一、原始信号
1、理想数据
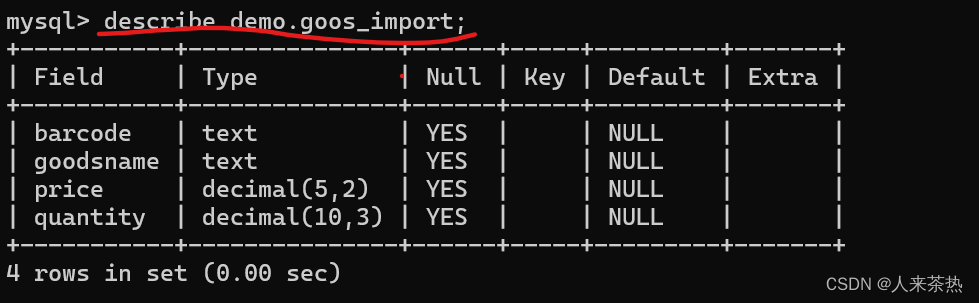
(1)系统参数
| 参数类型 | 数值 |
|---|---|
| J | 0.5 k g ∗ m 2 kg*m^2 kg∗m2 |
| K | 0.2 |
| b | 5 |
(2)激励曲线

import matplotlib.pyplot as plt
import numpy as np
# 生成数据
x = np.linspace(0, 10, 1000) # 生成0到10之间的100个数据点
y = 20*np.sin(x)+15*np.sin(2*x)+10*np.cos(x) # 计算正弦函数值
# 画曲线图
plt.figure()
plt.plot(x, y, label='20sin(x)+15sin(2x)+10cos(x)', color='blue', linestyle='-', linewidth=2) # 绘制曲线
plt.xlabel('x') # x轴标签
plt.ylabel('pos') # y轴标签
plt.title('Excitation Curve') # 图标题
plt.legend() # 显示图例
plt.grid(True) # 显示网格
plt.show()
(3)其他曲线

import matplotlib.pyplot as plt
import numpy as np
J = 0.5
K = 0.2
b = 51010
# 生成数据
x = np.linspace(0, 10, 1000) # 生成0到10之间的1000个数据点
pos = 20*np.sin(x) + 15*np.sin(2*x) + 10*np.cos(x) # 第一条曲线数据
spd = 20*np.cos(x) + 30*np.cos(2*x) - 10*np.sin(x) # 第二条曲线数据
acc = -20*np.sin(x) - 60*np.sin(2*x) - 10*np.cos(x) # 第三条曲线数据
tor = J*acc + K*spd + np.sign(spd)*b
# 画曲线图
plt.figure()
# 创建第一个子图
plt.subplot(411)
plt.plot(x, pos, label='pos', color='blue', linestyle='-', linewidth=2) # 绘制第一条曲线
plt.xlabel('x')
plt.ylabel('pos')
plt.legend()
plt.grid(True)
# 创建第二个子图
plt.subplot(412)
plt.plot(x, spd, label='spd', color='red', linestyle='-', linewidth=2) # 绘制第二条曲线
plt.xlabel('x')
plt.ylabel('spd')
plt.legend()
plt.grid(True)
# 创建第三个子图
plt.subplot(413)
plt.plot(x, acc, label='acc', color='green', linestyle='-', linewidth=2) # 绘制第三条曲线
plt.xlabel('x')
plt.ylabel('acc')
# plt.title('Excitation Curve 3')
plt.legend()
plt.grid(True)
plt.subplot(414)
plt.plot(x, tor, label='tor', color='black', linestyle='-', linewidth=2) # 绘制第三条曲线
plt.xlabel('x')
plt.ylabel('tor')
# plt.title('Excitation Curve 3')
plt.legend()
plt.grid(True)
plt.tight_layout() # 调整子图布局
plt.show()
2、增加噪声

import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
J = 0.5
K = 0.2
b = 5
# 生成数据
x = np.linspace(0, 10, 1000) # 生成0到10之间的1000个数据点
pos = 20*np.sin(x) + 15*np.sin(2*x) + 10*np.cos(x) + np.random.normal(0, 5, 1000) # 第一条曲线数据
spd = 20*np.cos(x) + 30*np.cos(2*x) - 10*np.sin(x) + np.random.normal(0, 5, 1000) # 第二条曲线数据
acc = -20*np.sin(x) - 60*np.sin(2*x) - 10*np.cos(x) + np.random.normal(0, 5, 1000) # 第三条曲线数据
tor = J*acc + K*spd + np.sign(spd)*b + np.random.normal(0, 5, 1000)
# 画曲线图
plt.figure()
# 创建第一个子图
plt.subplot(411)
plt.plot(x, pos, label='pos', color='blue', linestyle='-', linewidth=2) # 绘制第一条曲线
plt.xlabel('x')
plt.ylabel('pos')
plt.legend()
plt.grid(True)
# 创建第二个子图
plt.subplot(412)
plt.plot(x, spd, label='spd', color='red', linestyle='-', linewidth=2) # 绘制第二条曲线
plt.xlabel('x')
plt.ylabel('spd')
plt.legend()
plt.grid(True)
# 创建第三个子图
plt.subplot(413)
plt.plot(x, acc, label='acc', color='green', linestyle='-', linewidth=2) # 绘制第三条曲线
plt.xlabel('x')
plt.ylabel('acc')
# plt.title('Excitation Curve 3')
plt.legend()
plt.grid(True)
plt.subplot(414)
plt.plot(x, tor, label='tor', color='black', linestyle='-', linewidth=2) # 绘制第三条曲线
plt.xlabel('x')
plt.ylabel('tor')
# plt.title('Excitation Curve 3')
plt.legend()
plt.grid(True)
plt.tight_layout() # 调整子图布局
plt.show()
# 创建DataFrame
data = {'x': x, 'pos': pos, 'spd': spd, 'acc': acc, 'tor': tor}
df = pd.DataFrame(data)
# 保存数据到CSV文件
df.to_csv('data_with_noise.csv', index=False)
二、数据预处理
1、傅里叶变换画出频谱图
# 从CSV文件中读取数据
df = pd.read_csv('data_with_noise.csv')
column_name = 'pos' # 选择要进行傅里叶变换的列名
data = df[column_name].values
# 进行傅里叶变换
fs = 100 # 假设数据是均匀采样的
fft_data = np.fft.fft(data)
freqs = np.fft.fftfreq(len(fft_data), 1/fs)
freqs = freqs[:len(freqs)//2] # 取一半频谱(对称性)
# 绘制频谱图
plt.figure()
plt.plot(freqs, np.abs(fft_data[:len(fft_data)//2]))
plt.xlabel('Frequency (Hz)')
plt.ylabel('Amplitude')
plt.title('Spectrum of the data column')
plt.grid()
plt.show()
2、去除高频噪声并逆傅里叶变换

# import numpy as np
# import pandas as pd
# import matplotlib.pyplot as plt
# # 从CSV文件中读取数据
# df = pd.read_csv('data_with_noise.csv')
# column_name = 'pos' # 选择要进行傅里叶变换的列名
# data = df[column_name].values
# # 进行傅里叶变换
# fs = 100 # 采样频率为100 Hz
# fft_data = np.fft.fft(data)
# freqs = np.fft.fftfreq(len(fft_data), 1/fs)
# # 去除大于10Hz的频率成分
# fft_data_filtered = np.copy(fft_data)
# fft_data_filtered[np.where(np.abs(freqs) > 0.5)] = 0
# # 进行逆傅里叶变换
# filtered_data = np.fft.ifft(fft_data_filtered)
# # # 创建新的DataFrame保存原始数据和滤波后的数据
# # new_df = pd.DataFrame({'Original Data': data, 'Filtered Data': np.real(filtered_data)})
# # # 将数据保存到新的CSV文件中
# # new_df.to_csv('filtered_yaw_data.csv', index=False)
# # 绘制时域对比图
# plt.figure()
# plt.plot(data, label='Original Data')
# plt.plot(np.real(filtered_data), label='Filtered Data (freq < 10Hz)')
# plt.xlabel('Time')
# plt.ylabel('Amplitude')
# plt.title('Original Data vs Filtered Data')
# plt.legend()
# plt.grid()
# plt.show()
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 从CSV文件中读取数据
df = pd.read_csv('data_with_noise.csv')
column_name = 'pos' # 选择要进行傅里叶变换的列名
data = df[column_name].values
# 进行傅里叶变换
fs = 100 # 采样频率为100 Hz
fft_data = np.fft.fft(data) #离散快速傅里叶变换
freqs = np.fft.fftfreq(len(fft_data), 1/fs)
freqs = freqs[:len(freqs)] # 取一半频谱(对称性)正
print(freqs)
# 去除大于10Hz的频率成分
fft_data_filtered = np.copy(fft_data)
fft_data_filtered[np.where(np.abs(freqs) > 0.5)] = 0
print(fft_data_filtered)
# 进行逆傅里叶变换
filtered_data = np.fft.ifft(fft_data_filtered)
# 创建新的DataFrame保存原始数据和滤波后的数据
new_df = pd.DataFrame({'Original Data': data, 'Filtered Data': np.real(filtered_data)})
# 将数据保存到新的CSV文件中
new_df.to_csv('filtered_yaw_data.csv', index=False)
# 绘制时域对比图
plt.figure()
plt.plot(data, label='Original Data')
plt.plot(np.real(filtered_data), label='Filtered Data (freq < 10Hz)')
plt.xlabel('Time')
plt.ylabel('Amplitude')
plt.title('Original Data vs Filtered Data')
plt.legend()
plt.grid()
plt.show()
三、动力学辨识
1、动力学模型
t o r = J ∗ α + K ∗ s p d + s i g n ( s p d ) ∗ b tor = J*\alpha + K*spd+sign(spd)*b tor=J∗α+K∗spd+sign(spd)∗b
- 摩擦力使用粘滞-库伦模型
- 单自由度的关节模型
2、最小二乘法

import numpy as np
import pandas as pd
from scipy.optimize import curve_fit
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 从CSV文件中读取数据
df = pd.read_csv('data_with_noise.csv')
column_name_acc = 'Filtered_acc' # 第一列数据的列名
column_name_v = 'Filtered_spd' # 第二列数据的列名
column_name_tor = 'Filtered_tor' # 第三列数据的列名
data_acc = df[column_name_acc].values
data_v = df[column_name_v].values
data_tor = df[column_name_tor].values
# 定义拟合函数
def model_func(inputs, a, b, c):
acc, v = inputs
return a * acc + b * v + np.sign(v) * np.abs(c)
# 初始参数猜测值
initial_guess = [1, 1, 1]
# 使用最小二乘法拟合模型
params, covariance = curve_fit(model_func, (data_acc, data_v), data_tor, initial_guess)
# 提取拟合参数
a_fit, b_fit, c_fit = params
# 打印拟合参数
print("拟合参数:")
print("a =", a_fit)
print("b =", b_fit)
print("c =", c_fit)
# 绘制三维效果图
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(data_acc, data_v, data_tor, color='b', label='Fitted Data')
ax.scatter(data_acc, data_v, model_func((data_acc, data_v), a_fit, b_fit, c_fit), color='r', label='Model Data')
ax.set_xlabel('Filtered Acceleration')
ax.set_ylabel('Filtered Speed')
ax.set_zlabel('Filtered Torque')
ax.set_title('Fitted vs. Actual Data')
plt.legend()
plt.show()
3、结果分析
| 参数类型 | 数值 | |
|---|---|---|
| J | 0.5 | 0.47 |
| K | 0.2 | 0.275 |
| b | 5 | -0.676 |
- 转动惯量的部分还是可以的,摩擦力的两个参数就有点离谱了,速度越大摩擦力还小了。这是我觉得辨识方法最尴尬的地方,结果是拟合了,参数没拟合。这还是单自由度的情况下,如果是多自由度的整体辨识,大量参数耦合在一起,就更难说清到底是哪些参数起到了什么样的作用了,这也没比基于神经网络的纯黑盒强多少。
![下列程序定义了NxN的二维数组,并在主函数中自动赋值。请编写函数fun(int a[][N],int n),该函数的功能是:使数组右上半三角元素中的值乘以m。](https://img-blog.csdnimg.cn/direct/810d3107b3ec45bc8500a4afedf90d0e.png)