原文:
www.backtrader.com/
概念
平台概念
原文:
www.backtrader.com/docu/concepts/
这是平台某些概念的集合。它试图收集可在使用平台时有用的信息片段。
开始之前
所有小代码示例都假设以下导入可用:
import backtrader as bt
import backtrader.indicators as btind
import backtrader.feeds as btfeeds
注意
访问子模块的另一种替代语法,如指标和数据源:
import backtrader as bt
然后:
thefeed = bt.feeds.OneOfTheFeeds(...)
theind = bt.indicators.SimpleMovingAverage(...)
数据源 - 传递它们
与平台工作的基础将通过策略完成。这些将获得数据源。平台最终用户不需要关心接收它们:
数据源被自动提供为策略的成员变量,以数组形式和数组位置的快捷方式
策略派生类声明和运行平台的快速预览:
class MyStrategy(bt.Strategy):
params = dict(period=20)
def __init__(self):
sma = btind.SimpleMovingAverage(self.datas[0], period=self.params.period)
...
cerebro = bt.Cerebro()
...
data = btfeeds.MyFeed(...)
cerebro.adddata(data)
...
cerebro.addstrategy(MyStrategy, period=30)
...
注意以下内容:
-
策略的
__init__方法未接收到*args或**kwargs(仍然可以使用它们)。 -
存在成员变量
self.datas,其为包含至少一个项目的数组/列表/可迭代对象(希望至少有一个项目,否则将引发异常)。
是的。数据源被添加到平台上,它们将按照它们被添加到系统中的顺序显示在策略内部。
注意
这也适用于指标,如果最终用户开发自己的自定义指标或者查看某些现有指标参考的源代码时。
数据源的快捷方式
可以直接使用附加自动成员变量访问 self.datas 数组项:
-
self.data目标为self.datas[0] -
self.dataX目标为self.datas[X]
然后的示例:
class MyStrategy(bt.Strategy):
params = dict(period=20)
def __init__(self):
sma = btind.SimpleMovingAverage(self.data, period=self.params.period)
...
省略数据源
上述示例可以进一步简化为:
class MyStrategy(bt.Strategy):
params = dict(period=20)
def __init__(self):
sma = btind.SimpleMovingAverage(period=self.params.period)
...
self.data已从SimpleMovingAverage的调用中完全移除。如果这样做,指标(在本例中为SimpleMovingAverage)将接收正在创建的对象的第一个数据(策略),即self.data(又名self.data0或self.datas[0])
几乎一切都是数据源
不仅数据源是数据,也可以传递。指标和操作的结果也是数据。
在上一个示例中,SimpleMovingAverage将self.datas[0]作为输入进行操作。具有操作和额外指标的示例:
class MyStrategy(bt.Strategy):
params = dict(period1=20, period2=25, period3=10, period4)
def __init__(self):
sma1 = btind.SimpleMovingAverage(self.datas[0], period=self.p.period1)
# This 2nd Moving Average operates using sma1 as "data"
sma2 = btind.SimpleMovingAverage(sma1, period=self.p.period2)
# New data created via arithmetic operation
something = sma2 - sma1 + self.data.close
# This 3rd Moving Average operates using something as "data"
sma3 = btind.SimpleMovingAverage(something, period=self.p.period3)
# Comparison operators work too ...
greater = sma3 > sma1
# Pointless Moving Average of True/False values but valid
# This 4th Moving Average operates using greater as "data"
sma3 = btind.SimpleMovingAverage(greater, period=self.p.period4)
...
基本上,一旦被操作,一切都会转换为可以用作数据源的对象。
参数
平台中的几乎每个其他class都支持参数的概念。
-
参数连同默认值声明为类属性(元组的元组或类似字典的对象)
-
关键字参数(
**kwargs)被扫描以匹配参数,如果找到,则从**kwargs中删除它们并将值分配给相应的参数。 -
参数最终可以通过访问成员变量
self.params(简写:self.p)在类的实例中使用。
前面的快速策略预览已经包含了一个参数示例,但为了冗余起见,再次,只关注参数。使用元组:
class MyStrategy(bt.Strategy):
params = (('period', 20),)
def __init__(self):
sma = btind.SimpleMovingAverage(self.data, period=self.p.period)
并且使用一个dict:
class MyStrategy(bt.Strategy):
params = dict(period=20)
def __init__(self):
sma = btind.SimpleMovingAverage(self.data, period=self.p.period)
行
再次,平台上几乎每个其他对象都是Lines启用的对象。从最终用户的角度来看,这意味着:
- 它可以容纳一个或多个线系列,其中线系列是一个值数组,将这些值放在一起形成一条线。
一个line(或lineseries)的很好的例子是由股票收盘价形成的线。这实际上是价格演变的一个众所周知的图表表示(称为Line on Close)
平台的常规使用只关注访问lines。前面的迷你策略示例,稍微扩展一下,再次派上用场:
class MyStrategy(bt.Strategy):
params = dict(period=20)
def __init__(self):
self.movav = btind.SimpleMovingAverage(self.data, period=self.p.period)
def next(self):
if self.movav.lines.sma[0] > self.data.lines.close[0]:
print('Simple Moving Average is greater than the closing price')
已公开两个具有lines的对象:
-
self.data它有一个lines属性,其中又包含一个close属性 -
self.movav是一个SimpleMovingAverage指标 它有一个lines属性,其中又包含一个sma属性
注
从这可以明显看出,lines是有名称的。它们也可以按照声明顺序顺序访问,但这只应在Indicator开发中使用
两个lines,即close和sma,都可以查询一个点(索引 0)以比较值。
有一种缩写访问行的方法存在:
-
xxx.lines可以缩短为xxx.l -
xxx.lines.name可以缩短为xxx.lines_name -
类似策略和指标的复杂对象提供了对数据线的快速访问
-
self.data_name提供了对self.data.lines.name的直接访问 -
这也适用于编号的数据变量:
self.data1_name->self.data1.lines.name
-
此外,线路名称可以直接访问:
-
self.data.close和self.movav.sma但是如果实际上正在访问行,则该符号并不像之前的符号那样清晰。
不是
使用这两个后续符号设置/分配行不受支持
Lines声明
如果正在开发一个Indicator,则必须声明该指标具有的lines。
正如与params一样,这次以类属性的形式发生,仅作为元组。不支持字典,因为它们不按插入顺序存储事物。
对于简单移动平均线,应该这样做:
class SimpleMovingAverage(Indicator):
lines = ('sma',)
...
注
如果将单个字符串传递给元组,则元组中需要跟随声明的逗号,否则字符串中的每个字母都将被解释为要添加到元组中的项目。这可能是 Python 语法出错的几个情况之一。
如前面的例子所示,此声明在Indicator中创建了一个sma线,可以在策略的逻辑中(可能也可以由其他指标)稍后访问以创建更复杂的指标。
对于开发而言,有时以通用的非命名方式访问行是有用的,这就是编号访问发挥作用的地方:
self.lines[0]指向self.lines.sma
如果定义了更多行,则可以使用索引 1、2 和更高的索引来访问它们。
当然,还存在额外的简写版本:
-
self.line指向self.lines[0] -
self.lineX指向self.lines[X] -
self.line_X指向self.lines[X]
在接收数据源的对象内,这些数据源下方的行也可以通过数字快速访问:
-
self.dataY指向self.data.lines[Y] -
self.dataX_Y指向self.dataX.lines[X],这是self.datas[X].lines[Y]的完整简化版本
在数据源中访问 lines
在数据源内部,也可以访问 lines,省略 lines。这使得使用像 close 价格这样的内容更加自然。
例如:
data = btfeeds.BacktraderCSVData(dataname='mydata.csv')
...
class MyStrategy(bt.Strategy):
...
def next(self):
if self.data.close[0] > 30.0:
...
这似乎比也有效的更自然:if self.data.lines.close[0] > 30.0:。同样的情况不适用于带有以下理由的Indicators:
Indicator可能有一个属性close,它保存一个中间计算结果,稍后交付给实际的lines,也称为close
在数据源的情况下,不会进行任何计算,因为它只是一个数据源。
行长度
行有一组点,并在执行过程中动态增长,因此可以随时通过调用标准的 Python len 函数来测量长度。
这适用于例如:
-
数据源
-
策略
-
指标
数据源中存在另一个属性,当数据 预加载 时适用:
- 方法
buflen
该方法返回数据源可用的实际条形图数。
len 和 buflen 的区别
-
len报告已处理了多少个条形图 -
buflen报告为数据源加载了多少个条形图
如果两者返回相同的值,则要么没有预加载数据,要么条形图的处理已消耗所有预加载的条形图(除非系统连接到实时数据源,否则这将意味着处理结束)
行和参数的继承
一种元语言用于支持参数和行的声明。为了使其与标准 Python 继承规则兼容,已经尽一切努力。
参数继承
继承应该按预期工作:
-
支持多重继承
-
从基类继承参数
-
如果多个基类定义了相同的参数,则使用继承列表中最后一个类的默认值
-
如果在子类中重新定义了相同的参数,则新的默认值将取代基类的默认值
行继承
-
支持多重继承
-
来自所有基类的行都会被继承。作为命名行,如果相同的名称在基类中使用了多次,则只会有一个版本的行
索引:0 和 -1
行如前所述是线系列,并在绘制时一起组成一条线(就像沿时间轴连接所有收盘价一样)
要在常规代码中访问这些点,选择使用基于0的方法来获取/设置当前get/set即时。
策略只获取值。指标还设置值。
在之前的快速策略示例中,next方法被简要看到:
def next(self):
if self.movav.lines.sma[0] > self.data.lines.close[0]:
print('Simple Moving Average is greater than the closing price')
逻辑是通过应用索引0 获取移动平均值和当前收盘价的当前值。
注意
实际上,对于索引0,并且在应用逻辑/算术运算符时,可以直接进行比较,如下所示:
if self.movav.lines.sma > self.data.lines.close:
...
在文档后面看运算符的解释。
设置是用于开发时使用的,例如,一个 Indicator,因为必须通过该指标设置当前输出值。
可以按以下方式计算当前获取/设置点的 SimpleMovingAverage:
def next(self):
self.line[0] = math.fsum(self.data.get(0, size=self.p.period)) / self.p.period
访问先前设置的点是按照 Python 为访问数组/可迭代时定义的-1进行建模
- 它指向数组的最后一项
平台将最后设置的项(当前实时获取/设置点之前)视为-1。
因此,将当前close与前一个close进行比较是一个0 vs -1的事情。例如,在策略中:
def next(self):
if self.data.close[0] > self.data.close[-1]:
print('Closing price is higher today')
当然,从-1之前设置的价格将使用-2、-3、...进行访问。
切片
backtrader不支持对lines对象进行切片,这是一种设计决策,遵循了[0]和[-1]索引方案。对于常规可索引的 Python 对象,您会执行以下操作:
myslice = self.my_sma[0:] # slice from the beginning til the end
但请记住,在选择为0时……实际上是当前交付的值,后面没有了。另外:
myslice = self.my_sma[0:-1] # slice from the beginning til the end
再次……0是当前值,-1是最新(先前)的交付值。这就是为什么在backtrader生态系统中从0 -> -1切片没有意义的原因。
如果支持切片,将如下所示:
myslice = self.my_sma[:0] # slice from current point backwards to the beginning
或:
myslice = self.my_sma[-1:0] # last value and current value
或:
myslice = self.my_sma[-3:-1] # from last value backwards to the 3rd last value
获取一个切片
仍然可以获取具有最新值的数组。语法:
myslice = self.my_sma.get(ago=0, size=1) # default values shown
这将返回一个具有1值(size=1)的数组,当前时刻0作为向后查找的起始点。
要从当前时间点获取 10 个值(即:最后 10 个值):
myslice = self.my_sma.get(size=10) # ago defaults to 0
当然,数组具有您期望的顺序。最左边的值是最旧的值,最右边的值是最新的值(它是一个常规的 Python 数组,而不是一个lines对象)
要获取最后 10 个值,仅跳过当前点:
myslice = self.my_sma.get(ago=-1, size=10)
行:延迟索引
[]操作符语法用于在next逻辑阶段提取单个值。 Lines对象支持另一种符号,通过延迟行对象在__init__阶段访问值。
假设逻辑的兴趣是将前一个close值与简单移动平均值的实际值进行比较。而不是在每个next迭代中手动执行,可以生成一个预先定义的lines对象:
class MyStrategy(bt.Strategy):
params = dict(period=20)
def __init__(self):
self.movav = btind.SimpleMovingAverage(self.data, period=self.p.period)
self.cmpval = self.data.close(-1) > self.sma
def next(self):
if self.cmpval[0]:
print('Previous close is higher than the moving average')
在这里,正在使用(delay)符号:
-
这提供了一个
close价格的副本,但是延迟了-1。比较
self.data.close(-1) > self.sma生成另一个lines对象,如果条件为True则返回1,如果为False则返回0
线耦合
运算符()可以像上面显示的那样与delay值一起使用,以提供lines对象的延迟版本。
如果使用语法WITHOUT提供delay值,则返回一个LinesCoupler lines对象。这旨在在操作datas具有不同时间框架的指标之间建立耦合。
具有不同时间框架的数据源具有不同的长度,在其上操作的指标复制数据的长度。例如:
-
每年的日数据源大约有 250 个柱状图
-
每年的周数据源有 52 个柱状图
尝试创建一个操作(例如),比较两个简单移动平均,每个操作在上述引用的数据上运行,会出现问题。不清楚如何将每日时间框架的 250 个柱状图与每周时间框架的 52 个柱状图匹配。
读者可以想象在后台进行date比较,以找出一天 - 一周的对应关系,但是:
-
指标只是数学公式,没有日期时间信息。它们对环境一无所知,只知道如果数据提供足够的值,就可以进行计算。
()(空调用)符号来拯救:
class MyStrategy(bt.Strategy):
params = dict(period=20)
def __init__(self):
# data0 is a daily data
sma0 = btind.SMA(self.data0, period=15) # 15 days sma
# data1 is a weekly data
sma1 = btind.SMA(self.data1, period=5) # 5 weeks sma
self.buysig = sma0 > sma1()
def next(self):
if self.buysig[0]:
print('daily sma is greater than weekly sma1')
在这里,较大时间框架指标sma1与每日时间框架耦合为sma1()。这返回一个与sma0的更大柱状图兼容的对象,并复制由sma1产生的值,有效地将 52 周柱状图分散在 250 日柱状图中
运算符,使用自然构造
为了实现“易用性”目标,该平台允许(在 Python 的约束条件下)使用运算符。为了进一步增强这一目标,运算符的使用已分为两个阶段。
第 1 阶段 - 运算符创建对象
即使没有明确指定,示例已经展示了这一点。在像指标和策略这样的对象的初始化阶段(__init__方法)中,运算符创建可以进行操作、分配或保留作为后续在策略逻辑评估阶段使用的对象。
再次展示了一个简单移动平均的潜在实现,进一步分解为步骤。
简单移动平均指标__init__中的代码可能如下所示:
def __init__(self):
# Sum N period values - datasum is now a *Lines* object
# that when queried with the operator [] and index 0
# returns the current sum
datasum = btind.SumN(self.data, period=self.params.period)
# datasum (being *Lines* object although single line) can be
# naturally divided by an int/float as in this case. It could
# actually be divided by anothr *Lines* object.
# The operation returns an object assigned to "av" which again
# returns the current average at the current instant in time
# when queried with [0]
av = datasum / self.params.period
# The av *Lines* object can be naturally assigned to the named
# line this indicator delivers. Other objects using this
# indicator will have direct access to the calculation
self.line.sma = av
在策略初始化期间展示了一个更完整的用例:
class MyStrategy(bt.Strategy):
def __init__(self):
sma = btind.SimpleMovinAverage(self.data, period=20)
close_over_sma = self.data.close > sma
sma_dist_to_high = self.data.high - sma
sma_dist_small = sma_dist_to_high < 3.5
# Unfortunately "and" cannot be overridden in Python being
# a language construct and not an operator and thus a
# function has to be provided by the platform to emulate it
sell_sig = bt.And(close_over_sma, sma_dist_small)
在上述操作完成后,sell_sig是一个Lines对象,可以在策略的逻辑中稍后使用,指示条件是否满足。
第二阶段 - 自然的运算符
让我们首先记住,策略有一个next方法,系统处理每个柱状图时都会调用该方法。这就是运算符实际处于第 2 阶段模式的地方。在前面的示例基础上构建:
class MyStrategy(bt.Strategy):
def __init__(self):
self.sma = sma = btind.SimpleMovinAverage(self.data, period=20)
close_over_sma = self.data.close > sma
self.sma_dist_to_high = self.data.high - sma
sma_dist_small = sma_dist_to_high < 3.5
# Unfortunately "and" cannot be overridden in Python being
# a language construct and not an operator and thus a
# function has to be provided by the platform to emulate it
self.sell_sig = bt.And(close_over_sma, sma_dist_small)
def next(self):
# Although this does not seem like an "operator" it actually is
# in the sense that the object is being tested for a True/False
# response
if self.sma > 30.0:
print('sma is greater than 30.0')
if self.sma > self.data.close:
print('sma is above the close price')
if self.sell_sig: # if sell_sig == True: would also be valid
print('sell sig is True')
else:
print('sell sig is False')
if self.sma_dist_to_high > 5.0:
print('distance from sma to hig is greater than 5.0')
不是一个非常有用的策略,只是一个例子。在第 2 阶段,运算符返回预期的值(如果测试真实性则返回布尔值,如果与浮点数比较则返回浮点数),算术运算也是如此。
注意
请注意,比较实际上并没有使用[]运算符。这是为了进一步简化事情。
if self.sma > 30.0: … 比较self.sma[0]和30.0(第 1 行和当前值)
if self.sma > self.data.close: … 比较self.sma[0]和self.data.close[0]
一些未被覆盖的运算符/函数
Python 不允许覆盖所有内容,因此提供了一些函数来处理这些情况。
注意
仅在阶段 1 中使用,以创建稍后提供值的对象。
运算符:
-
and->And -
or->Or
逻辑控制:
if->If
函数:
-
any->Any -
all->All -
cmp->Cmp -
max->Max -
min->Min -
sum->SumSum实际上使用math.fsum作为底层操作,因为平台使用浮点数,并且应用常规的sum可能会影响精度。 -
reduce->Reduce
这些实用运算符/函数操作可迭代对象。可迭代对象中的元素可以是常规的 Python 数值类型(整数,浮点数,…)也可以是具有Lines的对象。
一个生成非常愚蠢买入信号的例子:
class MyStrategy(bt.Strategy):
def __init__(self):
sma1 = btind.SMA(self.data.close, period=15)
self.buysig = bt.And(sma1 > self.data.close, sma1 > self.data.high)
def next(self):
if self.buysig[0]:
pass # do something here
很明显,如果sma1高于最高价,那么它必须高于收盘价。但重点是说明bt.And的用法。
使用bt.If:
class MyStrategy(bt.Strategy):
def __init__(self):
sma1 = btind.SMA(self.data.close, period=15)
high_or_low = bt.If(sma1 > self.data.close, self.data.low, self.data.high)
sma2 = btind.SMA(high_or_low, period=15)
分解:
-
在
data.close上生成一个SMA,周期为15 -
然后
bt.If如果sma的值大于close,则返回low,否则返回high
请记住,当调用
bt.If时并不会返回实际值。它返回一个Lines对象,就像一个SimpleMovingAverage一样。值将在系统运行时计算
-
生成的
bt.IfLines对象然后被传递给第 2 个SMA,有时会使用low价格,有时会使用high价格进行计算
这些函数也接受数值。同样的例子,稍作修改:
class MyStrategy(bt.Strategy):
def __init__(self):
sma1 = btind.SMA(self.data.close, period=15)
high_or_30 = bt.If(sma1 > self.data.close, 30.0, self.data.high)
sma2 = btind.SMA(high_or_30, period=15)
现在第 2 个移动平均值使用30.0或high价格执行计算,取决于sma与close的逻辑状态
注意
值30在内部转换为一个伪可迭代对象,始终返回30
操作平台
原文:
www.backtrader.com/docu/operating/
线迭代器
为了参与操作,平台使用线迭代器的概念。它们松散地模仿了 Python 的迭代器,但实际上与它们毫不相关。
策略和指标都是线迭代器。
线迭代器的概念试图描述以下内容:
-
一条线迭代器踢动从属线迭代器,告诉它们迭代
-
然后,线迭代器遍历其自己声明的命名行并设置值
迭代的关键,就像普通的 Python 迭代器一样,是:
-
next方法它将被每次迭代调用。 线迭代器具有的并作为逻辑/计算基础的
datas数组已经被平台移动到下一个索引(除了数据重播)在满足线迭代器的最小周期时调用。稍后将详细介绍。
但因为它们不是常规迭代器,所以还存在两种额外的方法:
-
prenext在满足最小周期的条件之前调用线迭代器。
-
nextstart当满足最小周期的条件时仅调用一次线迭代器。
默认行为是将调用转发给
next,但如果需要的话当然可以重写。
指标的额外方法
为了加快操作速度,指标支持一种称为 runonce 的批处理操作模式。这不是严格必需的(一个next方法就足够了),但它极大地减少了时间。
runonce 方法规则使得与索引 0 的点的获取/设置无效,并依赖于直接访问保存数据的底层数组,并为每个状态传递正确的索引。
定义的方法遵循 next 系列的命名:
-
once(self, start, end)在满足最小周期的条件时调用。必须在从内部数组的起始位置为零开始的 start 和 end 之间处理内部数组
-
preonce(self, start, end)在满足最小周期之前调用。
-
oncestart(self, start, end)当满足最小周期的条件时仅调用一次。
默认行为是将调用转发给
once,但如果需要的话当然可以重写。
最小周期
一张图值千言,而在这种情况下可能还有一个例子。一个简单移动平均能够解释它:
class SimpleMovingAverage(Indicator):
lines = ('sma',)
params = dict(period=20)
def __init__(self):
... # Not relevant for the explanation
def prenext(self):
print('prenext:: current period:', len(self))
def nextstart(self):
print('nextstart:: current period:', len(self))
# emulate default behavior ... call next
self.next()
def next(self):
print('next:: current period:', len(self))
实例化可能如下所示:
sma = btind.SimpleMovingAverage(self.data, period=25)
简要解释:
-
假设传递给移动平均的数据是标准数据源,默认周期为
1,即数据源生成一个没有初始延迟的条形图。 -
然后,**“period=25”**实例化的移动平均将按以下方式调用其方法:
-
prenext24 次 -
nextstart1 次(依次调用next) -
next再次直到数据源耗尽
-
让我们来看一个致命的指标:另一个简单移动平均值的a SimpleMovingAverage。实例化可能如下所示:
sma1 = btind.SimpleMovingAverage(self.data, period=25)
sma2 = btind.SimpleMovingAverage(sma1, period=20)
现在发生的情况是:
-
对于
sma1也是如上所述 -
sma2正在接收一个数据源,其最小周期为 25,这是我们的sma1,因此 -
sma2方法的调用方式如下:-
prenext首次调用 25 + 18 次,总共 43 次 -
25 次让
sma1产生其第 1 个合理值。 -
18 次累积额外的
sma1值 -
总共 19 个值(在 25 次调用后再加 1 次,然后再加 18 次)
-
nextstart然后调用 1 次(轮流调用next) -
next另外调用 n 次,直到数据源耗尽
-
当系统已经处理了 44 个柱状时,平台会调用next。
最小周期已自动调整为传入数据。
策略和指标遵循这种行为:
- 只有当自动计算的最小周期已达到时,才会调用
next(除了对nextstart的初始钩子调用)
注意。
相同的规则适用于runonce批量操作模式的preonce、oncestart和once
注意。
最小周期行为可以被操纵,尽管不建议这样做。如果希望使用,在策略或指标中使用setminperiod(minperiod)方法
已启动并运行。
启动和运行至少涉及 3 个Lines对象:
-
一个数据源
-
一个策略(实际上是从策略派生的类)
-
一个 Cerebro(西班牙语中的“大脑”)。
数据源
这些对象显然提供将通过应用计算(直接和/或带有指标)进行回测的数据。
该平台提供了几个数据源:
-
几种 CSV 格式和一个通用的 CSV 阅读器
-
雅虎在线获取器
-
支持接收Pandas DataFrames和blaze对象
-
与Interacive Brokers、Visual Chart和Oanda一起的实时数据源。
该平台不对数据源的内容(如时间段和压缩)做任何假设。这些值,连同名称,可以供信息用途和高级操作(例如数据源重采样,将例如 5 分钟数据源转换为每日数据源)。
设置 Yahoo Finance 数据源的示例:
import backtrader as bt
import backtrader.feeds as btfeeds
...
datapath = 'path/to/your/yahoo/data.csv'
data = btfeeds.YahooFinanceCSVData(
dataname=datapath,
reversed=True)
显示了雅虎的可选reversed参数,因为直接从雅虎下载的 CSV 文件从最新日期开始,而不是从最旧日期开始。
如果您的数据跨越了大的时间范围,则实际加载的数据可以限制如下:
data = btfeeds.YahooFinanceCSVData(
dataname=datapath,
reversed=True
fromdate=datetime.datetime(2014, 1, 1),
todate=datetime.datetime(2014, 12, 31))
如果存在,fromdate和todate都将被包含在数据源中。
如已提及的时间段、压缩和名称可添加:
data = btfeeds.YahooFinanceCSVData(
dataname=datapath,
reversed=True
fromdate=datetime.datetime(2014, 1, 1),
todate=datetime.datetime(2014, 12, 31)
timeframe=bt.TimeFrame.Days,
compression=1,
name='Yahoo'
)
如果数据已绘制,则将使用这些值。
一个策略(派生)类
注意。
在继续之前,并且为了更简化的方法,请检查文档的Signals部分,如果不希望子类化策略。
使用该平台的任何人的目标都是对数据进行回测,这是在策略(派生类)内完成的。
至少有 2 种方法需要定制:
-
__init__ -
next
在初始化过程中,对数据和其他计算进行了创建和准备,以后将应用逻辑。
稍后将调用next方法来应用每个数据条的逻辑。
注意
如果传递了不同时间框架(因此具有不同的条形计数)的数据源,则将调用next方法以获取主数据(传递给 cerebro 的第一个数据,见下文),它必须是具有较小时间框架的数据
注意
如果使用数据重播功能,则将为相同的条形进行多次调用next方法,因为条形的发展正在重播。
一个基本的派生自类的策略:
class MyStrategy(bt.Strategy):
def __init__(self):
self.sma = btind.SimpleMovingAverage(self.data, period=20)
def next(self):
if self.sma > self.data.close:
self.buy()
elif self.sma < self.data.close:
self.sell()
策略具有其他方法(或挂钩点)可以重写:
class MyStrategy(bt.Strategy):
def __init__(self):
self.sma = btind.SimpleMovingAverage(self.data, period=20)
def next(self):
if self.sma > self.data.close:
submitted_order = self.buy()
elif self.sma < self.data.close:
submitted_order = self.sell()
def start(self):
print('Backtesting is about to start')
def stop(self):
print('Backtesting is finished')
def notify_order(self, order):
print('An order new/changed/executed/canceled has been received')
start和stop方法应该是不言而喻的。与预期的一样,并且遵循打印函数中的文本,当策略需要通知时,将调用notify_order方法。用例:
-
请求购买或出售(如下所示)
购买/出售将返回一个order,该订单将提交给经纪人。保留对此已提交订单的引用由调用者自行决定。
例如,可以用它来确保如果订单仍未处理,则不会提交新订单。
-
如果订单被接受/执行/取消/更改,则经纪人将通过 notify 方法将状态更改(例如执行大小)通知回策略
快速入门指南在notify_order方法中有一个完整而实用的订单管理示例。
还可以使用其他策略类做更多事情:
-
buy/sell/close使用底层的broker和sizer向经纪人发送购买/出售订单
也可以通过手动创建订单并将其传递给经纪人来完成相同的操作。但是该平台旨在使使用它的人更容易。
close将获取当前的市场持仓并立即关闭它。 -
getposition(或属性“position”)返回当前的市场持仓
-
setsizer/getsizer(或属性“sizer”)这些允许设置/获取底层的 Stake Sizer。可以对提供相同情况的不同 Stake 的 Sizer 检查相同的逻辑(固定大小,与资本成比例,指数)
有很多文献,但 Van K. Tharp 在这个领域有出色的书籍。
策略是Lines对象,这些对象支持参数,这些参数使用标准 Python kwargs 参数进行收集:
class MyStrategy(bt.Strategy):
params = (('period', 20),)
def __init__(self):
self.sma = btind.SimpleMovingAverage(self.data, period=self.params.period)
...
...
注意SimpleMovingAverage如何不再以固定值 20 进行实例化,而是使用已为策略定义的参数“period”进行实例化。
一个 Cerebro
一旦数据源可用并且策略已定义,Cerebro 实例就是将所有内容汇集在一起并执行操作的工具。实例化一个很容易:
cerebro = bt.Cerebro()
如果没有特殊要求,则默认情况下会进行处理。
-
创建默认经纪人
-
操作无佣金
-
数据源将被预加载
-
默认执行模式将是 runonce(批量操作),这是更快的模式
所有指标必须支持
runonce模式以实现全速运行。平台中包含的指标可以。自定义指标不需要实现 runonce 功能。
Cerebro将模拟它,这意味着那些不兼容 runonce 的指标将运行得更慢。但大部分系统仍将以批处理模式运行。
由于数据源已经可用,策略也已经创建(之前创建),将它们组合在一起并使其运行的标准方法是:
cerebro.adddata(data)
cerebro.addstrategy(MyStrategy, period=25)
cerebro.run()
请注意以下内容:
-
数据源“实例”被添加
-
MyStrategy“类”被添加以及将传递给它的参数(kwargs)。
MyStrategy 的实例化将由 cerebro 在后台完成,并且“addstrategy”中的任何 kwargs 将被传递给它
用户可以根据需要添加任意多的策略和数据源。策略如何相互通信以实现协调(如果需要)并不受平台的强制/限制。
当然,Cerebro 提供了额外的可能性:
-
决定预加载和操作模式:
cerebro = bt.Cerebro(runonce=True, preload=True)`这里有一个约束:
runonce需要预加载(如果不是,批处理操作将无法运行)。当然,预加载数据源并不强制执行runonce -
setbroker/getbroker(以及broker属性)如果需要,可以设置自定义经纪人。实际经纪人实例也可以被访问
-
绘图。在常规情况下,就像这样简单:
cerebro.run() cerebro.plot()`绘图需要一些参数进行自定义
-
numfigs=1如果图表过于密集,可以将其拆分为多个图表
-
plotter=None可以传递自定义绘图器实例,cerebro 将不会实例化默认绘图器
-
**kwargs- 标准关键字参数这将传递给绘图器。
请查看绘图部分获取更多信息。
-
-
优化策略。
如上所述,Cerebro 获得一个派生自 Strategy 的类(而不是实例),以及将在调用“run”时传递给它的关键字参数。
这样可以实现优化。相同的 Strategy 类将根据需要实例化多次,并使用新参数。如果一个实例已经传递给 cerebro…这将是不可能的。
请求优化如下:
cerebro.optstrategy(MyStrategy, period=xrange(10, 20))`方法
optstrategy具有与addstrategy相同的签名,但会进行额外的管理工作以确保优化按预期运行。一个策略可能期望一个范围作为策略的正常参数,而addstrategy不会对传递的参数做任何假设。另一方面,
optstrategy将理解可迭代对象是一组值,必须按顺序传递给每个 Strategy 类的实例化。注意,传递的不是单个值,而是一系列值。在这个简单的情况下,将尝试这个策略的 10 个值 10 -> 19(20 是上限)。
如果开发了更复杂的策略并具有额外的参数,它们都可以传递给optstrategy。必须不经过优化的参数可以直接传递,而无需最终用户创建一个仅包含一个值的虚拟可迭代对象。例如:
cerebro.optstrategy(MyStrategy, period=xrange(10, 20), factor=3.5)`optstrategy方法看到因子并在后台为具有单个元素的因子创建(所需的)虚拟可迭代对象(例如 3.5 中的示例)。注意
交互式 Python shell 和某些类型的在Windows下的冻结可执行文件对 Python 的
multiprocessing模块存在问题。请阅读有关
multiprocessing的 Python 文档。
大脑
Cerebro
原文:
www.backtrader.com/docu/cerebro/
这个类是backtrader的基石,因为它作为以下方面的中心点:
-
收集所有输入(数据源)、行动者(策略)、旁观者(观察员)、评论者(分析器)和文档编制者(写作者),确保节目随时进行。
-
执行回测/或实时数据提供/交易
-
返回结果
-
提供对绘图设施的访问
收集输入
-
首先创建一个
cerebro:cerebro = bt.Cerebro(**kwargs)`支持一些
**kwargs来控制执行,参见参考文献(这些参数后来也可以应用于run方法) -
添加数据源
最常见的模式是
cerebro.adddata(data),其中data已经实例化为数据源。例如:data = bt.BacktraderCSVData(dataname='mypath.days', timeframe=bt.TimeFrame.Days) cerebro.adddata(data)`重新采样和回放数据是可能的,遵循相同的模式:
data = bt.BacktraderCSVData(dataname='mypath.min', timeframe=bt.TimeFrame.Minutes) cerebro.resampledata(data, timeframe=bt.TimeFrame.Days)`或:
data = bt.BacktraderCSVData(dataname='mypath.min', timeframe=bt.TimeFrame.Minutes) cerebro.replaydatadata(data, timeframe=bt.TimeFrame.Days)`系统可以接受任意数量的数据源,包括混合常规数据与重新采样和/或重放数据。当然,其中一些组合肯定毫无意义,因此在能够组合数据时会应用一些限制:时间对齐。请参阅数据-多时间框架、数据重新采样-重新采样和数据-重播部分。
-
添加
Strategies与已经是类实例的
数据源不同,cerebro直接接受Strategy类和传递给它的参数。背后的原理是:在优化场景中,该类将被实例化多次并传递不同的参数即使没有运行优化,该模式仍然适用:
cerebro.addstrategy(MyStrategy, myparam1=value1, myparam2=value2)`当优化参数时,必须添加为可迭代对象。详细说明请参见优化部分。基本模式:
cerebro.optstrategy(MyStrategy, myparam1=range(10, 20))`运行
MyStrategy10 次,其中myparam1的值从 10 到 19(请记住,Python 中的范围是半开放的,20不会被包含) -
其他元素
还有一些其他元素可以添加以增强回测体验。查看相应的部分以了解详情。方法包括:
-
addwriter -
addanalyzer -
addobserver(或addobservermulti)
-
-
更改经纪人
Cerebro 将在
backtrader中使用默认经纪人,但可以被覆盖:broker = MyBroker() cerebro.broker = broker # property using getbroker/setbroker methods` -
接收通知
如果数据源和/或经纪人发送通知(或创建它们的存储提供程序),它们将通过
Cerebro.notify_store方法接收。有三(3)种处理这些通知的方法- 通过
addnotifycallback(callback)调用向cerebro实例添加回调。回调函数必须支持此签名:
callback(msg, *args, **kwargs)`实际的
msg、*args和**kwargs接收的内容是实现定义的(完全取决于数据/经纪人/存储),但一般可以期望它们是可打印的,以便接收和实验。- 在添加到
cerebro实例的Strategy子类中覆盖notify_store方法。
签名:
notify_store(self, msg, *args, **kwargs)- 子类
Cerebro并覆盖notify_store(与Strategy中的签名相同)
这应该是最不受欢迎的方法
- 通过
执行回测
有一个单一的方法可以做到这一点,但它支持几个选项(也可以在实例化时指定),以决定如何运行:
result = cerebro.run(**kwargs)
请参阅下面的参考文献,了解可用的参数。
标准观察者
cerebro(除非另有说明)会自动实例化三个标准观察者
-
一个Broker观察者,用于跟踪
cash和value(投资组合) -
一个Trades观察者,应显示每次交易的有效性如何
-
一个Buy/Sell观察者,应记录操作何时执行
如果希望更干净的绘图,只需使用stdstats=False禁用它们
返回结果
cerebro在回测期间返回所创建的策略实例。这允许分析它们的操作,因为可以访问策略中的所有元素:
result = cerebro.run(**kwargs)
由run返回的result的格式取决于是否使用了优化(使用optstrategy添加了一个策略):
-
所有使用
addstrategy添加的策略result将是在回测期间运行的实例的list -
使用
optstrategy添加了 1 个或多个策略result将是list的list。每个内部列表将包含每次优化运行后的策略
注意
优化的默认行为已更改为仅返回系统中存在的分析器,以减轻跨计算机核心的消息传递负担。
如果希望返回完整的策略集,请将参数optreturn设置为False
提供对绘图功能的访问
如果安装了matplotlib,则可以绘制策略图。通常的模式是:
cerebro.plot()
请参阅下文的参考文献和绘图部分
回测逻辑
事物流程的简要概述:
-
传递任何存储通知
-
要求数据源提供下一组 ticks/bars
**版本更改:**版本 1.9.0.99 中已更改:新行为
数据源通过查看下一个将提供的datetime来同步。在新周期中尚未交易的数据源仍提供旧数据点,而具有新数据的数据源则提供此数据(以及指标的计算)
旧行为(在Cerebro中使用
oldsync=True时保留)第 1 个插入系统的数据是
datamaster,系统将等待它提供一个 tick其他数据源或多或少是
datamaster的从属,且:* If the next tick to deliver is newer (datetime-wise) than the one delivered by the `datamaster` it will not be delivered * May return without delivering a new tick for a number of reasons`逻辑被设计为轻松同步多个数据源和具有不同时间框架的数据源
-
通知策略有关已排队的经纪人订单、交易和现金/价值的通知
-
告诉经纪人接受排队的订单,并使用新数据执行待处理的订单
-
调用策略的
next方法以使策略评估新数据(并可能发出在经纪人中排队的订单)根据阶段,策略/指标的最小周期要求可能在满足之前是
prenext还是nextstart。在内部,策略还会触发
observers、indicators、analyzers和其他活动元素 -
告诉任何
writers将数据写入其目标
注意:
注意
在上述第 1 步中,当 数据源 传递新的柱集时,这些柱是 关闭 的。 这意味着数据已经发生了。
因此,在第 4 步中策略发出的 订单 无法使用第 1 步的数据 执行。
这意味着订单将使用 x + 1 的概念执行。 其中 x 是订单执行的柱时刻,而 x + 1 是下一个,它是可能的订单执行的最早时刻
参考
类 backtrader.Cerebro()
参数:
preload(默认:True)
是否预加载传递给 cerebro 的不同 data feeds 用于策略
runonce(默认:True)
在向量化模式下运行 Indicators 以加速整个系统。 策略和观察器将始终基于事件运行。
live(默认:False)
如果没有数据通过数据的 islive 方法报告自身为 live,但最终用户仍希望以 live 模式运行,可以将此参数设置为 true
这将同时停用 preload 和 runonce。 对内存节省方案没有影响。
在向量化模式下运行 Indicators 以加速整个系统。 策略和观察器将始终基于事件运行。
-
maxcpus(默认:无->所有可用核心)同时使用多少核心进行优化
-
stdstats(默认:True)
如果为 True,默认观察者将被添加:经纪人(现金和价值)、交易和买卖
oldbuysell(默认:False)
如果 stdstats 为 True 并且观察者自动添加,则此开关控制 BuySell 观察者的主要行为
-
False:使用现代行为,在低/高价格的下方/上方分别绘制买入/卖出信号,以避免图表混乱 -
True:使用已弃用的行为,在给定时刻的订单执行的平均价格绘制买入/卖出信号。 这当然会在 OHLC 柱或 Cloe 柱上方绘制,难以识别图的内容。 -
oldtrades(默认:False)
如果 stdstats 为 True 并且观察者自动添加,则此开关控制 Trades 观察者的主要行为
-
False:使用现代行为,其中所有数据的交易都用不同的标记绘制 -
True:使用旧的交易观察器,它使用相同的标记绘制交易,仅在它们是正数还是负数时有所区别。 -
exactbars(默认:False)
默认情况下,每个值都会存储在内存中的一行中。
可能的值:
* `True` or `1`: all “lines” objects reduce memory usage to the
automatically calculated minimum period.
If a Simple Moving Average has a period of 30, the underlying data
will have always a running buffer of 30 bars to allow the
calculation of the Simple Moving Average
* This setting will deactivate `preload` and `runonce`
* Using this setting also deactivates **plotting**
* `-1`: datafreeds and indicators/operations at strategy level will
keep all data in memory.
For example: a `RSI` internally uses the indicator `UpDay` to
make calculations. This subindicator will not keep all data in
memory
* This allows to keep `plotting` and `preloading` active.
* `runonce` will be deactivated
* `-2`: data feeds and indicators kept as attributes of the
strategy will keep all points in memory.
For example: a `RSI` internally uses the indicator `UpDay` to
make calculations. This subindicator will not keep all data in
memory
If in the `__init__` something like
`a = self.data.close - self.data.high` is defined, then `a`
will not keep all data in memory
* This allows to keep `plotting` and `preloading` active.
* `runonce` will be deactivated
objcache(默认:False)
实验选项,用于实现线条对象的缓存并减少它们的数量。从 UltimateOscillator 示例:
bp = self.data.close - TrueLow(self.data)
tr = TrueRange(self.data) # -> creates another TrueLow(self.data)
如果这是True,则TrueRange内的第 2 个TrueLow(self.data)将与bp计算中的签名匹配。它将被重用。
边缘情况可能会发生,其中这会使线条对象超出其最小周期并且导致故障,因此已禁用。
writer(默认:False)
如果设置为True,将创建一个默认的 WriterFile,它将打印到 stdout。它将被添加到策略中(除了用户代码添加的任何其他写入器)
tradehistory(默认:False)
如果设置为True,它将激活每个策略的每次交易的更新事件记录。这也可以通过策略方法set_tradehistory逐个策略地完成。
optdatas(默认:True)
如果为True且正在优化(并且系统可以preload并使用runonce,数据预加载将仅在主进程中执行一次,以节省时间和资源。
测试显示,从在83秒的样本执行中移动到66秒的执行速度提高了约20%。
optreturn(默认:True)
如果为True,则优化结果将不是完整的Strategy对象(以及所有datas、indicators、observers…),而是具有以下属性的对象(与Strategy中相同):
* `params` (or `p`) the strategy had for the execution
* `analyzers` the strategy has executed
在大多数情况下,只有分析器和与之相关的参数是评估策略性能所需的内容。如果需要对生成的值(例如指标)进行详细分析,则关闭此选项。
测试显示执行时间提高了13% - 15%。与optdatas结合使用,总增益增加到了优化运行的32%的总体加速。
oldsync(默认:False)
从版本 1.9.0.99 开始,多个数据的同步(相同或不同的时间框架)已更改为允许长度不同的数据。
如果希望保留旧的行为,并将 data0 设置为系统的主要数据,则将此参数设置为 true。
tz(默认:None)
为策略添加全局时区。参数tz可以是
* `None`: in this case the datetime displayed by strategies will be
in UTC, which has been always the standard behavior
* `pytz` instance. It will be used as such to convert UTC times to
the chosen timezone
* `string`. Instantiating a `pytz` instance will be attempted.
* `integer`. Use, for the strategy, the same timezone as the
corresponding `data` in the `self.datas` iterable (`0` would
use the timezone from `data0`)
cheat_on_open(默认:False)
在调用策略的next_open方法之前将会调用它。这发生在next之前,也发生在经纪人有机会评估订单之前。指标尚未重新计算。这允许发出一个订单,该订单考虑了前一天的指标,但使用open价格进行股份计算。
对于cheat_on_open订单执行,还需要调用cerebro.broker.set_coo(True)或使用BackBroker(coo=True)实例化一个经纪人(其中coo代表 cheat-on-open),或者将broker_coo参数设置为True。除非在下面禁用,否则 Cerebro 将自动执行此操作。
broker_coo(默认:True)
这将自动调用经纪人的set_coo方法,并使用True来激活cheat_on_open执行。仅当cheat_on_open也为True时才执行。
quicknotify(默认值:False)
经纪人通知将在下一个价格传递之前立即传递。 对于回测,这没有任何影响,但对于实时经纪人,通知可能会在交付柱形图之前很久就发生了。 当设置为 True 时,通知将尽快传递(请参阅实时数据源中的 qcheck)
设置为 False 以实现兼容性。 可能会更改为 True
addstorecb(callback)
添加一个回调来获取将由 notify_store 方法处理的消息
回调函数的签名必须支持以下内容:
callback(msg, *args, **kwargs)
实际接收到的 msg、*args 和 **kwargs 取决于实现(完全依赖于 数据/经纪人/存储),但通常应该期望它们是可打印的,以便接收和实验。
notify_store(msg, *args, **kwargs)
在 cerebro 中接收存储通知
此方法可以在 Cerebro 的子类中重写
如果 name 不为 None,则将其放入 data._name 中,该参数用于装饰/绘图目的。
adddatacb(callback)
adddata(data, name=None)
向获取将由 notify_data 方法处理的消息添加一个回调
- callback(data, status, *args, **kwargs)
实际接收到的 *args 和 **kwargs 取决于实现(完全依赖于 数据/经纪人/存储),但通常应该期望它们是可打印的,以便接收和实验。
实际接收到的 msg、*args 和 **kwargs 取决于实现(完全依赖于 数据/经纪人/存储),但通常应该期望它们是可打印的,以便接收和实验。
在 cerebro 中接收数据通知
此方法可以在 Cerebro 的子类中重写
回调函数的签名必须支持以下内容:
notify_data(data, status, *args, **kwargs)
向组合中添加一个 Data Feed 实例。
添加一个 callback 来获取将由 notify_store 方法处理的消息
resampledata(dataname, name=None, **kwargs)
向系统添加一个将由系统重新采样的 Data Feed
如果 name 不为 None,则将其放入 data._name 中,该参数用于装饰/绘图目的。
任何其他支持重新采样过滤器的 kwargs,如 timeframe、compression、todate,都将被透明地传递
replaydata(dataname, name=None, **kwargs)
向系统添加一个将由系统重播的 Data Feed
如果 name 不为 None,则将其放入 data._name 中,该参数用于装饰/绘图目的。
任何其他支持回放过滤器的 kwargs,如 timeframe、compression、todate,都将被透明地传递
chaindata(*args, **kwargs)
将几个数据源串联成一个
如果 name 被传递为命名参数且不为 None,则将其放入 data._name 中,该参数用于装饰/绘图目的。
如果为 None,则将使用第 1 个数据的名称
rolloverdata(*args, **kwargs)
将几个数据源链接到一个数据源中
如果将 name 作为命名参数传递,并且不为 None,则将放入 data._name 中,用于装饰/绘图目的。
如果为 None,则将使用第 1 个数据的名称
任何其他的 kwargs 将传递给 RollOver 类
addstrategy(strategy, *args, **kwargs)
将 Strategy 类添加到混合中,以进行单次运行。实例化将在运行时发生。
args 和 kwargs 将像在实例化期间一样传递给策略。
返回用于引用其他对象(如调整器)的添加索引
optstrategy(strategy, *args, **kwargs)
将 Strategy 类添加到混合中以进行优化。实例化将在运行时发生。
args 和 kwargs 必须是可迭代的,其中包含要检查的值。
示例:如果一个策略接受一个参数 period,为了优化目的,optstrategy 的调用如下所示:
- cerebro.optstrategy(MyStrategy, period=(15, 25))
这将为值 15 和 25 执行优化。而
- cerebro.optstrategy(MyStrategy, period=range(15, 25))
将使用 period 值 15 -> 25(因为 Python 中的范围是半开放的,所以不包括 25)执行 MyStrategy
如果传递了一个参数,但不应该进行优化,则调用如下:
- cerebro.optstrategy(MyStrategy, period=(15,))
请注意,period 仍然传递为可迭代对象 … 只有 1 个元素
backtrader 将尝试识别诸如以下情况:
- cerebro.optstrategy(MyStrategy, period=15)
并在可能的情况下创建内部伪可迭代对象
optcallback(cb)
将 callback 添加到将在每个策略运行时调用的回调列表中进行优化
签名:cb(strategy)
addindicator(indcls, *args, **kwargs)
将 Indicator 类添加到混合中。实例化将在传递的策略的运行时完成
addobserver(obscls, *args, **kwargs)
将 Observer 类添加到混合中。实例化将在运行时完成
addobservermulti(obscls, *args, **kwargs)
将 Observer 类添加到混合中。实例化将在运行时完成
它将每个“数据”系统中添加一次。一个用例是观察单个数据的买入/卖出观察者。
反例是 CashValue,它观察系统范围的值
addanalyzer(ancls, *args, **kwargs)
将 Analyzer 类添加到混合中。实例化将在运行时完成
addwriter(wrtcls, *args, **kwargs)
将 Writer 类添加到混合中。实例化将在运行时在 cerebro 中完成
run(**kwargs)
执行回测的核心方法。传递给它的任何 kwargs 都会影响实例化时 Cerebro 的标准参数的值。
如果 cerebro 没有数据,则该方法将立即退出。
它具有不同的返回值:
-
对于无优化:包含使用
addstrategy添加的策略类实例的列表 -
用于优化:包含使用
addstrategy添加的 Strategy 类实例的列表的列表
runstop()
如果从策略内部或其他任何地方调用,包括其他线程,执行将尽快停止。
setbroker(broker)
为此策略设置特定的broker实例,替换从 cerebro 继承的实例。
getbroker()
返回经纪人实例。
这也可以作为名为broker的property使用
绘图(plotter=None,numfigs=1,iplot=True,start=None,end=None,width=16,height=9,dpi=300,tight=True,use=None,**kwargs)
在 cerebro 内部绘制策略
如果plotter为 None,则会创建一个默认的Plot实例,并在实例化期间将kwargs传递给它。
numfigs将绘图分成指定数量的图表,如果需要,可以减少图表密度
iplot:如果为True并在notebook中运行,则图表将内联显示
use:将其设置为所需 matplotlib 后端的名称。它将优先于iplot
start:策略或datetime.date、datetime.datetime实例的日期时间线数组的索引,指示绘图的开始
end:策略的日期时间线数组的索引或datetime.date、datetime.datetime实例,指示绘图的结束
width:保存图形的英寸
height:保存图形的英寸
dpi:保存图形的每英寸点数的质量
tight:仅保存实际内容而不是图形的框架
添加 sizer(sizercls,*args,**kwargs)
添加一个Sizer类(和 args),它是添加到 cerebro 的任何策略的默认 sizer
addsizer_byidx(idx,sizercls,*args,**kwargs)
按 idx 添加一个Sizer类。此 idx 是与addstrategy返回的兼容引用。只有由idx引用的策略将接收此大小
add_signal(sigtype,sigcls,*sigargs,**sigkwargs)
向系统添加一个信号,稍后将其添加到SignalStrategy中。
signal_concurrent(onoff)
如果向系统添加信号并且将concurrent值设置为 True,则将允许并发订单
signal_accumulate(onoff)
如果向系统添加信号并且将accumulate值设置为 True,则在已经进入市场时进入市场,将允许增加头寸
signal_strategy(stratcls,*args,**kwargs)
添加一个可以接受信号的 SignalStrategy 子类
addcalendar(cal)
向系统添加全局交易日历。个别数据源可能具有覆盖全局日历的单独日历
cal可以是TradingCalendar的实例、字符串或pandas_market_calendars的实例。字符串将被实例化为PandasMarketCalendar(需要系统中安装pandas_market_calendar模块。
如果传递的是 TradingCalendarBase 的子类(而不是实例),它将被实例化
addtz(tz)
这也可以通过参数tz完成
为策略添加全局时区。参数tz可以是
-
None:在这种情况下,策略显示的日期时间将为 UTC,这一直是标准行为 -
pytz实例。将按此使用它将 UTC 时间转换为所选时区 -
string。将尝试实例化一个pytz实例。 -
integer。对于策略,使用与self.datas可迭代对象中相应data相同的时区(0将使用来自data0的时区)
add_timer(when, offset=datetime.timedelta(0), repeat=datetime.timedelta(0), weekdays=[], weekcarry=False, monthdays=[], monthcarry=True, allow=None, tzdata=None, strats=False, cheat=False, *args, **kwargs)
安排定时器以调用notify_timer
-
参数
when (-) – 可以是
-
datetime.time实例(见下文tzdata) -
bt.timer.SESSION_START表示会话开始 -
bt.timer.SESSION_END表示会话结束 -
必须是
datetime.timedelta实例的offset
用于偏移值
when。与SESSION_START和SESSION_END结合使用时,它具有有意义的用途,用于指示诸如在会话开始后15 分钟调用定时器之类的事情。-
必须是
datetime.timedelta实例的repeat指示如果在第 1 次调用后,后续调用将在同一会话中按计划的
repeat增量中安排一旦定时器超过会话结束,它将被重置为
when的原始值 -
weekdays:一个排序的可迭代对象,其中的整数表示可以实际调用定时器的日期(ISO 代码,星期一为 1,星期日为 7)如果未指定,定时器将在所有日期上都处于活动状态。
-
weekcarry(默认值:False)。如果为True且周几未见(例如:交易假期),则定时器将在下一天执行(即使在新的一周中) -
monthdays:一个排序的可迭代对象,其中的整数表示定时器必须执行的月份中的哪一天。例如,每个月的第15天始终执行如果未指定,定时器将在所有日期上都处于活动状态
-
monthcarry(默认值:True)。如果当天没有看到(周末、交易假期),则定时器将在下一个可用日期执行。 -
allow(默认值:None)。一个回调函数,接收一个datetime.date实例,并返回True如果该日期允许定时器,否则返回False -
tzdata可以是None(默认值),一个pytz实例或一个data feed实例。None:when按面值解释(即使它不是 UTC,也会处理它)pytz实例:when将被解释为时区实例指定的本地时间。data feed实例:when将被解释为数据源实例的tz参数指定的本地时间。注意
如果
when是SESSION_START或SESSION_END且tzdata为None,则系统中的第 1 个数据源(也称为self.data0)将用作查找会话时间的参考。 -
strats(默认值:False)还会调用策略的notify_timer -
cheat(默认为False)如果为True,则会在经纪人有机会评估订单之前调用计时器。例如,在交易会话开始之前,可以根据开盘价下订单。 -
*args: 任何额外的参数都将传递给notify_timer。 -
**kwargs: 任何额外的关键字参数都将传递给notify_timer。
-
返回值:
- 创建的计时器
notify_timer(timer, when, *args, **kwargs)
接收计时器通知,其中 timer 是由 add_timer 返回的计时器,when 是调用时间。args 和 kwargs 是传递给 add_timer 的任何额外参数。
实际的 when 时间可能会晚一些,但系统可能无法在之前调用计时器。该值是计时器值,而不是系统时间。
add_order_history(orders, notify=True)
将订单历史记录添加到经纪人中,以供性能评估直接执行
-
orders: 是一个可迭代对象(例如列表、元组、迭代器、生成器),其中每个元素也将是一个具有以下子元素的可迭代对象(有 2 种格式)[datetime, size, price]或[datetime, size, price, data]注意
必须按照日期时间升序排序(或生成排序的元素)。
其中:
-
datetime是一个 pythondate/datetime实例,或者是一个格式为 YYYY-MM-DD[THH:MM:SS[.us]] 的字符串,方括号中的元素是可选的。 -
size是一个整数(买入为正,卖出为负) -
price是一个浮点数/整数 -
如果存在
data,则可以采用以下任何值-
None - 将使用第 1 个数据源作为目标。
-
integer - 将使用该索引对应的数据(在Cerebro中的插入顺序)。
-
string - 该名称的数据,例如通过
cerebro.addata(data, name=value)分配,将作为目标。
-
-
-
notify(默认值:True)如果设为
True,则会通知系统中插入的第 1 个策略,其会根据每个订单中的信息创建人工订单。
注意
隐含在描述中的是需要添加一个数据源,该数据源是订单的目标。例如,分析器需要追踪回报率。
节省内存
www.backtrader.com/docu/memory-savings/memory-savings/
发布版本 1.3.1.92已经重新设计并完全实现了先前存在的节省内存方案,尽管没有受到太多宣传并且使用较少。
backtrader曾经(并将继续)在内存较大的机器上开发,并且与通过绘图提供的视觉反馈是一个必需的美好事物相结合,使得设计决策变得容易:将所有内容保存在内存中。
这个决定有一些缺点:
-
用于数据存储的
array.array在超过某些限制时必须分配和移动数据。 -
RAM 较少的机器可能会受到影响。
-
连接到可以在线运行数周/数月、提供数千秒/分钟分辨率 ticks 的实时数据源
后者比第一点更加重要,因为另一个设计决定是为了 backtrader:
-
必须是纯 Python,以便在需要时在嵌入式系统中运行。
将来的一个场景可能是
backtrader连接到第二台机器,该机器提供实时数据源,而backtrader本身运行在类似 Raspberry Pi 或甚至更有限的设备上,如 ADSL 路由器(AVM Frit!Box 7490,带有 Freetz 映像)
因此需要 backtrader 支持动态内存方案。现在 Cerebro 可以使用以下语义进行实例化或run:
-
exactbars(默认值:False)
默认值为
False,每个存储在一行中的值都会保存在内存中。可能的值:
-
True或1:所有“lines”对象将内存使用量减少到自动计算的最小周期。如果简单移动平均值的周期为 30,底层数据将始终具有 30 个条形图的运行缓冲区,以允许计算简单移动平均值
-
此设置将停用
preload和runonce。 -
使用此设置还会停用plotting。
-
-
-1:在策略级别,数据和指标/操作将保留所有数据在内存中。例如:
RSI在内部使用指标UpDay进行计算。此子指标将不会将所有数据保存在内存中。-
这允许保持
plotting和preloading处于活动状态。 -
runonce将被停用。
-
-
-2:作为策略属性保留的数据和指标将在内存中保存所有数据。例如:
RSI在内部使用指标UpDay进行计算。此子指标将不会将所有数据保存在内存中。如果在
__init__中定义了类似a = self.data.close - self.data.high这样的内容,则a将不会将所有数据保存在内存中。-
这允许保持
plotting和preloading处于活动状态。 -
runonce将被停用。
-
-
一如既往,一个例子胜过千言万语。一个示例脚本显示了差异。它针对 1996 年至 2015 年的 Yahoo 每日数据运行,总共 4965 天。
注意
这只是一个小样本。每天交易 14 小时的 EuroStoxx50 期货,在仅 1 个月的交易中将产生大约 18000 个 1 分钟的 K 线。
执行脚本 1^(st)以查看在不请求内存节省时使用了多少内存位置:
$ ./memory-savings.py --save 0
Total memory cells used: 506430
对于 1 级(总储蓄):
$ ./memory-savings.py --save 1
Total memory cells used: 2041
天啊!!!从五十万跌至2041。确实。系统中的每个lines对象都使用collections.deque作为缓冲区(而不是array.array),并且长度被限制在绝对需要的最小值以进行请求的操作。例如:
- 在数据源上使用期间为
30的SimpleMovingAverage策略。
在这种情况下,将进行以下调整:
-
数据源将具有
30个位置的缓冲区,这是SimpleMovingAverage产生下一个值所需的数量 -
SimpleMovingAverage将有一个1位置的缓冲区,因为除非其他指标需要(这些指标将依赖于移动平均线),否则不需要保留较大的缓冲区。
注意
这种模式最吸引人且可能最重要的功能是,所使用的内存量在脚本的整个生命周期内保持不变。
无论数据源的大小如何。
如果例如连接到长时间的实时数据源,则这将非常有用。
但请注意:
-
绘图不可用
-
还有其他的内存消耗来源,随着时间的推移会积累,比如策略生成的
orders。 -
此模式只能在
cerebro中的runonce=False时使用。对于实时数据源,这也是强制性的,但在简单回测的情况下,这比runonce=True慢。肯定有一个权衡点,从而内存管理比逐步执行回测更昂贵,但这只能由平台的最终用户在每个案例中进行判断。
现在是负级别。这些级别旨在在仍然节省相当数量的内存的同时保持绘图可用。第一级别-1:
$ ./memory-savings.py --save -1
Total memory cells used: 184623
在这种情况下,指标的第 1 级别(在策略中声明的那些)保持其完整长度的缓冲区。但是如果这些指标依赖于其他指标(这就是情况),则子对象将被长度限制。在这种情况下,我们已经从:
506430个内存位置到->184623
超过 50%的节省。
注意
当然,array.array对象已被collections.deque所取代,这在内存方面更昂贵,尽管在操作方面更快。但是collections.deque对象相当小,并且节省了大致计算的内存位置的使用。
现在是级别-2,这也是为了节省在策略级别上声明的指标的内存,这些指标已被标记为不需要绘制:
$ ./memory-savings.py --save -2
Total memory cells used: 174695
现在没有保存太多。这是因为一个单独的指标已被标记为不需要绘制:TestInd().plotinfo.plot = False
让我们看看来自最后一个示例的绘图:
$ ./memory-savings.py --save -2 --plot
Total memory cells used: 174695
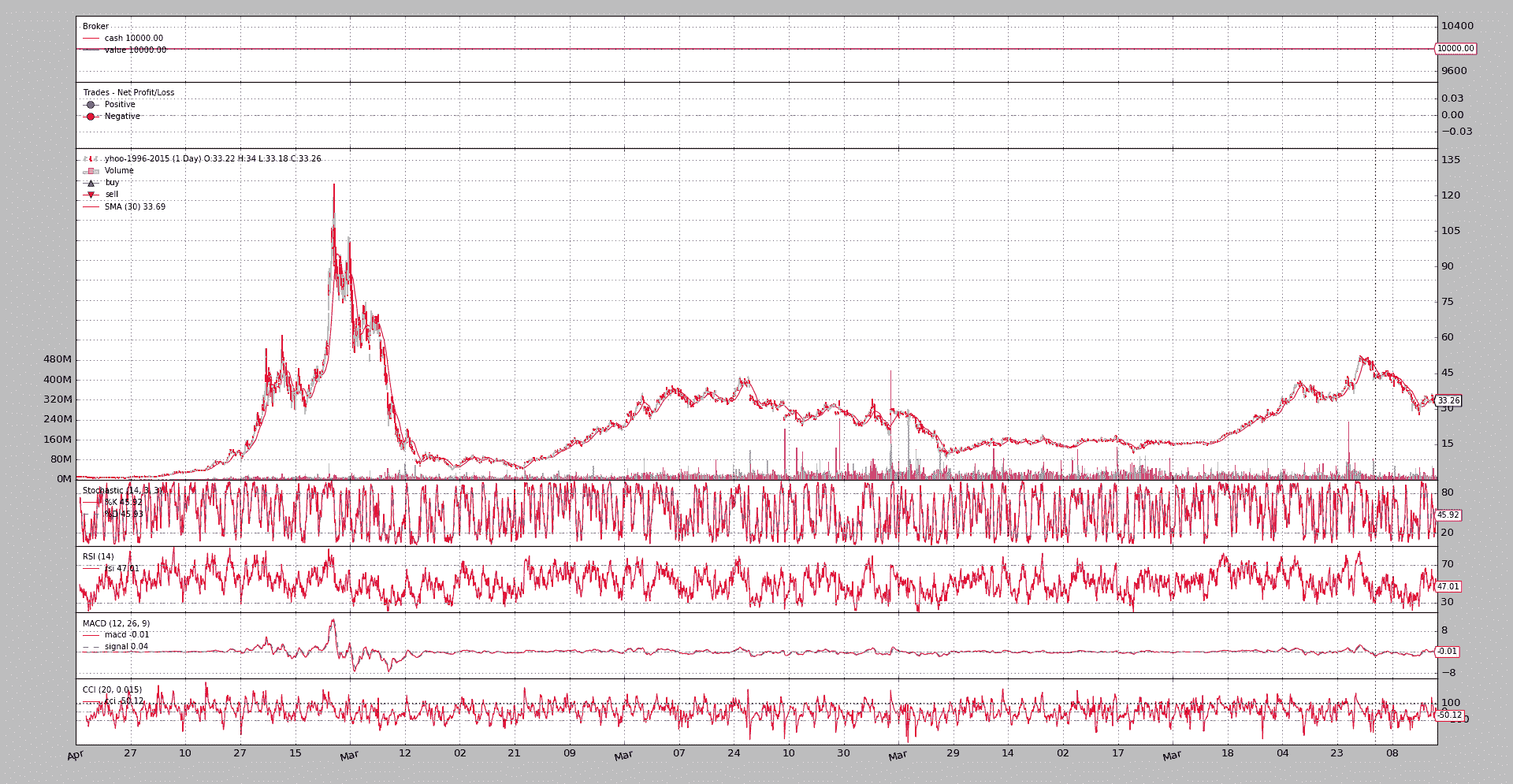
对于感兴趣的读者,示例脚本可以生成对指标层次结构中遍历的每个行对象的详细分析。运行时启用绘图(保存在-1):
$ ./memory-savings.py --save -1 --lendetails
-- Evaluating Datas
---- Data 0 Total Cells 34755 - Cells per Line 4965
-- Evaluating Indicators
---- Indicator 1.0 Average Total Cells 30 - Cells per line 30
---- SubIndicators Total Cells 1
---- Indicator 1.1 _LineDelay Total Cells 1 - Cells per line 1
---- SubIndicators Total Cells 1
...
---- Indicator 0.5 TestInd Total Cells 9930 - Cells per line 4965
---- SubIndicators Total Cells 0
-- Evaluating Observers
---- Observer 0 Total Cells 9930 - Cells per Line 4965
---- Observer 1 Total Cells 9930 - Cells per Line 4965
---- Observer 2 Total Cells 9930 - Cells per Line 4965
Total memory cells used: 184623
同样的,但启用了最大节省(1):
$ ./memory-savings.py --save 1 --lendetails
-- Evaluating Datas
---- Data 0 Total Cells 266 - Cells per Line 38
-- Evaluating Indicators
---- Indicator 1.0 Average Total Cells 30 - Cells per line 30
---- SubIndicators Total Cells 1
...
---- Indicator 0.5 TestInd Total Cells 2 - Cells per line 1
---- SubIndicators Total Cells 0
-- Evaluating Observers
---- Observer 0 Total Cells 2 - Cells per Line 1
---- Observer 1 Total Cells 2 - Cells per Line 1
---- Observer 2 Total Cells 2 - Cells per Line 1
第二个输出立即显示了数据源中的行数被限制为38个内存位置,而不是完整数据源长度4965。
并且指标和观察者在可能的情况下被限制为1,如输出的最后几行所示。
脚本代码和用法
在backtrader的源代码中可作为示例使用。用法:
$ ./memory-savings.py --help
usage: memory-savings.py [-h] [--data DATA] [--save SAVE] [--datalines]
[--lendetails] [--plot]
Check Memory Savings
optional arguments:
-h, --help show this help message and exit
--data DATA Data to be read in (default: ../../datas/yhoo-1996-2015.txt)
--save SAVE Memory saving level [1, 0, -1, -2] (default: 0)
--datalines Print data lines (default: False)
--lendetails Print individual items memory usage (default: False)
--plot Plot the result (default: False)
代码:
from __future__ import (absolute_import, division, print_function,
unicode_literals)
import argparse
import sys
import backtrader as bt
import backtrader.feeds as btfeeds
import backtrader.indicators as btind
import backtrader.utils.flushfile
class TestInd(bt.Indicator):
lines = ('a', 'b')
def __init__(self):
self.lines.a = b = self.data.close - self.data.high
self.lines.b = btind.SMA(b, period=20)
class St(bt.Strategy):
params = (
('datalines', False),
('lendetails', False),
)
def __init__(self):
btind.SMA()
btind.Stochastic()
btind.RSI()
btind.MACD()
btind.CCI()
TestInd().plotinfo.plot = False
def next(self):
if self.p.datalines:
txt = ','.join(
['%04d' % len(self),
'%04d' % len(self.data0),
self.data.datetime.date(0).isoformat()]
)
print(txt)
def loglendetails(self, msg):
if self.p.lendetails:
print(msg)
def stop(self):
super(St, self).stop()
tlen = 0
self.loglendetails('-- Evaluating Datas')
for i, data in enumerate(self.datas):
tdata = 0
for line in data.lines:
tdata += len(line.array)
tline = len(line.array)
tlen += tdata
logtxt = '---- Data {} Total Cells {} - Cells per Line {}'
self.loglendetails(logtxt.format(i, tdata, tline))
self.loglendetails('-- Evaluating Indicators')
for i, ind in enumerate(self.getindicators()):
tlen += self.rindicator(ind, i, 0)
self.loglendetails('-- Evaluating Observers')
for i, obs in enumerate(self.getobservers()):
tobs = 0
for line in obs.lines:
tobs += len(line.array)
tline = len(line.array)
tlen += tdata
logtxt = '---- Observer {} Total Cells {} - Cells per Line {}'
self.loglendetails(logtxt.format(i, tobs, tline))
print('Total memory cells used: {}'.format(tlen))
def rindicator(self, ind, i, deep):
tind = 0
for line in ind.lines:
tind += len(line.array)
tline = len(line.array)
thisind = tind
tsub = 0
for j, sind in enumerate(ind.getindicators()):
tsub += self.rindicator(sind, j, deep + 1)
iname = ind.__class__.__name__.split('.')[-1]
logtxt = '---- Indicator {}.{} {} Total Cells {} - Cells per line {}'
self.loglendetails(logtxt.format(deep, i, iname, tind, tline))
logtxt = '---- SubIndicators Total Cells {}'
self.loglendetails(logtxt.format(deep, i, iname, tsub))
return tind + tsub
def runstrat():
args = parse_args()
cerebro = bt.Cerebro()
data = btfeeds.YahooFinanceCSVData(dataname=args.data)
cerebro.adddata(data)
cerebro.addstrategy(
St, datalines=args.datalines, lendetails=args.lendetails)
cerebro.run(runonce=False, exactbars=args.save)
if args.plot:
cerebro.plot(style='bar')
def parse_args():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
description='Check Memory Savings')
parser.add_argument('--data', required=False,
default='../../datas/yhoo-1996-2015.txt',
help='Data to be read in')
parser.add_argument('--save', required=False, type=int, default=0,
help=('Memory saving level [1, 0, -1, -2]'))
parser.add_argument('--datalines', required=False, action='store_true',
help=('Print data lines'))
parser.add_argument('--lendetails', required=False, action='store_true',
help=('Print individual items memory usage'))
parser.add_argument('--plot', required=False, action='store_true',
help=('Plot the result'))
return parser.parse_args()
if __name__ == '__main__':
runstrat()