Xtuner学习视频
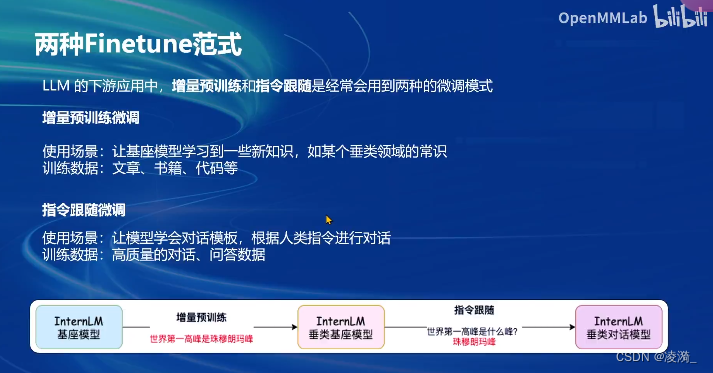
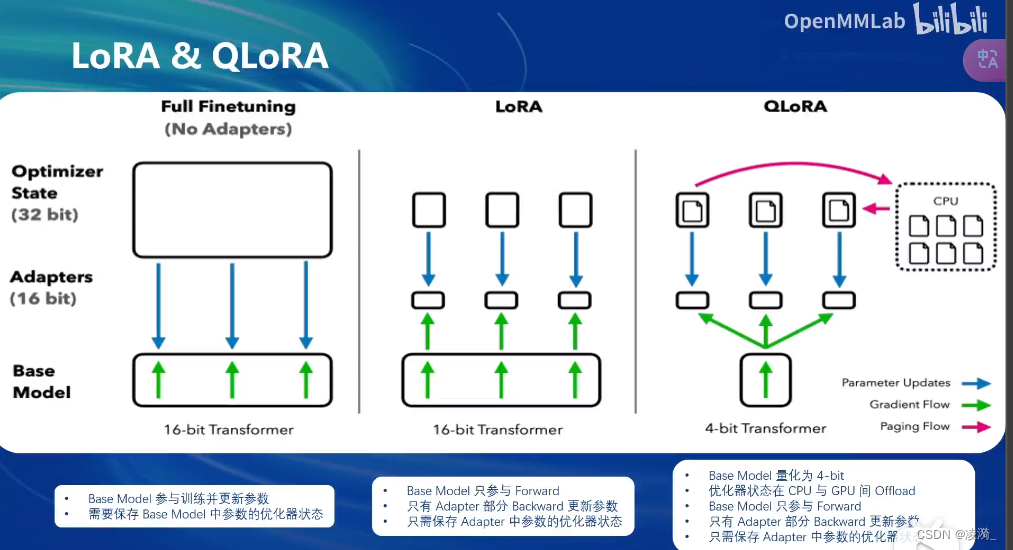
两种微调范式
在指令微调的过程中,需要高质量的对话数据。
而构建高质量的对话(指令)数据,则涉及到以下流程

- 先通过system/user/assistant的json格式来构造对话模板,把问题和期望模型做出的回答通过这样的格式进行封装
- 不同的模型有不同的模板来区分system/user/assitant的字段,即一些特殊字符
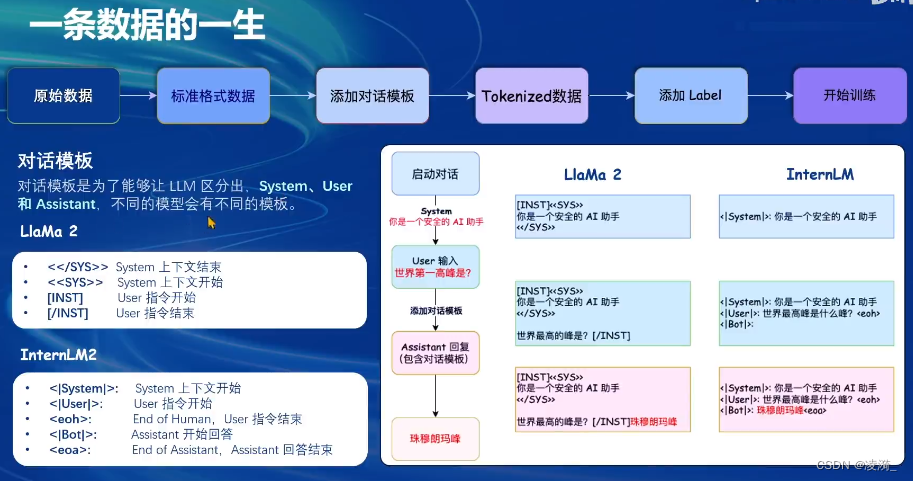
真正喂给模型的东西是经过chat template包装后的内容
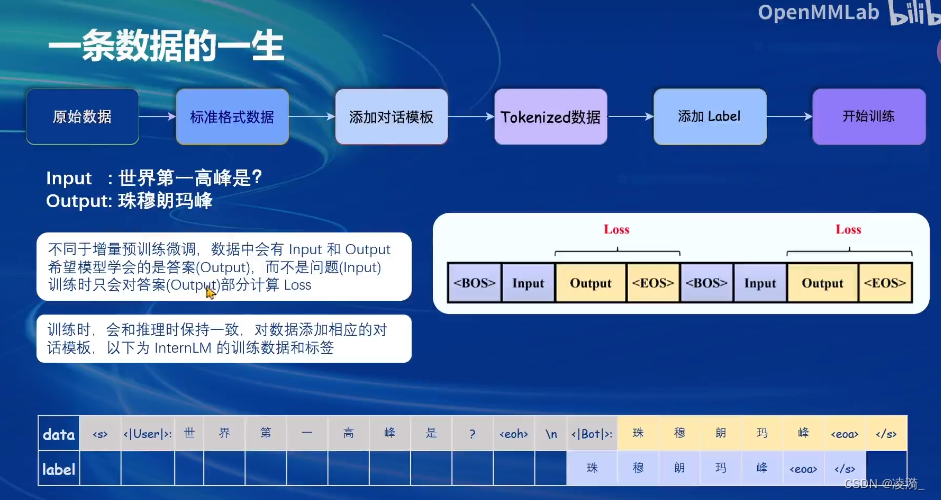
模型只会对【输入的信息里的assitant输出的答案进行loss计算】
微调方案
lora
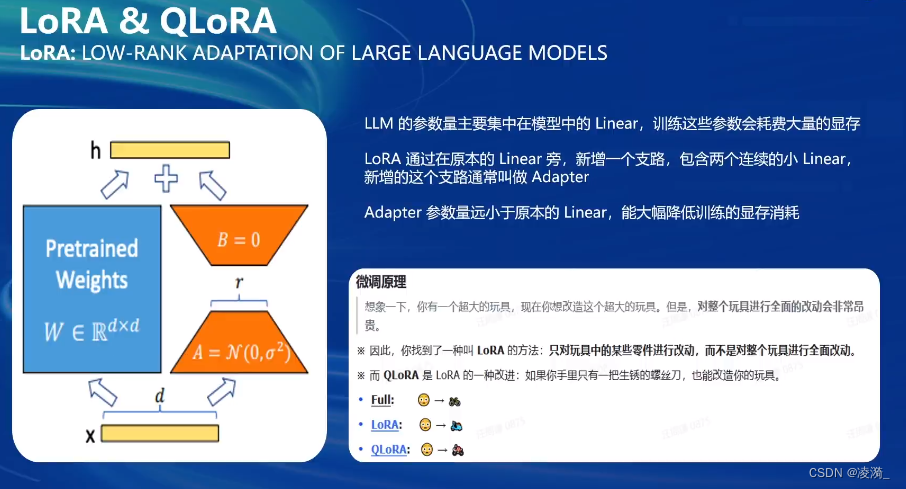
Qlora
全参数微调是整个模型加载到内存中,并且所有参数的优化器状态也会加载
lora微调是整个模型参数加载到内存中,但是只加载lora的部分参数的优化器状态
qlora是整个模型的参数都以4bit的形式加载

![[NISACTF 2022]bilala的二维码](https://img-blog.csdnimg.cn/direct/c2aff0ddf7c34e4b87b2625e98b676b6.png)







![Github进行fork后如何与原仓库同步[解决git clone 太慢的问题]](https://img-blog.csdnimg.cn/direct/3a1adaf9acd744c88a0ed7171dcc0f67.png#pic_center)
