找往期文章包括但不限于本期文章中不懂的知识点:
个人主页:我要学编程(ಥ_ಥ)-CSDN博客
所属专栏:数据结构
数据结构之单链表的相关知识点及应用-CSDN博客
下面题目基于上面这篇文章:
下面有任何不懂的地方欢迎在评论区留言或者私信我哦!
题目链接: 206.反转链表
题目描述:
给你单链表的头节点
head,请你反转链表,并返回反转后的链表。示例 1:
输入:head = [1,2,3,4,5] 输出:[5,4,3,2,1]示例 2:
输入:head = [1,2] 输出:[2,1]示例 3:
输入:head = [] 输出:[]
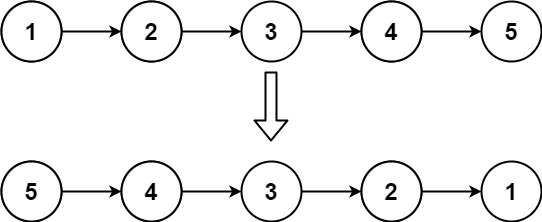

思路一:创建一个新的链表,把原链表中的节点头插到新链表中。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
typedef struct ListNode ListNode;//为了方便创建变量
//头插
void ListBuyNode(ListNode **newListHead, int val)
{
ListNode* newNode = (ListNode*)malloc(sizeof(ListNode));
if(newNode == NULL)
{
perror("malloc:");
exit(1);
}
newNode->val = val;
newNode->next = *newListHead;//新节点的next为前一个节点的地址
*newListHead = newNode;//更新 新链表的头节点
}
struct ListNode* reverseList(struct ListNode* head) {
ListNode *pcur = head;
ListNode *newlist = NULL;//创建新的链表(链表是由节点组成)
//当pcur指向为空时,就说明原链表中已经没有了节点
while(pcur)
{
ListBuyNode(&newlist, pcur->val);//头插会改变头节点,因此传地址
pcur = pcur->next;
}
return newlist;
}思路二:用三个指针遍历,直接完成原链表的反转。

typedef struct ListNode ListNode;
struct ListNode* reverseList(struct ListNode* head) {
//首先判断链表是否为空,如果是就直接返回,否则下面会有对空指针的解引用
if(head == NULL)
{
return head;
}
ListNode *prev = NULL;
ListNode *pcur = head;
ListNode *next = head->next;
while(pcur)
{
//把pcur的next指针指向改为prev
pcur->next = prev;
prev = pcur;
pcur = next;
if(next)//不为空,才能解引用
{
next = next->next;
}
}
return prev;//刚好指向最后一个节点
}题目链接:203.移除链表元素
题目描述:
给你一个链表的头节点
head和一个整数val,请你删除链表中所有满足Node.val == val的节点,并返回 新的头节点 。示例 1:
输入:head = [1,2,6,3,4,5,6], val = 6 输出:[1,2,3,4,5]示例 2:
输入:head = [], val = 1 输出:[]示例 3:
输入:head = [7,7,7,7], val = 7 输出:[]
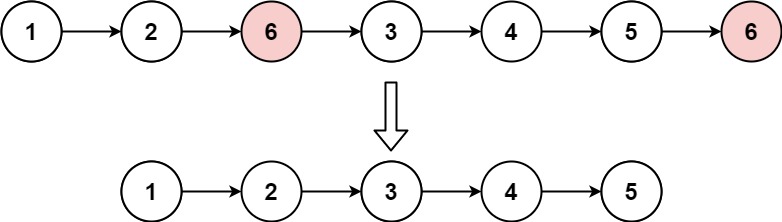
思路一:在原链表的基础上把值为val的节点全部删除。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
typedef struct ListNode ListNode;//为了方便创建变脸
void ListErase(ListNode **head, ListNode *pcur)
{
ListNode *phead = *head;
if(*head == pcur)//要删除的是头节点
{
*head = pcur->next;//头节点 改变为 头节点的下一个节点
}
else
{
while(phead->next != pcur)//找到pcur前一个节点
{
phead = phead->next;
}
//直接把pcur的后一个节点的地址给到pcur前一个节点的next指针
phead->next = pcur->next;
}
}
struct ListNode* removeElements(struct ListNode* head, int val) {
ListNode *pcur = head;
if(head == NULL)
{
return head;
}
while(pcur)
{
if(pcur->val == val)
{
//删除该节点
ListErase(&head, pcur);//可能是头节点,因此要传头指针的地址
}
pcur = pcur->next;
}
return head;
}注意:这里不需要我们自己主动的去释放被删除的空间,平台自己会判断。
思路二:创建一个新的链表,把值不为val的节点全部尾插到新的链表中。
typedef struct ListNode ListNode;
struct ListNode* removeElements(struct ListNode* head, int val) {
ListNode *newHead = NULL;//头指针
ListNode *newTail = NULL;//尾指针
ListNode *pcur = head;
while(pcur)
{
if(pcur->val != val)
{
//尾插该节点(这里只关注头指针和尾指针)
if(newHead == NULL)//链表为空
{
newHead = newTail = pcur;//把这个节点即作为头也作为尾
}
else//链表不为空
{
//尾节点的next指针指向新的节点
newTail->next = pcur;
//新的尾节点诞生了
newTail = pcur;
}
}
pcur = pcur->next;
}
//最后一个节点的next要指向NULL,但是得提前判断是否为链表是否为空
if(newTail)
{
newTail->next = NULL;
}
return newHead;
}题目链接:876.链表的中间节点
题目描述:
给你单链表的头结点
head,请你找出并返回链表的中间结点。如果有两个中间结点,则返回第二个中间结点。
示例 1:
输入:head = [1,2,3,4,5] 输出:[3,4,5] 解释:链表只有一个中间结点,值为 3 。示例 2:
输入:head = [1,2,3,4,5,6] 输出:[4,5,6] 解释:该链表有两个中间结点,值分别为 3 和 4 ,返回第二个结点。


有一种非常奇妙的方法:快慢指针。
原理:快指针——一次走两步;慢指针——一次走一步。所以就有了一个公式:2*慢指针 = 快指针,因此就得出了一个结论:当快指针走到结尾时,慢指针就走了快指针一半路程。也就是中间。
这个题目也就迎刃而解了。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
typedef struct ListNode ListNode;
struct ListNode* middleNode(struct ListNode* head) {
ListNode *slow = head;
ListNode *fast = head;
while(fast!=NULL && fast->next!=NULL)//注意这里
{
slow = slow->next;//走一步
fast = fast->next->next;//走两步
}
return slow;
}这里有一个要注意的点是:链表中元素个数为奇数或者偶数时,判断循环跳出的条件不一样。但链表的元素个数为奇数时,fast->next == NULL,slow就走到了链表的中间节点;链表元素个数为偶数时,fast == NULL时,slow就走到了链表的中间节点 。因此只要上面有一个条件满足时,就要跳出循环了。
题目链接:牛客网——环形链表的约瑟夫问题
介绍:
著名的Josephus问题
据说著名犹太 Josephus有过以下的故事:在罗马人占领乔塔帕特后,39 个犹太人与 Josephus及他的朋友躲到一个洞中,39个犹太人决定宁愿死也不要被人抓到,于是决定了一个自杀方式,41个人排成一个圆圈,由第1个人开始报数,每报数到第3人该人就必须自杀,然后再由下一个重新报数,直到所有人都自杀身亡为止。 然而Josephus 和他的朋友并不想遵从,Josephus要他的朋友先假装遵从,他将朋友与自己安排在 第16个与第31个位置,于是逃过了这场死亡游戏。
题目描述:
编号为 1 到 n 的 n 个人围成一圈。从编号为 1 的人开始报数,报到 m 的人离开。
下一个人继续从 1 开始报数。
n-1 轮结束以后,只剩下一个人,问最后留下的这个人编号是多少?
数据范围:1≤n,m≤10000
进阶:空间复杂度 O(1)O(1),时间复杂度 O(n)O(n)
示例1:
输入:
5,2返回值:
3说明:
开始5个人 1,2,3,4,5 ,从1开始报数,1->1,2->2编号为2的人离开 1,3,4,5,从3开始报数,3->1,4->2编号为4的人离开 1,3,5,从5开始报数,5->1,1->2编号为1的人离开 3,5,从3开始报数,3->1,5->2编号为5的人离开 最后留下人的编号是3示例2:
输入:
1,1返回值:
1
思路:首先,创建一个环形链表。创建一个单链表之后,让单链表的头尾相连就可以了。有了环形链表之后,就可以开始报数了,当报到了满足m时,就进行删除操作,不满足就继续往下走,直至整个链表中之有一个节点为止。
创建环形链表:因为这里没有现成的节点,所以我们就只能一个一个的创建。先写一个创建节点是函数。
//题目给了一个结构体,因此我们可以直接用
typedef struct ListNode ListNode;//重命名一下
//创建节点
ListNode* ListBuyNode(int n)//n是用来存放节点里储存的数据的
{
ListNode *node = (ListNode*)malloc(sizeof(sizeof(ListNode)));//创建节点
if (node == NULL)
{
perror("malloc:");
exit(1);
}
//初始化节点的内容
node->val = n;
node->next = NULL;
return node;
}当有一个一个的节点之后就可以开始创建一个链表了。
//创建带环链表
ListNode* createCircle(int n)
{
//创建节点(1~n)
//创建头节点
ListNode *head, *tail;
for(int i=1; i<=n; i++)
{
ListNode *ret = ListBuyNode(i);
if(ret->val == 1)//判断是否为头节点
{
head = ret;
tail = ret;
}
else //更新尾节点
{
tail->next = ret;
tail = tail->next;
}
}
//开始创建环(头尾相连)
tail->next = head;
return tail;//返回尾节点
}
这里我们为什么要返回尾节点呢?因为我们最后来报数时,是要通过两个指针来遍历,如果返回头节点的话,就找不到尾节点;而返回尾节点,还是可以找到头节点。
下面就是要开始报数了。
满足报到了m的情况:

不满足报到了m的情况:
int ysf(int n, int m ) {
//创建一个带环链表
ListNode *prev = createCircle(n);
//开始执行约瑟夫条件
ListNode *pcur = prev->next;//这里相当于已经开始报数了
int count = 1;//用于计数
//不管怎么样最终只会剩下一个
while(pcur->next != pcur)//当pcur->next指向自己时,就说明现在只剩下自己了
{
//当报数的结果满足m
if(count == m)
{
//删除节点,开始重新实现带环链表,并重新开始计数
prev->next = pcur->next;
free(pcur);
pcur = prev->next;
count = 1;
}
else
{
//持续计数
prev = pcur;
pcur = pcur->next;
count++;
}
}
int ret = pcur->val;
//动态开辟的空间要提前释放掉
free(pcur);
pcur = NULL;
return ret;
}完整代码(注释较少):
#include <stdlib.h>
typedef struct ListNode ListNode;
//创建节点
ListNode* ListBuyNode(int n)
{
ListNode *node = (ListNode*)malloc(sizeof(sizeof(ListNode)));//创建节点
if (node == NULL)
{
perror("malloc:");
exit(1);
}
//初始化节点的内容
node->val = n;
node->next = NULL;
return node;
}
//创建带环链表
ListNode* createCircle(int n)
{
//创建节点(1~n)
//创建头节点
ListNode *head, *tail;
for(int i=1; i<=n; i++)
{
ListNode *ret = ListBuyNode(i);
if(ret->val == 1)//判断是否为头节点
{
head = ret;
tail = ret;
}
else //更新尾节点
{
tail->next = ret;
tail = tail->next;
}
}
//开始创建环
tail->next = head;
return tail;
}
int ysf(int n, int m ) {
//创建一个带环链表
ListNode *prev = createCircle(n);
//开始执行约瑟夫条件
ListNode *pcur = prev->next;//这里相当于已经开始报数了
int count = 1;//用于计数
//不管怎么样最终只会剩下一个
while(pcur->next != pcur)
{
//当报数的结果满足m
if(count == m)
{
prev->next = pcur->next;
free(pcur);
pcur = prev->next;
count = 1;
}
else
{
prev = pcur;
pcur = pcur->next;
count++;
}
}
int ret = pcur->val;
free(pcur);
pcur = NULL;
return ret;
}题目链接:21.合并两个有序链表
题目描述:
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例 1:
输入:l1 = [1,2,4], l2 = [1,3,4] 输出:[1,1,2,3,4,4]示例 2:
输入:l1 = [], l2 = [] 输出:[]示例 3:
输入:l1 = [], l2 = [0] 输出:[0]
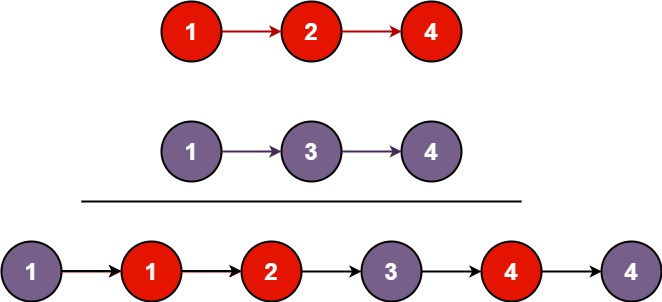
思路:创建一个新的链表,比较两个链表中节点的数据的大小,分别尾插到这个新链表中。
typedef struct ListNode ListNode;
void ListPopBack(ListNode **newHead, ListNode **newTail, ListNode *list)
{
if(*newHead == NULL)//没有节点
{
*newHead = list;
*newTail = list;
}
else
{
(*newTail)->next = list;
*newTail = (*newTail)->next;
}
}
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {
//当两个链表都为空时,也就代表着list1也为空,可以返回list2
//当list1为空时,就返回list2
if(list1 == NULL)
{
return list2;
}
//当list2为空时,就返回list1
if(list2 == NULL)
{
return list1;
}
//创建一个新的链表
ListNode *newHead = NULL;
ListNode *newTail = NULL;
//开始比较
while(list1 && list2)//当链表中还有节点时
{
if(list1->val > list2->val)
{
ListPopBack(&newHead, &newTail, list2);//尾插,注意是&
list2 = list2->next;
}
else
{
ListPopBack(&newHead, &newTail, list1);
list1 = list1->next;
}
}
//还有一个有剩余
if(list1)//l1剩余,因为链表已经是有序的了,因此就可以直接尾插
{
newTail->next = list1;
}
if(list2)//l2剩余
{
newTail->next = list2;
}
return newHead;
}优化:这里在创建链表时,可以创建一个带头的链表,这样就不需要每次判断链表是否为空。
创建带头链表:
//创建一个带头链表
ListNode *head = (ListNode*)malloc(sizeof(ListNode));
ListNode *tail = head;
......
......
......
//
//在返回时要返回头节点的next指针,返回前要把动态开辟的内存释放掉
ListNode *ret = head->next;
free(head);
head = NULL;
return ret;题目链接:面试题 02.04.分割链表
题目描述:
给你一个链表的头节点
head和一个特定值x,请你对链表进行分隔,使得所有 小于x的节点都出现在 大于或等于x的节点之前。你不需要 保留 每个分区中各节点的初始相对位置。
示例 1:
输入:head = [1,4,3,2,5,2], x = 3 输出:[1,2,2,4,3,5]示例 2:
输入:head = [2,1], x = 2 输出:[1,2]

思路一:在原链表的基础上进行修改,通过双指针遍历,left指针找节点数据大于x的值,right指针找节点数据小于x的,然后再进行交换,直至right == left 停止循环。
这个思路写出来的代码非常复杂。
思路二:在原链表的基础上进行修改,通过一个指针进行遍历,节点数据大于x的就尾插到原链表中,直至这个指针找到原链表的尾节点。
这个代码也比较复杂。
思路三:创建一个新的链表,通过一个指针遍历原链表, 节点数据大于x的就尾插到新链表,节点数据小于x的就头插到新链表。
这个代码就比较好办,但还不是最简方法。
最简思路: 创建两个带头链表,根据题目给出的x,来遍历判断大小,分别存入大链表和小链表中,最后把小链表尾节点的next指针指向大链表的头指针,这样就完成了链表的分割。
typedef struct ListNode ListNode;
void ListPopBack(ListNode **Tail, ListNode *pcur)
{
//因为我们创建的是带头链表,因此不需要判断是否为空链表
(*Tail)->next = pcur;
(*Tail) = (*Tail)->next;
}
struct ListNode* partition(struct ListNode* head, int x){
//如果节点个数小于等于1个,就不需要分割了
if(head == NULL || head->next == NULL)
{
return head;
}
//创建两个带头链表
ListNode *lessHead = (ListNode*)malloc(sizeof(ListNode));
ListNode *lessTail = lessHead;
ListNode *greatHead = (ListNode*)malloc(sizeof(ListNode));
ListNode *greatTail = greatHead;
//开始判断大小,分割链表
ListNode *pcur = head;
while(pcur)
{
if(pcur->val < x)
{
//尾插到小链表中
ListPopBack(&lessTail, pcur);
}
else
{
//尾插到大链表中
ListPopBack(&greatTail, pcur);
}
pcur = pcur->next;
}
//开始链接大小链表
lessTail->next = greatHead->next;
//要有停止打印的节点,否则就会陷入死循环
greatTail->next = NULL;
//不能返回哨兵位,一个返回哨兵位的next指针
return lessHead->next;
}但是上面的代码还是会报错。

因为当输入的数据一致时,大链表没有效节点(哨兵位除外),而我们会对大链表解引用。
因此我们就需要判断大链表是否有有效节点,怎么判断呢?只需要把哨兵位的next指针赋值为NULL,再去判断这个位置是否为NULL。如果是就说明没有有效数据,就直接返回lessHead->next就行了;反之,就需要判断。
typedef struct ListNode ListNode;
void ListPopBack(ListNode **Tail, ListNode *pcur)
{
//因为我们创建的是带头链表,因此不需要判断是否为空链表
(*Tail)->next = pcur;
(*Tail) = (*Tail)->next;
}
struct ListNode* partition(struct ListNode* head, int x){
//如果节点个数小于等于1个,就不需要分割了
if(head == NULL || head->next == NULL)
{
return head;
}
//创建两个带头链表
ListNode *lessHead = (ListNode*)malloc(sizeof(ListNode));
ListNode *lessTail = lessHead;
ListNode *greatHead = (ListNode*)malloc(sizeof(ListNode));
ListNode *greatTail = greatHead;
greatHead->next = NULL;
//开始判断大小,分割链表
ListNode *pcur = head;
while(pcur)
{
if(pcur->val < x)
{
//尾插到小链表中
ListPopBack(&lessTail, pcur);
}
else
{
//尾插到大链表中
ListPopBack(&greatTail, pcur);
}
pcur = pcur->next;
}
//开始链接链表之前,先判断一下
if(greatHead->next == NULL)
{
return lessHead->next;
}
lessTail->next = greatHead->next;
//要有停止打印的节点,否则就会陷入死循环
greatTail->next = NULL;
//不能返回哨兵位,一个返回哨兵位的next指针
return lessHead->next;
}好啦!本期有关单链表的刷题之旅就到此结束啦!我们下一期再一起学习吧!