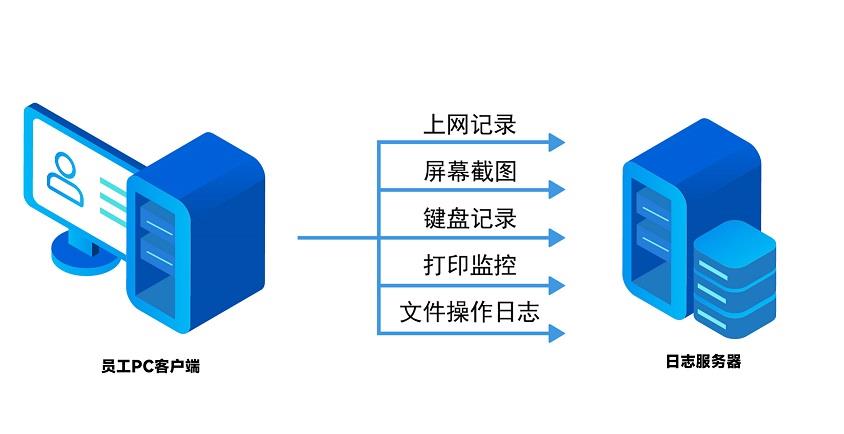
Input type(torch.suda.FloatTensor) and weight type (torch.FloatTensor) should be same
自己搭建模型的时候,经常会遇到二者不匹配,以这种情况为例,是因为部分模型没有加载到CUDA上面造成的。
 注意搭建模型的时候,所有层都应该在init函数中完成初始化
注意搭建模型的时候,所有层都应该在init函数中完成初始化
其次,对于List、Tuple这种类型,不建议直接用。
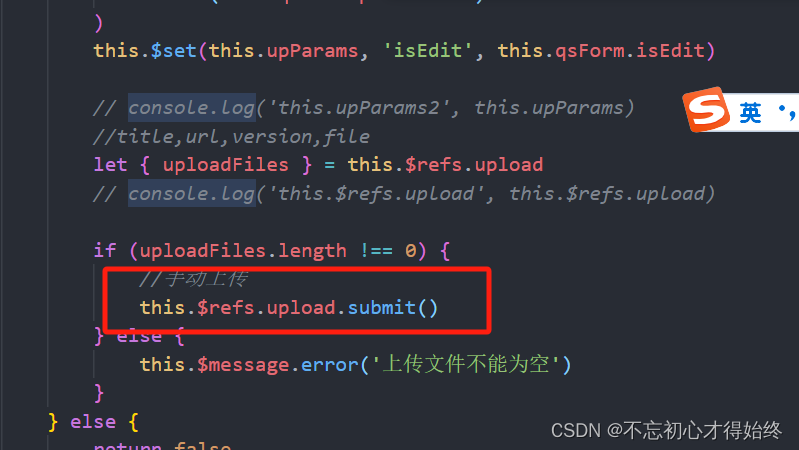
以下是错误代码,我搞了半天,不理解为什么总是不对,正确的应该是self.aspp = nn.ModuleList()
self.aspp = [] # 注意这里不能直接用list[]。类似元组,tuple[]也不能用,要不然会导致weight不在cuda上
for dilation in dilations:
self.aspp.append(
ConvModule(
self.in_channels,
self.channels,
1 if dilation == 1 else 3,
dilation=dilation,
padding=0 if dilation == 1 else dilation,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg))
搭建代码时,希望记住。没有系统教学,只能自己在网上摸索。
Expected to have finished reduction in the prior iteration before starting a new one. This error indicates that your module has parameters that were not used in producing loss. You can enable unused parameter detection by passing the keyword argument find_unused_parameters=True to torch.nn.parallel.DistributedDataParallel, and by making sure all forward function outputs participate in calculating loss.
多GPU的坑,翻译为
- 在开始新的迭代之前,应已在上一次迭代中完成缩减。此错误表示您的模块具有未用于产生损失的参数。通过将关键字参数
find_unused_parameters=True传递给torch.nn.parallel,可以启用未使用的参数检测。DistributedDataParallel,和
确保所有“正向”函数输出都参与计算损失。
关键在于
This error indicates that your module has parameters that were not used in producing loss.
即有参数未参与到loss生成过程中,换句话说就是有参数在init中定义,但是未在forward中使用,就会造成这样的结果。原来为了不断调优模型,我将几个待选网络模块都写在了init函数中,然后这样只需要在forward中改变调用的模块就可以了。在单机运行中这样是可行的无错的,但是在DDP中由于需要多卡进行loss的reduce,为了防止出错,ddp就强行设置了这样的规则,但是可以通过如上错误提示里面的参数更改此设置,但是尽量不要修改。
解决方法:
可以通过 (1) 将关键字参数 find_unused_parameters=True 传递给 torch.nn.parallel.DistributedDataParallel 来启用未使用的参数检测;
(2) 确保所有 forward 函数的所有输出都参与计算损失。解决方法:将init函数中未使用到的模块注释掉即可。
一般推荐2,
因为我只修改了骨干网络,骨干网络是我自己创建的,仔细检查发现,复制粘贴的时候,有个地方忘记修改
x = self.aspp2(x[3]) # 此处是aspp2,之前是aspp3
修改之后,就可以跑通了
拓展:
也有推荐用如下代码检查,我试了一下,但是将所有的都输出来了,不知道是不是放的位置不对:
在mmseg/models/segmentors/encoder_decoder.py中的losses.update(loss_decode)语句下加入下段代码
for name, p in self.decode_head.named_parameters():
# print(name)
if p.grad is None:
print(name)