一、引言
Self-Attention并行的计算方式未考虑输入特征间的位置关系,这对NLP来说是不可接受的,毕竟一个句子中每个单词都有着明显的顺序关系。Transformer没有RNN、LSTM那样的顺序结构,所以Transformer在提出Self-Attention的同时提出了Positional Encoding。
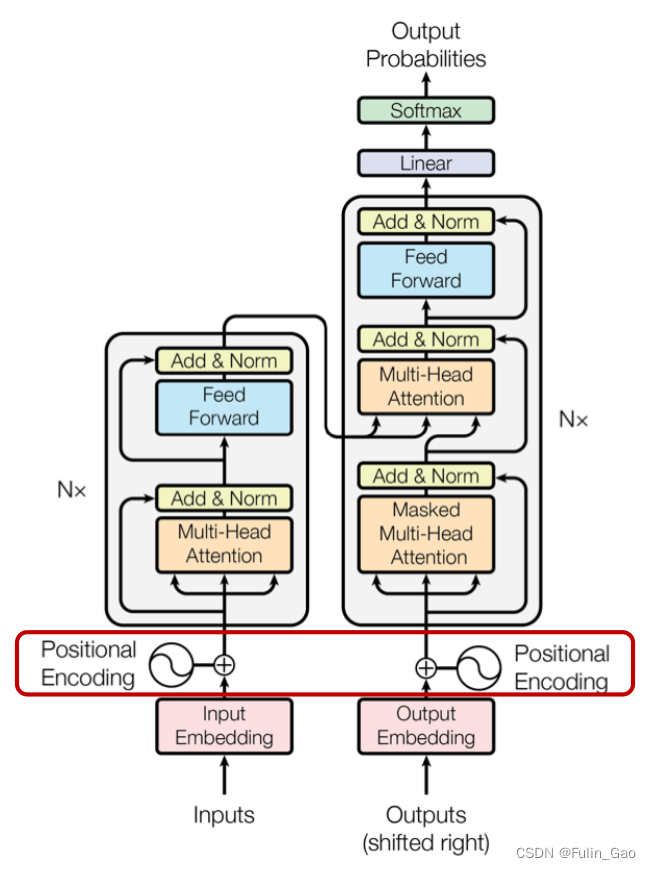
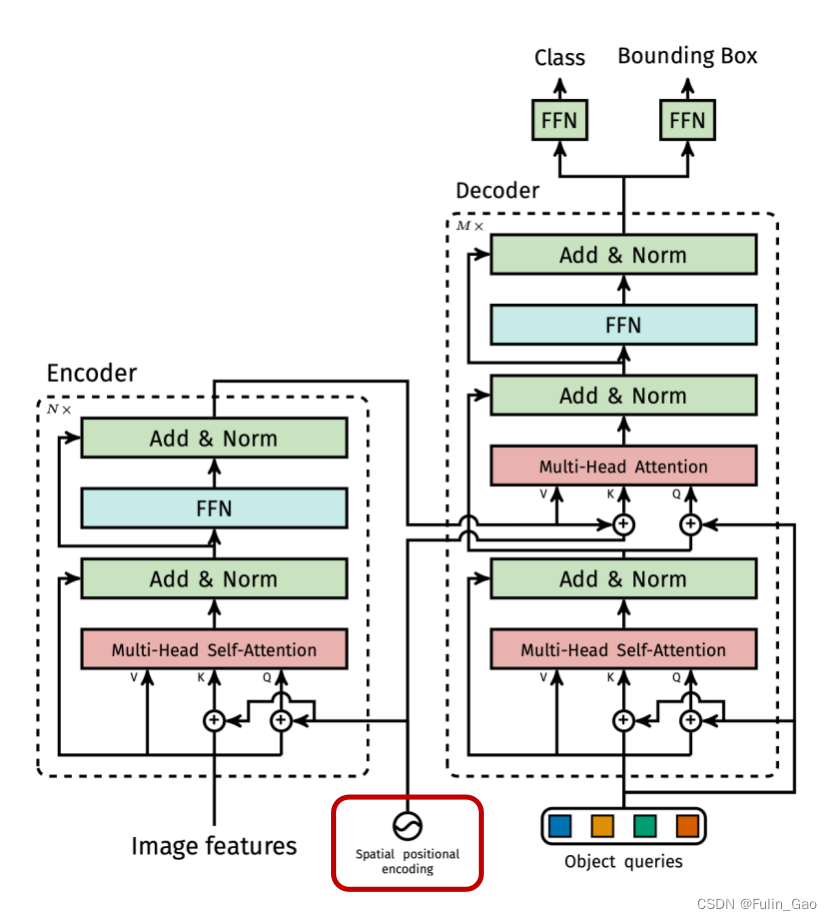
如图所示,Transformer在Attention模块之前将位置编码加进了待输入特征中。
二、位置编码
首先需要明确NLP中数据的形式,一个批次包含多个句子,每个句子包含多个单词,每个单词被转为长度相同的token向量。由于每个句子中包含的单词数不同,所以会通过padding统一同一批次的embedding。假设一个批次padding后的embedding维度为 [ b a t c h _ s i z e , n u m _ t o k e n , d i m _ t o k e n ] [batch\_size,num\_token,dim\_token] [batch_size,num_token,dim_token]。
1. 直观的位置编码
1.1 索引型
将token的索引作为位置编码,第一个token编码为0,第二个token编码为1,以此类推。
其主要问题在于位置编码的值无界。
1.2 [0,1]型
为保证值有界,可限制位置编码范围为 [ 0 , 1 ] [0,1] [0,1],第一个token编码为0,最后一个token编码为1,其余token等间隔取值。例如共3个token时,位置编码为 [ 0 , 0.5 , 1 ] [0,0.5,1] [0,0.5,1],共4个token时,位置编码为 [ 0 , 0.33 , 0.66 , 1 ] [0,0.33,0.66,1] [0,0.33,0.66,1]。
其主要问题在于两个句子的token个数不同时,两个相同位置间的相对距离不同。共3个token时,第三个与第一个token间距为1,但共4个token时,第三个与第一个token间距为0.66。
1.3 二进制型
为保证值有界、句子长度不同时相对距离相同,可通过索引的二进制编码作为位置编码。下图为一个包含8个token,token向量长度为3的句子的位置编码。
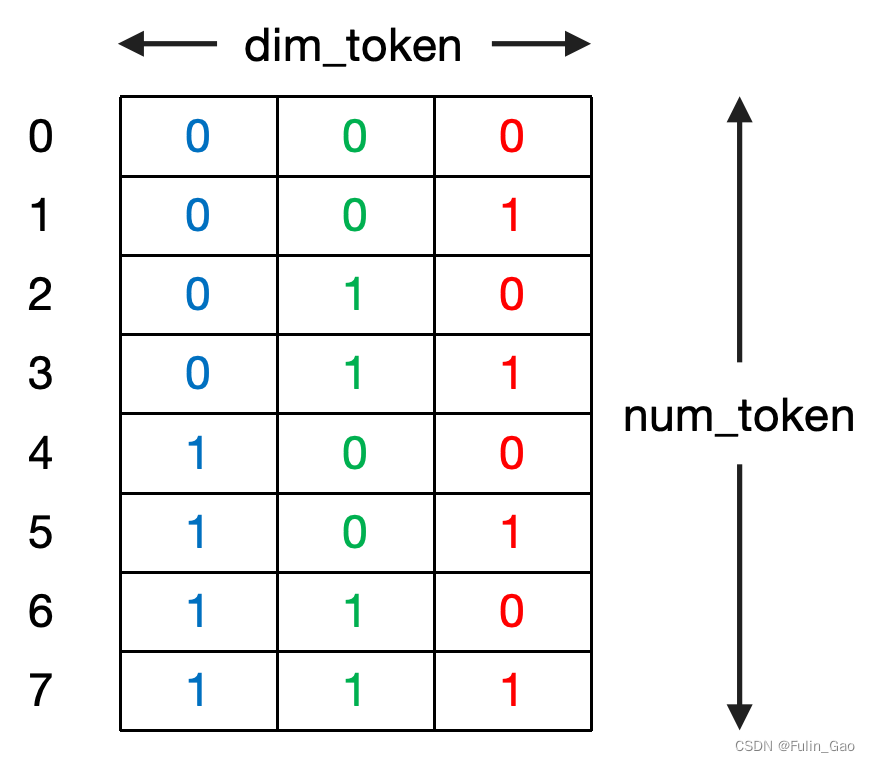
如图,因为位置编码与embedding需要相加,所以通常位置编码的维度与embedding的维度相同。直白地说,有几个token就有几个位置编码,token向量的维度是多少位置编码向量的维度就是多少。
其主要问题在于二进制编码的位置向量处于离散空间,与输入相加后进入浮点世界,造成了空间上的浪费。
不过,我们可以观察该类型位置编码的规律。纵向来看,每个维度的编码值变化频率不同,蓝色变化周期为4,绿色变化周期为2,红色变化周期为1。
1.4 周期型
为保证值有界、句子长度不同时相对距离相同、节约空间,周期型位置编码包含了类似二进制型位置编码的变化规律,并将离散的二进制转为连续的 sin \sin sin或 cos \cos cos。
以
sin
\sin
sin为例,我们用
p
o
s
pos
pos表示embedding中token的索引,用
i
i
i表示token上元素的索引。于是第
p
o
s
pos
pos个token的位置编码可以表示如下:
P
E
(
p
o
s
)
=
[
sin
(
p
o
s
2
0
)
,
sin
(
p
o
s
2
1
)
,
⋯
,
sin
(
p
o
s
2
i
)
,
⋯
,
sin
(
p
o
s
2
d
i
m
_
t
o
k
e
n
−
1
)
]
PE_{(pos)}=[\sin(\frac{pos}{2^0}),\sin(\frac{pos}{2^1}),\cdots,\sin(\frac{pos}{2^i}),\cdots,\sin(\frac{pos}{2^{dim\_token-1}})]
PE(pos)=[sin(20pos),sin(21pos),⋯,sin(2ipos),⋯,sin(2dim_token−1pos)]
其中, p o s = 0 , 1 , ⋯ , n u m _ t o k e n − 1 pos=0,1,\cdots,num\_token-1 pos=0,1,⋯,num_token−1, i = 0 , 1 , ⋯ , d i m _ t o k e n − 1 i=0,1,\cdots,dim\_token-1 i=0,1,⋯,dim_token−1。
可见,每个维度上 1 2 i \frac{1}{2^i} 2i1被用来控制变化规律,详情如下图。
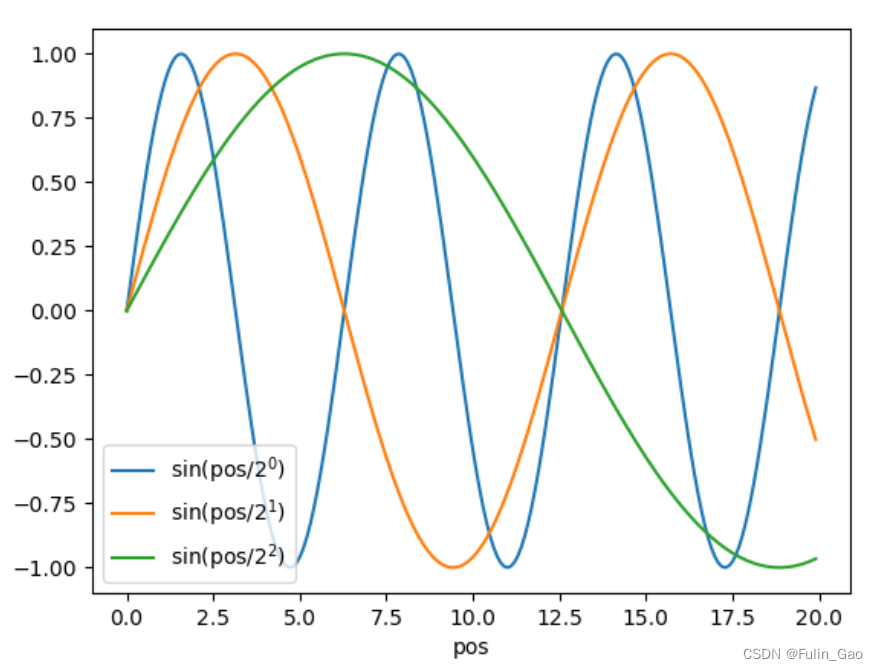
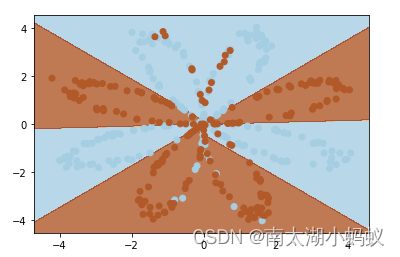
但是,使用 1 2 i \frac{1}{2^i} 2i1来控制变化规律会使 P E ( p o s ) PE_{(pos)} PE(pos)很快形成一个闭环。

如图,当 d i m _ t o k e n = 3 dim\_token=3 dim_token=3时,以 0.1 0.1 0.1的间隔在 [ 0 , 20 ] [0,20] [0,20]取 p o s pos pos,得到200个 P E ( p o s ) PE_{(pos)} PE(pos),前100个点为蓝色,后100个点为橙色,可以清晰看到它们的重叠部分。这表明即便 p o s pos pos不同, P E ( p o s ) PE_{(pos)} PE(pos)也有很多点的值是相同的,但我们希望位置编码像地址一样是独一无二的,所以我们使用 1 1000 0 i / d i m _ t o k e n \frac{1}{10000^{i/dim\_token}} 10000i/dim_token1替换 1 2 i \frac{1}{2^i} 2i1来控制变化规律。此时, P E ( p o s ) PE_{(pos)} PE(pos)如下图,不再有重叠。
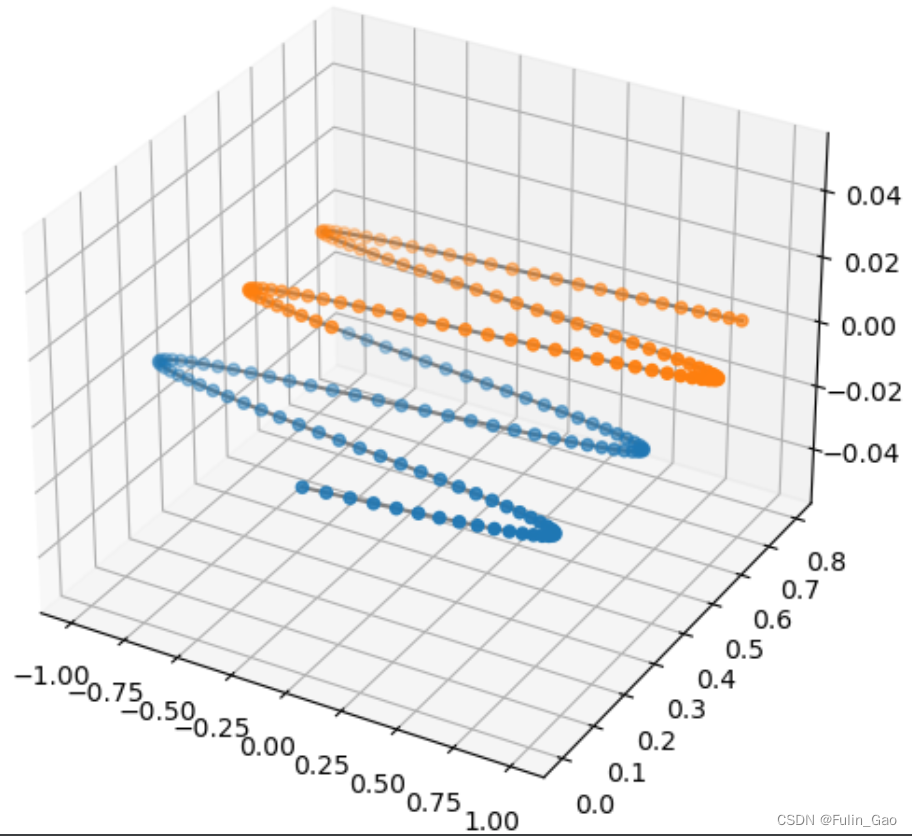
于是有:
P
E
(
p
o
s
)
=
[
sin
(
w
0
p
o
s
)
,
sin
(
w
1
p
o
s
)
,
⋯
,
sin
(
w
i
p
o
s
)
,
⋯
,
sin
(
w
d
i
m
_
t
o
k
e
n
−
1
p
o
s
)
]
PE_{(pos)}=[\sin(w_0pos),\sin(w_1pos),\cdots,\sin(w_ipos),\cdots,\sin(w_{dim\_token-1}pos)]
PE(pos)=[sin(w0pos),sin(w1pos),⋯,sin(wipos),⋯,sin(wdim_token−1pos)]
其中, w i = 1 1000 0 i / d i m _ t o k e n w_i=\frac{1}{10000^{i/dim\_token}} wi=10000i/dim_token1。
但它仍有一个问题,不同位置编码无法相互线性转换。
2. Sinusoidal位置编码
为保证值有界、句子长度不同时相对距离相同、节约空间、不同位置编码可相互线性转换,Sinusoidal型位置编码交替使用
sin
\sin
sin和
cos
\cos
cos,于是第
p
o
s
pos
pos个token的位置编码可表示如下:
P
E
(
p
o
s
)
=
[
sin
(
w
0
p
o
s
)
,
cos
(
w
0
p
o
s
)
,
⋯
,
sin
(
w
i
p
o
s
)
,
cos
(
w
i
p
o
s
)
,
⋯
,
sin
(
w
d
i
m
_
t
o
k
e
n
2
−
1
p
o
s
)
,
cos
(
w
d
i
m
_
t
o
k
e
n
2
−
1
p
o
s
)
]
PE_{(pos)}=[\sin(w_0pos),\cos(w_0pos),\cdots,\sin(w_ipos),\cos(w_ipos),\cdots,\sin(w_{\frac{dim\_token}{2}-1}pos),\cos(w_{\frac{dim\_token}{2}-1}pos)]
PE(pos)=[sin(w0pos),cos(w0pos),⋯,sin(wipos),cos(wipos),⋯,sin(w2dim_token−1pos),cos(w2dim_token−1pos)]
其中, p o s = 0 , 1 , ⋯ , n u m _ t o k e n − 1 pos=0,1,\cdots,num\_token-1 pos=0,1,⋯,num_token−1, i = 0 , 1 , ⋯ , d i m _ t o k e n 2 − 1 i=0,1,\cdots,\frac{dim\_token}{2}-1 i=0,1,⋯,2dim_token−1, w i = 1 1000 0 i / d i m _ t o k e n w_i=\frac{1}{10000^{i/dim\_token}} wi=10000i/dim_token1。
该形式下
P
E
(
p
o
s
)
PE_{(pos)}
PE(pos)可以线性变换,可由下式证明:
P
E
(
p
o
s
+
Δ
p
o
s
)
=
(
sin
(
w
0
(
p
o
s
+
Δ
p
o
s
)
)
cos
(
w
0
(
p
o
s
+
Δ
p
o
s
)
)
⋯
sin
(
w
d
i
m
_
t
o
k
e
n
2
−
1
(
p
o
s
+
Δ
p
o
s
)
)
cos
(
w
d
i
m
_
t
o
k
e
n
2
−
1
(
p
o
s
+
Δ
p
o
s
)
)
)
=
(
[
cos
(
w
0
Δ
p
o
s
)
sin
(
w
0
Δ
p
o
s
)
−
sin
(
w
0
Δ
p
o
s
)
cos
(
w
0
Δ
p
o
s
)
]
⋯
0
⋯
⋯
⋯
0
⋯
[
cos
(
w
d
i
m
_
t
o
k
e
n
2
−
1
Δ
p
o
s
)
sin
(
w
d
i
m
_
t
o
k
e
n
2
−
1
Δ
p
o
s
)
−
sin
(
w
d
i
m
_
t
o
k
e
n
2
−
1
Δ
p
o
s
)
cos
(
w
d
i
m
_
t
o
k
e
n
2
−
1
Δ
p
o
s
)
]
)
(
sin
(
w
0
p
o
s
)
cos
(
w
0
p
o
s
)
⋯
sin
(
w
d
i
m
_
t
o
k
e
n
2
−
1
p
o
s
)
cos
(
w
d
i
m
_
t
o
k
e
n
2
−
1
p
o
s
)
)
=
T
Δ
p
o
s
∗
P
E
(
p
o
s
)
\begin{split} PE_{(pos+\Delta pos)} &= \left(\begin{array}{c} \sin(w_0(pos+\Delta pos))\\ \cos(w_0(pos+\Delta pos))\\ \cdots\\ \sin(w_{\frac{dim\_token}{2}-1}(pos+\Delta pos))\\ \cos(w_{\frac{dim\_token}{2}-1}(pos+\Delta pos)) \end{array}\right)\\ &= \left(\begin{array}{c} \left[\begin{array}{c} \cos(w_0\Delta pos)&\sin(w_0\Delta pos)\\ -\sin(w_0\Delta pos)&\cos(w_0\Delta pos) \end{array}\right]&\cdots&0\\ \cdots&\cdots&\cdots\\ 0&\cdots&\left[\begin{array}{c} \cos(w_{\frac{dim\_token}{2}-1}\Delta pos)&\sin(w_{\frac{dim\_token}{2}-1}\Delta pos)\\ -\sin(w_{\frac{dim\_token}{2}-1}\Delta pos)&\cos(w_{\frac{dim\_token}{2}-1}\Delta pos) \end{array}\right]\\ \end{array}\right) \left(\begin{array}{c} \sin(w_0pos)\\ \cos(w_0pos)\\ \cdots\\ \sin(w_{\frac{dim\_token}{2}-1}pos)\\ \cos(w_{\frac{dim\_token}{2}-1}pos) \end{array}\right)\\ &= T_{\Delta pos}*PE_{(pos)} \end{split}
PE(pos+Δpos)=
sin(w0(pos+Δpos))cos(w0(pos+Δpos))⋯sin(w2dim_token−1(pos+Δpos))cos(w2dim_token−1(pos+Δpos))
=
[cos(w0Δpos)−sin(w0Δpos)sin(w0Δpos)cos(w0Δpos)]⋯0⋯⋯⋯0⋯[cos(w2dim_token−1Δpos)−sin(w2dim_token−1Δpos)sin(w2dim_token−1Δpos)cos(w2dim_token−1Δpos)]
sin(w0pos)cos(w0pos)⋯sin(w2dim_token−1pos)cos(w2dim_token−1pos)
=TΔpos∗PE(pos)
实际上,是用到如下和角公式中的第1项和第3项:
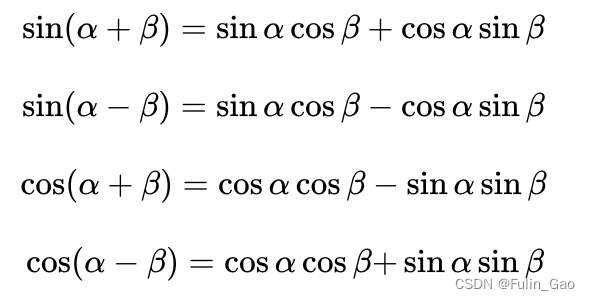
三、应用
1. Transformer中的位置编码
1.1 简介
上述Sinusoidal位置编码是在Transformer中针对NLP问题提出的。一个 n u m _ t o k e n = 50 , d i m _ t o k e n = 128 num\_token=50,dim\_token=128 num_token=50,dim_token=128的句子的位置编码如下图:

纵向来看,不同列的变化频率不同,从左到右频率依次下降。即使后58个维度无变化,为保证位置编码与embedding维度相同,仍然保留完整的128个维度。
位置编码在Transformer模型中的作用主要体现在以下几个方面:
(1) 捕捉词序信息:由于位置编码与词的位置相关,因此它们可以帮助模型理解输入序列中词的顺序。这对于依赖关系分析、句法分析等任务非常重要。
(2) 防止重复使用相同输入:由于位置编码是随机的,相同的输入序列会产生不同的位置编码。这有助于防止模型重复使用相同的输入来生成输出,从而提高模型的多样性和泛化能力。
(3) 增加模型的鲁棒性:位置编码的随机性可以帮助模型更好地处理噪声和异常值,从而提高其鲁棒性。
在实际应用中,位置编码通常在自注意力机制之前添加到输入序列中。这样,自注意力机制可以同时考虑词的语义信息和位置信息,从而更好地捕捉输入序列中的依赖关系。
1.2 实现
import torch.nn as nn
import torch
class PositionalEncoding(nn.Module):
def __init__(self, dim_token, max_num_token=5000):
super(PositionalEncoding, self).__init__()
self.encoding = torch.zeros(max_num_token, dim_token)
pos = torch.arange(0, max_num_token).unsqueeze(dim=1) # 不是每次实时计算,而是预估一个pos上限
_2i = torch.arange(0, dim_token, step=2) # 共计算dim_token/2-1次,每次计算两个值sin和cos
self.encoding[:, 0::2] = torch.sin(pos / (10000 ** (_2i / dim_token)))
self.encoding[:, 1::2] = torch.cos(pos / (10000 ** (_2i / dim_token)))
def forward(self, x):
batch_size, num_token, dim_token = x.size()
return self.encoding[:num_token, :] # num_token是padding前单词的数量
if __name__ == '__main__':
x = torch.randn((2, 3, 6)) # [batch_size,num_token,dim_token]
pe = PositionalEncoding(6) # dim_token必须是偶数
y = pe(x)
2. DETR中的位置编码
2.1 简介
DETR将Transformer用在了CV的目标检测任务中,目标检测要求预测目标框,因此位置信息也很重要,所以也需要引入位置编码。DETR引入的位置编码也是Sinusoidal形式的。
不过,图像的维度与句子的维度不同。句子维度为 [ b a t c h _ s i z e , n u m _ t o k e n , d i m _ t o k e n ] [batch\_size,num\_token,dim\_token] [batch_size,num_token,dim_token],Transformer中位置编码与句子维度相同,一个位置编码向量表示一个句子(位置编码向量长度 = d i m _ t o k e n =dim\_token =dim_token)。图像维度为 [ b a t c h _ s i z e , n u m _ c h a n n e l , h e i g h t , w i d t h ] [batch\_size,num\_channel,height,width] [batch_size,num_channel,height,width],DETR中一个位置编码向量表示一个像素(位置编码向量长度 = n u m _ c h a n n e l =num\_channel =num_channel,一半的向量表示横坐标,另一半表示纵坐标)。此外,DETR还考虑了padding问题,仅针对非padding区域计算位置编码。
不仅如此,DETR中位置编码仅在Attention的 Q Q Q和 K K K中,而Transformer在 Q Q Q、 K K K、 V V V上都有。
2.2 实现
import torch.nn as nn
import torch
class PositionEmbeddingSine(nn.Module):
def __init__(self, num_channel=64, temperature=10000):
super().__init__()
self.num_channel = num_channel
self.temperature = temperature
def forward(self, mask):
assert mask is not None
not_mask = ~mask # mask中True表示padding区域,False表示非padding区域
pos_y = not_mask.cumsum(1) # 如果是padding区域,pos不增加
pos_x = not_mask.cumsum(2) # 横、纵坐标均计算pos
i = torch.arange(self.num_channel)
wi = self.temperature ** (2 * (i // 2) / self.num_channel) # 2i = i // 2
pos_x = pos_x[:, :, :, None] / wi # 所有像素都有num_channel/2个横坐标
pos_y = pos_y[:, :, :, None] / wi # 所有像素都有num_channel/2个纵坐标
pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3) # 原本dim只到3,在第4个维度上stack然后flatten能使sin和cos交替出现
pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2) # 前半部分为纵坐标,后半部分为横坐标
return pos
if __name__ == '__main__':
x = torch.randn((8, 4, 5, 6)) # [batch_size,num_channel,height,width]
mask = torch.zeros((8, 5, 6)) # 同一图像上mask在每个通道上都一样
mask = mask.bool() # 默认没有padding
pes = PositionEmbeddingSine(2) # num_channel必须是偶数,这里输入的是num_channel/2,一半用于横坐标,另一半用于纵坐标
y = pes(mask)
致谢:
本博客仅做记录使用,无任何商业用途,参考内容如下:
四种Position Embedding的原理与PyTorch手写逐行实现(Transformer/ViT/Swin-T/MAE)
【Transformer系列】深入浅出理解Positional Encoding位置编码
Transformer学习笔记一:Positional Encoding(位置编码)
DE⫶TR: End-to-End Object Detection with Transformers