Mybatis-plus新用法
VehicleBO one = vehicleService.getOne(Wrappers.<VehicleBO>lambdaQuery().eq(VehicleBO::getVin, reqVo.getVin()));
boolean b = bizAccountApplyService.remove(Wrappers.<BizAccountApplyBO>lambdaQuery().eq(BizAccountApplyBO::getId, 1457753126076448l));
iBizAccountService.update(Wrappers.<BizAccountBO>lambdaUpdate().setSql("follow_count=follow_count+1").eq(BizAccountBO::getId, accountId));
mybatisPlus坑
字段更新为null 默认不生效,除非加上updateStrategy = FieldStrategy.IGNORED
@ApiModelProperty(value = "贷款类型")
@TableField(value = "LOAN_TYPE", updateStrategy = FieldStrategy.IGNORED)
private String loanType;
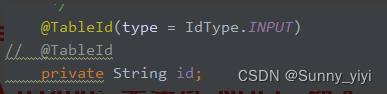
Cause: java.sql.SQLIntegrityConstraintViolationException: ORA-01400: 无法将 NULL 插入 (“ZHXY_RSW_LOCAL”.“T_EXAM_SUBJECT”.“ID”)
使用mybatis-plus插入时,明明设置了id的值,还报这个错
解决办法:在id字段上,添加 @TableId(type = IdType.INPUT)
条件是表中的某个字段不为null时,添加过滤
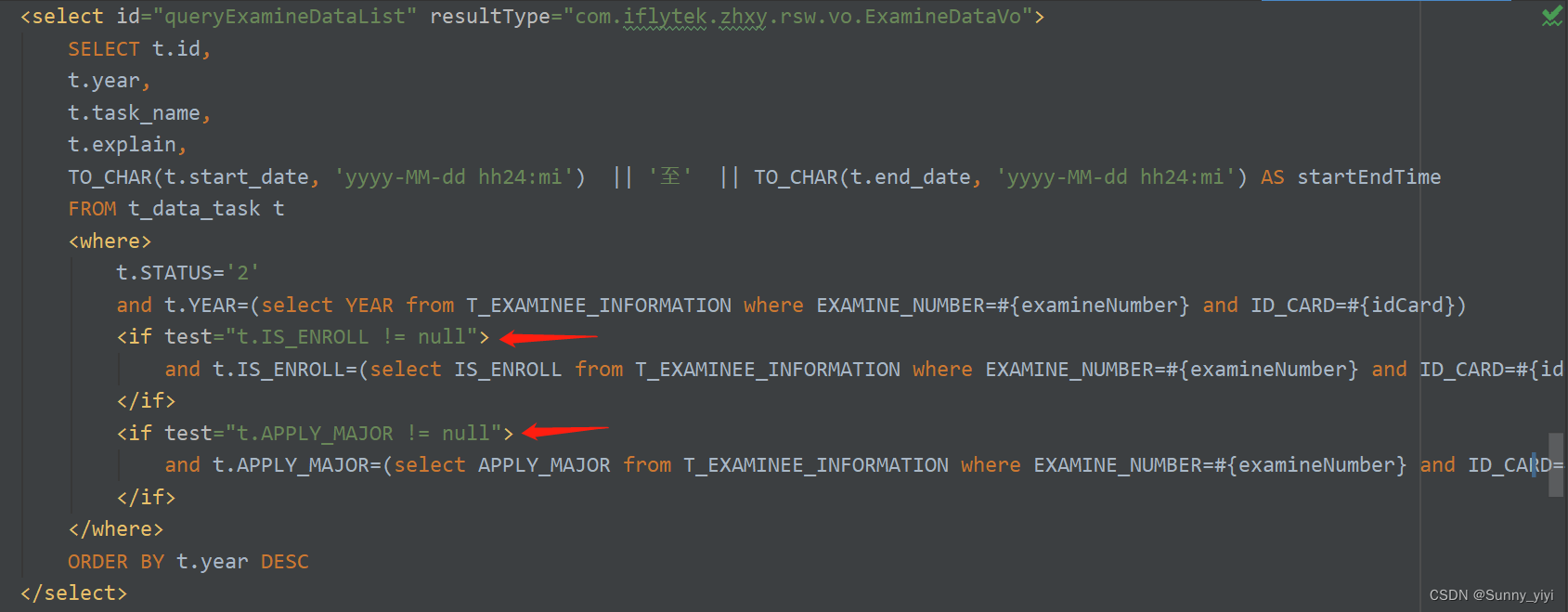
上面这样写会报错,下面这样写才对
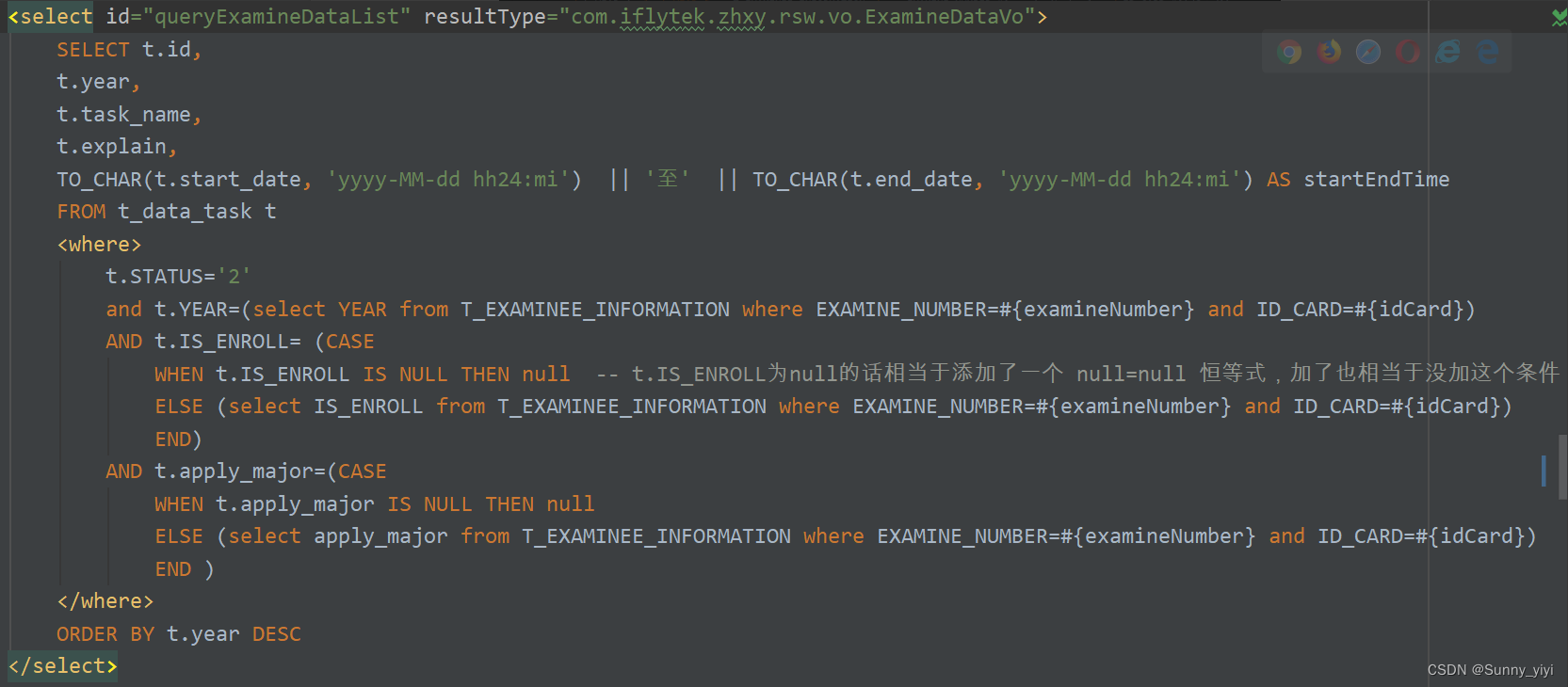
left join时左表过滤用where,右表过滤用and
说有下面两张表
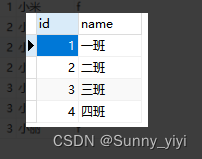
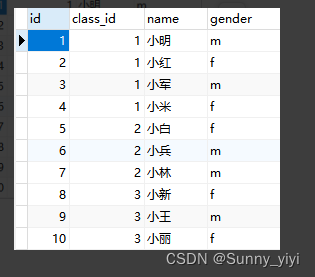
– 找出每个班级的名称及其对应的女同学数量
SELECT c.name, count(s.name) as num
FROM classes c left join students s
on s.class_id = c.id
and s.gender = 'f'
group by c.name
– 找出一班的同学总数
SELECT c.name, count(s.name) as num
FROM classes c left join students s
on s.class_id = c.id
where c.name = '一班'
group by c.name
mysql分组后 组内排序 然后取每组第一条结果
需求:按room_id分组后,组内按data_time排序,然后取每组的第一条数据
可能看不懂,但就这么写没错,亲测正确(必须加limit)
select t.* from (
select t1.room_id,t2.room_name,t1.queuing_time,t1.in_num
from t_meal_room t2
left join t_meal_data t1 on t1.room_id=t2.id
order by t1.data_time desc
limit 999999999
) t group by room_id
resultMap
适用场景:类似一个项目多个合同
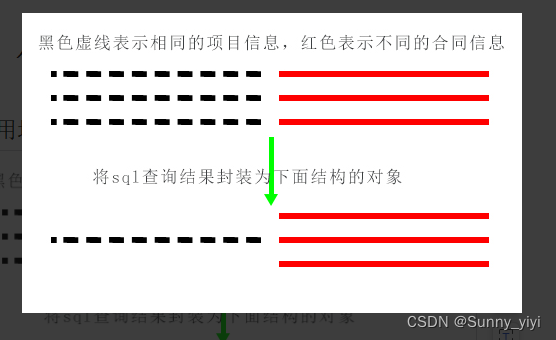
<resultMap id="projectManegeMap" type="com.iflytek.project.base.vo.resp.ProjMoneyManageVo">
<result column="PROJECT_ID" property="projectId"/>
<result column="PROJECT_NAME" property="projectName"/>
<result column="PROJECT_CODE" property="projectCode"/>
<result column="PROJECT_STAGE" property="projectStage"/>
<result column="ESTIMATED_INVESTMENT_AMOUNT" property="estimatedInvestmentAmount"/>
<!--ProjMoneyManageVo有属性 List<ContractInfo> contractList-->
<collection property="contractList" javaType="list" ofType="com.iflytek.project.base.vo.resp.ContractInfo">
<result column="CONTRACT_ID" property="contractId"/>
<result column="CONTRACT_MONEY" property="contractMoney"/>
<result column="SIGN_DATE" property="signDate"/>
<result column="PAYMENTS_NUM" property="paymentsNum"/>
<result column="CURRENT_NUM" property="currentNum"/>
<result column="PAYED_MONEY" property="payedMoney"/>
<result column="TOPAY_MONEY" property="topayMoney"/>
<result column="PAYMENTS_PER" property="paymentsPer"/>
<result column="PAYED_TOPAY" property="payedTopay"/>
<result column="PAYED_PER" property="payedPer"/>
</collection>
</resultMap>
in 占位符
mapper接口ids传数组String[]
List<TTopicFileStorage> selectFileList(@Param("ids") String[] ids, @Param("stage") String stage);
mapper.xml
and d.id IN
<foreach collection="ids" index="index" item="item" open="(" separator="," close=")">
#{item}
</foreach>
或者
mapper接口idList传列表List
List<ProjectFileResp> getProjectFileByIds(@Param("idList") List<String> idList);
mapper.xml
<if test='idList != null and idList.size() >0'>
and t.id in
<foreach collection="idList" item="id" open="(" close=")" separator=",">
#{id}
</foreach>
</if>
根据某个字段正序和倒叙排序
前端传过来排序的字段和如何排
sortField: rk_avg_score
sortOrder: asc
后端排序的时候使用 $ 代替#,这里只能用$, 用#不行 报错:ORA-01745: 无效的主机/绑定变量名
order by ${reqVo.sortField} ${reqVo.sortOrder}
函数使用
日期转为指定格式的字符串
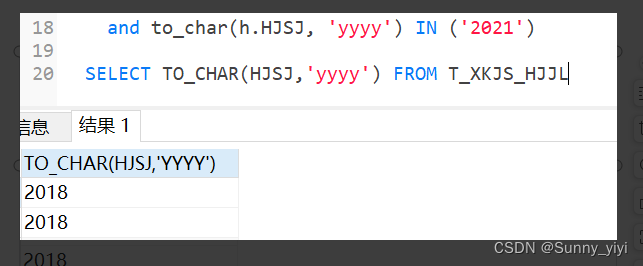
字符串转时间
AND h.HJSJ >= to_date('2021/01/01 00:00:00', 'YYYY-MM-DD hh24:mi:ss')
如果为null则显示0(oracle)
NVL(expr, 0)
MySQL中是
IFNULL(t4.CURRENT_NUM,0) CURRENT_NUM
保留两位小数
ROUND(expr, 2)
oracle批量插入
比循环一个一个插入快
mapper接口:
Integer insertCommonSelectUser(List<CommonSelectUser> list);
xml文件:
<insert id="insertCommonSelectUser" parameterType="java.util.List">
insert all
<foreach collection="list" item="item" index="index">
into COMMON_SELECT_USER(ID,REF_ID,REF_SRC,USER_CODE,USER_NAME)
values (#{item.id},#{item.refId},#{item.refSrc},#{item.userCode},#{item.userName})
</foreach>
SELECT 1 FROM DUAL
</insert>
插入系统当前时间
oracle:sysdate
mysql:now()
将这种查询结果封装为list套list结构
想要的效果:公共的流程类别信息提出来,里面包含所有该类别的流程信息列表
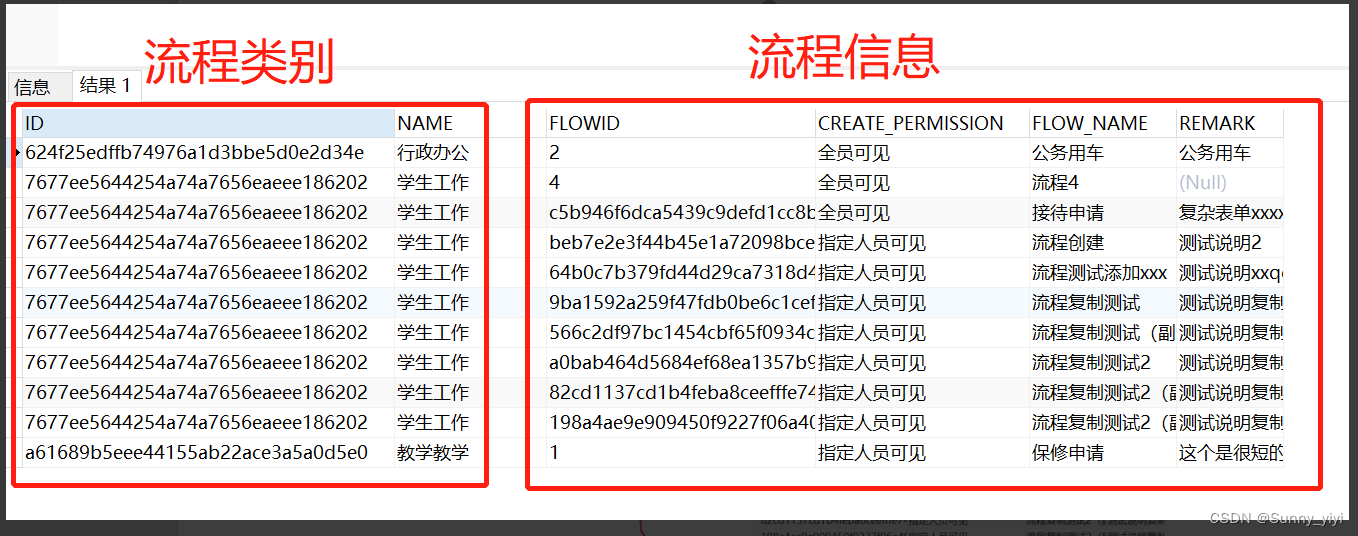

返回结果结构:
[
{
"id":"624f25edffb74976a1d3bbe5d0e2d34e", //流程类别id
"name":"行政办公", //流程类别名称
"flowList":[ //该流程类别下的所有流程信息列表
{
"id":"2",
"createPermission":"全员可见",
"flowName":"公务用车",
"lcbm":null,
"remark":"公务用车"
}
]
},
{
"id":"7677ee5644254a74a7656eaeee186202",
"name":"学生工作",
"flowList":[
{
"id":"4",
"createPermission":"全员可见",
"flowName":"流程4",
"lcbm":null,
"remark":null
},
{
"createUser":null,
"createDate":null,
"opUser":null,
"opDate":null,
"activeFlag":null,
"id":"c5b946f6dca5439c9defd1cc8b700dae",
"createPermission":"全员可见",
"flowName":"接待申请",
"lcbm":null,
"remark":"复杂表单xxxx"
}
]
},
{
"id":"a61689b5eee44155ab22ace3a5a0d5e0",
"name":"教学教学",
"flowList":[
{
"id":"1",
"createPermission":"指定人员可见",
"flowName":"保修申请",
"lcbm":null,
"remark":"这个是很短的一个说明"
}
]
}
]
怎么实现? 返回结果使用resultMap
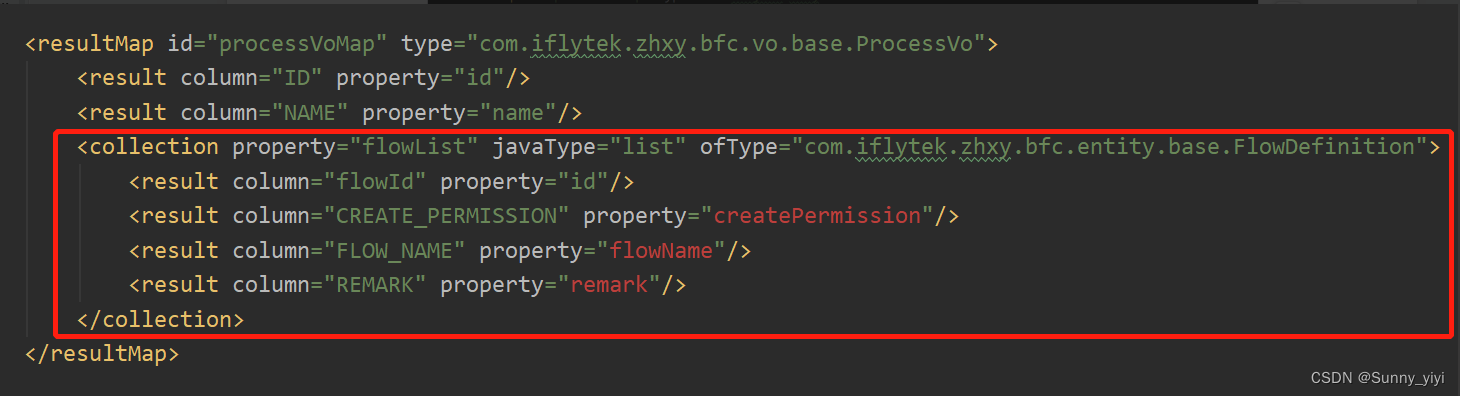
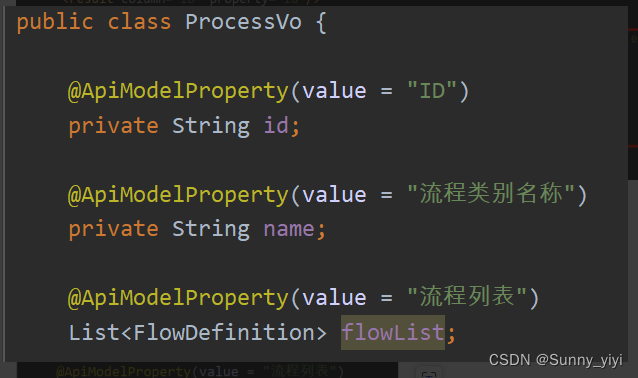
GROUP BY
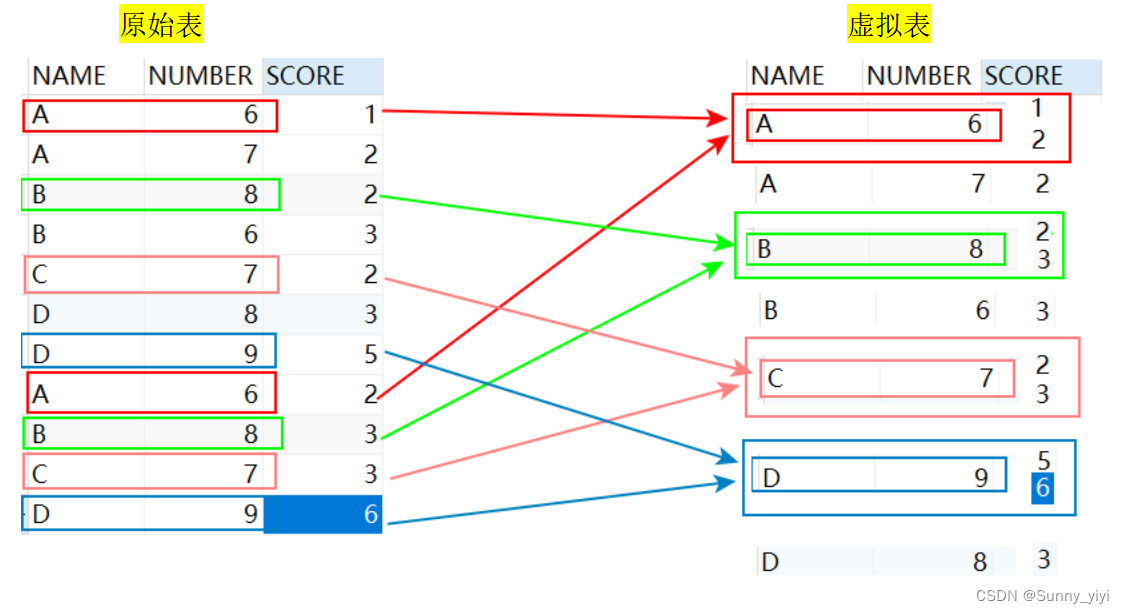
test原始表
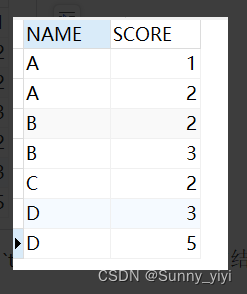
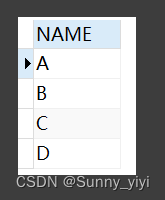
SELECT NAME FROM test GROUP BY NAME 的结果:
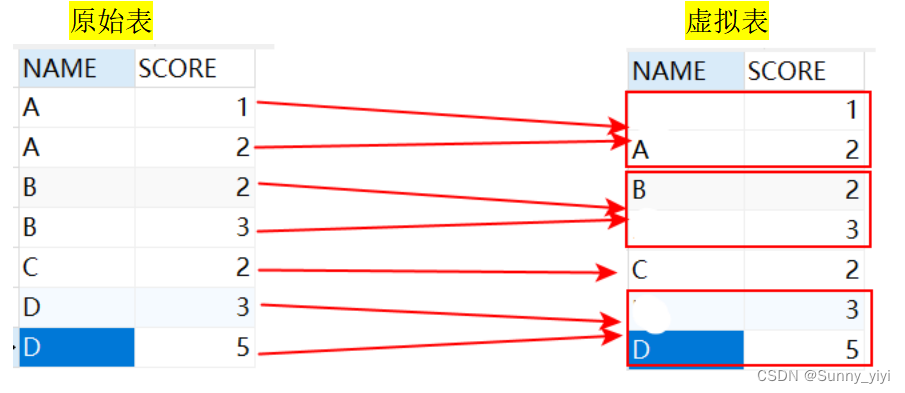
理解分析:GROUP BY NAME
该句执行后,我们想象生成了虚拟表3,如下所图所示,生成过程是这样的:group by name,那么找name那一列,具有相同name值的行,合并成一行,接下来对这个虚拟表执行select操作,如果执行select * 因为SCORE有两个数据,所以会报错,对于SCORE这样多个值得该怎么办呢?答案就是聚合函数
GROUP BY多个字段
例如: GROUP BY NAME,NUMBER我们可以把name和number 看成一个整体字段,以他们整体来进行分组的。如下图
SELECT NAME,AVG(SCORE) AVG FROM test GROUP BY NAME,NUMBER 结果为:

GROUP BY统计
有这样一张表:
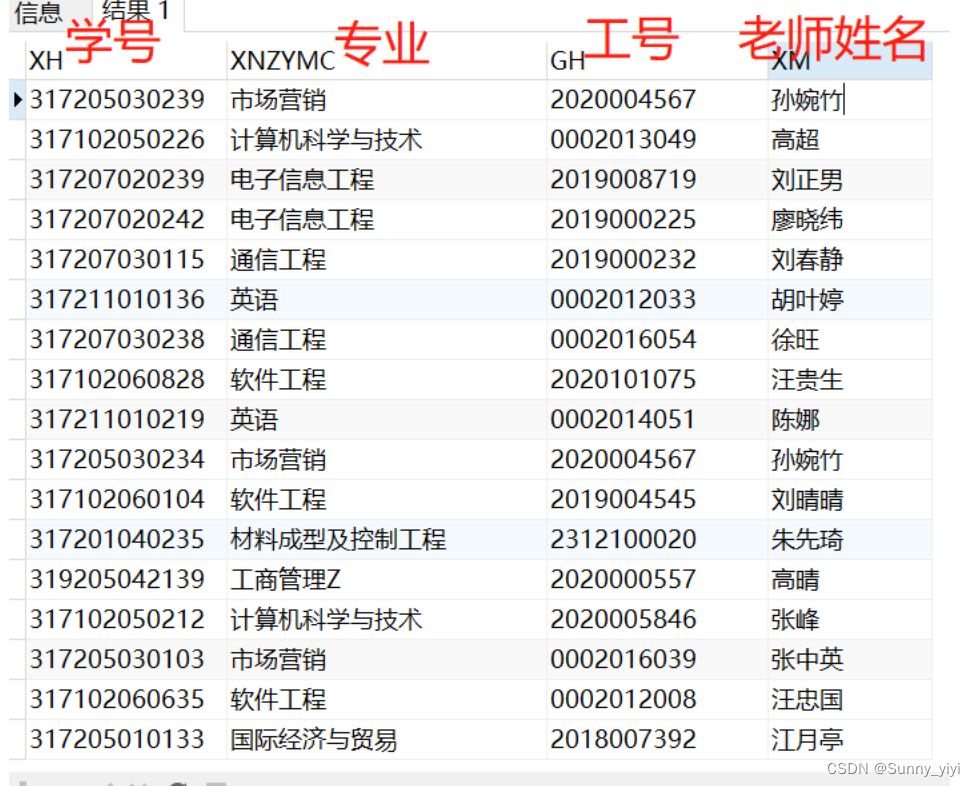
统计:按专业为维度,统计每个专业 老师平均指导学生数量
思路:用专业分组,统计所有的学生数/所有的老师数
SELECT x.XNZYMC, ROUND(COUNT(x.XH)/COUNT(DISTINCT x.GH), 0) ZDXSS
From x
GROUP BY x.XNZYMC
HAVING COUNT(1) > 1
SELECT COMMENT_ID
FROM COMMENT_COMMENTTAG
WHERE POST_ID = 1
GROUP BY COMMENT_ID, COMMENT_TAG
HAVING COUNT(1) > 1
根据COMMENT_ID 和 COMMENT_TAG分组后取数量大于1的COMMENT_ID
深入理解JOIN
select * from student
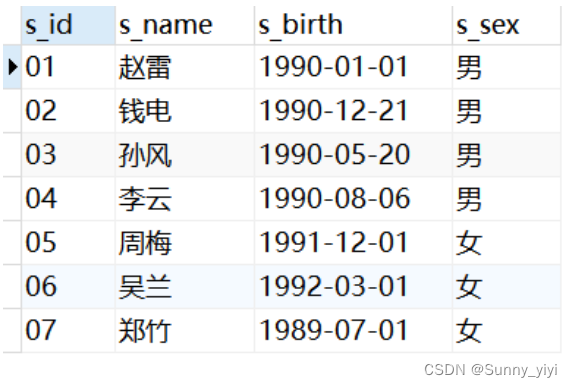
select * from score
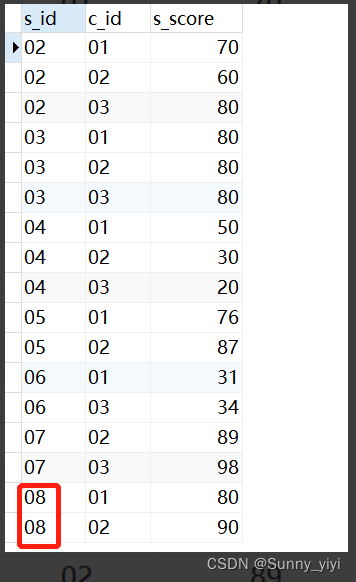
select a.* ,b.* from student a join score b on a.s_id=b.s_id
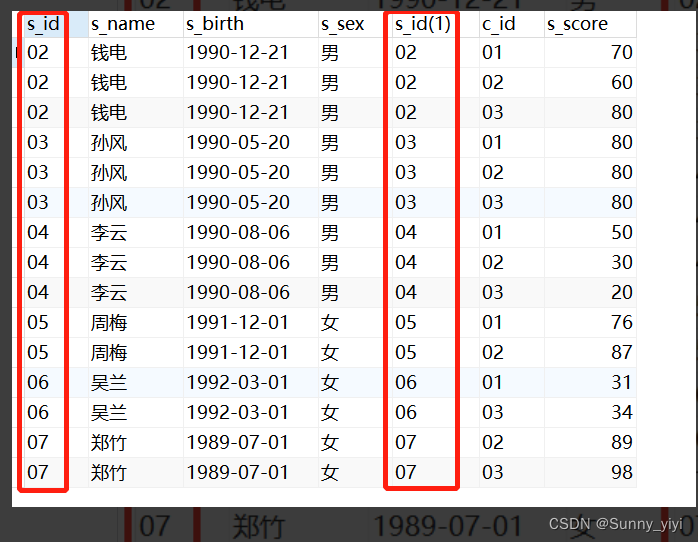
select a.* ,b.* from student a left join score b on a.s_id=b.s_id
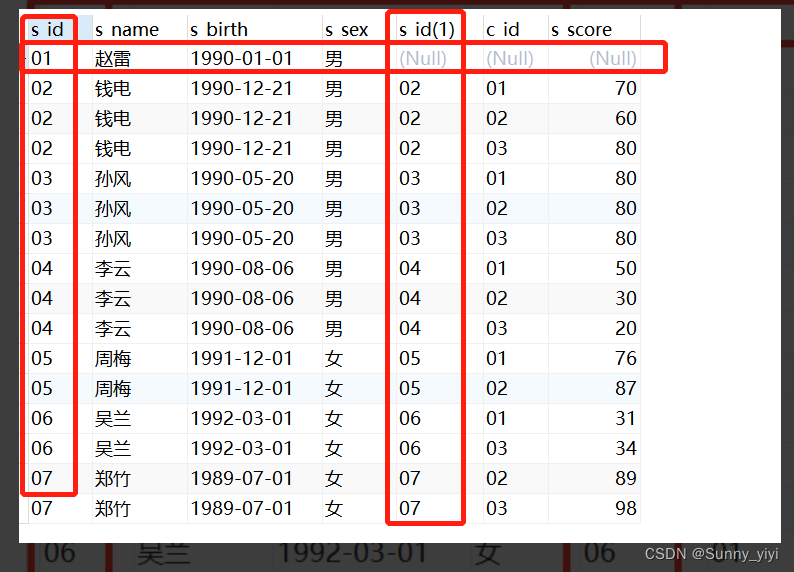
由此可见join或者left join都是以数据多的一张表为基表,数据少表的根据关联字段匹配到数据多的表。
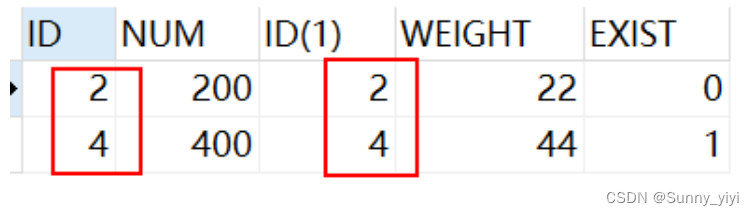
LEFT JOIN ON 和 JOIN ON
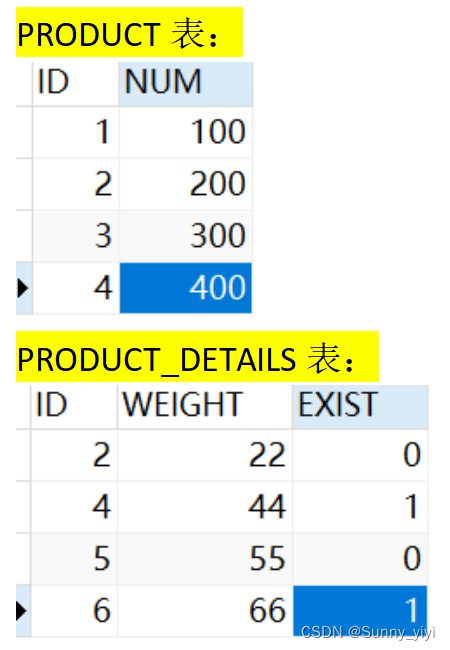
SELECT * FROM `product` t1 LEFT JOIN `product_details` t2 ON t1.ID=t2.ID
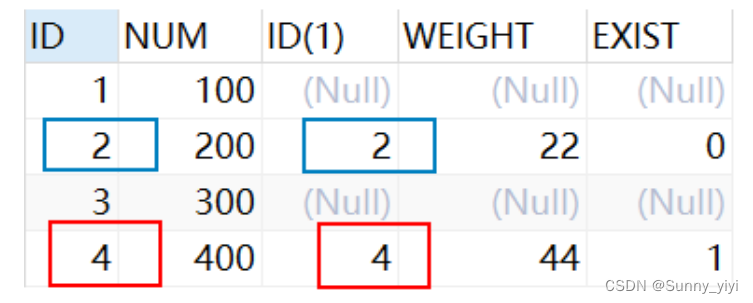
分析理解:把两张表水平拼接在一起,左表全部查出来,根据条件来匹配出右表,不匹配的右表用null代替。
JOIN ON相当于在LEFT JOIN ON的基础上,将右表不匹配的记录null删除
SELECT * FROM `product` t1 JOIN `product_details` t2 ON t1.ID=t2.ID
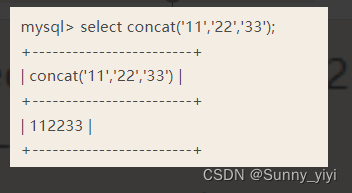
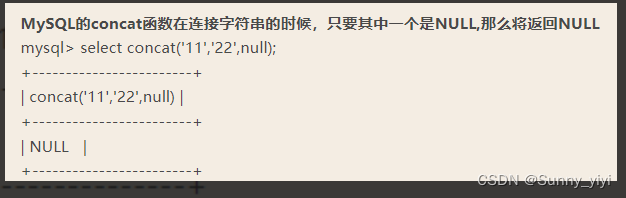
MySQL中的concat
concat(str1,str2,…)
Oracle中的||(类似MySQL中的concat)拼接字段
Oracle中的concat() 与 ‘||’ 不同在于,concat()只能对两个字符串进行拼接(字符串多的话只能嵌套使用),而||可以对字符串无限拼接。跟MySQL中的concat一样。
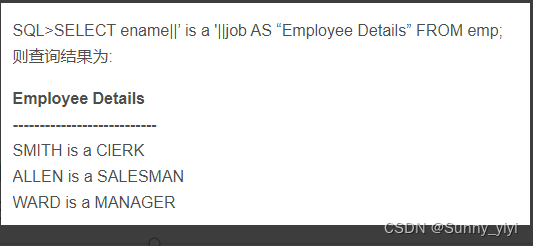
Mysql 中group_concat
使用情况:

select t3.*,group_concat(t4.GROUP_NAME separator',') groupName
from t3
left join t4 on t4.ID=t3.AREA_ID
Oracle中WM_CONCAT
功能类似MySQL的group_concat
原表:

结果:

做法:
第一步:先将原表两个字段CAPACITY, SCORE合并为一个字段CAPACITY_SCORE
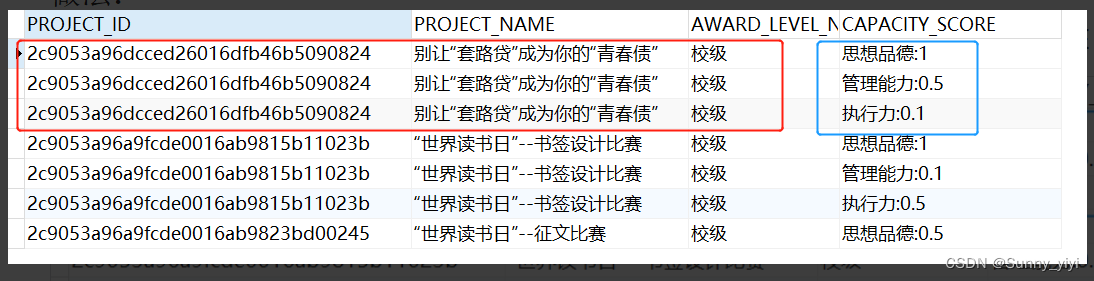
SELECT PROJECT_ID,PROJECT_NAME,AWARD_LEVEL_NAME,
CONCAT(CONCAT(t4.CAPACITY_NAME, ':'), t3.SCORE) CAPACITY_SCORE
FROM XXX ...
第二步:再将合并后的结果列转行

SELECT PROJECT_ID,PROJECT_NAME,AWARD_LEVEL_NAME,
TO_CHAR(WM_CONCAT(CAPACITY_SCORE)) GROUP_CAPACITY_SCORE
FROM (
SELECT PROJECT_ID,PROJECT_NAME,AWARD_LEVEL_NAME,
CONCAT(CONCAT(t4.CAPACITY_NAME, ':'), t3.SCORE) CAPACITY_SCORE
FROM XXX ...
) tt GROUP BY PROJECT_ID,PROJECT_NAME,AWARD_LEVEL_NAME
注意1:SELECT 的字段都要再GROUP BY中分组,否则出现 > ORA-00979: not a GROUP BY expression
注意2:TO_CHAR(WM_CONCAT())配套使用,单独使用WM_CONCAT()查询很慢
Oracle中listagg列转行
有这样一个字典表

需求结果
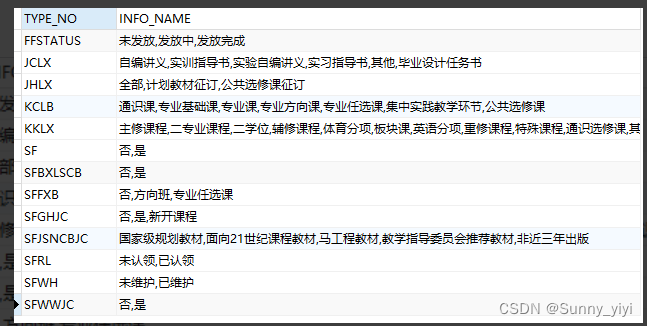

如果T_BOOKS_TEACHER表中is_Lately_Three字段存了上面字典表中的TYPE_NO为SFJSNCBJC的多个INFO_CODE,查询的时候要求翻译过来
SELECT
b.IS_LATELY_THREE,
(
SELECT listagg(info_name, ',') WITHIN GROUP(ORDER BY info_code)
FROM t_dict_info
WHERE type_no = 'SFJSNCBJC'
AND info_code IN
((SELECT REGEXP_SUBSTR(b.is_Lately_Three, '[^,]+', 1, LEVEL, 'i') AS STR
FROM DUAL
CONNECT BY LEVEL <= LENGTH(b.is_Lately_Three) -
LENGTH(REGEXP_REPLACE(b.is_Lately_Three, ',', '')) + 1))
) isLatelyThreeName
FROM
T_BOOKS_TEACHER b
where
b.PLAN_ID='3031e8270f7241bb9d93b527e1dbcb77'

DECODE 函数(好用,有点像case when)
decode(条件,值1,返回值1,值2,返回值2,…值n,返回值n,缺省值)
SELECT DECODE(t.SSEX, null,‘未知’,‘1’,‘男’,‘0’,‘女’, ‘男’) SEX
FROM STUDENTS t

CASE WHEN(MySQL和Oracle)
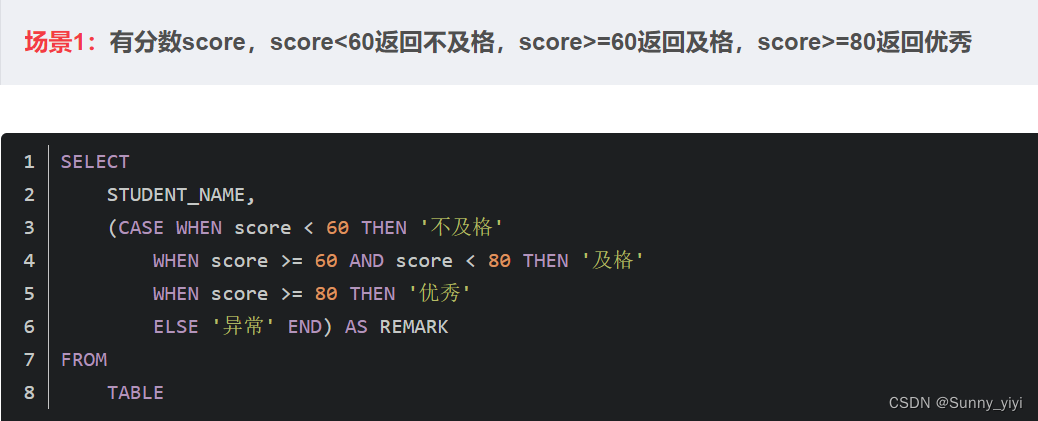

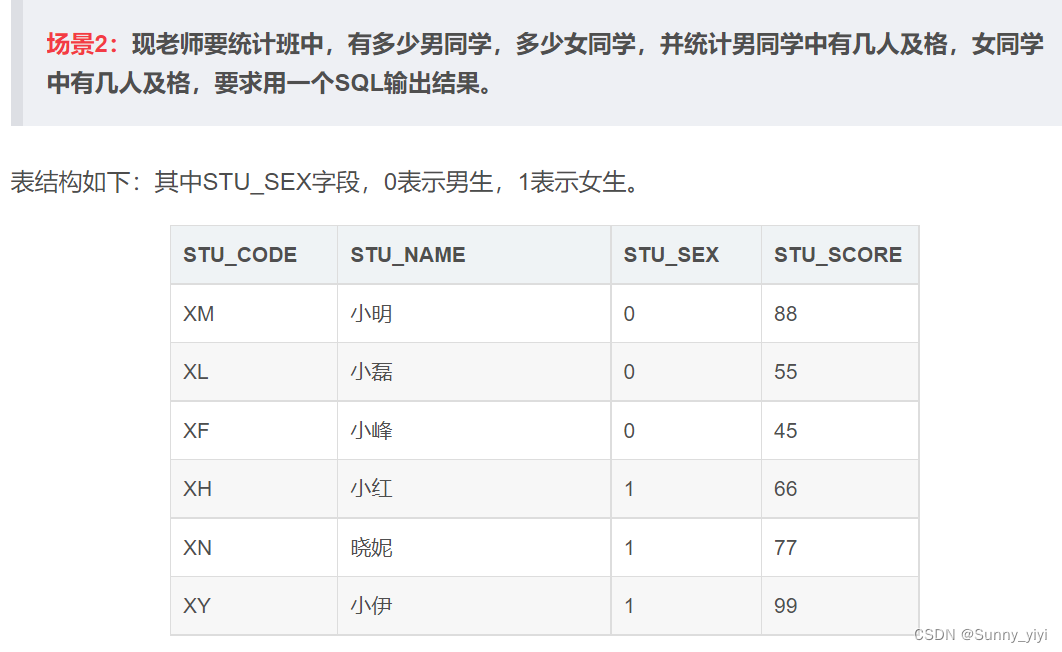
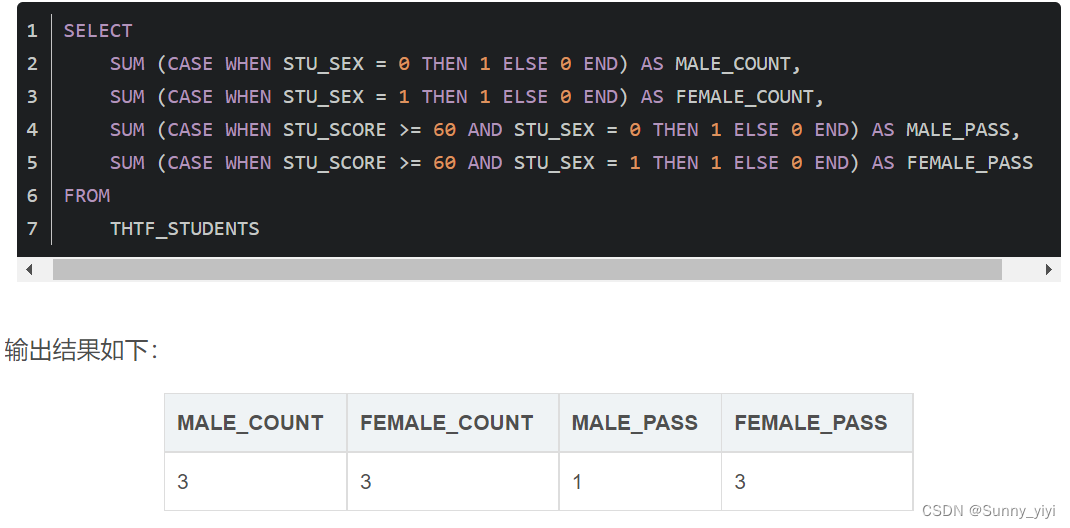
CASE WHEN实现行转列
现有表
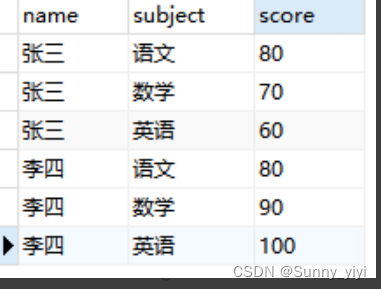
需求是
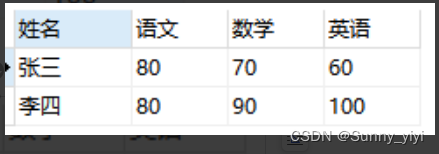
方法1:临时表

方法2:静态sql
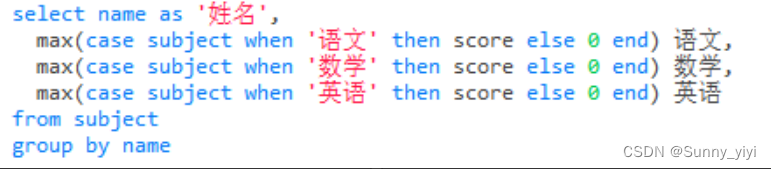
统计(MySQL 字段符合条件+1)
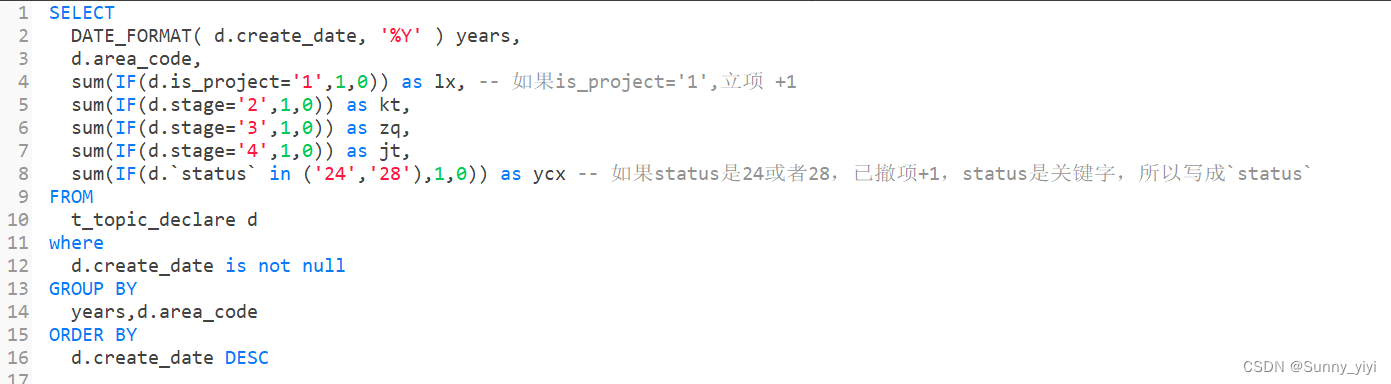
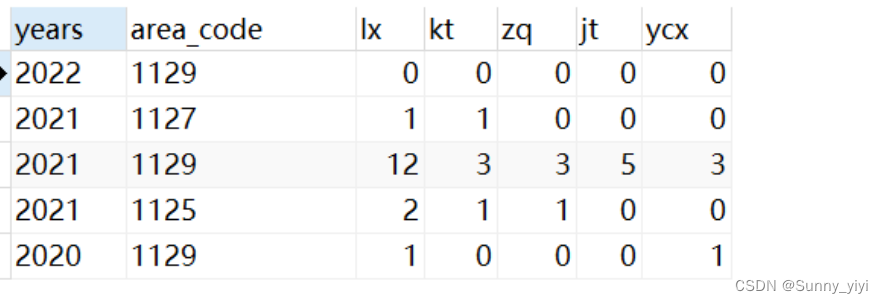
两张表table1和table2根据一个字段id相同,将table2的name字段值设置为table1对应id的name值
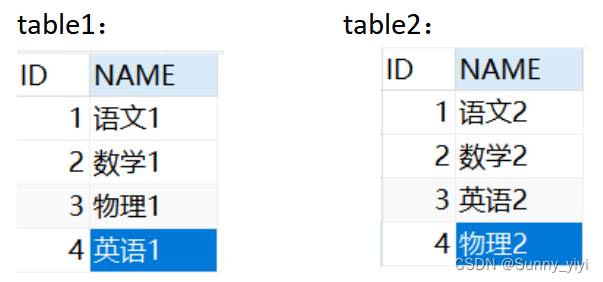

结果table2:

合并两个查询的结果集
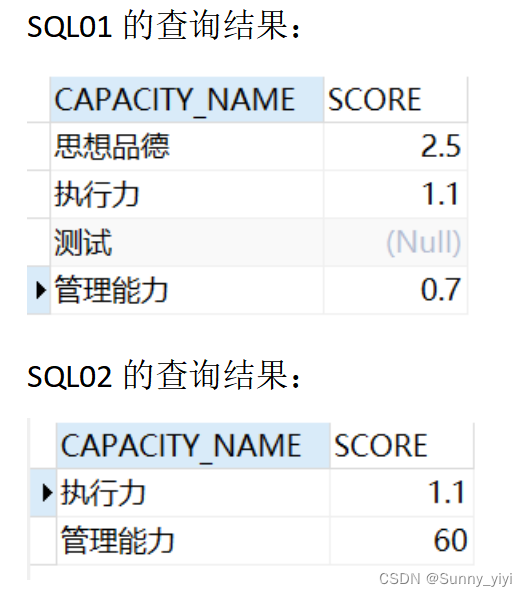
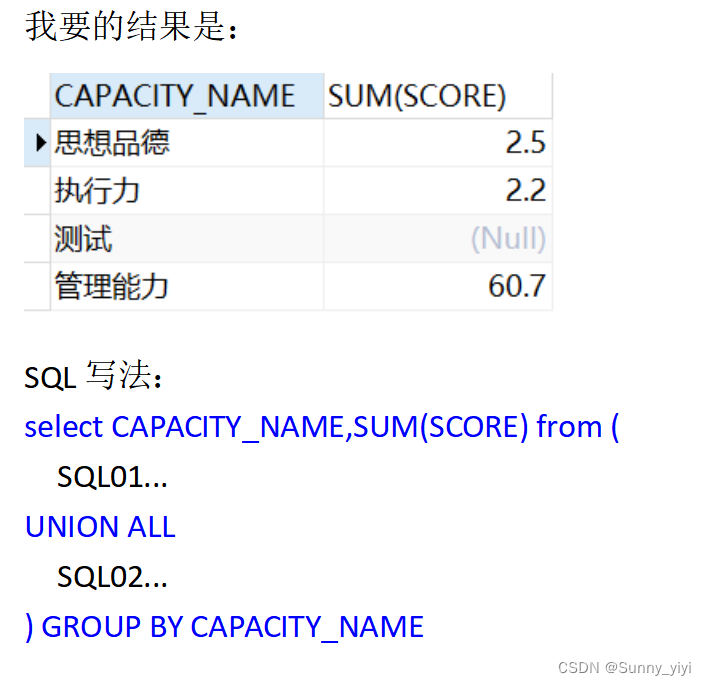
union all
把两个SQL的结果叠加在一起,常用来代替or
(
select max(t.WHICH_ROUND) WHICH_ROUND,
t.PROJECT_ID id
from t_biz_file t
join t_biz_project t1
on t1.ID = t.BELONG_ID and t.BELONG_TYPE = 'LX' and t1.STATE != 'ZC'
group by t.PROJECT_ID
)
union all
(
select max(t.WHICH_ROUND) WHICH_ROUND,
tbm.ID
from t_biz_file t
join t_biz_project t1 on t1.ID = t.PROJECT_ID and t.BELONG_TYPE = 'SH'
join t_biz_meeting tbm on t.BELONG_ID = tbm.id and tbm.STATE != 'ZC'
group by tbm.ID
)
排序的字段有null的
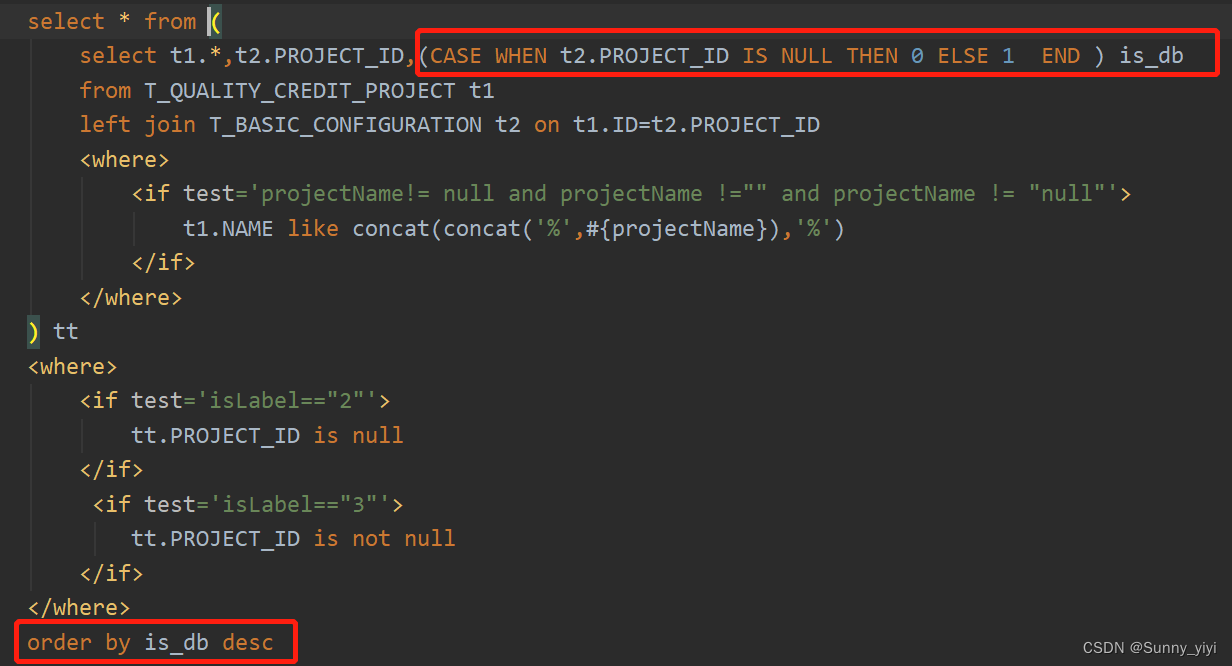
传多个参数,可以使用map也可以使用@Param注解或者使用reqVo对象
使用了@Param注解,xml中就要使用注解中的字符串.属性
使用map
mapper.xml (如果mapper接口中添加了@Param(“map”),那xml中使用要加map.password这样,没加@Param注解,就不需要加map. 跟javaBean一致)
<!--根据邮件数字字符串区间查询-->
<select id="findByEmailArea" resultType="cn.tedu.store.entity.User">
select * from t_user where email between #{startEmail} and #{endEmail} and password=#{password}
</select>
mapper接口
List<User> findByEmailArea(Map<String,String> map);
单元测试
@Test
public void findByEmailArea(){
HashMap<String, String> map = new HashMap<>();
map.put("startEmail","12346");
map.put("endEmail","12349");
map.put("password","zhu");
List<User> list = mapper.findByEmailArea(map);
for (User user:list) {
System.err.println(user);
}
}
使用@Param注解
Mapper.xml跟上面一样,将参数用#{}占位替代
Mapper接口
List<User> findByEmailArea(@Param("startEmail") String startEmail,
@Param("endEmail") String endEmail,
@Param("password") String password
);
单元测试:
String startEmail="12346";
String endEmail="12349";
String password="zhu";
List<User> list = mapper.findByEmailArea(startEmail,endEmail,password);
for (User user:list) {
System.err.println(user);
}
另外,使用@Param注解,如果传入的是一个对象,在xml中使用这个对象中的属性时,需要使用@Param注解中的字符串.属性 来获得
例如
Page<TEnterpriseResources> selectListByCondition(Page<TEnterpriseResources> page, @Param("query") TEnterpriseResourcesReqVo query);
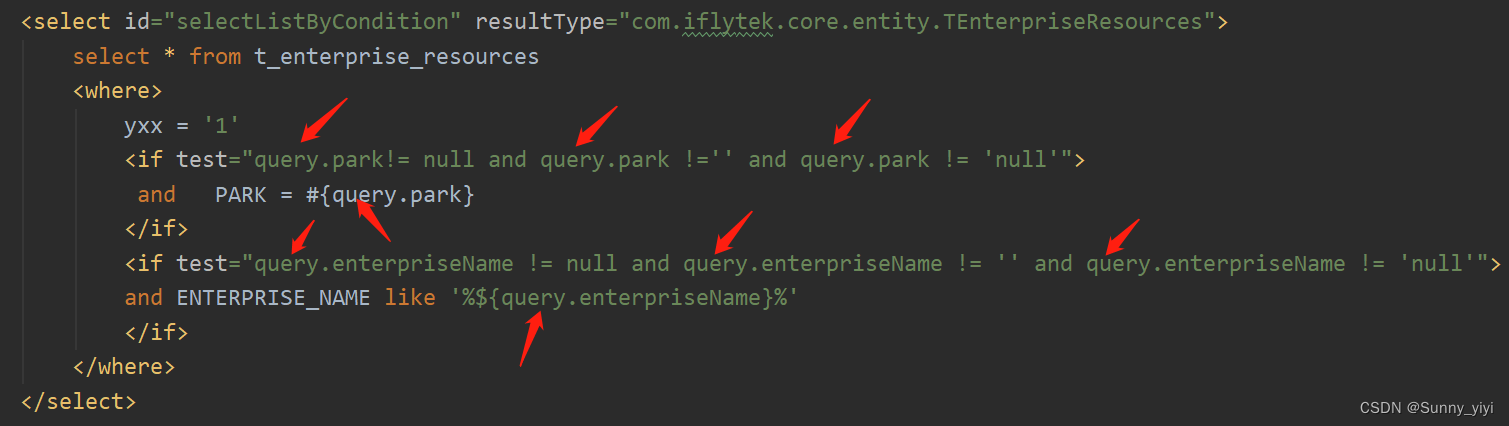
使用reqVo对象
vo对象

mapper接口
Integer selectAlarmCount(BeginEndTimeVo vo);
mapper.xml (如果mapper接口中添加了@Param(“vo”),那xml中使用要加vo.beginTime这样,没加@Param注解,就不需要加vo. 跟Map一致)

动态SQL
注意:test后面的条件,单引号写在外面,双引号写在里面,切记!否则会出现条件不起作用的情况(特别是字符串,一定是这样)
查询:
<select id="selectListByCondition" resultType="com.iflytek.core.entity.TEnterpriseResources">
select * from t_enterprise_resources
<where>
yxx = '1'
<if test='query.park!= null and query.park !="" and query.park != "null"'>
and PARK = #{query.park}
</if>
<if test='query.enterpriseName != null and query.enterpriseName != "" and query.enterpriseName != "null"'>
and ENTERPRISE_NAME like '%${query.enterpriseName}%'
</if>
<if test='query.status != null and query.status != "" and query.status != "null"'>
and STATUS = #{query.status}
</if>
<if test='query.tag != "0" and query.tag != null and query.tag != "" and query.tag != "null"'>
and KEY_ENTERPRISES = '1'
</if>
<if test='query.tag != "1" and query.tag != null and query.tag != "" and query.tag != "null"'>
and INVALID_ENTERPRISE = '0'
</if>
</where>
</select>
更新:
Mapper接口
/*根据code批量废弃服务站*/
Integer abandonedByCodes(@Param("codes") List<String> codes);
Xml
<update id="abandonedByCodes" parameterType="java.util.List">
update appoint_dealer
set STATUS='0'
where CODE in
<foreach collection="codes" open="(" close=")" separator="," item="code">
#{code}
</foreach>
</update>
update ${bindTable} set
<foreach collection="inputControls" separator="," item="item">
${item.bindColumn} = #{item.value}
</foreach>
where ID=#{id}
删除:
service:
void delete(String id);
serviceImpl:
@Override
public void delete(String ids) {
if(StringUtils.isNotBlank(ids)){
String[] idArr = ids.split(",");
mapper.delete(idArr);
}
}
mapper接口:
void delete(@Param("idArr")String[] idArr);
mapper.xml
<select id="delete">
<if test="idArr != null and idArr.length != 0 ">
update t_instructor_resource set yxx = '0' where id in
<foreach collection="idArr" item="resourceId" index="index" open="(" close=")" separator=",">
#{resourceId}
</foreach>
</if>
</select>
新增:
<if test='query.fileIdList != null and query.fileIdList.size() >0'>
and t.id in
<foreach collection="query.fileIdList" item="id" open="(" close=")" separator=",">
#{id}
</foreach>
</if>
<!-- sql片段对应字段名,id属性值任意 -->
<sql id="key">
<!-- 去掉最后一个, -->
<trim suffixOverrides=",">
<if test="id!=null">
students_id,
</if>
<if test="name!=null">
students_name,
</if>
<if test="sal!=null">
students_sal,
</if>
</trim>
</sql>
<!-- sql片段,最后一个逗号必须用<trim>去除-->
<sql id="value">
<!-- 去掉最后一个, -->
<trim suffixOverrides=",">
<if test="id!=null">
#{id},
</if>
<if test="name!=null">
#{name},
</if>
<if test="sal!=null">
#{sal},
</if>
</trim>
</sql>
<!-- <include refid="key"/>和<include refid="value"/>表示引用上面定义的sql片段 -->
<insert id="dynaInsert" parameterType="cn.itcast.javaee.mybatis.app14.Student">
insert into students(<include refid="key"/>) values(<include refid="value"/>)
</insert>
if else switch case写法
<if test='query.carType!=null and query.carType!=""'>
<choose>
<when test='query.carType=="unknown"'>
and t1.CAR_TYPE is null
</when>
<when test='query.carType=="unknown2"'>
... 这里可以多个when条件,类似swach case
</when>
<otherwise>
and t1.CAR_TYPE=#{query.carType}
</otherwise>
</choose>
</if>
时间范围过滤
mysql日期时间 根据日期范围过滤
表数据:

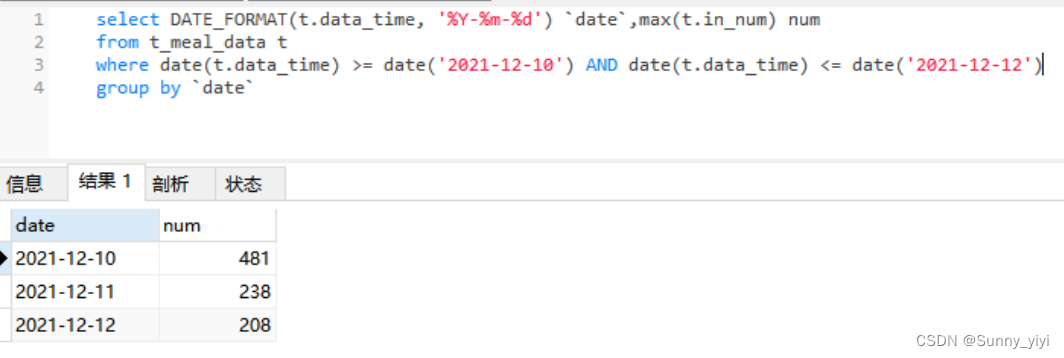
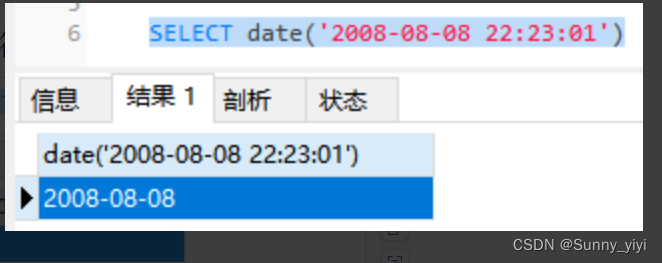
date函数将字符串类型的日期或时间 转为对应的日期
时间范围拼接
where ALARM_TIME <![CDATA[>]]> concat(#{year},'-12-01 00:00:00') and ALARM_TIME <![CDATA[<=]]> concat(#{year},'-12-31 23:59:59')
本年
<if test='query.type == "2"'>
and ALARM_TIME <![CDATA[>]]> (SELECT DATE_FORMAT(now(), '%Y-01-01 00:00:00'))
and ALARM_TIME <![CDATA[<=]]> (SELECT DATE_FORMAT(now(), '%Y-12-31 23:59:59'))
</if>
本月
<if test='query.type == "3"'>
and ALARM_TIME <![CDATA[>]]> (SELECT DATE_FORMAT(DATE_SUB(NOW(),INTERVAL (DAYOFMONTH(NOW())-1) day),'%Y-%m-%d 00:00:00'))
and ALARM_TIME <![CDATA[<=]]> (SELECT DATE_FORMAT( LAST_DAY(NOW()),'%Y-%m-%d 23:59:59'))
</if>
字符串日期比较大小
字符串转为Long然后比较大小
String inputDate = (String)map.get("INPUT_DATE");
Long input = Long.valueOf(inputDate.replaceAll("[-\\s:]", ""));
模糊查询
<if test='query.userName!=null and query.userName!=""'>
and t1.USER_NAME like concat('%',#{query.userName},'%')
</if>
或者
<if test='query.userName!=null and query.userName!=""'>
and t1.USER_NAME like concat(concat('%',#{query.userName}),'%')
</if>
或者
<if test='courseVo.bookName!=null and courseVo.bookName!="" '>
<bind name="bookName" value=" '%'+courseVo.bookName+'%' "/>
and (t2.book_name like #{bookName} or t2.ISBN like #{bookName})
</if>
使用HashMap可以接收所有查询的返回
一条记录就是一个Map,其中key就是字段名,value就是该条记录的数据
mapper.xml
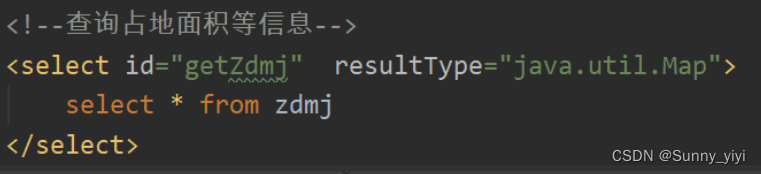
mapper.java





![[C++] 类和对象 _ 剖析构造、析构与拷贝](https://img-blog.csdnimg.cn/img_convert/0980a36b43766541867344fa64655988.png)