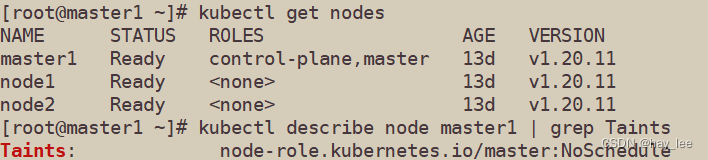
一般来说,OCR的任务是将图片文字转化成计算机可编辑的文字,一般不识别字体,当然,也不排除某些OCR软件可以识别字体的,具体来说,造成这种现象的可能原因如下:
1. **字体匹配问题**:OCR可能使用的是默认的字体库,而你的图片中的字体与默认字体不匹配,导致识别结果与实际字体有所偏差。
2. **图像质量问题**:图片质量不佳、模糊或失真可能会影响OCR的准确性,导致识别结果不理想。
3. **文本处理问题**:如果图片中的文本被扭曲、倾斜或受到其他形式的干扰,可能会导致OCR识别出错误的字体。
为了调整OCR识别结果与实际字体的匹配度,可以尝试以下方法:
1. **优化图像质量**:确保图片的清晰度和质量,可以通过调整光照、对比度、色彩等参数来改善图像质量。
2. **选择合适的OCR引擎**:有些OCR引擎支持自定义字体库或者根据需要选择合适的字体。可以尝试不同的OCR引擎,看看哪个更适合你的需求。
3. **预处理图像**:对图像进行预处理,如去除背景噪音、平滑化、裁剪等操作,可以提高OCR的准确性。
4. **手动调整识别结果**:如果OCR识别结果与实际字体不匹配,你可以手动修改识别结果,校正成正确的字体。
5. **训练自定义OCR模型**:对于特定的字体或者文本样式,你可以考虑训练自定义的OCR模型,以提高识别的准确性。









![[入门]测试层级-ApiHug准备-测试篇-005](https://img-blog.csdnimg.cn/img_convert/016ed28023b501ad5080767a14c9e45c.gif)