吃掉字符串中相邻的相同字符
文章目录
- 吃掉字符串中相邻的相同字符
- 题目重现
- 解法一:(基于 erase() 函数实现)
- 解法二:(利用 栈 辅助实现)
- 总结
题目链接: 点击消除_牛客网
题目重现
牛牛拿到了一个字符串。
他每次“点击”,可以把字符串中相邻两个相同字母消除,例如,字符串 “abbc” 点击后可以生成 “ac”。
但相同而不相邻、不相同的相邻字母都是不可以被消除的。
牛牛想把字符串变得尽可能短。他想知道,当他点击了足够多次之后,字符串的最终形态是什么?
输入描述
一个字符串,仅由小写字母组成。(字符串长度不大于300000)
输出描述
一个字符串,为“点击消除”后的最终形态。若最终的字符串为空串,则输出0。
解法一:(基于 erase() 函数实现)
缺点:
- 效率问题:使用
erase()函数会导致字符串中的元素频繁移动,特别是在字符串较长时,这会造成较大的性能开销。- 复杂的边界处理:代码中需要多次检查迭代器是否到达字符串的末尾,这增加了代码的复杂性。
代码示例:
void eatCharacters(std::string& s)
{
auto cur = s.begin();
auto pre = cur + 1;
for (; pre != s.end(); pre++, cur++)
{
while (*cur == *pre)
{
bool cur_is_begin = (cur == s.begin()) ? true : false;
auto cur_l = cur - 1;
pre = s.erase(cur, pre + 1);
if (pre == s.end()) { return; } // 注意这里判断避免后面越界
if (cur_is_begin)
{
cur = pre;
pre++;
if (pre == s.end()) { return; } // 注意这里判断避免后面越界
}
else
{
cur = cur_l;
}
}
}
}
void test() {
std::string input;
std::cin >> input; // 从标准输入读取字符串
eatCharacters(input);
if (input.size() == 0)
{
cout << 0 << endl;
}
else
{
std::cout << input << std::endl; // 输出最终状态
}
}
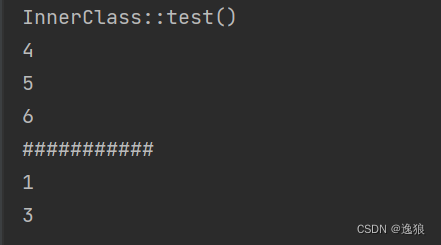
提交截图:

评价:
时间复杂度:
- 最坏情况下,每次
erase()调用都可能导致整个字符串的复制,因此时间复杂度为O(n^2),其中 n 是字符串的长度。空间复杂度:
- 由于直接在原字符串上操作,空间复杂度为
O(1)。实际运行时间:
- 在字符串较短或者需要消除的字符对较少时,这种方法可能表现得相当快。
- 在字符串较长且有大量相邻字符对需要消除时,性能会显著下降。
适用场景:
- 当处理的字符串较短,且内存资源受限时,这种方法可能更合适。
解法二:(利用 栈 辅助实现)
缺点:
- 空间复杂度:虽然时间复杂度有所优化,但是这种方法需要额外的空间来存储栈。
代码示例:
void eatCharacters(std::string& s) {
stack<char> st;
for (auto e : s)
{
if (st.empty() || st.top() != e) { st.push(e); }
else {
st.pop();
}
}
s.clear();
while (!st.empty())
{
s = st.top() + s;
st.pop();
}
}
void test() {
std::string input;
std::cin >> input; // 从标准输入读取字符串
eatCharacters(input);
if (input.size() == 0)
{
cout << 0 << endl;
}
else
{
std::cout << input << std::endl; // 输出最终状态
}
}
提交截图:

评价:
时间复杂度:
- 由于每个字符只被处理一次,时间复杂度为
O(n)。空间复杂度:
- 需要一个额外的栈来存储字符,最坏情况下空间复杂度为
O(n)。实际运行时间:
- 对于任何长度的字符串,这种方法都能保持稳定的性能。
- 在处理大量数据时,这种方法的性能优势更加明显。
适用场景:
- 当处理的字符串非常长,或者需要频繁执行消除操作时,这种方法更为高效。
总结
在选择解法时,应考虑问题的规模和性能要求。对于小规模数据,两种方法都可以工作得很好,但解法一可能更节省内存。对于大规模数据,解法二的性能优势将非常明显,尽管它需要更多的内存。在实际应用中,如果内存不是问题,推荐使用解法二,因为它提供了更好的时间效率和代码的可维护性。
执行消除操作时,这种方法更为高效。