1.服务器环境以及配置
Kunpeng 920
内存:
256G DDR4
整机类型/架构:
TaiShan 200 (Model 2280)
内核版本
4.19.90-23.8.v2101.ky10.aarch64
2.问题现象描述 两台搭载麒麟v10 sp1的机器均在系统CPU软锁报错时,触发了softlockup_panic宕机。
3.问题分析 3.1.分析kylin 1 日志 3.1.1. 分析vmcore-dmesg日志
3.2.分析kylin2日志 3.2.1.分析messages日志 从messages日志看,系统不断出现软锁。
Dec 4 23:06:46 localhost sh[2145769]: [docker][INFO] do health check success [200]
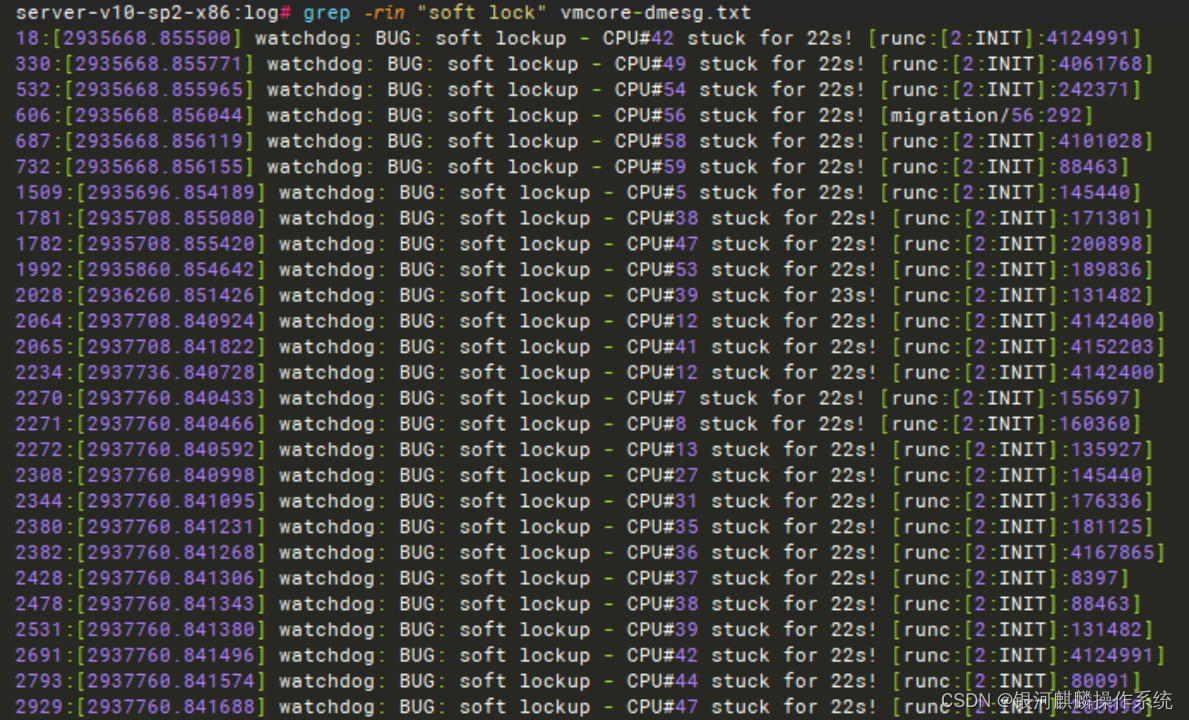
3.2.2.分析vmcore-dmesg日志 runc出现大量的软锁,软锁日志如下 pc : get_dominating_id+0x58/0xb8, lr : show_mountinfo+0x10c/0x2d8,从lr寄存器看,是在查看挂载信息。
[2935812.854382] watchdog: BUG: soft lockup - CPU#55 stuck for 22s! [runc:[2:INIT]:926483]
整理堆栈的函数调用,如下所示:
__arm64_sys_read+0x24/0x30
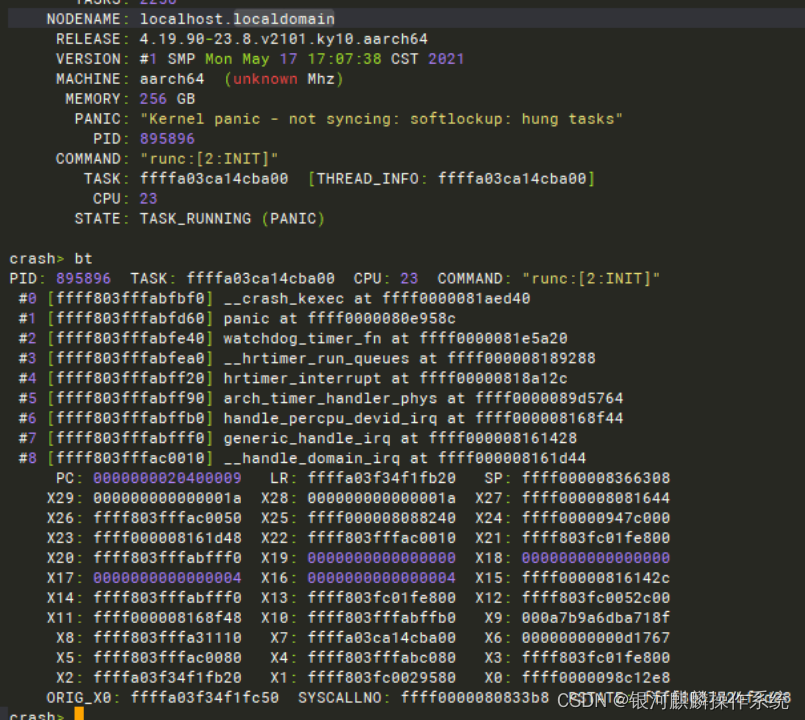
3.2.3.分析vmcore
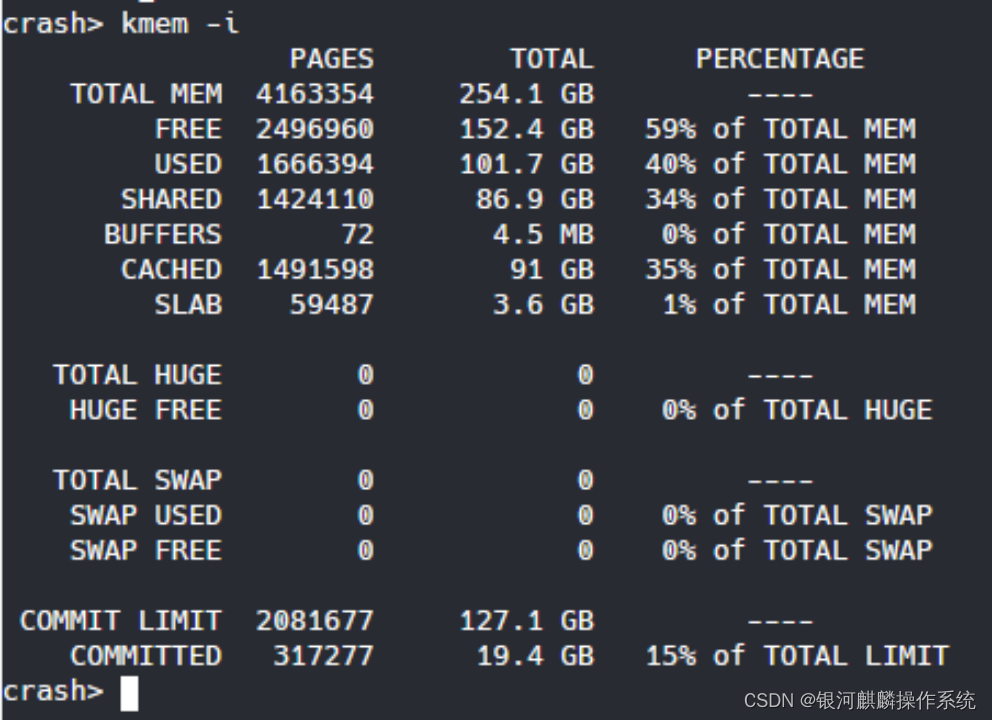
查看当时的内存使用情况,可见当时的空闲内存还有很多。
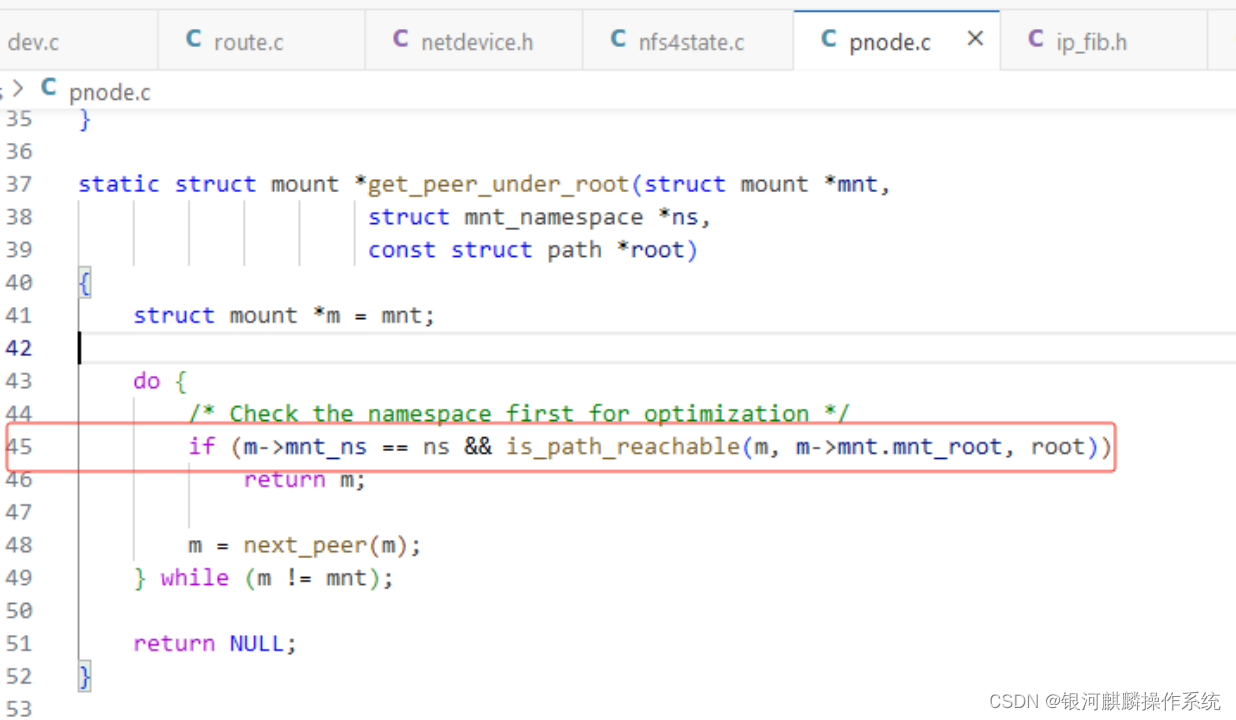
分析软锁堆栈的PC寄存器 get_dominating_id+0x58/0xb8,可见一直在执行/fs/pnode.c: 45
查看/fs/pnode.c: 45的源码如下,可见当时卡在do{}while循环出不来,这是因为m = next_peer(m);一直找不到尽头,最后内核一直在循环遍历。
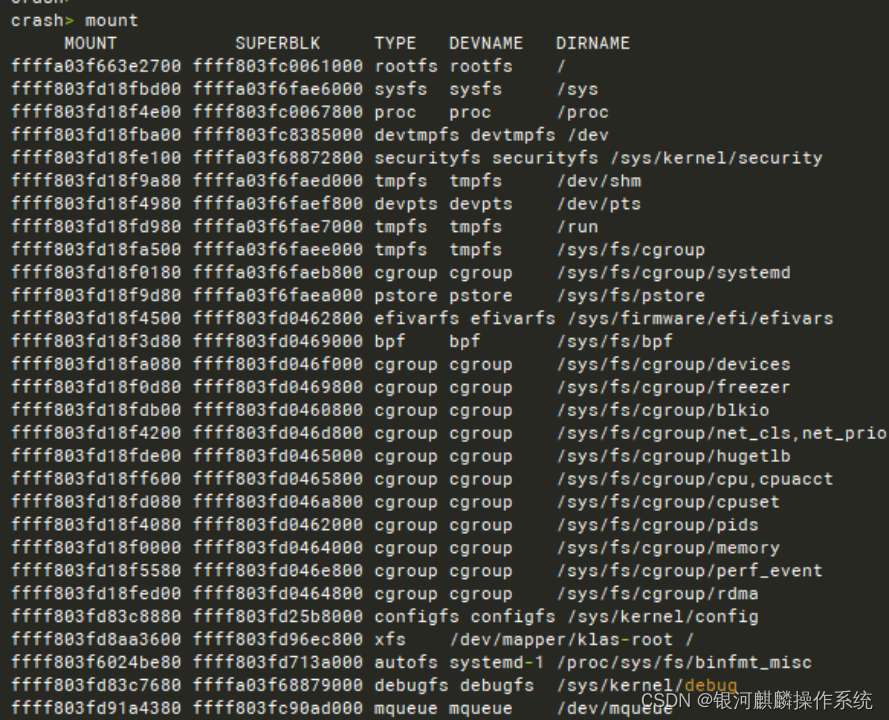
vmcore中查看mount信息
发现有很多
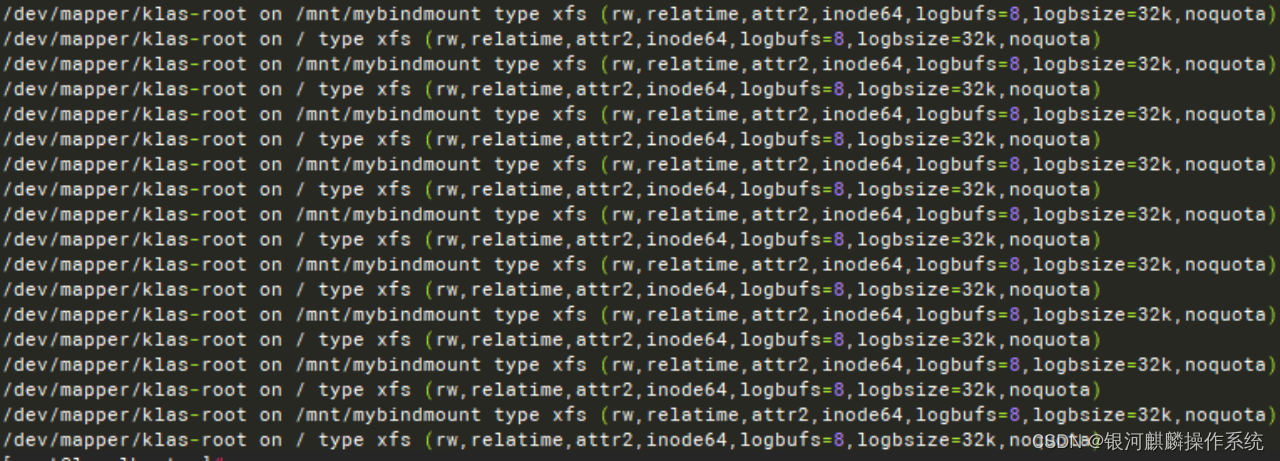
/dev/mapper/klas-root 挂载到/mnt/paas/kubernetes/kubelet/plugins/kubernetes.io/csi/pv。这是不正常的。
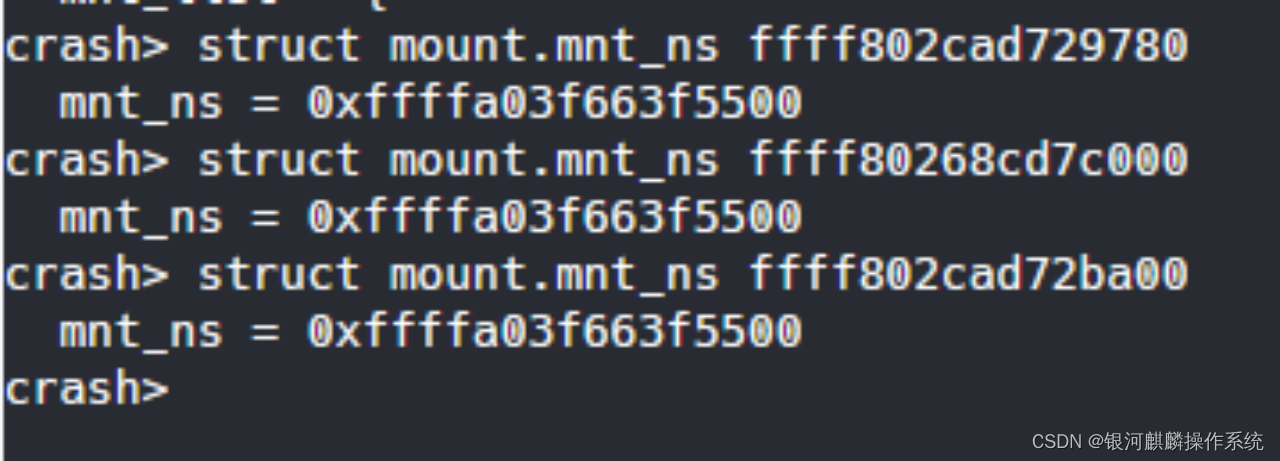
查看各个struct mount.mnt_ns,发现都是相同的,说明struct mnt_namespace相同。
3.3. 问题复现测试 使用如下脚本复现了重复挂载
#!/bin/bash
4.问题分析结果 分析两台机器的vmcore-dmesg.txt日志。软锁可能发生在runc进程尝试从某个文件(可能是与文件系统挂载相关的文件)中读取数据时。由于某种原因,这个读取操作卡住了。
分析vmcore,查看软锁时的堆栈情况,可见 pc : get_dominating_id+0x58/0xb8, lr : show_mountinfo+0x10c/0x2d8,从lr寄存器看,是在查看挂载信息出现了软锁。
查看pc寄存器所对应的内核代码,可见当时正处于一个查看mount的循环中无法出来。使用crash分析vmcore发现mount过多,有无数条/dev/mapper/klas-root 挂载到/mnt/paas/kubernetes/kubelet/plugins/kubernetes.io/csi/pv的记录,导致遍历这些记录的时候,内核进入一个死循环,最后触发软锁。
需应用端检查是否存在类似于循环挂载/dev/mapper/klas-root 挂载到/mnt/paas/kubernetes/kubelet/plugins/kubernetes.io/csi/pv的情况。例如循环执行 mount --bind / /mnt/paas/kubernetes/kubelet/plugins/kubernetes.io/csi/pv。