大部分教程只讲如何打印含有NA的列或行。这个函数可以直接定位到单元格,当dataframe的行和列都很多的时候更加直观。
# Finding NaN locations for df.loc
def locate_na(df):
nan_indices = set()
nan_columns = set()
for col, vals in df_descriptors.items():
for index, val in vals.items():
if pd.isna(val):
nan_indices.add(index)
nan_columns.add(col)
# Use df.loc with the found indices and columns
nan_values = df.loc[list(nan_indices), list(nan_columns)]
return nan_values.drop_duplicates()
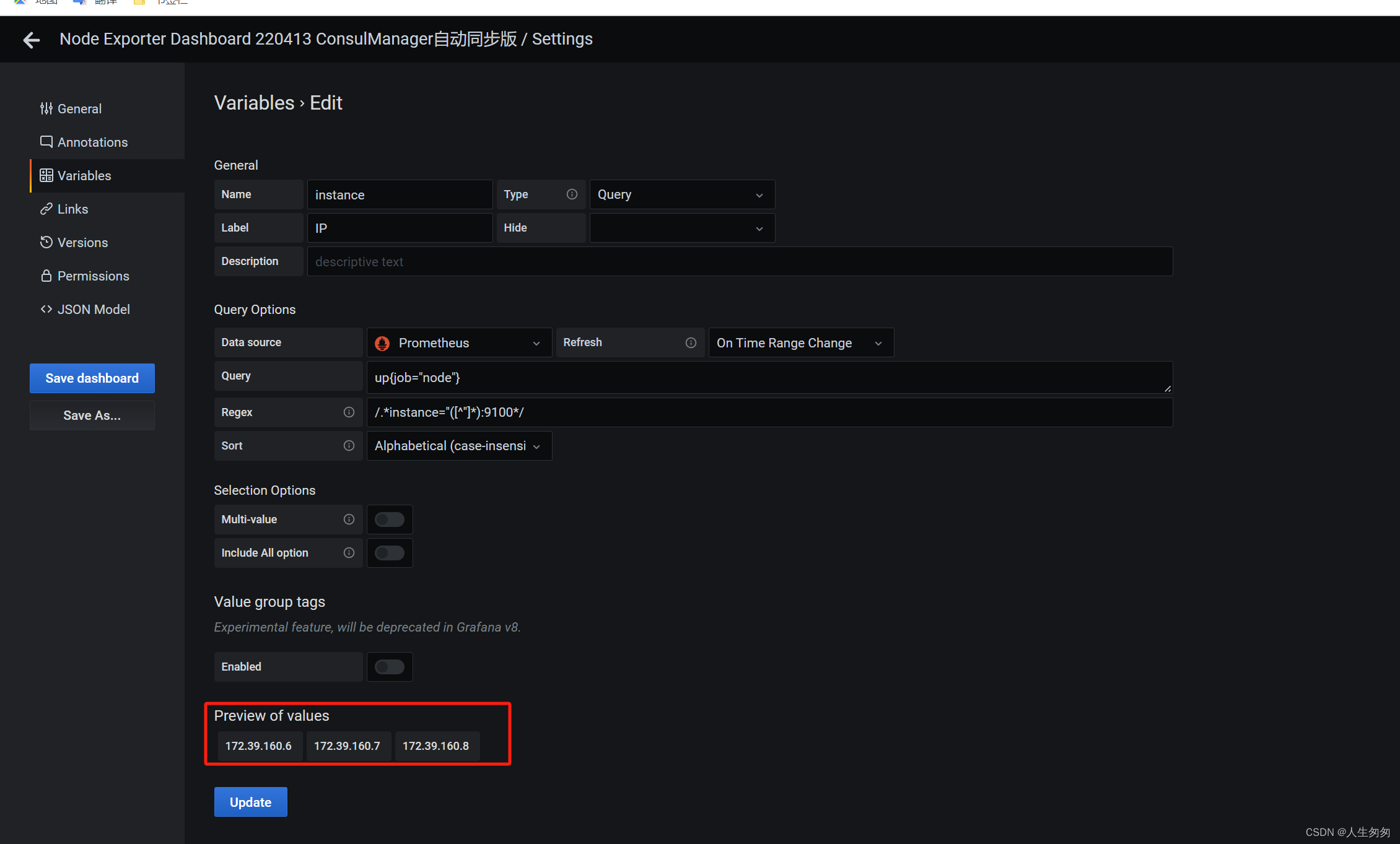
效果如下:

再附加一个寻找非数值单元格的方法:
df.select_dtypes(exclude=[float, int])

![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-6.5](https://img-blog.csdnimg.cn/direct/af3bbc40a90646d1809e9eff2cc45597.png)