性能测试-数据库优化
数据库的优化方向
1、数据库是安装在操作系统中,是非常追求磁盘的稳定性。MySQL的库是磁盘文件夹,表是磁盘文件所以数据库的优化:
- 磁盘的性能
- 1、磁盘的速度,减少同时读写,考虑读写分离;
- 2、考虑用内存速度 换磁盘速度,用缓存;
- 3、磁盘矩阵RAID;
- 4、机械硬盘考虑转速更快
- 数据库的缓存:
- ①是数据库本身有缓存机制。
- ②缓存数据库,如redis
2、数据库管理系统是安装在操作系统中的,相当于操作系统的一个软件而已,它受操作系统限制
- 操作系统的硬件配置提高
- 操作系统资源分配
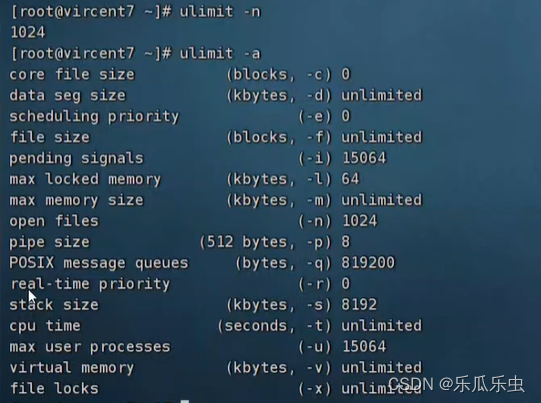
- 操作系统本身也是一个软件,自身就有限制参数(ulimit命令、sysctl命令)
- ulimit限制 ulimit -n可以改变程序允许打开的最大进程和线程数量
3、数据库管理系统,本身也是软件:软件自身参数限制
- 配置文件 my.cnf
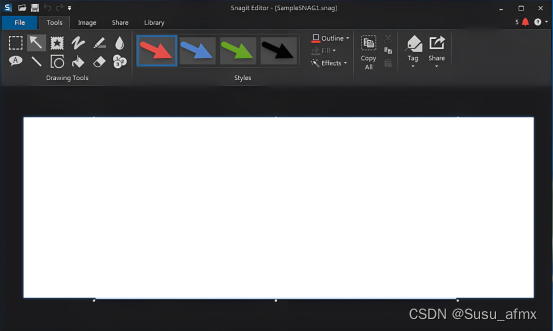
- 可以通过 show variables sql脚本查看数据库的所有的参数限制,msyql数据库现在有500+多个配置参数。
- max_connections 151 最大连接数
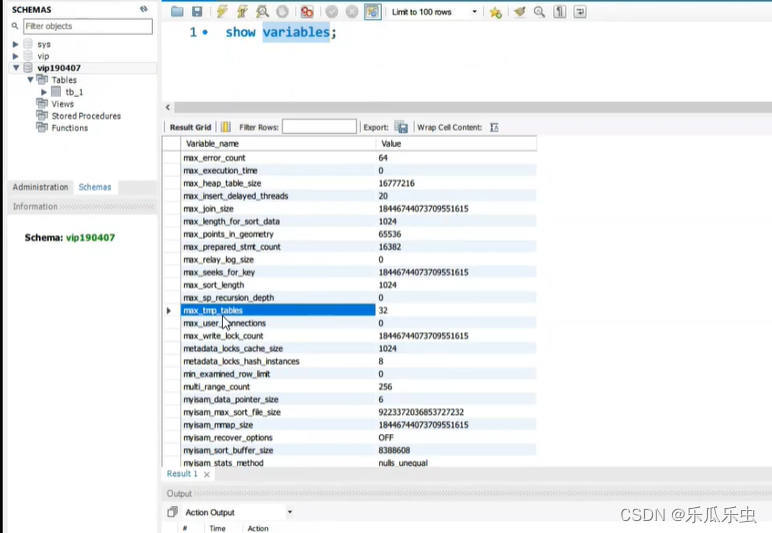
- slow_query_log OFF 慢查询的开关 slow_query_log_file 慢查询日志 long_query_time 10秒 慢查询的阈值
- 配置参数都一些关键词: max、min、size、buff、cache、innodb、myisam、limit、query、log
- 可以使用 show variables like ‘%关键词%’ 进行模糊搜索
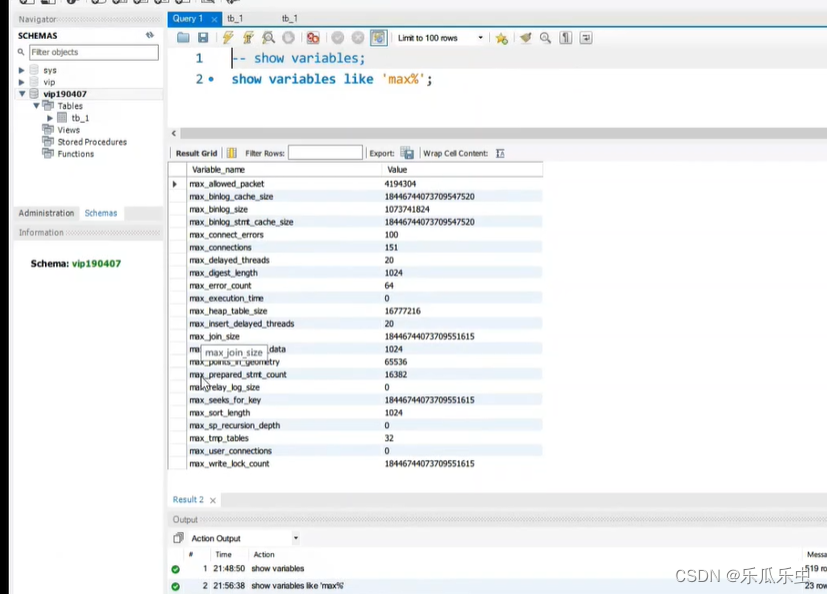
配置参数可以修改的,遇到性能问题时可能需要修改这些配置参数的值。
应用服务链接数不够,HTTP协议错误的响应码是: 4xx
数据库服务的连接数不够,http协议错误的响应码是: 5xx
数据库自身的配置参数
数据库自身的配置参数:
- show variables;
- 查看数据库的配置文件,但是这个配置文件中,没有包含所有的,如果配置文件中有优先使用 配置文件中的内容。(只有一部分可以修改)
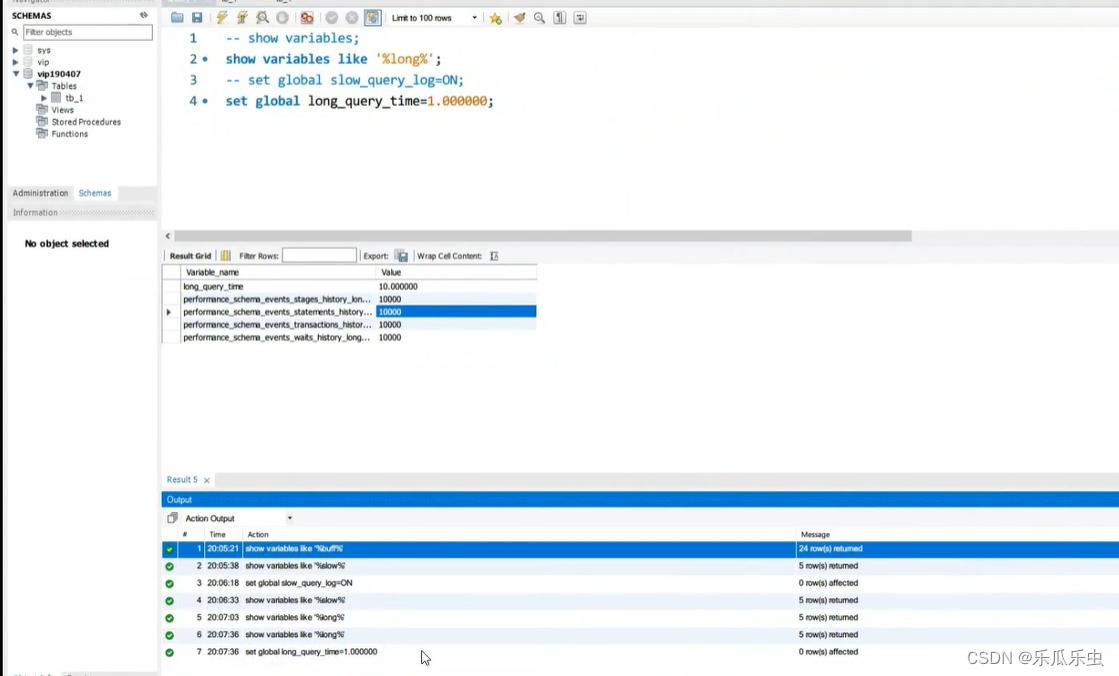
数据库的配置修改
- 通过sql语句来修改配置信息。------数据库一旦重启配置就失效。 set global 参数名称=值 这个 修改,不能修改所有的配置参数
- 修改数据库的配置文件。-----修改之后,要重启数据库才能生效。
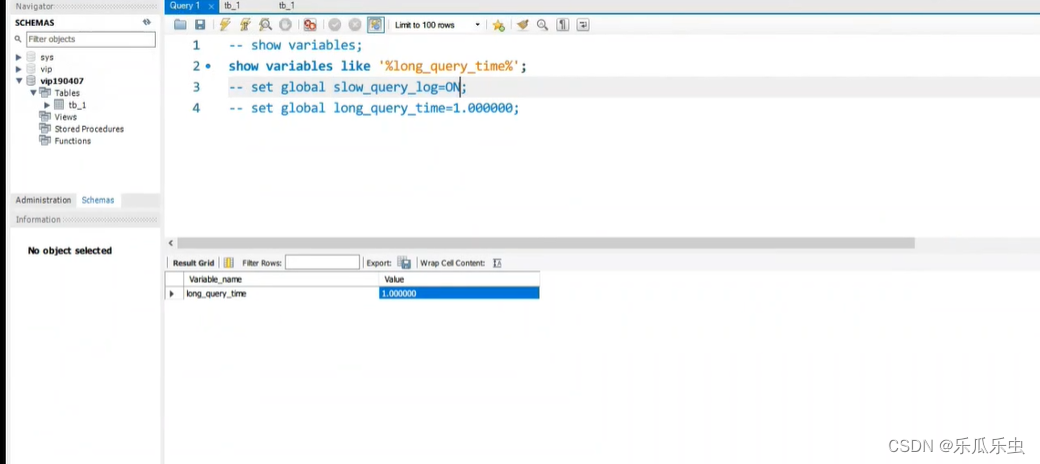
- 修改了慢查询的开关:slow_query_log=ON
- 修改了慢查询的阈值:long_query_time=1.000000就是1秒钟,就是当某一个sql的执行时长,超过1秒钟的时候,就会认为是一个慢sql。
这个阈值到底设置为多少,一般要根据你公司的实际情况。
做性能测试时,HTTP协议的接口响应时间,能接受的极限时长是多少:1.5s
如果把慢查询的开关开启了,阈值也设置了,那么在项目运行过程中,如果某个sql的执行时长超过阈值,就会记录到慢sql的日志文件中。这个日志文件由slow_query_log_file这个配置来决定写入到哪个 路径下。这样我们就获取到了慢sql的日志。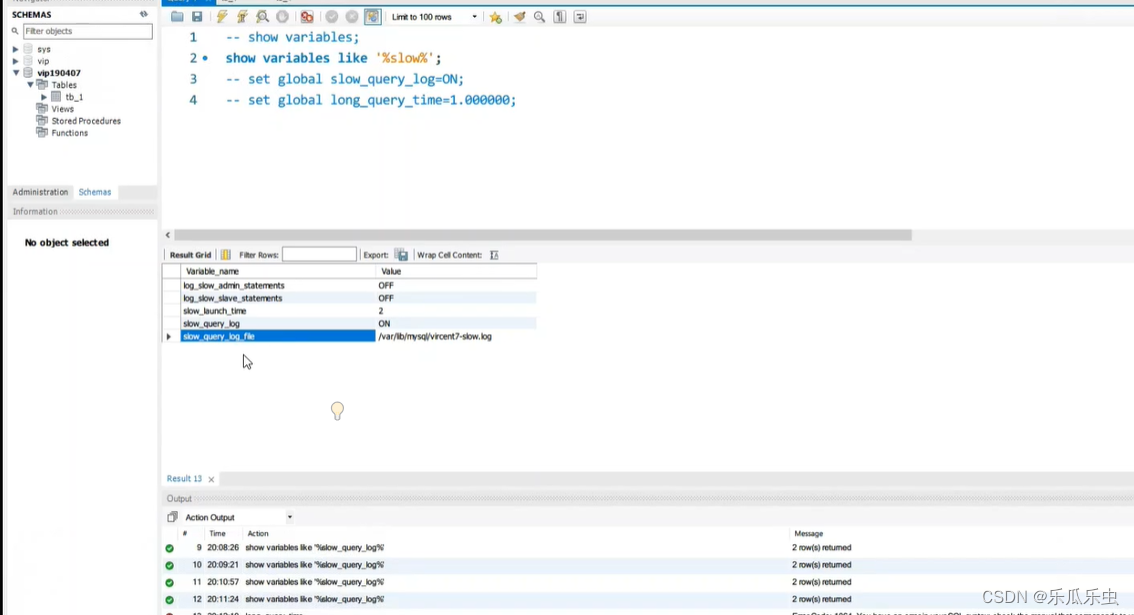
数据库对磁盘的性能要求比较到,因为对数据库的操作,需要磁盘的io,而这个慢sql日志一旦开启,就 要使用磁盘的写操作。就会影响数据库的性能。所以,在生产环境中,数据库的慢sql的开关,一般是不 允许开启的。只有,在分析性能时,怀疑有慢sql,才开启这个开关。
在企业中,有很多日志平台或数据库监控平台,在这些平台中是可以直接看到sql语句和他们的执行时长的。这些日志、监控平台,是记录了sql和sql的执行时长,所以不管你有没有开启慢sql的开关,日志中都会有sql和sql的执行时长。通过一些监控平台,根据时长的倒序,也是可以发现慢sql的。
实战获取慢sql
数据库的配置参数
max_connections 最大连接数,现在是151 ; centos系统默认情况下一个进程运行打开的进程+线程 数量默认是1024,数据库的最大连接数大概是这个值的1/5,也就是说在不修改操作系统的参数配置情况下,数据库的最大连接池大概可以是200.(超过200需要更改系统相关参数)
应用程序连接数据库也有一个配置参数。(一般开发写在代码里面不会单独写个文件来做配置参数)
假设:微服务中配置数据连接maxActive=20,此时,启动10个微服务,那么最大就可以有200个连接, 而数据库默认151,就可能出现在高并发的时候,应用服务这边,可能会产生200个数据库连接,但是数据库却只能有151,服务的响应就会报 ERROR 1040: Too many connections

看到这个错误就要知道是数据库连接数不够。

如果HTTP响应直接是5xx系列错误,可能是数据库连接不够。

分析sql执行过程
explain select 语句
explain解析sql
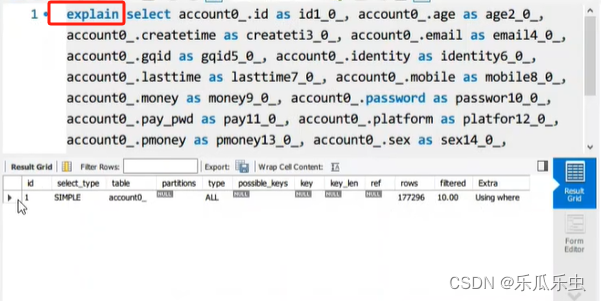
explain
select account0_.id as id1_0_, account0_.age as age2_0_, account0_.createtime as
createti3_0_, account0_.email as email4_0_, account0_.gqid as gqid5_0_,
account0_.identity as identity6_0_, account0_.lasttime as lasttime7_0_,
account0_.mobile as mobile8_0_, account0_.money as money9_0_, account0_.password
as passwor10_0_, account0_.pay_pwd as pay11_0_, account0_.platform as
platfor12_0_, account0_.pmoney as pmoney13_0_, account0_.sex as sex14_0_,
account0_.token as token15_0_, account0_.username as usernam16_0_
from kyj.cb_account account0_
where account0_.mobile='15503893978';通过explain,就能解析出一个sql要分几步来执行,每一步执行什么情况。
编号
- 步骤id从大到小执行
- id相同时,从上到下执行
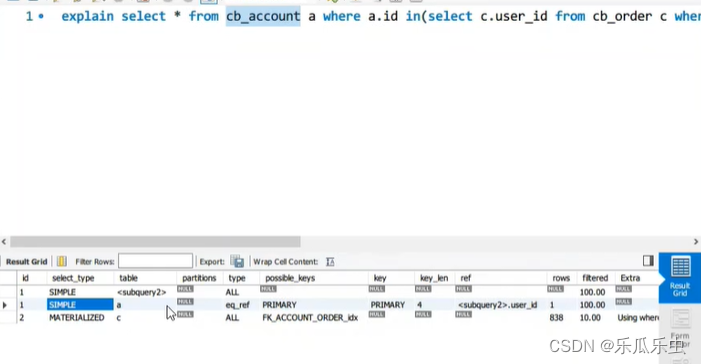
- select_type 查询类型
- table:执行的表
- type:类型-----这个信息,可以看出sql性能优劣
- possible_keys:可能会用到的索引
- key:真正用到索引
- key_len:索引的长度
- ref:表之间的关系
- rows:执行的行数量
- Extra:补充说明
在sql的性能分析的时候,主要看:type、rows、Extra
select_type查询类型
- SIMPLE:简单的SELECT,不使用union或子查询
- PRIMARY:查询中包含复杂的子查询,最外层的select被标记为
- PRIMARY UNION:union中第二个或后面的select语句
- DEPENDENT UNION: union中的第二个或后面的select语句,取决于外面的查询
- UNION RESULT: union的结果 SUBQUERY:子查询的第一个select
- DEPENDENT SUBQUERY:子查询中的第一个select,取决于外面的查询
- DERIVED:衍生查询,使用了临时表(select、from子句的子查询)
- UNCACHEABLE SUBQUERY :一个子查询的结果不能被缓存,必须重新评估外链接的第一行
type类型
- All:全表扫描Full table scan -----性能非常差
- index:遍历索引数据Full index scan ----使用率索引,但是是全索引扫描
- range:使用一个索引来检索给定范围的行---使用一定范围的索引
- ref:使用了索引列上值进行查询 eq_ref: 类似ref,只是使用的索引为唯一索引
- const、system:MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访 问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量,system是const类型 的特例,当查询的表只有一行的情况下,使用system
- NULL:MySQL在优化过程中分解语句,执行时甚至不用访问表或索引
性能效率:system > const > eq_ref > ref > range > index > all 左边效率高于右边
sql语句优化我们就是期望优化之后,type的类型,越往左边越好。尽可能的把sql的type类型,优化 到eq_ref 或ref。
如果看到sql的type为all,看rows行数量,行数量在几十、几百、几千,没有什么好优化,但如果是几十万、几百万甚至更大的时候,就必须优化
- rows行数量:执行这个sql要查找多少行数据
- 行数量越多,性能也就越差
- type:eq_ref rows:多;type:ref rows:少-------在这种情况下,ref+rows少的可能性能会更好一些
- Extra额外的信息
- Using where:显示的字段,不在索引(select的字段,有的不在索引中,要从源table表中查 询)
- Using index:使用了索引,不用回表查询,能够起到性能提升,
- Using temporary:使用了临时表,性能消耗比较大,常见于group by语句--------一定要进行性能优化
- Using filesort:使用文件排序,无法利用索引完成排序操作,性能消耗非常大,常见于order by 语句-----也是需要性能优化
- Using join buffer: mysql引擎使用了连接缓存
- Impossible where: where子句永远为false
- Select tables optimized away:仅通过使用索引,优化器可能仅从聚合函数结果中返回一行
- NULL
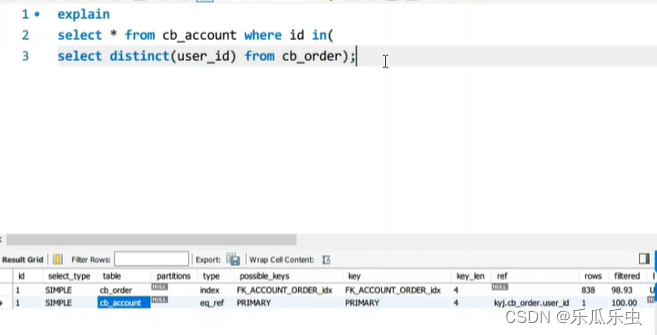
kyj项目 慢sql
select account0_.id as id1_0_, account0_.age as age2_0_, account0_.createtime as
createti3_0_, account0_.email as email4_0_, account0_.gqid as gqid5_0_,
account0_.identity as identity6_0_, account0_.lasttime as lasttime7_0_,
account0_.mobile as mobile8_0_, account0_.money as money9_0_, account0_.password
as passwor10_0_, account0_.pay_pwd as pay11_0_, account0_.platform as
platfor12_0_, account0_.pmoney as pmoney13_0_, account0_.sex as sex14_0_,
account0_.token as token15_0_, account0_.username as usernam16_0_ from
kyj.cb_account account0_ where account0_.mobile='15503893978';使用explain解析之后, type为All,rows在10w以上,extra中为using where
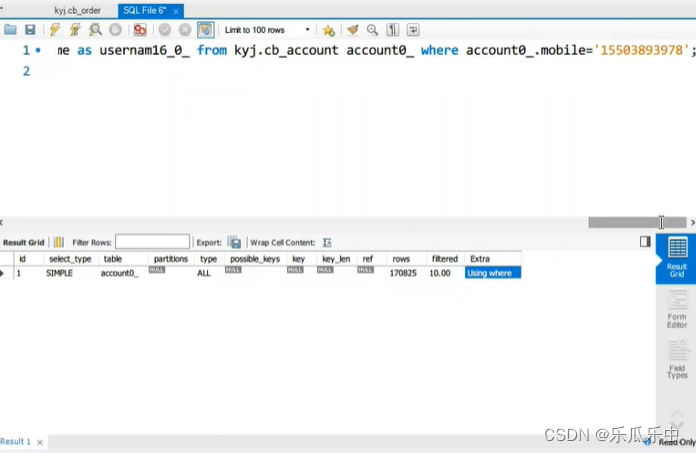
通过这些信息,我们就知道这个sql是全表扫描,没有使用索引;但是这个sql只有一个where条件 mobile字段,所以很明显就是把mobile字段添加到索引中即可。
实战
做性能测试
观察服务器资源使用情况: top命令
- load average 第1个值很大
- CPU的使用率接近100%,us态最高达到98%左右
- 进程列表中,CPU使用率最高的进程是:mysqld
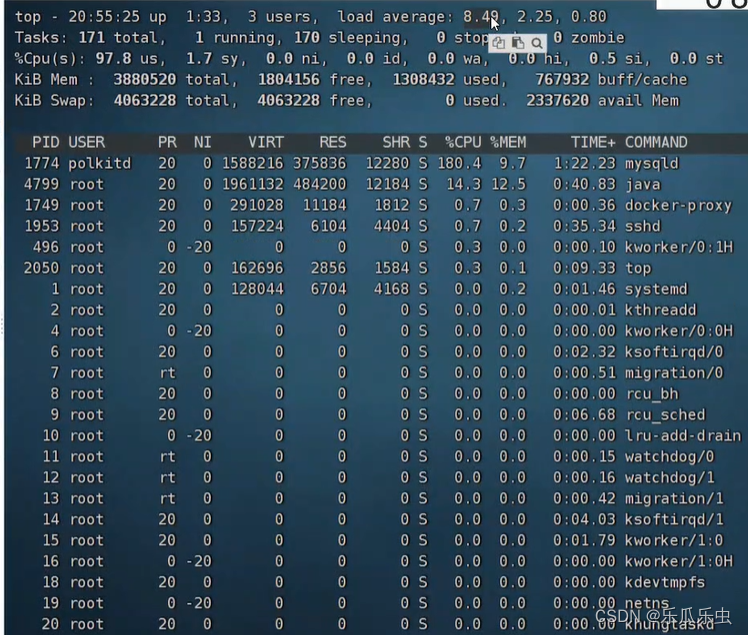
分析:
- 目前性能问题主要点在mysqld服务导致CPU使用率过高
- mysqld数据库导致CPU的用户态高-----sql的逻辑复杂
- 怀疑是慢sql,CPU的wa基本没有数据,磁盘性能应该没有问题
- 要开启慢sql日志,获取慢sql
- 找到数据库的配置文件:添加long_query_time=1
- 重启数据库 再执行: set global slow_query_log=ON
- 再执行性能测试
- 有慢sql,就会把sql语句写入到慢sql日志文件中
- 获取慢sql日志文件中的sql
- 使用explain解析sql执行过程
- 分析得到,sql没有使用索引
- 去cb_account表中,添加索引使用mobile字段
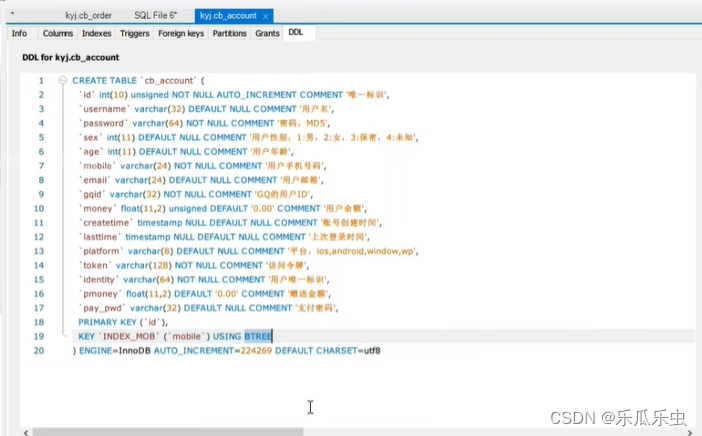
- 再次执行性能测试
注意:给一张已经有数据的表,新建索引是有一定时间的。
做完上面的性能调优之后,性能数据是有了很大提升,但是CPU的使用率依然很高,达到了97%以 上,此时java程序称为了主要的性能问题。
优化java程序
- 1、调整jvm内存大小(详看这里)

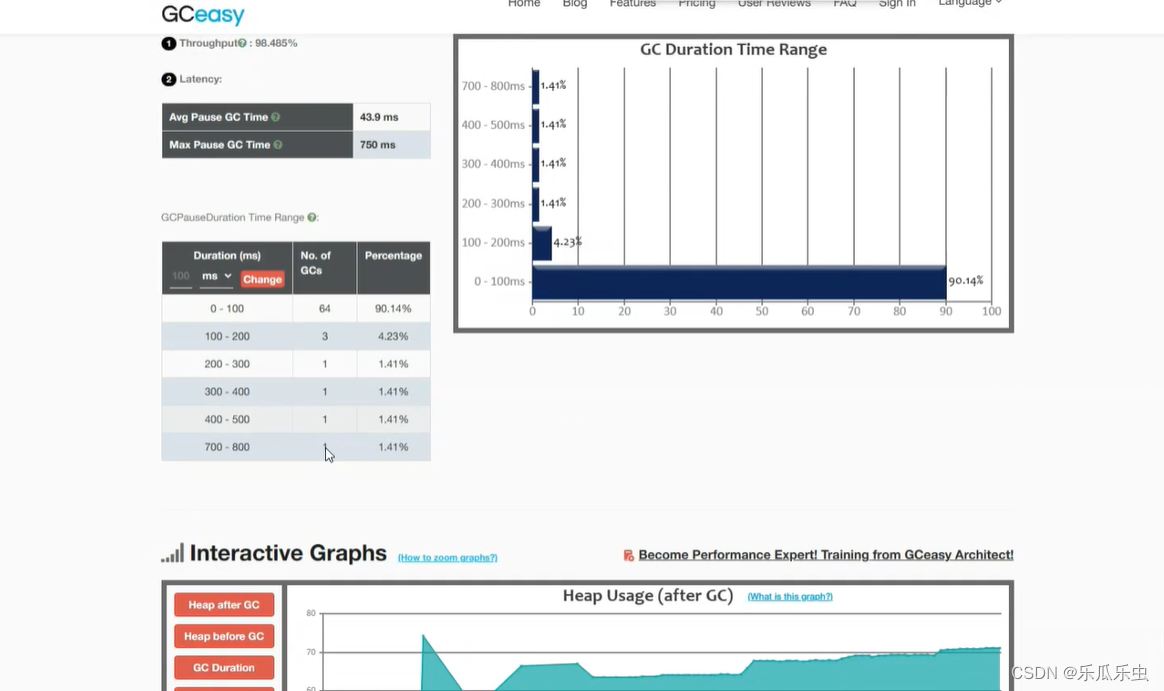
- 2、打印了gc日志,从gc日志分析看,有大量的YGC,暂时没有FGC,YGC次数比较多
- 怀疑: GC策略有问题,-----可以图调整GC策略 Universal JVM GC analyzer - Java Garbage collection log analysis made easy
- 3、CPU的us态稍微还高一定,怀疑可能有代码性能问题。
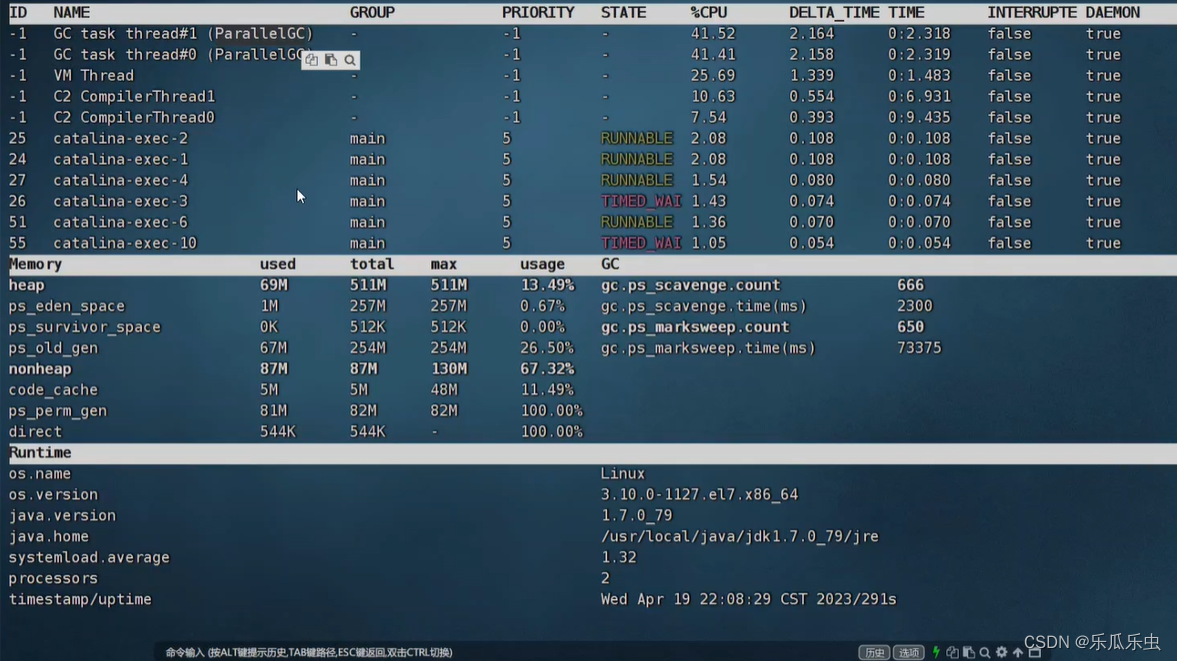
- arthas,去获取堆栈信息、去获取线程栈信息
- jmap
- top获取进程\线程id,然后,把线程id转换为16进制,然后再jstack打印线程栈信息
现在项目的情况,应该是已经内存溢出了。