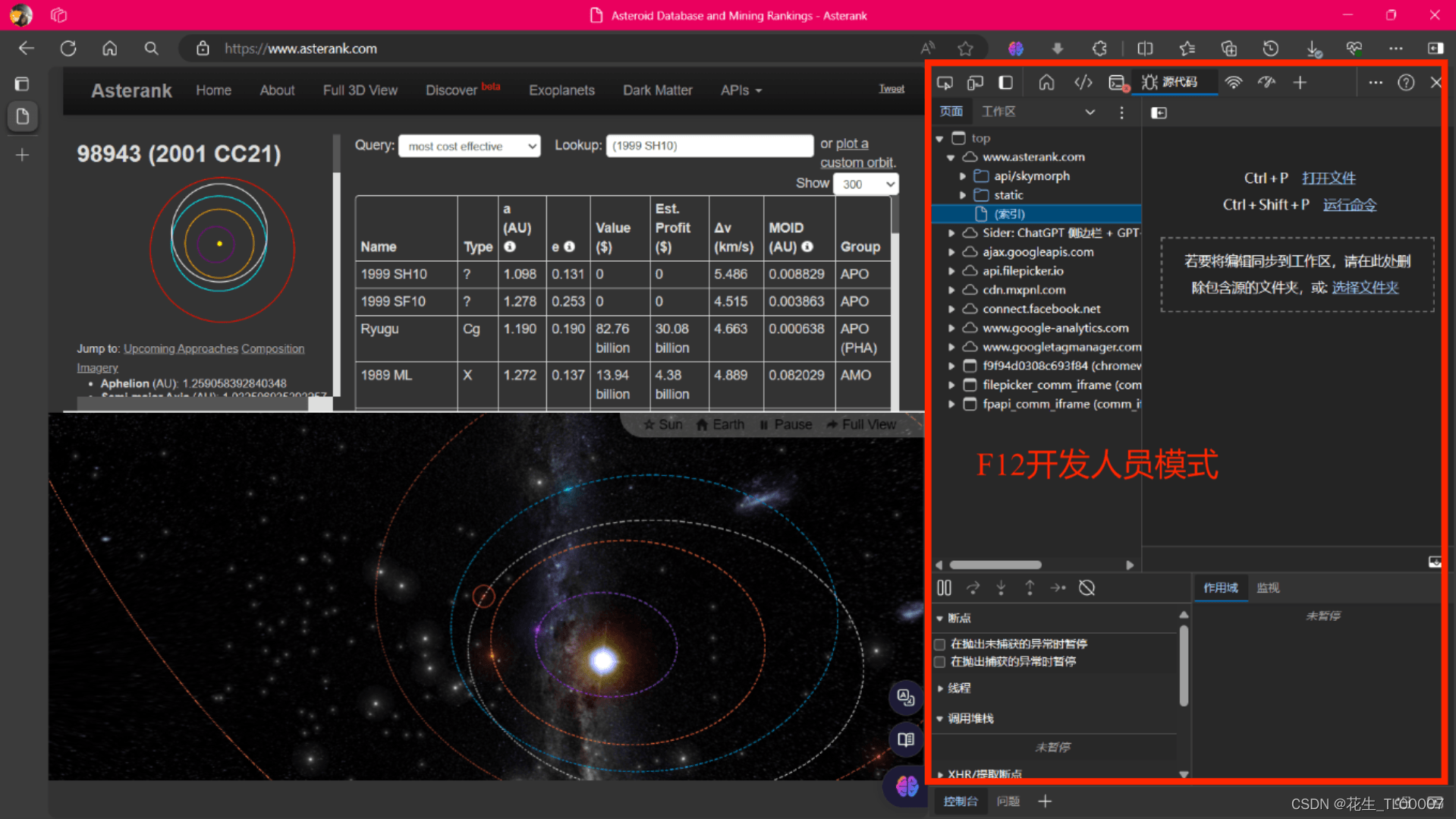
使用BeautifulSoup4爬取网站
https://www.damai.cn/projectlist.do中的的演出信息,将结果保存到CSV文件


我的目标是抓取当Name='Inputname'时 ,Est.profit那一列的数据
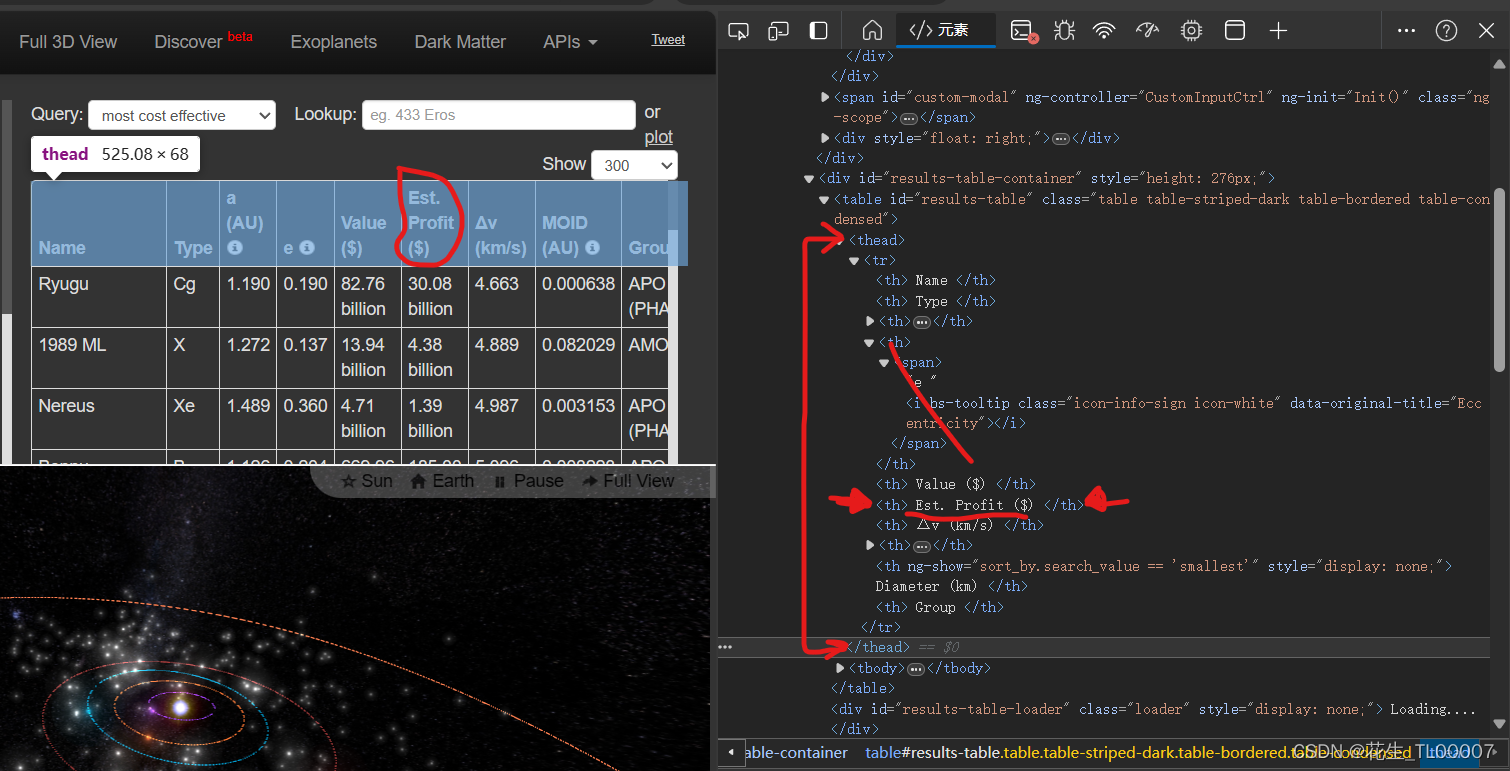
晚上试了很久,都没有成功运行。(GTP不太行)
第二天早上继续尝试。
爬爬爬(一)——网页表格(四种方法) - 知乎 (zhihu.com)
每行是一个tr标签,每一个内容是tr下的td标签
在 soup 里循环遍历所有的元素并存储在变量中
写了两天爬虫代码,没弄出来。好想寺