目录
- 字符类
- 量词
- 边界匹配
- 逻辑和分组
- 转义和特殊字符
- 验证正则表达式是否能够成功提取数据
字符类
.:匹配除换行符之外的任何单个字符。
[abc]:匹配方括号内的任何字符。
[^abc]:匹配不在方括号内的任何字符。
[a-z]:匹配任何小写字母。
[A-Z]:匹配任何大写字母。
[0-9]:匹配任何数字。
\d:匹配任何数字,等价于 [0-9]。
\D:匹配任何非数字字符。
\w:匹配任何单词字符(等价于 [a-zA-Z0-9_])。
\W:匹配任何非单词字符。
\s:匹配任何空白字符(如空格、制表符、换行符等)。
\S:匹配任何非空白字符。
量词
*:匹配前面的元素零次或多次。
+:匹配前面的元素一次或多次。
?:匹配前面的元素零次或一次。
{n}:匹配前面的元素恰好 n 次。
{n,}:匹配前面的元素至少 n 次。
{n,m}:匹配前面的元素至少 n 次,但不超过 m 次。
边界匹配
^:匹配输入字符串的开始位置。
$:匹配输入字符串的结束位置。
\b:匹配一个单词边界。
\B:匹配非单词边界。
逻辑和分组
|:匹配 | 两侧的任一模式。
():捕获括号,用于分组和提取子匹配。
(?:...):非捕获括号,只用于分组,不提取子匹配。
(?=...):正向肯定预查,断言自身位置后面能匹配表达式。
(?!...):正向否定预查,断言自身位置后面不能匹配表达式。
(?<=...):反向肯定预查,断言自身位置前面能匹配表达式。
(?<!...):反向否定预查,断言自身位置前面不能匹配表达式。
转义和特殊字符
\:转义字符,用于转义特殊字符或指定特殊序列(如 \n 表示换行符)。
验证正则表达式是否能够成功提取数据
使用https://rubular.com/网站:
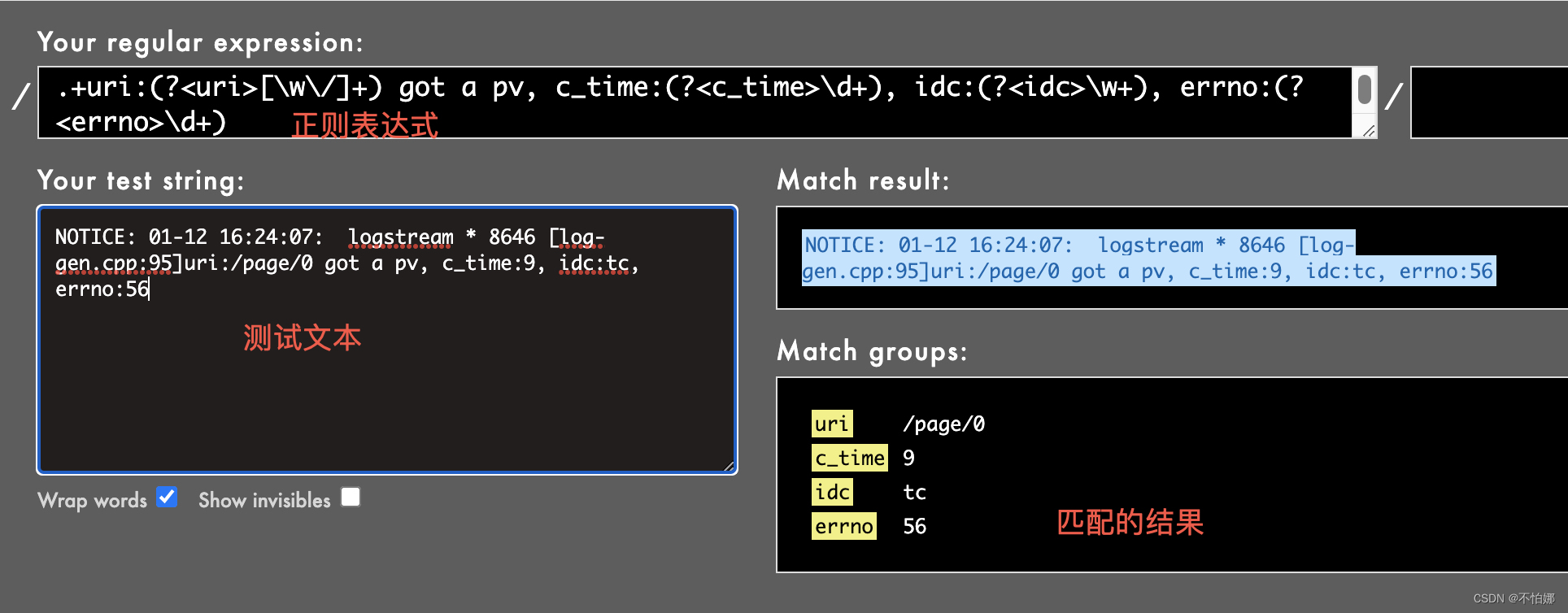
解释这里的正则表达式.+uri:(?<uri>[\w\/]+) got a pv, c_time:(?<c_time>\d+), idc:(?<idc>\w+), errno:(?<errno>\d+):
-
.+:.匹配任意单个字符(除了换行符)。+表示前面的元素(即.)可以出现一次或多次。- 所以
.+匹配任意长度的字符序列(至少一个字符),直到遇到后面的模式为止。
-
uri::- 这部分直接匹配文本中的 “uri:” 字符串。
-
(?<uri>[\w\/]+):- 这是一个命名捕获组,名为
uri。 [\w\/]+匹配一个或多个单词字符(\w,等价于[a-zA-Z0-9_])或斜杠字符(\/)。- 这部分用于捕获 URI 路径,它可能包含字母、数字、下划线和斜杠。
- 这是一个命名捕获组,名为
-
got a pv,:- 这部分直接匹配文本中的 “got a pv,” 字符串。
-
c_time:(?<c_time>\d+):c_time:直接匹配文本中的 “c_time:” 字符串。(?<c_time>\d+)是一个命名捕获组,名为c_time。\d+匹配一个或多个数字字符。- 这部分用于捕获
c_time的值,它应该是一个或多个数字。
-
idc:(?<idc>\w+):idc:直接匹配文本中的 “idc:” 字符串。(?<idc>\w+)是一个命名捕获组,名为idc。\w+匹配一个或多个单词字符。- 这部分用于捕获
idc的值,它应该是一个或多个字母、数字或下划线。
-
errno:(?<errno>\d+):errno:直接匹配文本中的 “errno:” 字符串。(?<errno>\d+)是一个命名捕获组,名为errno。\d+匹配一个或多个数字字符。- 这部分用于捕获
errno的值,它应该是一个或多个数字。