指标类型
测量型(gauge)
这种类型是上下增减的数字,本质上是特定度量的快照。常见的有CPU,内存,磁盘使用率等。对于业务上来说,指标可能是网站上的客户数量。

计数型(counter)
这种类型是随着时间增加而不会减少的数字。虽然它们永远不会减少,但有时可以将其重置为零并再次开始递增。应用程序和基础设施的计数型示例包括系统正常运行时间、设备收发包的字节数或登录次数。业务方便的示例可能是一个月内的销售数量或应用程序收到的订单数量。
计数型指标的一个优势在于它们可以让你计算变化率。每个观察到的数值都是在一个时刻:t,你
可以使用t+1处的值减去t处的值,以获得两个值之间的变化率。通过了解两个值之间的变化率,可以
理解许多有用的信息。例如登录次数指标,你可以通过计算变化率来查看每秒的登录次数,这有助于
确定网站这段时间的受欢迎程度。

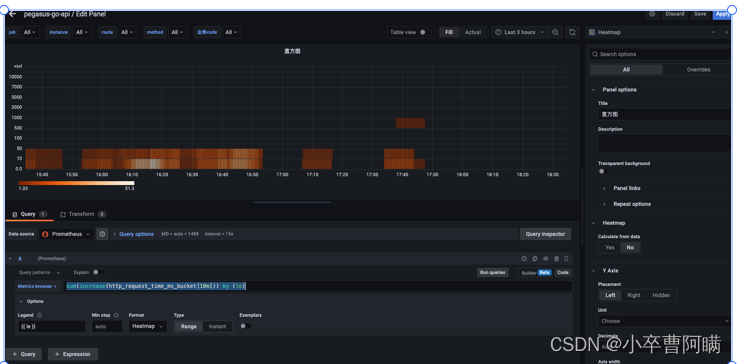
直方图(histogram)
是对观察点进行采样的指标类型,可以展现数据集的频率分布。将数据分组在一起并以这样的方式显示,这个被称为“分箱”(binning)的过程可以直观地查看数值的相对大小。 统计每个观察点并将其放入不同的桶中,这样可以产生多个指标:每个桶一个,加上所有值的总和以及计数
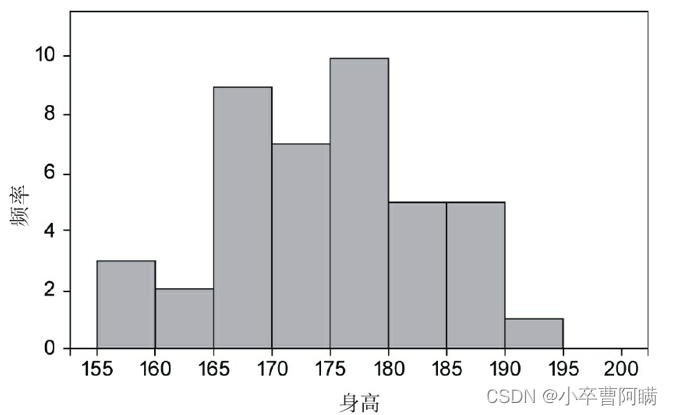
示例是身高频率分布的样本直方图。x轴是身高的分布,y轴是对应的频率值,例如可以看到身高160~165cm对应的值是2
直方图有三个指标:
累积计数<basename>_bucket{le="<upper inclusive bound>"}
指标值的总和:<basename>_sum
指标的个数:<basename>_count (identical to <basename>_bucket{le="+Inf"}
可以使用 histogram_quantile()函数计算分位数
histograms和summaries都是抽样指标,典型的有请求耗时,响应体的大小。他们记录指标的数量,和指标值的和,允许你计算平均值。
计算过去的5min的平均耗时,从histograms或者summaries
rate(http_request_duration_seconds_sum[5m]) / rate(http_request_duration_seconds_count[5m])
计算最近5分钟内在0.3seconds内的请求占比
sum(rate(http_request_duration_seconds_bucket{le="0.3"}[5m])) by (job) / sum(rate(http_request_duration_seconds_count[5m])) by (job)
计算最近5分钟内在0.3和1.2 seconds内的请求占比
( sum(rate(http_request_duration_seconds_bucket{le="0.3"}[5m])) by (job) + sum(rate(http_request_duration_seconds_bucket{le="1.2"}[5m])) by (job) ) / 2 / sum(rate(http_request_duration_seconds_count[5m])) by (job)
95分位
histogram_quantile(0.95, sum(rate(http_request_duration_seconds_bucket[5m])) by (le)) // GOOD.
摘要型(summary)
类似于直方图,但它还会计算百分位数。
直方图可以很好地展现时间序列数据,尤其适用于数据的可视化(如应用程序延迟等)。
通常来说,单个指标对我们价值很小,往往需要联合并可视化多个指标,这其中需要应用一些数
学变换。例如,我们可能会将统计函数应用于指标或指标组,一些可能应用的常见函数包括:
·计数:计算特定时间间隔内的观察点数。
·求和:将特定时间间隔内所有观察点的值累计相加。
·平均值:提供特定时间间隔内所有值的平均值。
·中间数:数值的几何中点,正好50%的数值位于它前面,而另外50%则位于它后面。
·百分位数:度量占总数特定百分比的观察点的值。
·标准差:显示指标分布中与平均值的标准差,这可以测量出数据集的差异程度。标准差为0表示
数据都等于平均值,较高的标准差意味着数据分布的范围很广。
·变化率:显示时间序列中数据之间的变化程度。
与直方图相似,它也提供了一个总个数和值的总和,它通过滑动时间窗计算可配置的分位数。
-
streaming φ-quantiles (0 ≤ φ ≤ 1) of observed events, exposed as
<basename>{quantile="<φ>"}
-
the total sum of all observed values, exposed as
<basename>_sum
-
the count of events that have been observed, exposed as
<basename>_count
For each instance scrape, Prometheus stores a sample in the following time series:
-
up{job="<job-name>", instance="<instance-id>"}:1if the instance is healthy, i.e. reachable, or0if the scrape failed.
-
scrape_duration_seconds{job="<job-name>", instance="<instance-id>"}: duration of the scrape.
-
scrape_samples_post_metric_relabeling{job="<job-name>", instance="<instance-id>"}: the number of samples remaining after metric relabeling was applied.
-
scrape_samples_scraped{job="<job-name>", instance="<instance-id>"}: the number of samples the target exposed.
-
scrape_series_added{job="<job-name>", instance="<instance-id>"}: the approximate number of new series in this scrape. New in v2.10
The up time series is useful for instance availability monitoring.
监控方法论
USE方法
USE是使用率(Utilization)、饱和度(Saturation)和错误(Error)的缩写
USE方法可以概括为:针对每个资源,检查使用率、饱和度和错误。该方法对于监控那些受高使用率或饱和度的性能问题影响的资源来说是最有效的。
资源:系统的一个组件。在Gregg对模型的定义中,它是一个传统意义上的物理服务器组件,如CPU、磁盘等,但许多人也将软件资源包含在定义中。
·使用率:资源忙于工作的平均时间。它通常用随时间变化的百分比表示。
·饱和度:资源排队工作的指标,无法再处理额外的工作。通常用队列长度表示。
·错误:资源错误事件的计数。
在这个示例中,我们将从CPU开始:
·CPU使用率随时间的百分比。
·CPU饱和度,等待CPU的进程数。
·错误,通常对CPU资源不太有影响。
然后是内存:
·内存使用率随时间的百分比。
·内存饱和度,通过监控swap测量。
·错误,通常不太关键,但也可以捕获。
其他组件以此类推,直到我们找到了问题的瓶颈或信号。
Google的四个黄金指标
延迟:服务请求所花费的时间,需要区分成功请求和失败请求。例如,失败请求可能会以非常低的延迟返回错误结果。
流量:针对系统,例如,每秒HTTP请求数,或者数据库系统的事务。
错误:请求失败的速率,要么是HTTP 500错误等显式失败,要么是返回错误内容或无效内容等隐式失败,或者基于策略原因导致的失败——例如,强制要求响应时间超过30ms的请求视为错误。
饱和度:应用程序有多“满”,或者受限的资源,如内存或IO。这还包括即将饱和的部分,例如正在快速填充的磁盘。
警报和通知
要建立一个出色的通知系统,需要考虑以下基础信息:
·哪些问题需要通知
·谁需要被告知
·如何告知他们
·多久告知他们一次
·何时停止告知以及何时升级到其他人
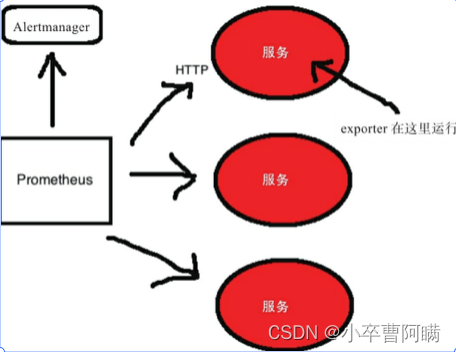
prometheus架构
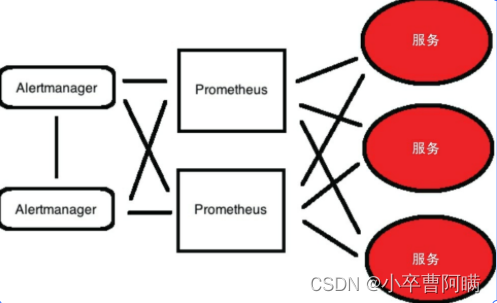
冗余和高可用
冗余和高可用性侧重弹性而非数据持久性。Prometheus团队建议将Prometheus服务器部署到特定环
境和团队,而不是仅部署一个单体Prometheus服务器。如果你确实要部署高可用HA模式,则可以使用
两个或多个配置相同的Prometheus服务器来收集时间序列数据,并且所有生成的警报都由可消除重复
警报的高可用Alertmanager集群来处理。
采样数据
时间序列的真实值是采样(sample)的结果,它包括两部分:
·一个float64类型的数值
·一个毫秒精度的时间戳
![]()
示例如下:

首先是时间序列名称,后面跟着一组键/值对标签。通常所有时间序列都有一个instance标签(标识源主机或应用程序)以及一个job标签(包含抓取特定时间序列的作业名称)。
Prometheus专为短期监控和警报需求而设计。默认情况下,它在其数据库中保留15天的时间序列数据。如果要保留更长时间的数据,则建议将所需数据发送到远程的第三方平台。Prometheus能够写入外部数据存储
prometheus配置文件
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']global
配置的第一部分是global,它包含了控制Prometheus服务器行为的全局配置。
第一个参数scrape_interval用来指定应用程序或服务抓取数据的时间间隔(在示例中是15秒)。这个值是时间序列的颗粒度,即该序列中每个数据点所覆盖的时间段。
在从特定位置收集指标时,有可能会覆盖这个全局抓取间隔。强烈建议不要这么做!可以在服务器上保持一个全局抓取间隔,这会确保你的所有时间序列具有相同的颗粒度,并且可以组合在一起计算。但是,当你使用了不同的数据间隔来收集数据时,则可能产生不合逻辑的结果
参数evaluation_interval用来指定Prometheus评估规则的频率。目前主要有两种规则:记录规则 (
recording rule)和警报规则(alerting rule)。
·记录规则:允许预先计算使用频繁且开销大的表达式,并将结果保存为一个新的时间序列数据。
·警报规则:允许定义警报条件。
根据这个参数,Prometheus将每隔15秒(重新)评估这些规则。
alerting
配置的第二部分是alerting,它用来设置Prometheus的警报。正如我们在上面提到的,警报是由名为Alertmanager的独立工具进行管理的。Alertmanager是一个可以集群化的独立警报管理工具。
在默认配置中,alerting部分包含服务器的警报配置,其中alertmanagers块会列出Prometheus服务器使用的每个Alertmanager,static_configs块表示我们要手动指定在targets数组中配置的Alertmanager。
Prometheus还支持Alertmanager的服务发现功能。例如,你可以通过查询外部源(如Consul服务器)来返回可用的Alertmanager列表,而不是单独指定每个Alertmanager.
rule_files
配置的第三部分是rule_files,它用来指定包含记录规则或警报规则的文件列表
scrape_configs
配置的最后一部分是scrape_configs,用来指定Prometheus抓取的所有目标
Prometheus将它抓取的指标的数据源称为端点。为了抓取这些端点的数据,Prometheus定义了一个目标,这个目标里包含的信息是抓取数据所必需的,比如用到的标签、建立连接所需的身份验证,或者其他定义数据抓取的信息。若干目标构成的组称为作业,作业里每个目标都有一个名为实例(instance)的标签,用来唯一标识这个目标
默认配置中定义了一个作业prometheus,它的static_configs参数部分列出了抓取的目标,这些特定的目标被单独列出来,而不是通过自动服务发现。你也可以将静态配置理解为手动或人工服务发现。
Rule
语法检查 0成功, 1错误
promtool check rules /path/to/example.rules.ymlRecording rules
预处理数据,可以让查询计算更快。
https://prometheus.io/docs/prometheus/latest/configuration/recording_rules/
groups: - name: example rules: - record: job:http_inprogress_requests:sum expr: sum by (job) (http_inprogress_requests)Alerting rules
groups: - name: example rules: - alert: HighRequestLatency expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5 for: 10m labels: severity: page annotations: summary: High request latency聚合时间序列
我们想要每个作业的HTTP请求总数,为此,我们需要通过查询语句来创建新的指标
![]()
这个查询使用了promhttp_metric_handler_requests_total指标的sum()运算符[2],它对所有请求进行累加,但没有按作业分类。为此,我们需要根据特定的标签维度进行聚合。PromQL有一个子句by,它允许按特定维度聚合。
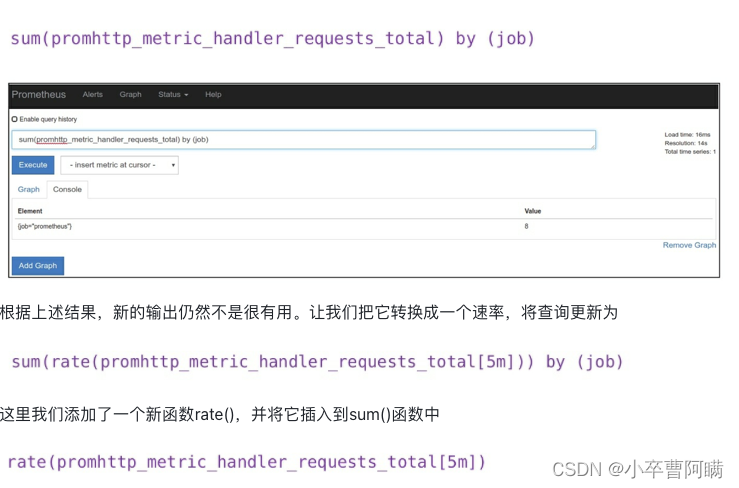
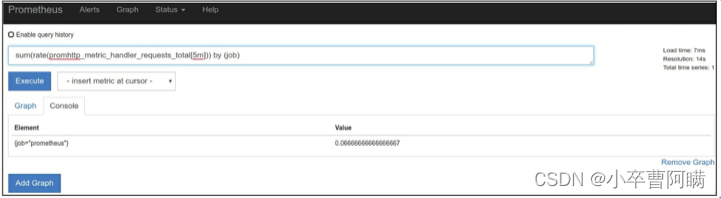
rate()函数用来计算一定范围内时间序列的每秒平均增长率,只能与计数器一起使用。它非常“聪明”且可以自适应,例如在资源重启时会重置计数器,并且通过推断来处理时间序列中的间隔,例如一次漏掉的数据抓取。rate()函数最适合用于增长较慢的计数器或用于警报的场景。
还有一个irate()函数 可以计算增长较快的计时器的瞬时增长率。
这里我们计算5分钟范围向量的速率。范围向量(range vector)[7]是第二个PromQL数据类型,它包含一组时间序列,其中每个时间序列都包含一系列数据点。范围向量允许我们显示该时间段的时间序列,持续时间被包含在中括号[ ]中,内容是一个整数值后跟一个单位缩写,其中单位缩写:
·s表示秒
·m表示分钟
·h表示小时
·d表示天
·w表示周
另外两个PromQL数据类型是Scalars(数字浮点值)和Strings(字符串值,且暂时未使用)。
Prometheus server部署的容量规划
内存
每个收集的时间序列、查询和记录规则都会消耗进程内存。关于Prometheus的容量规划的参考数据并不多(特别是自2.0版本发布以来),但一个有用的、粗略的经验法则是将每秒采集的样本数乘以样本的大小。我们可以使用以下查询语句来查看样本收集率
![]()
这将显示你在最后一分钟添加到数据库的每秒样本率。如果想知道收集的指标数量,则可以使用以下语句:
![]()
这里使用sum聚合来计算所有匹配的指标的计数和,使用=~运算符和.+的正则表达式来匹配所有指标。每个样本的大小通常为1到2个字节,让我们谨慎一点,按照2个字节计算。假设在12小时内每秒收集100 000个样本,那我们可以像下面这样计算内存使用情况:
结果大概是8.64GB的内存。

你还需要考虑在查询和记录规则方面的内存使用情况。这个不太好计算,并且依赖于许多其他变量,建议根据内存使用情况灵活调整。你可以通过检查process_resident_memory_bytes指标来查看Prometheus进程的内存使用情况。
磁盘
磁盘使用量受存储的时间序列数量和这些时间序列的保留时间限制。默认情况下,指标会在本地
时间序列数据库中存储15天。数据库的位置和保留时间由命令行选项控制
--storage.tsdb.path选项:它的默认数据目录位于运行Prometheus的目录中,用于控制时间序列数
据库位置。
--storage.tsdb.retention选项:控制时间序列的保留期。默认值为15d,代表15天。
建议采用SSD作为时间序列数据库的磁盘。
对于每秒10万个样本的示例,我们知道按时间序列收集的每个样本在磁盘上占用大约1到2个字
节。假设每个样本有2个字节,那么保留15天的时间序列意味着需要大约259 GB的磁盘。
cpu使用率

cpu饱和度

这里我们查询的是1分钟的平均负载超过主机CPU数量的两倍的结果
业务监控
mtail:
mtail 是用于从应用程序日志中提取指标以导出到时间序列数据库或时间序列计算器以进行警报和仪表板显示的工具。简单来说,就是实时读取应用程序的日志,并且通过自己编写的脚本实时分析,最终生成时间序列指标的工具。
优点:1.业务无侵入,与业务解耦
缺点:1.多个组件,架构复杂,需要运维 2.需要规范日志格式
热加载
sudo killall -HUP mtail
prometheus客户端
优点:1.架构简单
缺点:1.需要侵入业务代码
启动
启动prometheus
sudo nohup ./prometheus --web.listen-address=:8091 --config.file=prometheus.yml
启动mtail
sudo nohup ./mtail -logtostderr --progs /data2/mtail --logs /data2/pegasus-go-api/logs/access.log --logs /data2/pegasus-go-api/logs/error.log
启动grafana
grafana
1.变量的使用
https://blog.csdn.net/fu_huo_1993/article/details/115026228
业务监控配置