视图 ( Views ) 是Django的MTV架构模式的V部分 , 主要负责处理用户请求和生成相应的响应内容 , 然后在页面或其他类型文档中显示 .
也可以理解为视图是MVC架构里面的C部分 ( 控制器 ) , 主要处理功能和业务上的逻辑 .
我们习惯使用视图函数处理HTTP请求 , 即在视图里定义def函数 , 这种方式称为FBV ( Function Base Views ) .
网站的运行原理是遵从HTTP协议 , 分为HTTP请求和HTTP响应 .
HTTP响应方式也称为HTTP状态码 , 分为 5 种状态 : 消息 , 成功 , 重定向 , 请求错误和服务器错误 .
若以使用频率划分 , 则HTTP状态码可分为 : 成功 , 重定向和异常响应 ( 请求错误和服务器错误 ) .
视图函数是通过return方式返回响应内容 , 然后生成相应的网页内容呈现在浏览器上 .
return是Python的内置语法 , 用于设置函数的返回值 , 若要设置不同的响应方式 , 则需要使用Django内置的响应类 , 如表 4 - 1 所示 .
响应类型 状态码 说明 HttpResponse('Hello world')200请求已成功被服务器接收, 响应内容为 "Hello world"HttpResponseRedirect('/')302重定向到首页地址, 状态码为 302 (临时重定向)HttpResponsePermanentRedirect('/')301永久重定向到首页地址, 状态码为 301 (永久重定向)HttpResponseBadRequest('400')400请求错误, 状态码为 400 (客户端错误)HttpResponseNotFound('404')404网页不存在或网页的 URL 失效, 状态码为 404 (未找到)HttpResponseForbidden('403')403没有访问权限,状态码为 403 (禁止访问)HttpResponseNotAllowed('405')405不允许使用该请求方式,状态码为 405 (方法不允许)HttpResponseServerError('500')500服务器内容错误,状态码为 500 (服务器内部错误)JsonResponse({'foo': 'bar'})200默认状态码为 200, 响应内容为 JSON 数据 ({'foo': 'bar'})StreamingHttpResponse()200响应内容以流式输出, 默认状态码为 200 (成功)
表 4 - 1 响应类
不同的响应方式代表不同的HTTP状态码 ,
其核心作用是Web Server服务器用来告诉浏览器当前的网页请求发生了什么事 , 或者当前Web服务器的响应状态 .
上述的响应类主要来自于模块django . http , 该模块是实现响应功能的核心 .
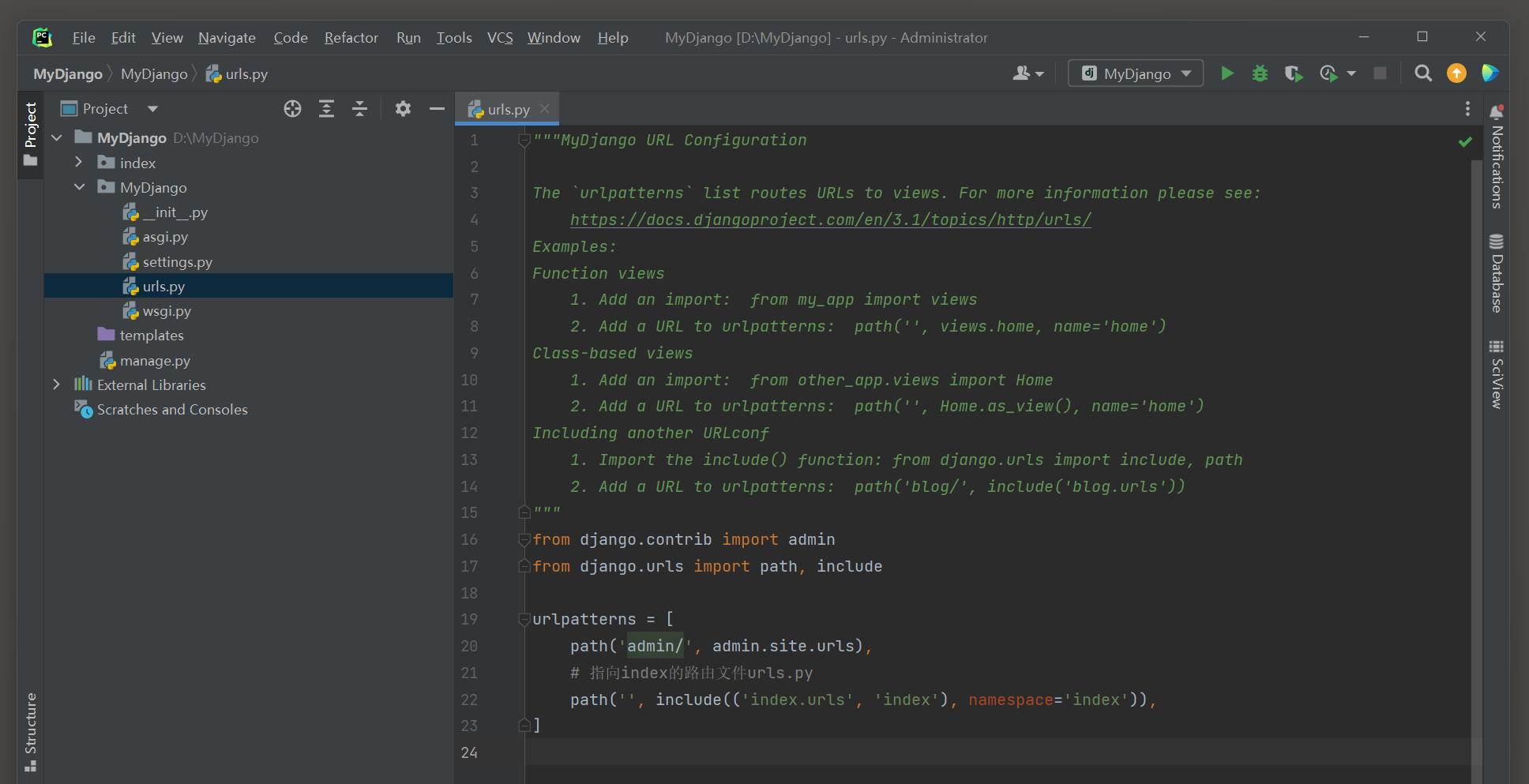
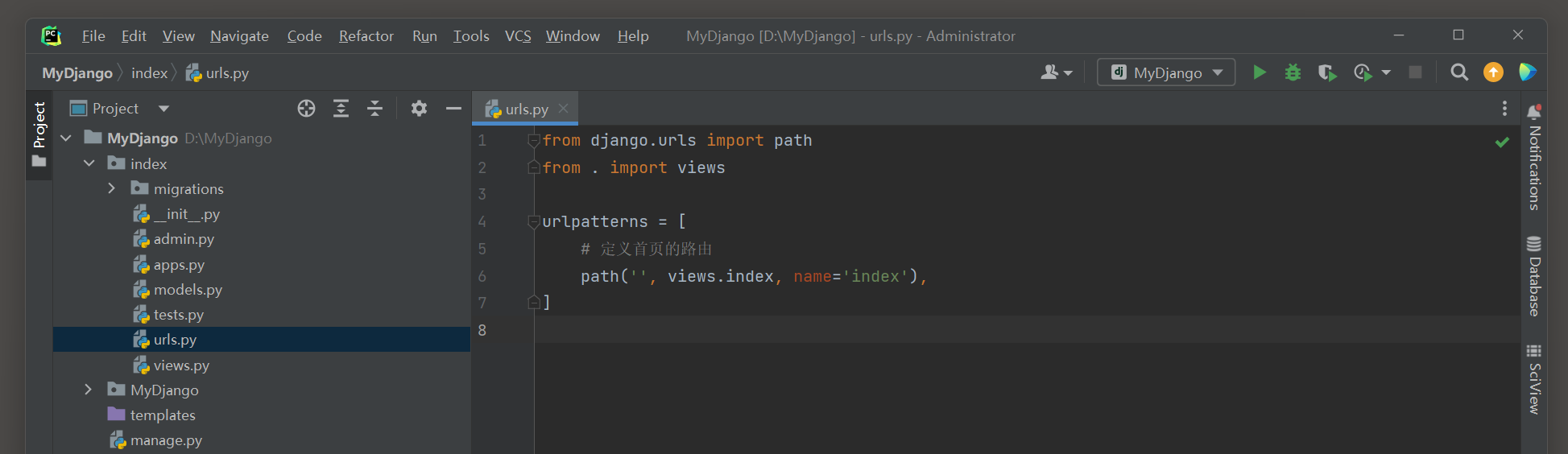
以HttpResponse为例 , 在MyDjango项目 ( 新建MyDjango项目 ) 的index文件夹的urls . py和views . py中编写功能代码 :
from django. contrib import admin
from django. urls import path, include
urlpatterns = [
path( 'admin/' , admin. site. urls) ,
path( '' , include( ( 'index.urls' , 'index' ) , namespace= 'index' ) ) ,
]
from django. urls import path
from . import views
urlpatterns = [
path( '' , views. index, name= 'index' ) ,
]
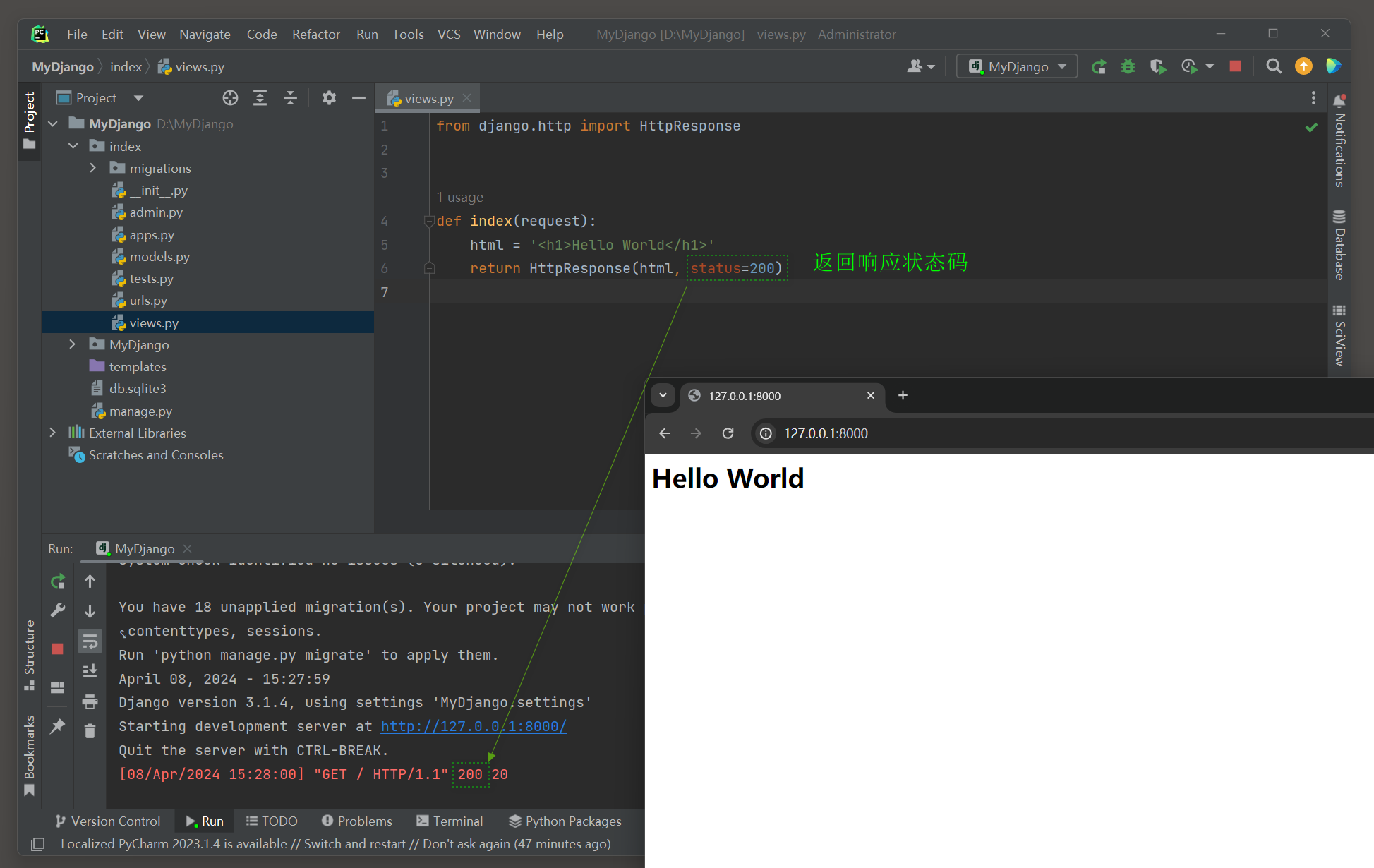
from django. http import HttpResponse
def index ( request) :
html = '<h1>Hello World</h1>'
return HttpResponse( html, status= 200 )
视图函数index使用响应类HttpResponse实现响应过程 .
从HttpResponse的参数可知 , 第一个参数是响应内容 , 一般是网页内容或JSON数据 ,
网页内容是以HTML语言为主的 , JSON数据用于生成API接口数据 .
第二个参数用于设置HTTP状态码 , 它支持HTTP所有的状态码 .
从源码角度分析 , 打开响应类HttpResponse的源码文件 ,
发现表 4 - 1 中的响应类都是在HttpResponse的基础上实现的 , 只不过它们的HTTP状态码有所不同 , 如图 4 - 1 所示 .
图 4 - 1 响应函数
从HttpResponse的使用过程可知 , 如果要生成网页内容 , 就需要将HTML语言以字符串的形式表示 ,
如果网页内容过大 , 就会增加视图函数的代码量 , 同时也没有体现模板的作用 .
因此 , Django在此基础上进行了封装处理 , 定义了函数render , render_to_response和redirect .
render和render_to_response实现的功能是一致的 .
render_to_response自 2.0 版本以来已开始被弃用 , 但并不代表在 2.0 以上版本无法使用 , 只是大部分开发者都使用render .
因此 , 本书只对render进行讲解 . render的语法如下 :
render ( request , template_name , context = None , content_type = None , status = None , using = None )
render的参数request和template_name是必需参数 , 其余的参数是可选参数 .
各个参数说明如下 :
● request : 浏览器向服务器发送的请求对象 , 包含用户信息 , 请求内容和请求方式等 .
● template_name : 设置模板文件名 , 用于生成网页内容 .
● context : 对模板上下文 ( 模板变量 ) 赋值 , 以字典格式表示 , 默认情况下是一个空字典 .
● content_type : 响应内容的数据格式 , 一般情况下使用默认值即可 .
● status : HTTP状态码 , 默认为 200.
● using : 设置模板引擎 , 用于解析模板文件 , 生成网页内容 .
为了更好地说明render的使用方法 , 我们通过简单的例子来加以说明 .
以MyDjango为例 , 在index的views . py和templates的index . html中编写以下代码 :
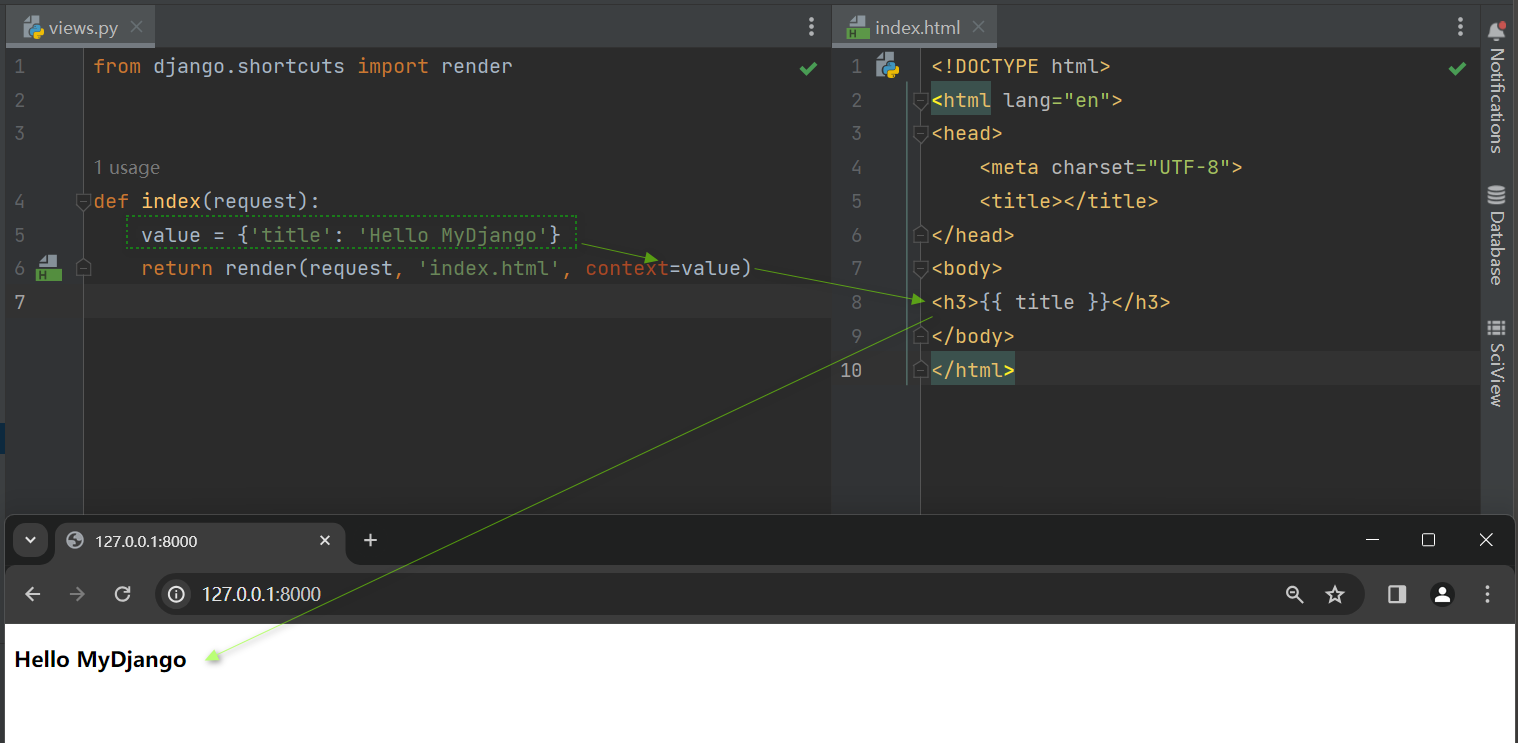
from django. shortcuts import render
def index ( request) :
value = { 'title' : 'Hello MyDjango' }
return render( request, 'index.html' , context= value)
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> < h3> </ h3> </ body> </ html> 视图函数index定义的变量value作为render的参数context ,
而模板index . html里通过使用模板上下文 ( 模板变量 ) { { title } } 来获取变量value的数据 ,
上下文的命名必须与变量value的数据命名 ( 字典的key ) 相同 ,
这样Django内置的模板引擎才能将参数context ( 变量value ) 的数据与模板上下文进行配对 ,
从而将参数context的数据转换成网页内容 .
运行MyDjango项目 , 在浏览器上访问 127.0 .0 .1 : 8000 即可看到网页信息 , 如图 4 - 2 所示 .
图 4 - 2 运行结果
在实际开发过程中 , 如果视图传递的变量过多 , 在设置参数context时就显得非常冗余 , 而且不利于日后的维护和更新 .
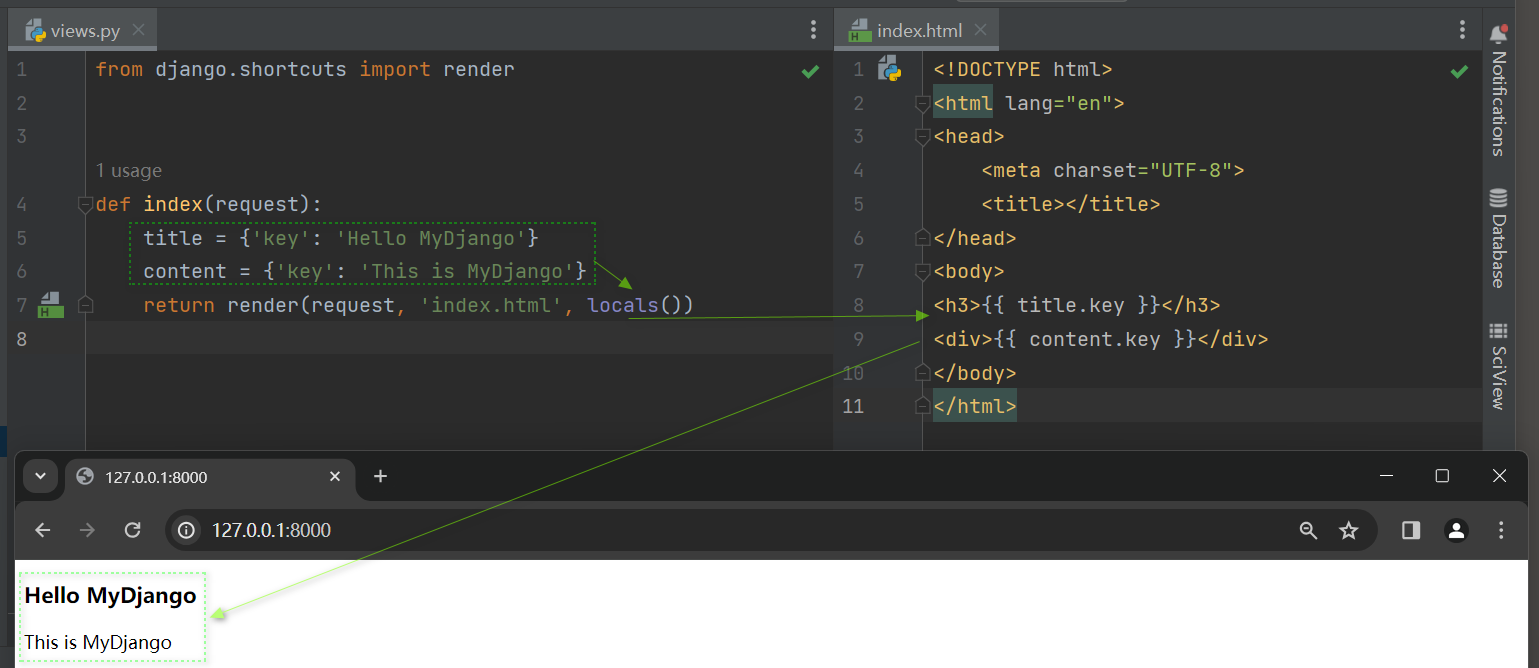
因此 , 可以使用Python内置语法locals ( ) 取代参数context , 在index的views . py和templates的index . html中重新编写以下代码 :
def index ( request) :
title = { 'key' : 'Hello MyDjango' }
content = { 'key' : 'This is MyDjango' }
return render( request, 'index.html' , locals ( ) )
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> < h3> </ h3> < div> </ div> </ body> </ html> 视图函数index定义变量title和content , 在使用render的时候 , 只需设置请求对象request , 模板文件名和locals ( ) 即可完成响应过程 .
locals ( ) 会自动将变量title和content分别传入模板文件 , 并由模板引擎找到与之匹配的上下文 .
也就是说 , 在视图函数中所定义的变量名一定要与模板文件的上下文 ( 变量名 ) 相同才能生效。
视图定义变量的数据格式不同 , 在模板文件里的使用方式也各不相同 .
有关模板上下文的使用方式会在第 6 章详细讲述 .
运行MyDjango项目 , 上述代码的运行结果如图 4 - 3 所示 .
图 4 - 3 运行结果
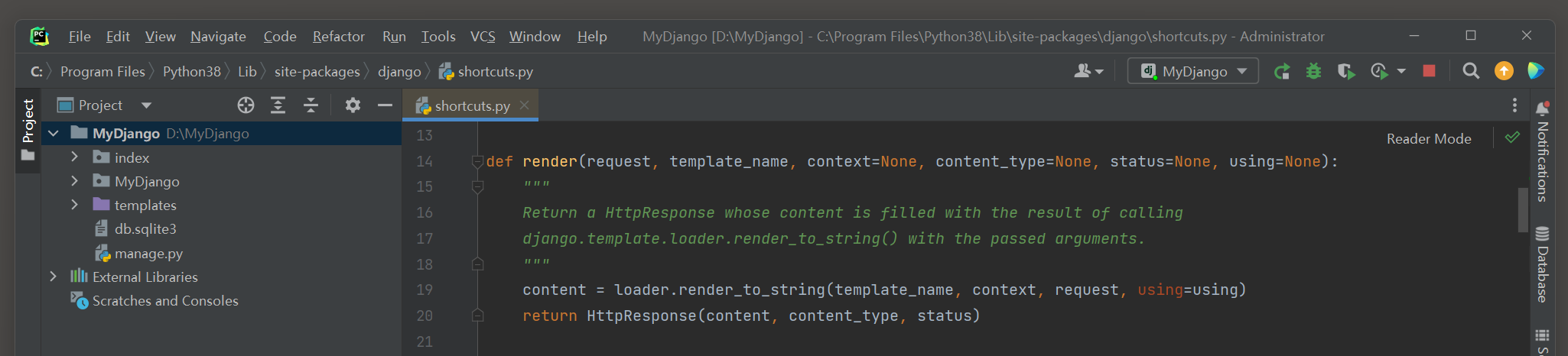
掌握了render的使用方法后 , 为了进一步了解其原理 ,
在PyCharm里查看render的源码信息 , 按键盘上的Ctrl键并单击函数render即可打开该函数的源码文件 , 如图 4 - 4 所示 .
图 4 - 4 render的源码文件
函数render的返回值调用响应类HttpResponse来生成具体的响应内容 , 这说明响应类HttpResponse是Django在响应过程中核心的功能类 .
结合render源码进一步阐述render读取模板index . html的运行过程 :
( 1 ) 使用loader . render_to_string方法读取模板文件内容 .
( 2 ) 由于模板文件设有模板上下文,因此模板文件解析网页内容的过程需要由模板引擎using实现。
( 3 ) 解析模板文件的过程中 , loader . render_to_string的参数context给模板语法的变量提供具体的数据内容 ,
若模板上下文在该参数里不存在 , 则对应的网页内容为空 .
( 4 ) 调用响应类HttpResponse , 并将变量content ( 模板文件的解析结果 ) ,
变量content_type ( 响应内容的数据格式 ) 和变量status ( HTTP状态码 ) 以参数形式传入HttpResponse , 从而完成响应过程 .
综上所述 , 我们介绍了Django的响应类 , 如HttpResponse , HttpResponseRedirect和HttpResponseNotFound等 ,
其中最为核心的响应类是HttpResponse , 它是所有响应类的基础 .
在此基础上 , Django还进一步封装了响应函数render , 该函数能直接读取模板文件 , 并且能设置多种响应方式 ( 设置不同的HTTP状态码 ) .
Django的重定向方式已在 3.3 .3 小节简单介绍过了 ,
本小节将深入讲述Django的重定向类HttpResponseRedirect , HttpResponsePermanentRedirect以及重定向函数redirect .
重定向的状态码分为 301 和 302 , 前者是永久性跳转的 , 后者是临时跳转的 , 两者的区别在于搜索引擎的网页抓取 .
301 重定向是永久的重定向 , 搜索引擎在抓取新内容的同时会将旧的网址替换为重定向之后的网址 .
302 跳转是暂时的跳转 , 搜索引擎会抓取新内容而保留旧的网址 .
因为服务器返回 302 代码 , 所以搜索引擎认为新的网址只是暂时的 .
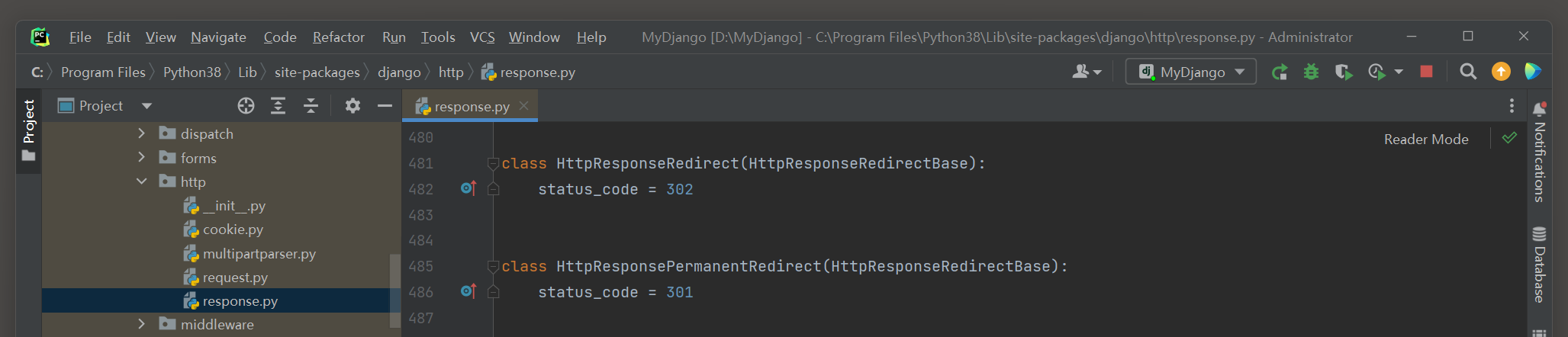
重定向类HttpResponseRedirect和HttpResponsePermanentRedirect分别代表HTTP状态码 302 和 301 ,
在PyCharm里查看源码 , 发现两者都继承HttpResponseRedirectBase类 , 如图 4 - 5 所示 .
图 4 - 5 源码信息
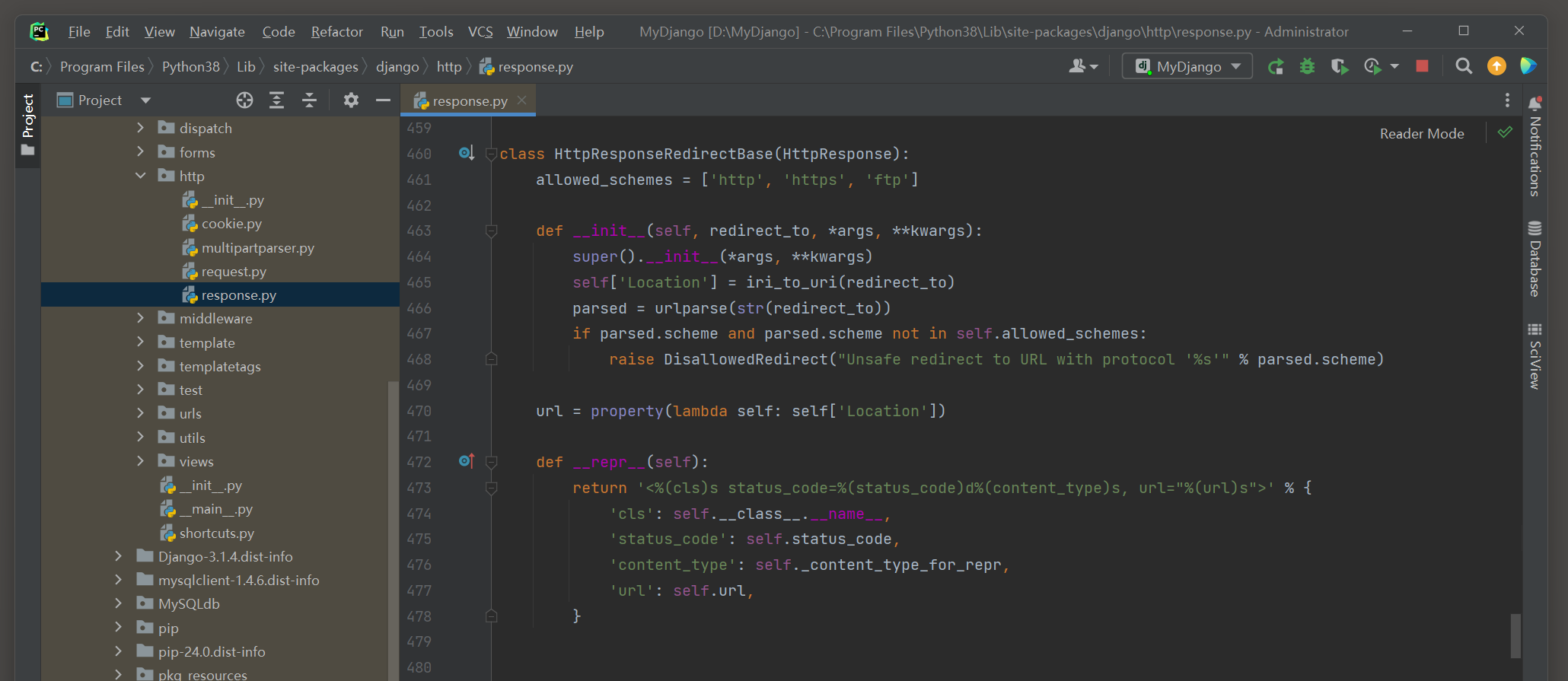
在图 4 - 5 的文件里可以找到类HttpResponseRedirectBase的定义过程 ,
发现该类继承了响应类HttpResponse , 并重写__init__ ( ) 和__repr__ ( ) .
也就是说 , Django的重定向是在响应类HttpResponse的基础上进行功能重写的 , 从而实现整个重定向过程 , 如图 4 - 6 所示 .
图 4 - 6 HttpResponseRedirectBase类
HttpResponseRedirect或HttpResponsePermanentRedirect的使用只需传入路由地址即可 ,
两者只支持路由地址而不支持路由命名的传入 .
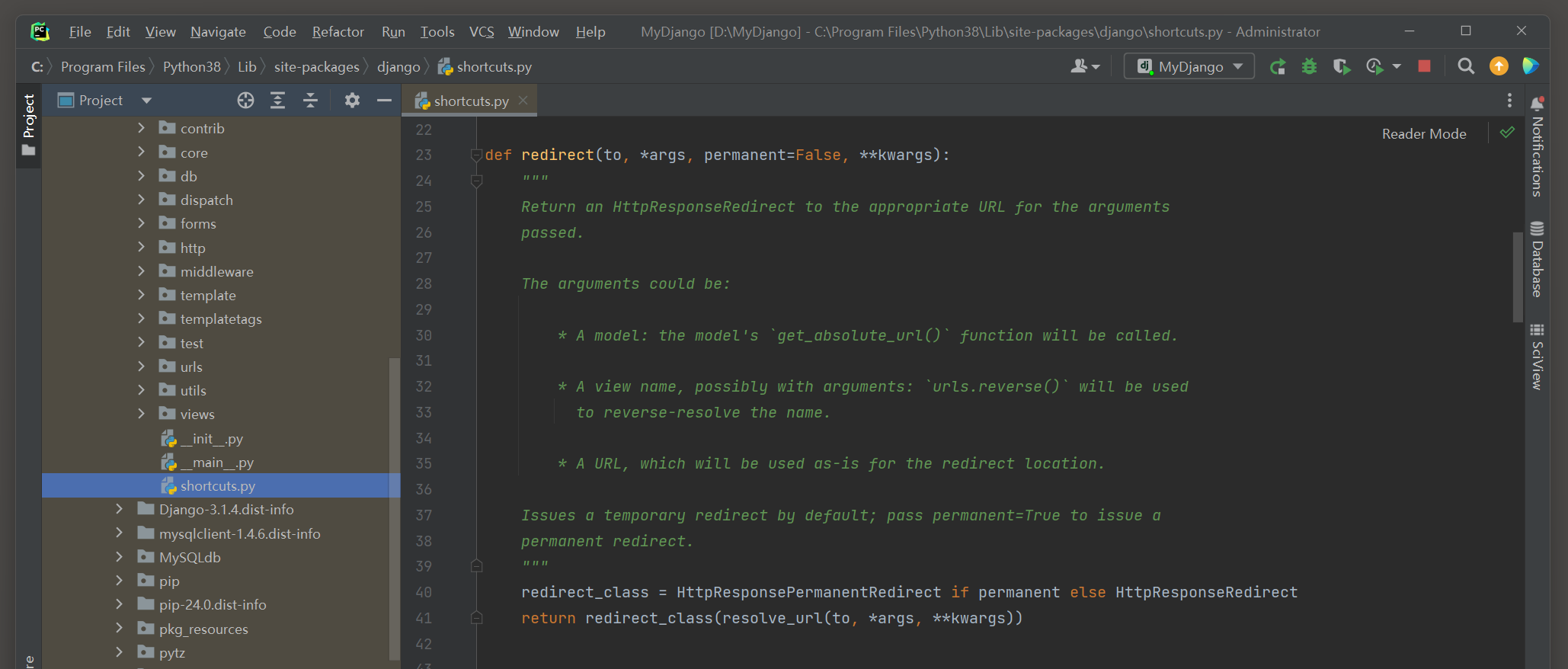
为了进一步完善功能 , Django在此基础上定义了重定向函数redirect ,
该函数支持路由地址或路由命名的传入 , 并且能通过函数参数来设置重定向的状态码 .
在PyCharm里查看函数redirect的源码信息 , 如图 4 - 7 所示 .
图 4 - 7 函数redirect的源码信息
从函数redirect的定义过程可以看出 , 该函数的运行原理如下 :
● 判断参数permanent的真假性来选择重定向的函数 .
若参数permanent为True , 则调用HttpResponsePermanentRedirect来完成重定向过程 ;
若为False , 则调用HttpResponseRedirect .
● 由于HttpResponseRedirect和HttpResponsePermanentRedirect只支持路由地址的传入 ,
因此函数redirect调用resolve_url方法对参数to进行判断 .
若参数to是路由地址 , 则直接将参数to的参数值返回 ;
若参数to是路由命名 , 则使用reverse函数转换路由地址 ;
若参数to是模型对象 , 则将模型转换成相应的路由地址 ( 这种方法的使用频率相对较低 ) .
函数redirect是将HttpResponseRedirect和HttpResponsePermanentRedirect的功能进行完善和组合 .
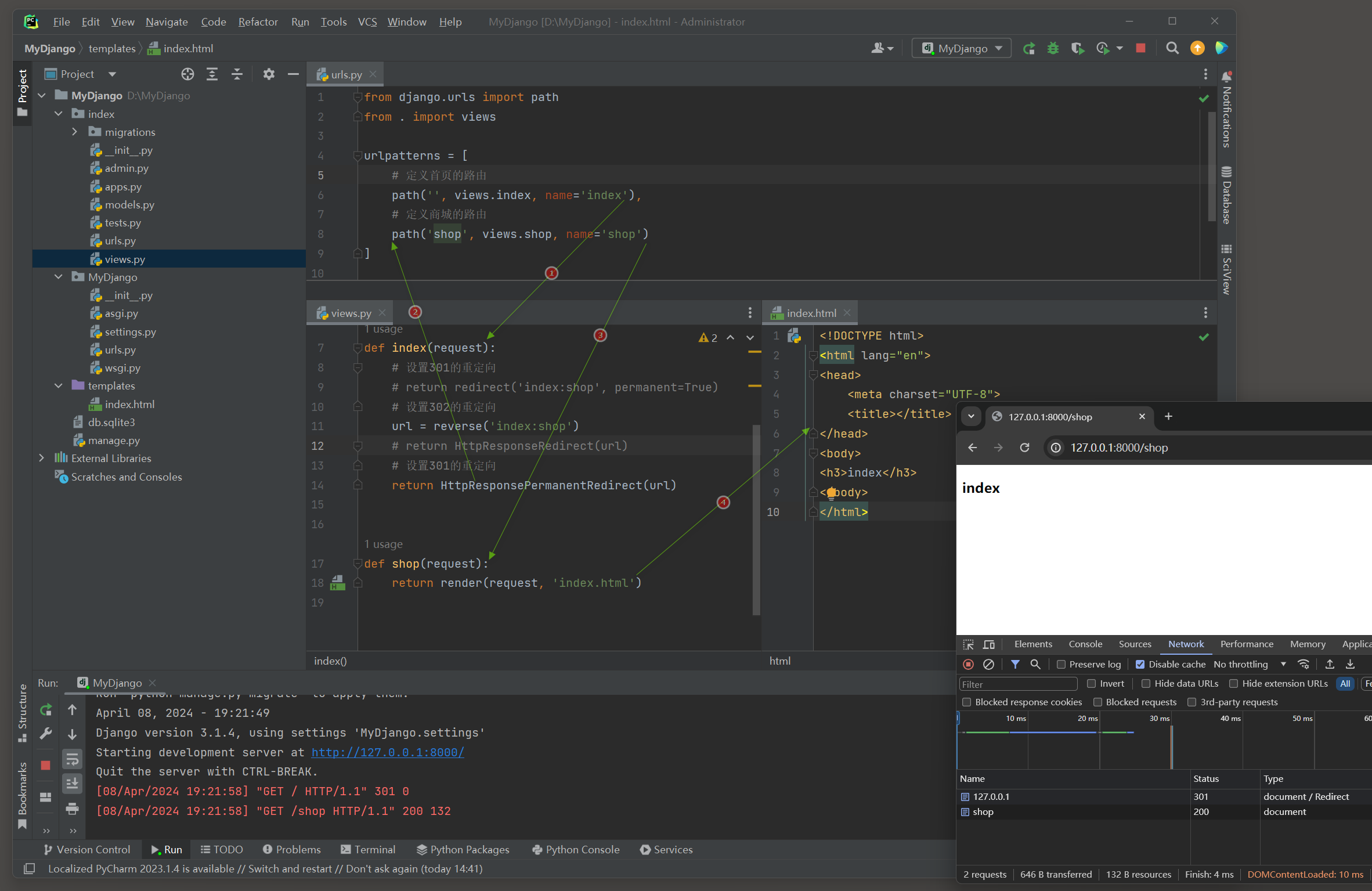
我们在MyDjango项目里讲述这三者的使用方法 , 在index文件夹的urls . py中定义路由信息 , 在views . py中定义相关的视图函数 , 代码如下 :
from django. urls import path
from . import views
urlpatterns = [
path( '' , views. index, name= 'index' ) ,
path( 'shop' , views. shop, name= 'shop' )
]
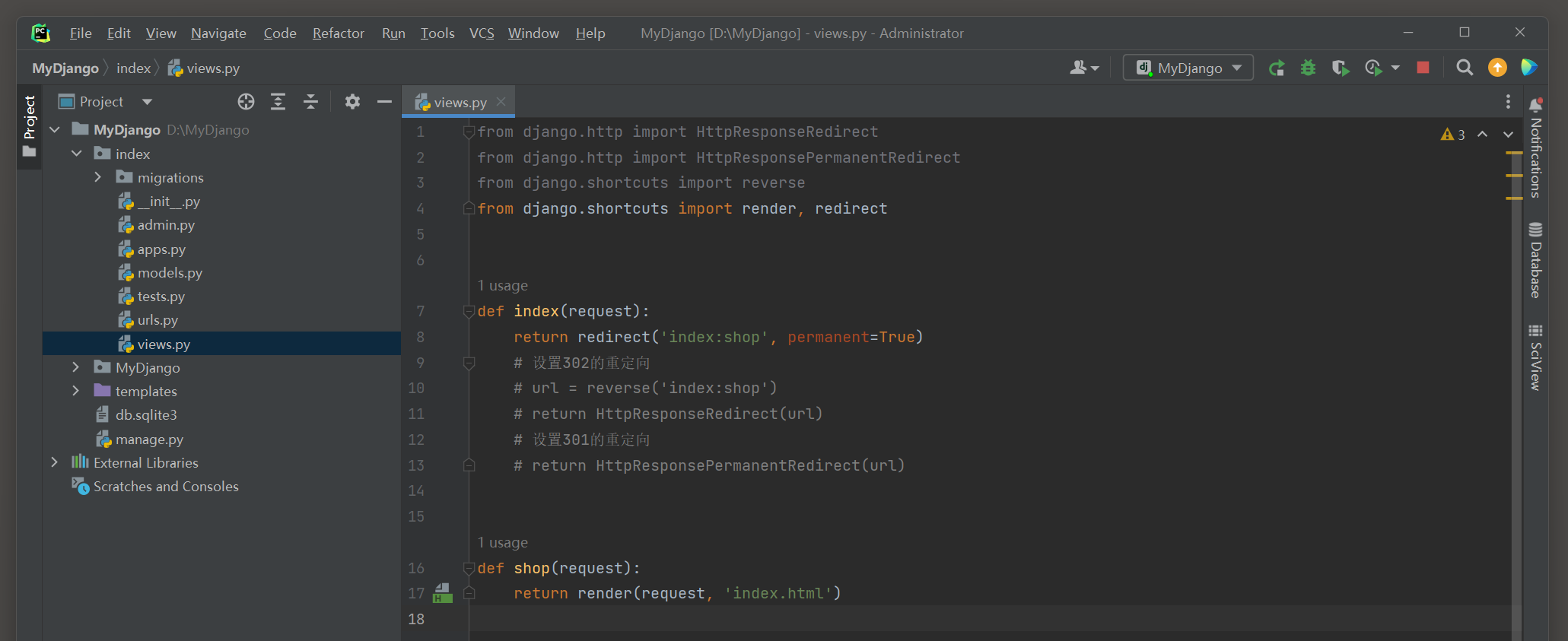
from django. http import HttpResponseRedirect
from django. http import HttpResponsePermanentRedirect
from django. shortcuts import reverse
from django. shortcuts import render, redirect
def index ( request) :
return redirect( 'index:shop' , permanent= True )
def shop ( request) :
return render( request, 'index.html' )
代码解释 :
redirect ( 'index:shop' , permanent = True ) ,
redirect调用resolve_url方法对参数to进行判断若参数to是路由命名 , 则使用reverse函数转换路由地址 ;
HttpResponseRedirect 和 HttpResponsePermanentRedirect 只能识别路由地址 ,
作者写了一个路由命名 ( 'index:shop' ) , 然后通过reverse反向解析成url地址 .
视图函数index的响应函数redirect将参数permanent设置为True , 并跳转到路由命名为shop的网页 ;
若使用HttpResponseRedirect或HttpResponsePermanentRedirect , 则需要使用reverse函数将路由命名转换成路由地址 .
从三者的使用方式来说 , 函数redirect更为便捷 , 更符合Python的哲学思想 .
修改index . html文件 , 代码如下 :
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> < h3> </ h3> </ body> </ html>
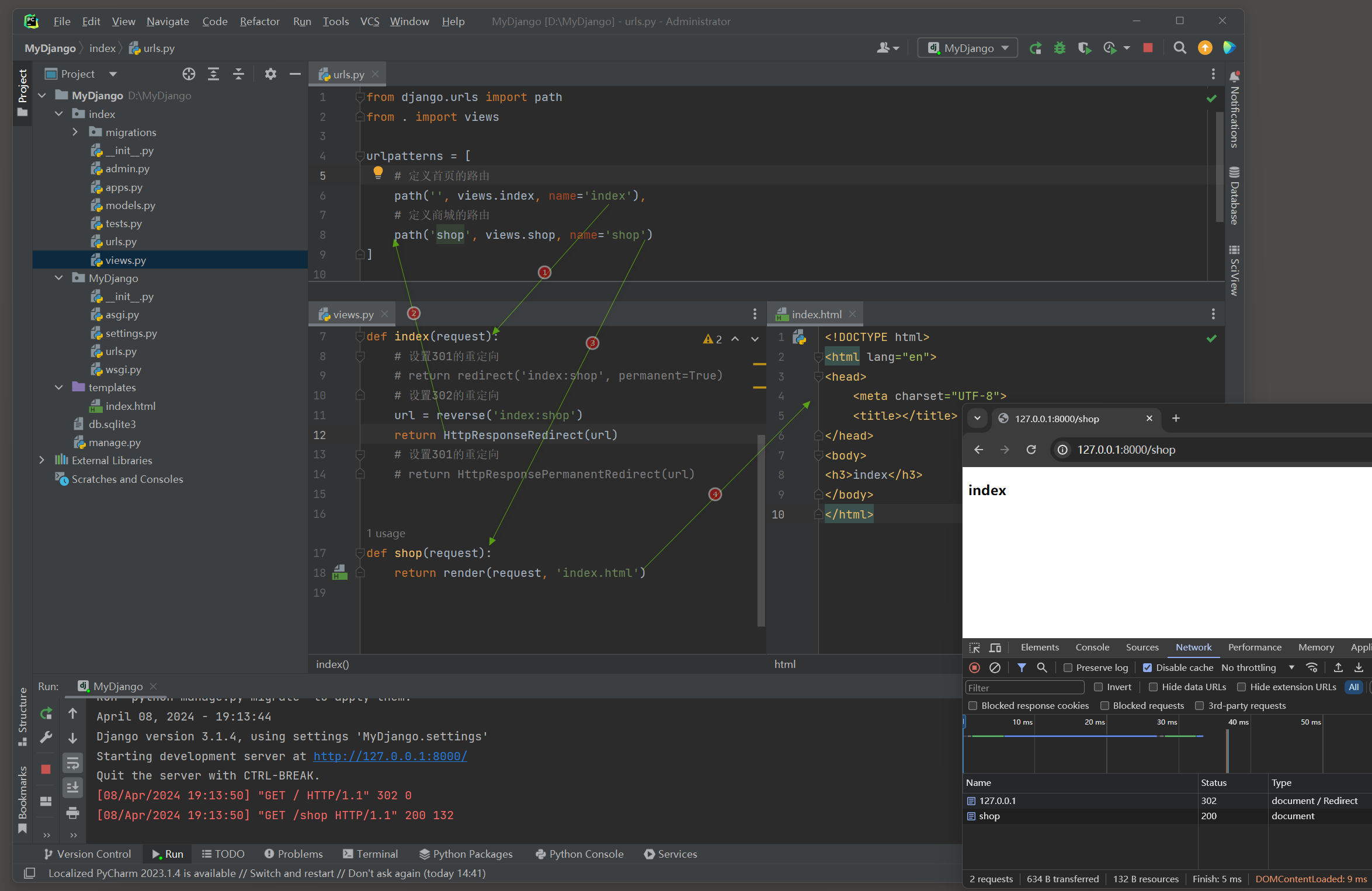
测试 1 , 输入地址 : 127.0 .0 .1 访问主页 , index视图将访问重定向到shop页面 .
测试 2 , 输入地址 : 127.0 .0 .1 访问主页 , index视图将访问重定向到shop页面 .
异常响应是指HTTP状态码为 404 或 500 的响应状态 , 它与正常的响应过程 ( HTTP状态码为 200 的响应过程 ) 是一样的 ,
只是HTTP状态码有所不同 , 因此使用函数render作为响应过程 , 并且设置参数status的状态码 ( 404 或 500 ) 即可实现异常响应 .
同一个网站的每种异常响应所返回的页面都是相同的 , 因此网站的异常响应必须适用于整个项目的所有应用 .
而在Django中配置全局的异常响应 , 必须在项目名的urls . py文件里配置 .
以MyDjango为例 , 在MyDjango文件夹的urls . py中定义路由以及在index文件夹的views . py中定义视图函数 , 代码如下 :
from django. urls import path, include
urlpatterns = [
path( '' , include( ( 'index.urls' , 'index' ) , namespace= 'index' ) ) ,
]
handler404 = 'index.views.pag_not_found'
handler500 = 'index.views.page_error'
from django. shortcuts import render
def pag_not_found ( request, exception) :
"""全局404的配置函数 """
return render( request, '404.html' , status= 404 )
def page_error ( request) :
"""全局500的配置函数 """
return render( request, '500.html' , status= 500 )
在MyDjango文件夹的urls . py里设置handler404和handler500 ,
分别指向index文件夹的views . py的视图函数pag_not_found和page_error .
当用户请求不合理或服务器发生异常时 , Django就会根据请求信息执行相应的异常响应 .
视图函数分别使用到模板 404. html和 500. html , 因此在templates文件夹里新增 404. html和 500. html文件 , 代码如下 :
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> < h3> </ h3> </ body> </ html>
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> < h3> </ h3> </ body> </ html>
上述内容是设置Django全局 404 和 500 的异常响应 , 只需在项目的urls . py中设置变量handler404和handler500 .
变量值是指向某个项目应用的视图函数 , 而被指向的视图函数需要设置相应的模板文件和响应状态码 .
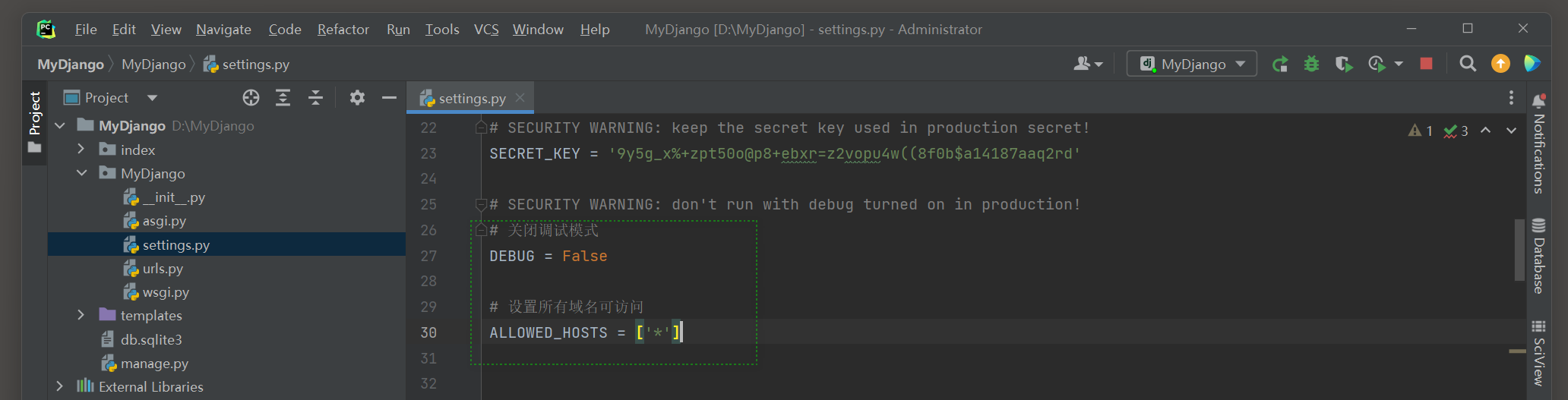
为了验证全局 404 和 500 的异常响应 , 需要对MyDjango项目进行功能调整 , 修改配置文件settings . py中的DEBUG和ALLOWED_HOSTS ,
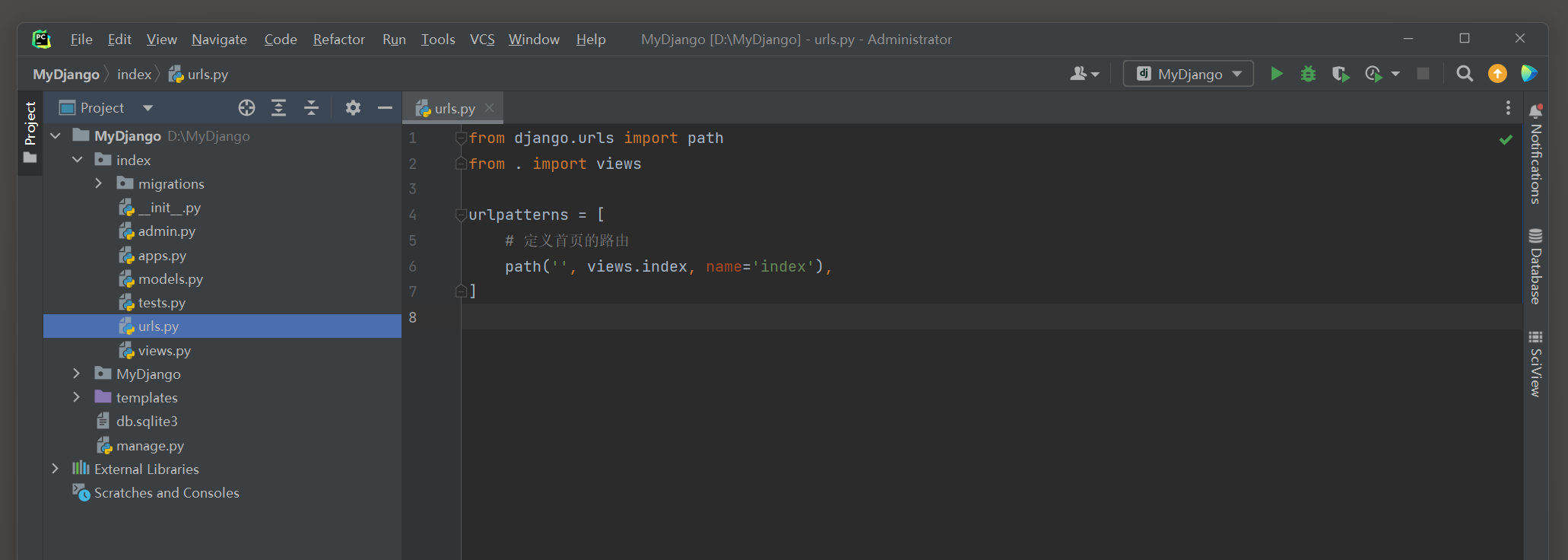
并在index文件夹的urls . py和views . py中设置路由和相应的视图函数 , 代码如下 :
DEBUG = False
ALLOWED_HOSTS = [ '*' ]
from django. urls import path
from . import views
urlpatterns = [
path( '' , views. index, name= 'index' ) ,
]
from django. shortcuts import render
from django. http import Http404
def index ( request) :
if request. GET. get( 'error' , '' ) :
raise Http404( 'page does not exits' )
else :
return render( request, 'index.html' )
from django. shortcuts import render
from django. http import Http404
def index ( request) :
if request. GET. get( 'error' , '' ) :
raise Http404( 'page does not exits' )
else :
return render( request, 'index.html' )
def pag_not_found ( request, exception) :
"""全局404的配置函数 """
return render( request, '404.html' , status= 404 )
def page_error ( request) :
"""全局500的配置函数 """
return render( request, '500.html' , status= 500 )
如果想要验证 404 或 500 的异常响应 , 就必须同时设置settings . py的DEBUG = False和ALLOWED_HOSTS = [ '*' ] .
在Django的调试模式下 , 即DEBUG = True , 当出现异常时 , 404 页面是Django内置的调试页面 , 该页面提供了代码的异常信息 , 如图 4 - 8 所示 .
图 4 - 8 调试页面
如果关闭调试模式 ( DEBUG = False ) 而没有设置ALLOWED_HOSTS = [ '*' ] ,
在运行Django的时候 , 程序就会提示CommandError的错误信息 , 如图 4 - 9 所示 .
图 4 - 9 CommandError错误信息
视图函数index从请求信息里获取请求参数error并进行判断 , 如果请求参数为空 ,
就将模板文件index . html返回浏览器生成网页内容 ;
如果参数error不为空 , 就使用Django内置函数Http404主动抛出 404 异常响应 .
测试 :
1. 输入地址 : 127.0 .0 .1 进入index主页 .
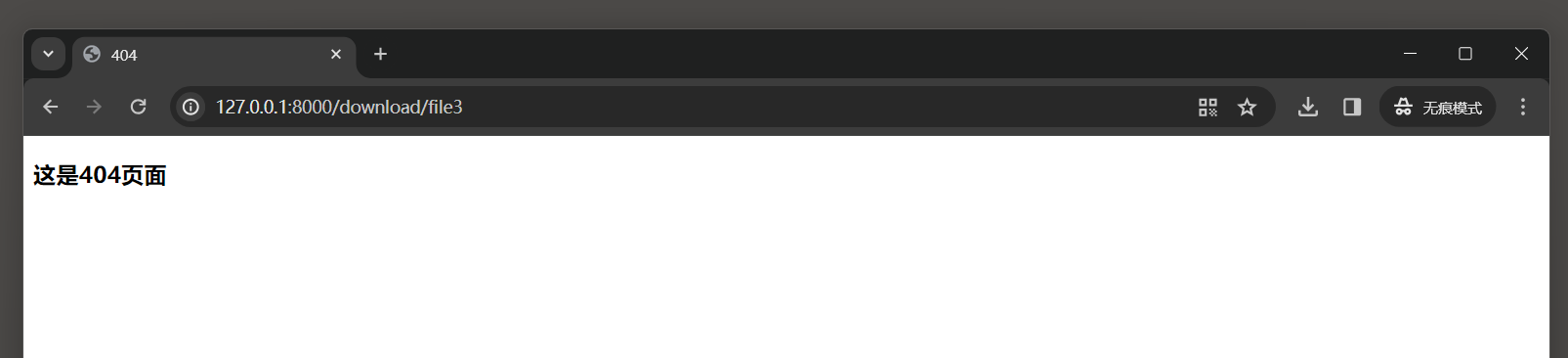
2. 输入地址 : 127.0 .0 .1 / 11 访问不存在的网页返回 404 页面 .
pag_not_found ( request , exception ) 函数中的exception参数通常是一个Http404实例 ,
这是Django专门用来表示页面未找到的异常 .
可以访问exception对象的属性 , 比如exception . args , 它包含了异常的参数 ( 通常是一个描述错误的字符串 ) ,
从而了解触发 404 错误的具体原因 .
响应内容除了返回网页信息外 , 还可以实现文件下载功能 , 是网站常用的功能之一 .
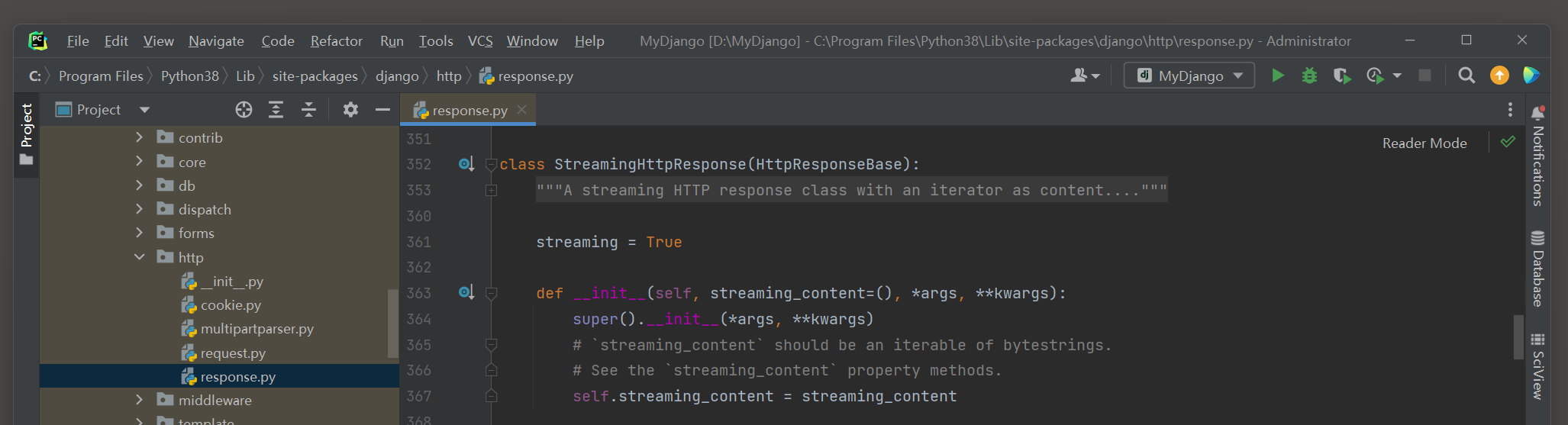
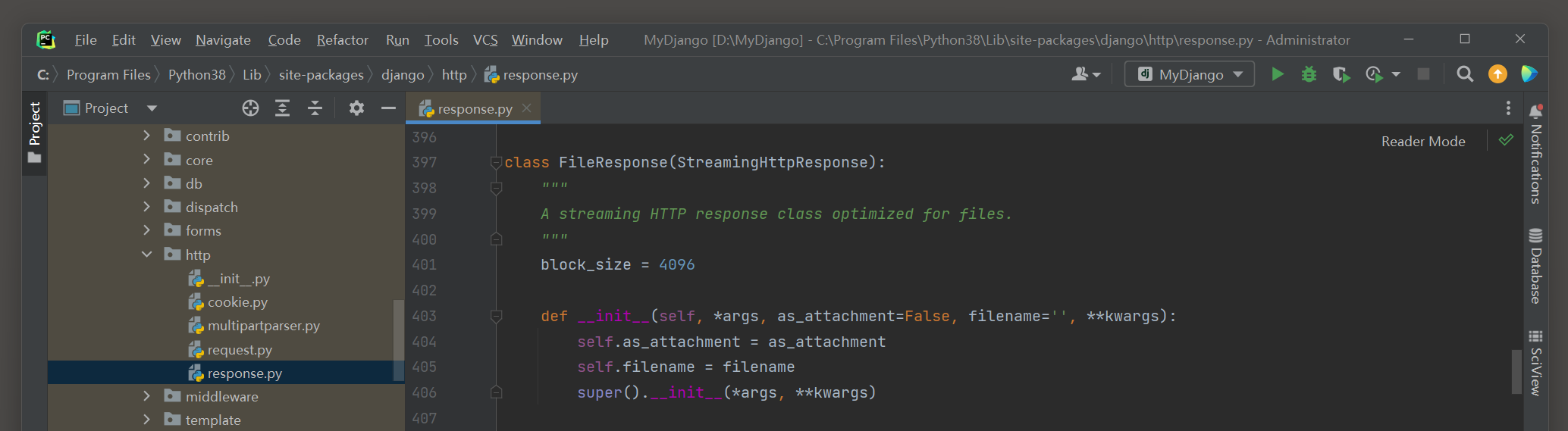
Django提供三种方式实现文件下载功能 , 分别是HttpResponse , StreamingHttpResponse和FileResponse , 三者的说明如下 :
● HttpResponse是所有响应过程的核心类 , 它的底层功能类是HttpResponseBase .
● StreamingHttpResponse是在HttpResponseBase的基础上进行继承与重写的 ,
它实现流式响应输出 ( 流式响应输出是使用Python的迭代器将数据进行分段处理并传输的 ) , 适用于大规模数据响应和文件传输响应 .
● FileResponse是在StreamingHttpResponse的基础上进行继承与重写的 , 它实现文件的流式响应输出 , 只适用于文件传输响应 .
为了进一步了解StreamingHttpResponse和FileResponse ,
在PyCharm里打开StreamingHttpResponse的源码文件 , 如图 4 - 10 所示 .
图 4 - 10 StreamingHttpResponse的源码信息
从图 4 - 10 可以看出 , StreamingHttpResponse的初始化函数设置参数streaming_content和形参 * args及 * * kwargs , 参数说明如下 :
● 参数streaming_content的数据格式可设为迭代器对象或字节流 , 代表数据或文件内容 .
● 形参 * args和 * * kwargs设置HttpResponseBase的参数 , 即响应内容的数据格式content_type和响应状态码status等参数 .
总的来说 , 若使用StreamingHttpResponse实现文件下载功能 , 则文件以字节的方式读取 ,
在StreamingHttpResponse实例化时传入文件的字节流 .
由于该类支持数据或文件内容的响应式输出 , 因此还需要设置响应内容的数据格式和文件下载格式 .
继续分析FileResponse , 在PyCharm里打开FileResponse的源码文件 , 如图 4 - 11 所示 .
图 4 - 11 FileResponse的源码信息
从FileResponse的初始化函数__init__的定义得知 , 该函数设置参数as_attachment和filename , 形参 * args , * * kwargs , 参数说明如下 :
● 参数as_attachment的数据类型为布尔型 , 若为False , 则不提供文件下载功能 ,
文件将会在浏览器里打开并读取 , 若浏览器无法打开文件 , 则将文件下载到本地计算机 , 但没有设置文件后缀名 ;
若为True , 则开启文件下载功能 , 将文件下载到本地计算机 , 并设置文件后缀名 .
● 参数filename设置下载文件的文件名 , 该参数与参数as_attachment的设置有关 .
若参数as_attachment为False , 则参数filename不起任何作用 .
在as_attachment为True的前提下 , 若参数filename为空 , 则使用该文件原有的文件名作为下载文件的文件名 ,
反之以参数filename作为下载文件的文件名 .
参数filename与参数as_attachment的关联可在类FileResponse的函数set_headers里找到 .
● 形参 * args和 * * kwargs用于设置HttpResponseBase的参数 , 即响应内容的数据格式content_type和响应状态码status等参数 .
我们从源码的角度分析了StreamingHttpResponse和FileResponse的定义过程 ,
下一步通过一个简单的例子来讲述如何在Django里实现文件下载功能 .
以MyDjango为例 , 在MyDjango的urls . py , index的urls . py , views . py和templates的index . html
中分别定义路由 , 视图函数和模板文件 , 代码如下 :
from django. urls import path, include
urlpatterns = [
path( '' , include( ( 'index.urls' , 'index' ) , namespace= 'index' ) ) ,
]
handler404 = 'index.views.pag_not_found'
handler500 = 'index.views.page_error'
from django. urls import path
from . import views
urlpatterns = [
path( '' , views. index, name= 'index' ) ,
path( 'download/file1' , views. download1, name= 'download1' ) ,
path( 'download/file2' , views. download2, name= 'download2' ) ,
path( 'download/file3' , views. download3, name= 'download3' )
]
from django. shortcuts import render
from django. http import HttpResponse, Http404
from django. http import StreamingHttpResponse
from django. http import FileResponse
def index ( request) :
return render( request, 'index.html' )
def download1 ( request) :
file_path = r'D:\cat.jpg'
try :
r = HttpResponse( open ( file_path, 'rb' ) )
r[ 'content_type' ] = 'application/octet-stream'
r[ 'Content-Disposition' ] = 'attachment;filename=cat.jpg'
return r
except Exception:
raise Http404( 'Download Error' )
def download2 ( request) :
file_path = r'D:\duck.jpg'
try :
r = StreamingHttpResponse( open ( file_path, 'rb' ) )
r[ 'content_type' ] = 'application/octet-stream'
r[ 'Content-Disposition' ] = 'attachment;filename=duck.jpg'
return r
except Exception:
raise Http404( 'Download Error' )
def download3 ( request) :
file_path = r'D:\dog.jpg'
try :
f = open ( file_path, 'rb' )
r = FileResponse( f, as_attachment= True , filename= 'dog.jpg' )
return r
except Exception:
raise Http404( 'Download Error' )
def pag_not_found ( request, exception) :
"""全局404的配置函数 """
return render( request, '404.html' , status= 404 )
def page_error ( request) :
"""全局500的配置函数 """
return render( request, '500.html' , status= 500 )
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> < ahref = " {% url 'index:download1' %}" > </ a> < br> < ahref = " {% url 'index:download2' %}" > </ a> < br> < ahref = " {% url 'index:download3' %}" > </ a> </ body> </ html>
上述代码是整个MyDjango项目的功能代码 , 文件下载功能实现原理如下 :
( 1 ) MyDjango的urls . py定义的路由指向index的urls . py文件 .
( 2 ) index的urls . py定义 4 条路由信息 , 路由index是网站首页 ,
路由所对应的视图函数index将模板文件index . html作为网页内容呈现在浏览器上 .
( 3 ) 当在浏览器访问 127.0 .0 .1 : 8000 时 , 网页会出现 3 条地址链接 , 每条链接分别对应路由download1 , download2和download3 ,
这些路由所对应的视图函数分别使用不同的响应类实现文件下载功能 .
( 4 ) 视图函数download1使用HttpResponse实现文件下载 , 将文件以字节流的方式读取并传入响应类HttpResponse进行实例化 ,
并对实例化对象r设置参数content_type和Content-Disposition , 这样就能实现文件下载功能 .
( 5 ) 视图函数download2使用StreamingHttpResponse实现文件下载 , 该类的使用方式与响应类HttpResponse的使用方式相同 .
( 6 ) 视图函数download3使用FileResponse实现文件下载 , 该类的使用方式最为简单 ,
只需将文件以字节流的方式读取并且设置参数as_attachment和filename , 然后将三者一并传入FileResponse进行实例化即可 .
如果读者对参数as_attachment和filename的关联存在疑问 , 那么可自行修改上述代码的参数值来梳理两者的关联 .
运行MyDjango项目 , 在D盘下分别放置图片dog . jpg , duck . jpg和cat . jpg ,
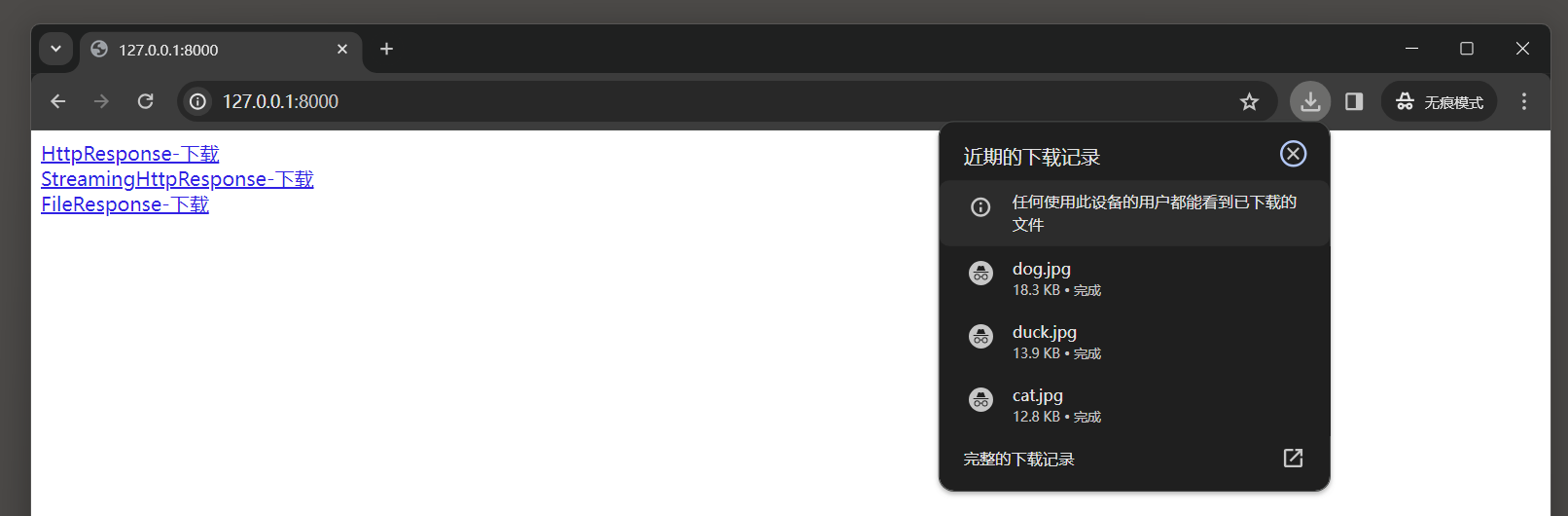
然后在浏览器上访问 : 127.0 .0 .1 : 8000 , 并单击每个图片的下载链接 , 如图 4 - 12 所示 .
图 4 - 12 图片下载
如果没有提供下载文件 , 则会报错 !
上述例子证明HttpResponse , StreamingHttpResponse和FileResponse都能实现文件下载功能 ,
但三者之间存在一定的差异 , 说明如下 :
● HttpResponse实现文件下载存在很大的弊端 , 其工作原理是将文件读取并载入内存 , 然后输出到浏览器上实现下载功能 .
如果下载的文件较大 , 该方法就会占用很多内存 .
对于下载大文件 , Django推荐使用StreamingHttpResponse和FileResponse方法 ,
这两个方法将下载文件分批写入服务器的本地磁盘 , 而不再将文件载入服务器的内存 .
● StreamingHttpResponse和FileResponse的实现原理是相同的 ,
两者都是将下载文件分批写入本地磁盘 , 实现文件的流式响应输出 .
● 从适用范围来说 , StreamingHttpResponse的适用范围更为广泛 ,
可支持大规模数据或文件输出 , 而FileResponse只支持文件输出 .
● 从使用方式来说 , 由于StreamingHttpResponse支持数据或文件输出 ,
因此在使用时需要设置响应输出类型和方式 , 而FileResponse只需设置 3 个参数即可实现文件下载功能 .
网站是根据用户请求来输出相应的响应内容的 , 用户请求是指用户在浏览器上访问某个网址链接的操作 ,
浏览器会根据网址链接信息向网站发送HTTP请求 , 那么 , 当Django接收到用户请求时 , 它是如何获取用户请求信息的呢?
当在浏览器上访问某个网址时 , 其实质是向网站发送一个HTTP请求 , HTTP请求分为 8 种请求方式 , 每种请求方式的说明如表 4 - 2 所示 .
表 4 - 2 请求方式
请求方式 说明 OPTIONS返回服务器针对特定资源所支持的请求方法GET向特定资源发出请求(访问网页)POST向指定资源提交数据处理请求(提交表单, 上传文件)PUT向指定资源位置上传数据内容DELETE请求服务器删除 request-URL 所标示的资源HEAD与 GET 请求类似, 返回的响应中没有具体内容, 用于获取报头TRACE回复和显示服务器收到的请求, 用于测试和诊断CONNECTHTTP/1.1 协议中能够将连接改为管道方式的代理服务器
在上述的HTTP请求方式里 , 最基本的是GET请求和POST请求 , 网站开发者关心的也只有GET请求和POST请求 .
GET请求和POST请求是可以设置请求参数的 , 两者的设置方式如下 :
● GET请求的请求参数是在路由地址后添加 "?" 和参数内容 , 参数内容以key = value形式表示 , 等号前面的是参数名 , 后面的是参数值 ,
如果涉及多个参数 , 每个参数之间就使用 "&" 隔开 , 如 127.0 .0 .1 : 8000 /?user=xy&pw= 123.
● POST请求的请求参数一般以表单的形式传递 , 常见的表单使用HTML的form标签 , 并且form标签的method属性设为POST .
对于Django来说 , 当它接收到HTTP请求之后 , 会根据HTTP请求携带的请求参数以及请求信息来创建一个WSGIRequest对象 ,
并且作为视图函数的首个参数 , 这个参数通常写成request , 该参数包含用户所有的请求信息 .
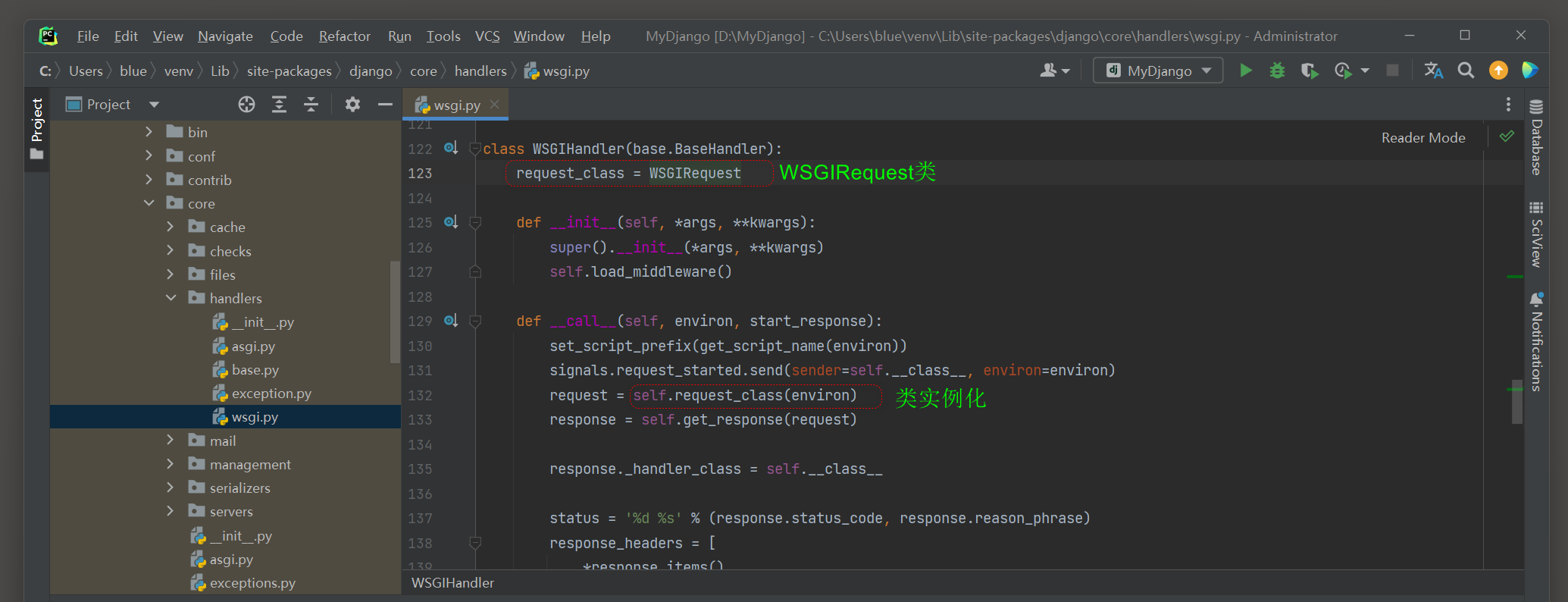
在PyCharm里打开WSGIRequest对象的源码信息 ( django \ core \ handlers \ wsgi . py ) , 如图 4 - 13 所示 .
图 4 - 13 WSGIRequest
从类WSGIRequest的定义看到 , 它继承并重写类HttpRequest .
若要获取请求信息 , 则只需从类WSGIRequest读取相关的类属性即可 .
下面对一些常用的属性进行说明 .
● COOKIE : 获取客户端 ( 浏览器 ) 的Cookie信息 , 以字典形式表示 , 并且键值对都是字符串类型 .
● FILES : django . http . request . QueryDict对象 , 包含所有的文件上传信息 .
● GET : 获取GET请求的请求参数 , 它是django . http . request . QueryDict对象 , 操作起来类似于字典 .
● POST : 获取POST请求的请求参数 , 它是django . http . request . QueryDict对象 , 操作起来类似于字典 .
● META : 获取客户端 ( 浏览器 ) 的请求头信息 , 以字典形式存储 .
● method : 获取当前请求的请求方式 ( GET请求或POST请求 ) .
● path : 获取当前请求的路由地址 .
● session : 一个类似于字典的对象 , 用来操作服务器的会话信息 , 可临时存放用户信息 .
● user : 当Django启用AuthenticationMiddleware中间件时才可用 .
它的值是内置数据模型User的对象 , 表示当前登录的用户 .
如果用户当前没有登录 , 那么user将设为django . contrib . auth . models . AnonymousUser的一个实例 .
由于类WSGIRequest继承并重写类HttpRequest , 因此类HttpRequest里定义的类方法同样适用于类WSGIRequest .
打开类HttpRequest所在的源码文件 , 如图 4 - 14 所示 .
图 4 - 14 HttpRequest
类HttpRequest一共定义了 31 个类方法 , 我们选择一些常用的方法进行讲述 .
● is_secure ( ) : 是否是采用HTTPS协议 .
● is_ajax ( ) : 是否采用AJAX发送HTTP请求 .
判断原理是请求头中是否存在X-Requested-With : XMLHttpRequest .
● get_host ( ) : 获取服务器的域名 .
如果在访问的时候设有端口 , 就会加上端口号 , 如 : 127.0 .0 .1 : 8000.
● get_full_path ( ) : 返回路由地址 .
如果该请求为GET请求并且设有请求参数 , 返回路由地址就会将请求参数返回 , 如 / ?user = xy & pw = 123.
● get_raw_uri ( ) : 获取完整的网址信息 , 将服务器的域名 , 端口和路由地址一并返回 ,
如 : http : / / 127.0 .0 .1 : 8000 /?user=xy&pw= 123.
下面从源码的角度来了解类WSGIRequest的定义过程 .
现在通过一个简单的例子来讲述如何在视图函数里使用类WSGIRequest , 从中获取请求信息 .
以MyDjango为例 , 在MyDjango的urls . py , index的urls . py , views . py和模板文件夹templates的index . html中分别编写代码 :
新建项目 .
from django. urls import path, include
urlpatterns = [
path( '' , include( ( 'index.urls' , 'index' ) , namespace= 'index' ) ) ,
]
from django. urls import path
from . import views
urlpatterns = [
path( '' , views. index, name= 'index' ) ,
]
from django. shortcuts import render
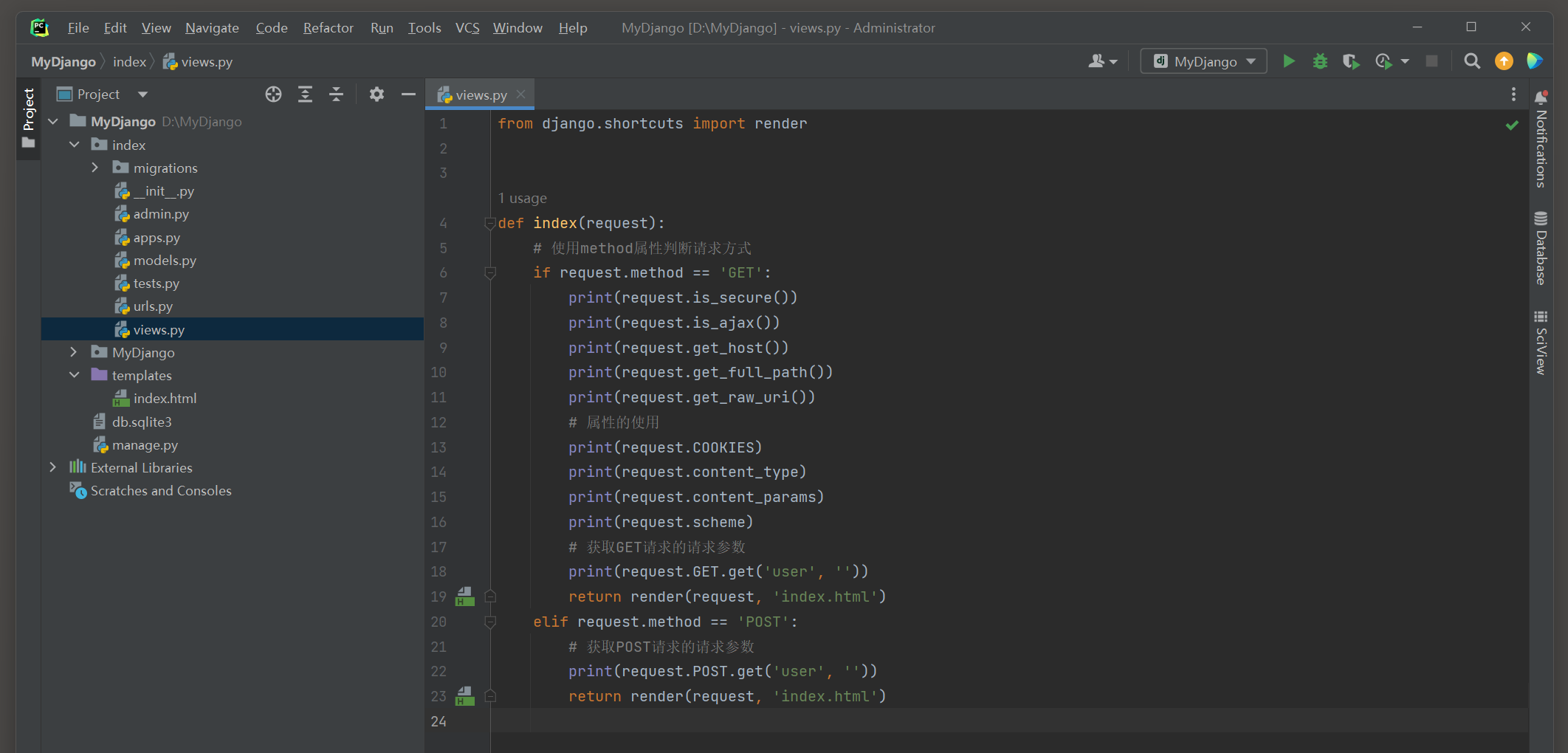
def index ( request) :
if request. method == 'GET' :
print ( request. is_secure( ) )
print ( request. is_ajax( ) )
print ( request. get_host( ) )
print ( request. get_full_path( ) )
print ( request. get_raw_uri( ) )
print ( request. COOKIES)
print ( request. content_type)
print ( request. content_params)
print ( request. scheme)
print ( request. GET. get( 'user' , '' ) )
return render( request, 'index.html' )
elif request. method == 'POST' :
print ( request. POST. get( 'user' , '' ) )
return render( request, 'index.html' )
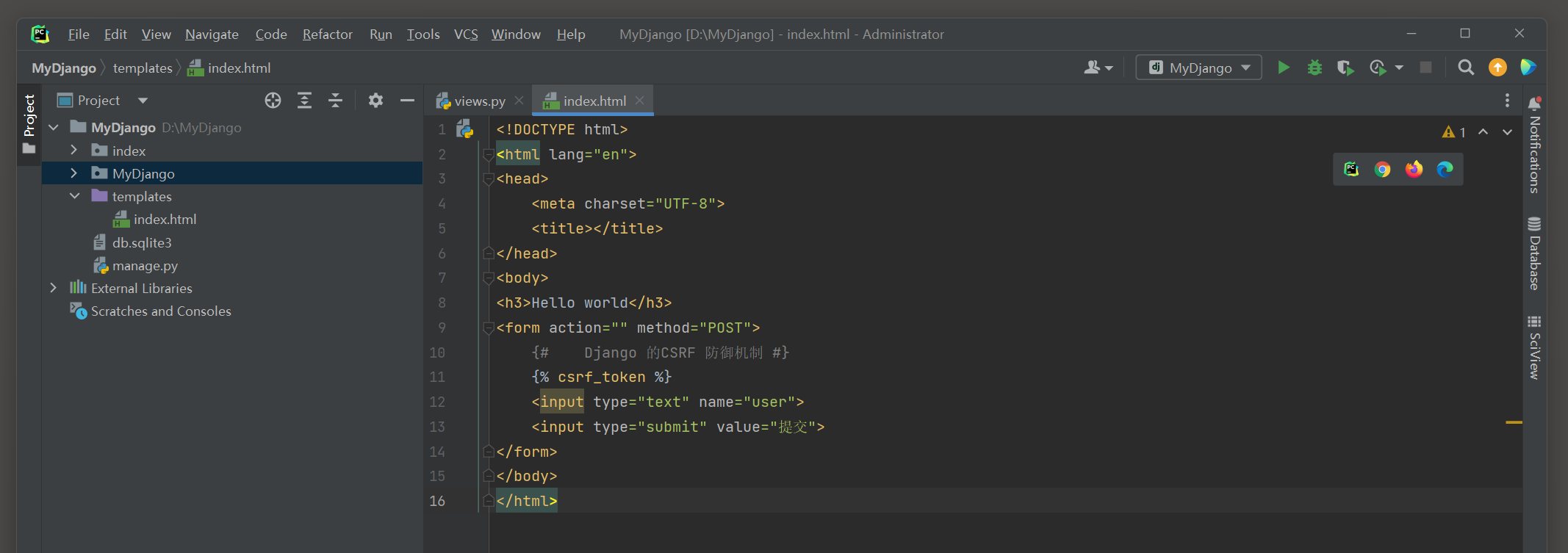
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> < h3> </ h3> < formaction = " " method = " POST" > < inputtype = " text" name = " user" > < inputtype = " submit" value = " 提交" > </ form> </ body> </ html>
视图函数index的参数request是类WSGIRequest的实例化对象 , 通过参数request的method属性来判断HTTP请求方式 .
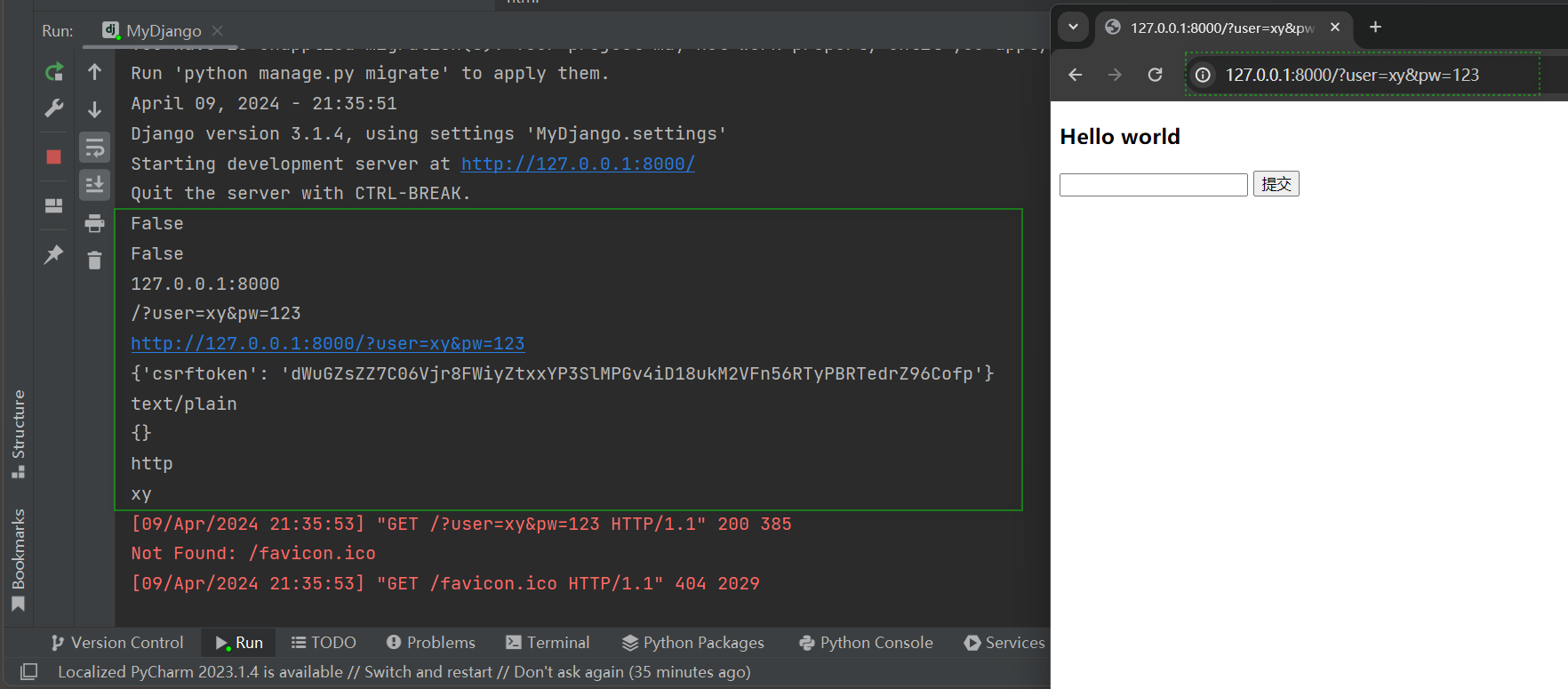
当在浏览器访问 : 127.0 .0 .1 : 8000 /?user=xy&pw= 123 时 , 相当于向Django发送GET请求 ,
从PyCharm的正下方查看请求信息的输出情况 , 如图 4 - 15 所示 .
图 4 - 15 请求信息
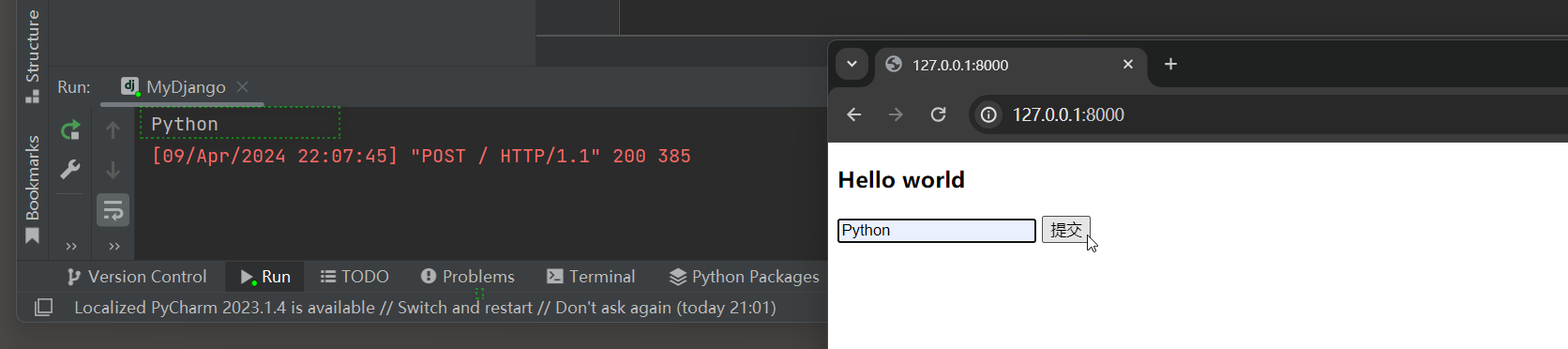
在网页上的文本框中输入数据并单击 '提交' 按钮 , 这时就会触发一个POST请求 ,
再次在PyCharm的正下方查看请求信息的输出情况 , 如图 4 - 16 所示 .
图 4 - 16 请求信息
文件上传功能是网站开发常见的功能之一 , 比如上传图片 ( 用户头像或身份证信息 ) 和导入文件 ( 音视频文件 , 办公文件或安装包等 ) .
无论上传的文件是什么格式的 , 其上传原理都是将文件以二进制的数据格式读取并写入网站指定的文件夹里 .
我们通过一个简单的例子来讲述如何使用Django实现文件上传功能 .
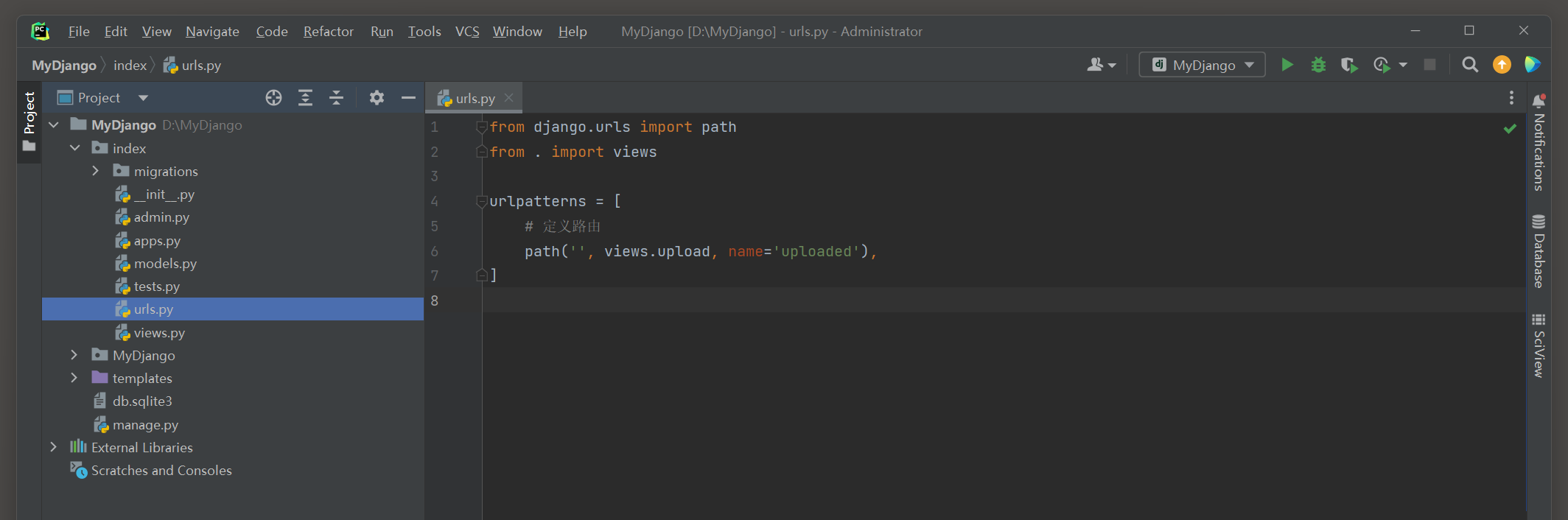
以MyDjango为例 , 在index的urls . py , views . py和模板文件夹templates的upload . html中分别编写以下代码 :
from django. urls import path
from . import views
urlpatterns = [
path( '' , views. upload, name= 'uploaded' ) ,
]
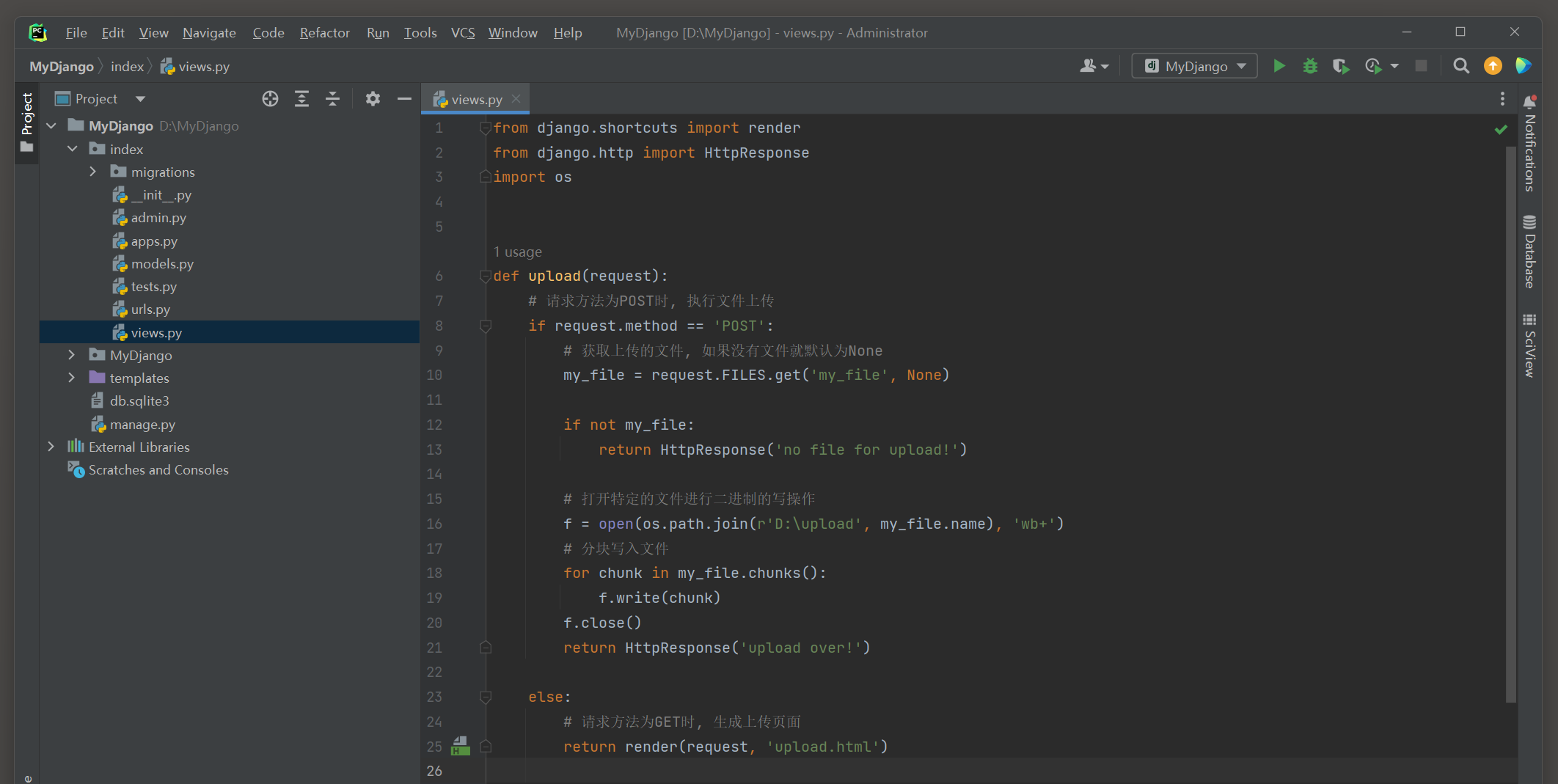
from django. shortcuts import render
from django. http import HttpResponse
import os
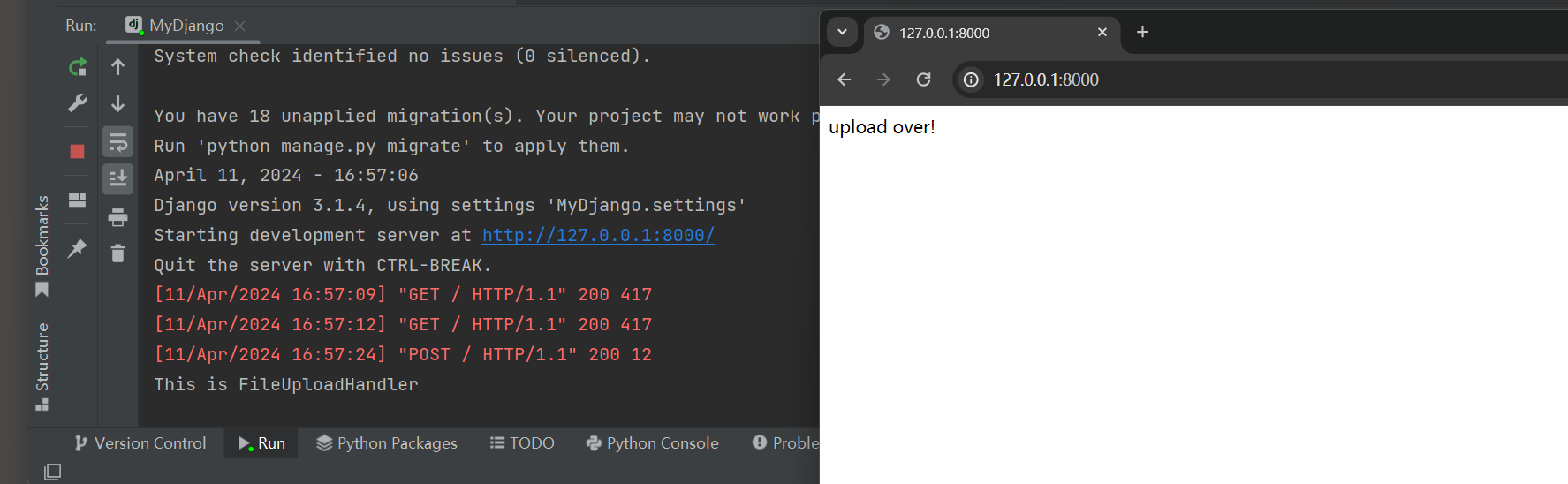
def upload ( request) :
if request. method == 'POST' :
my_file = request. FILES. get( 'my_file' , None )
if not my_file:
return HttpResponse( 'no file for upload!' )
f = open ( os. path. join( r'D:\upload' , my_file. name) , 'wb+' )
for chunk in my_file. chunks( ) :
f. write( chunk)
f. close( )
return HttpResponse( 'upload over!' )
else :
return render( request, 'upload.html' )
注意 : 自己动手创建 'D:\upload' , oopen 函数本身并没有创建目录 ( 路径 ) 的能力 .
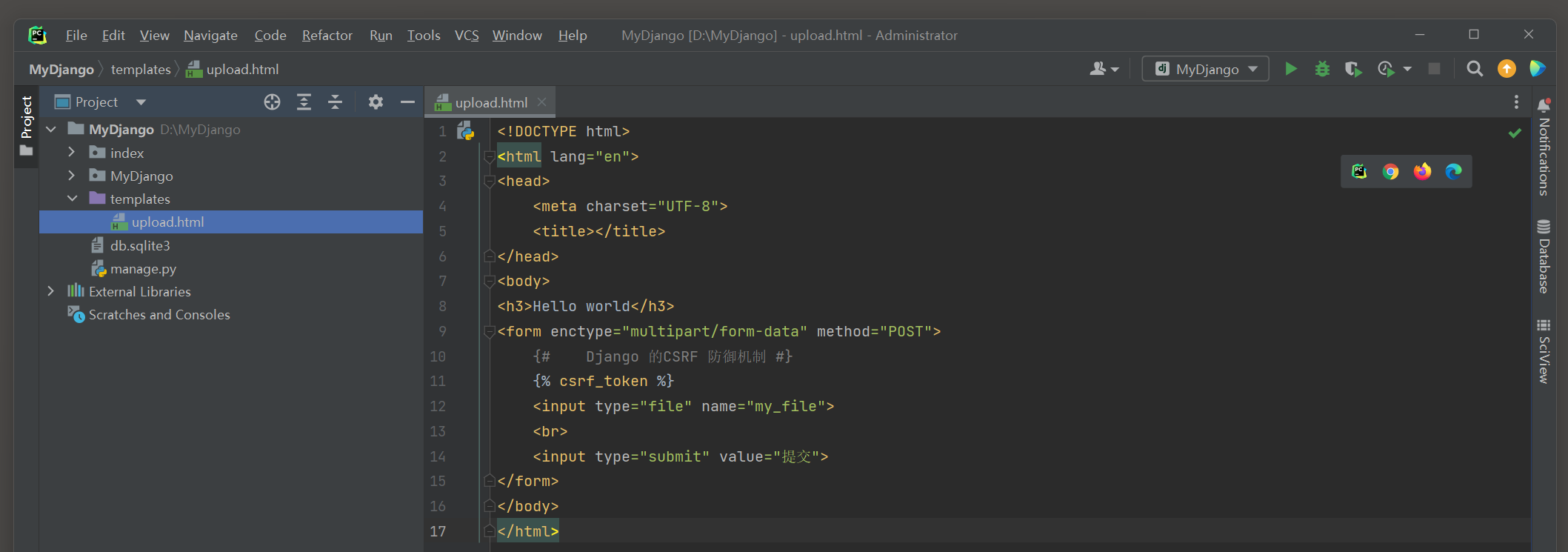
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> < h3> </ h3> < formaction = " multipart/from-data" method = " POST" > < inputtype = " file" name = " my_file" > < br> < inputtype = " submit" value = " 提交" > </ form> </ body> </ html>
测试 :
* 1. 运行项目 , 输入地址 : 127.0 .0 .1 进入文件上传页面 .
* 2. 点击选择文件 .
* 3. 然后提交文件 .
* 4. 文件上传到指定路径 .
从视图函数upload可以看到 , 如果当前的HTTP请求为POST , 就会触发文件上传功能 .
其运行过程如下 :
( 1 ) 模板文件upload . html使用form标签的文件控件file生成文件上传功能 ,
该控件将用户上传的文件以二进制读取 , 读取方式由form标签的属性enctype = "multipart/form-data" 设置 .
( 2 ) 浏览器将用户上传的文件读取后 , 通过HTTP的POST请求将二进制数据传到Django ,
当Django收到POST请求后 , 从请求对象的属性FILES获取文件信息 , 然后在D盘的upload文件夹里创建新的文件 ,
文件名 ( 从文件信息对象my_file . name获取 ) 与用户上传的文件名相同 .
( 3 ) 从文件信息对象my_file . chunks ( ) 读取文件内容 , 并写入D盘的upload文件夹的文件中 , 从而实现文件上传功能 .
上述例子有两个关键知识点 , 即form标签属性enctype = "multipart/form-data" 和文件对象my_file , 两者说明如下 :
如果将模板文件的form标签属性enctype = "multipart/form-data" 去掉 ,
当用户在浏览器操作文件上传的时候 , Django就无法从请求对象的FILES获取文件信息 , 控件file变为请求参数的形式传递 , 如图 4 - 17 所示 .
没有去掉模板文件的form标签属性时 :
将模板文件的form标签属性enctype = "multipart/form-data" 去掉 :
图 4 - 17 请求对象request
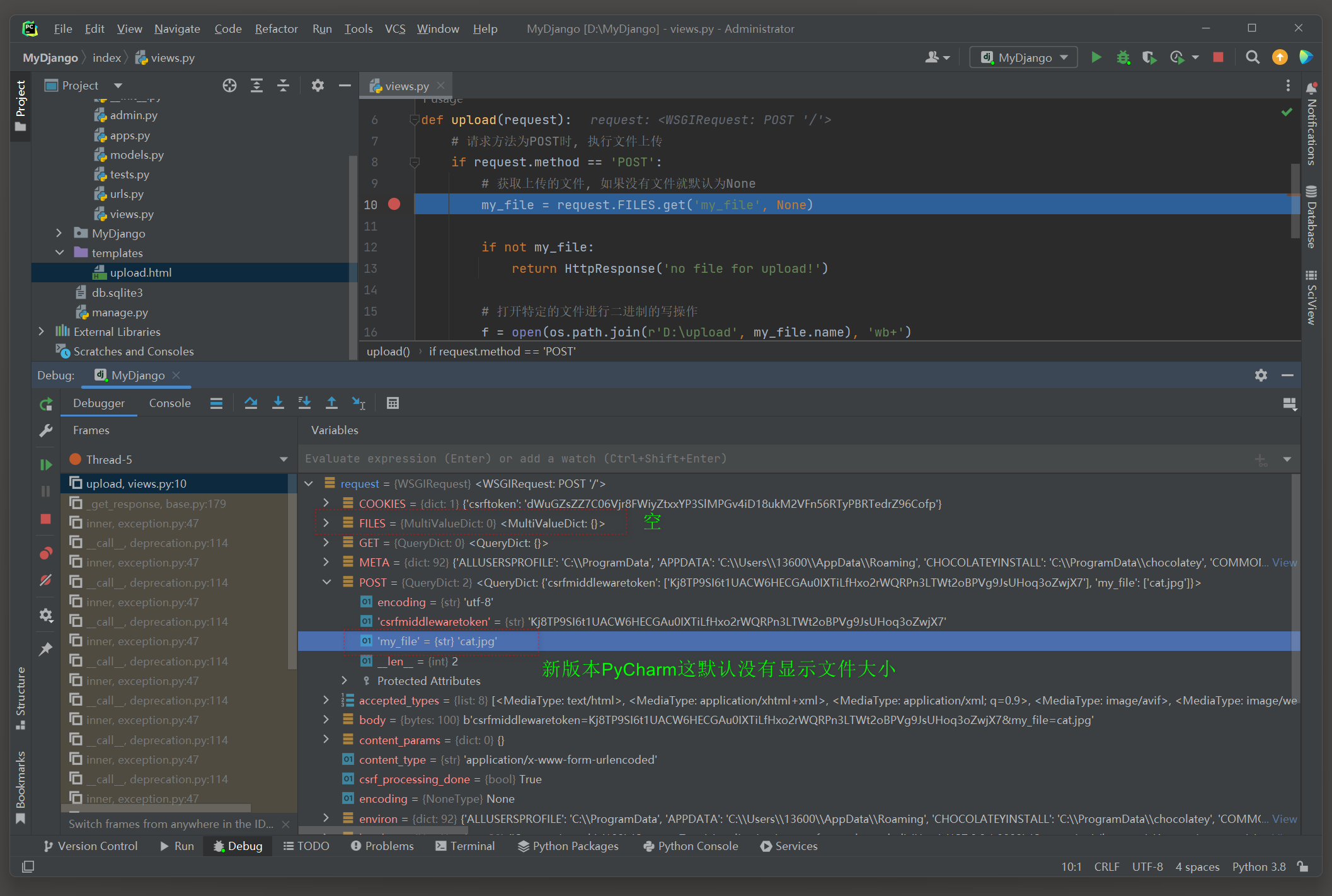
文件对象my_file包含文件的基本信息 , 如文件名 , 大小和后缀名等 .
在PyCharm的断点调试模式下可以查看文件对象my_file的具体信息 , 如图 4 - 18 所示 .
从图 4 - 18 可以看到 , 文件对象my_file提供了以下属性来获取文件信息 .
● my_file . name : 获取上传文件的文件名 , 包含文件后缀名 .
● my_file . size : 获取上传文件的文件大小 .
● my_file . content_type : 获取文件类型 , 通过后缀名判断文件类型 .
从文件对象my_file获取文件内容 , Django提供了以下读取方式 , 每种方式说明如下 :
● my_file . read ( ) : 从文件对象里读取整个文件上传的数据 , 这个方法只适合小文件 .
● my_file . chunks ( ) : 按流式响应方式读取文件 , 在for循环中进行迭代 , 将大文件分块写入服务器所指定的保存位置 .
● my_file . multiple_chunks ( ) : 判断文件对象的文件大小 , 返回True或者False ,
当文件大于 2.5 MB ( 默认值为 2.5 MB ) 时 , 该方法返回True , 否则返回False .
因此 , 可以根据该方法来选择选用read方法读取还是采用chunks方法 .
上述是从功能实现的角度了解Django的文件上传过程 , 为了深入了解文件上传机制 , 我们从Django源码里分析文件上传功能 .
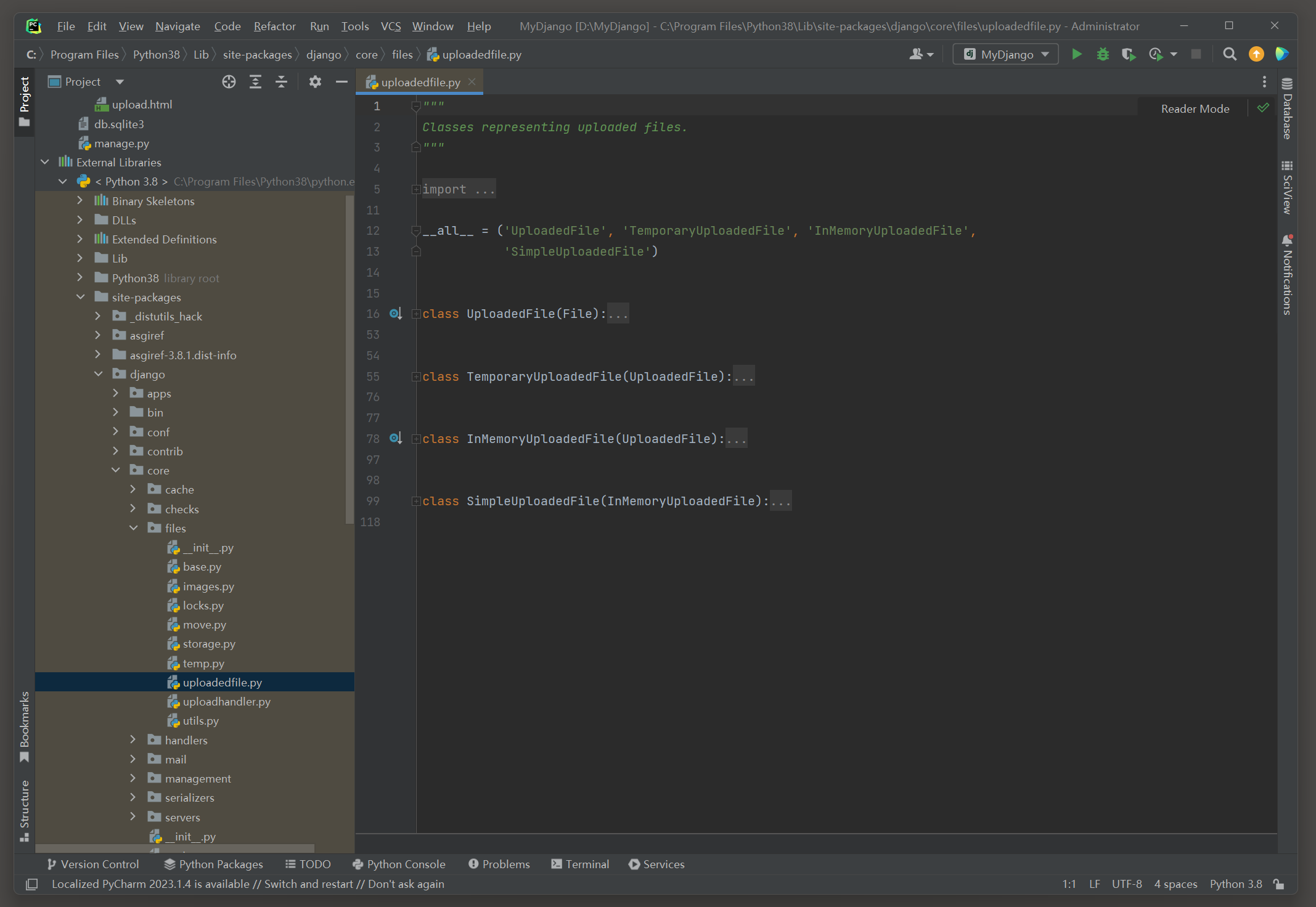
在PyCharm里打开Django文件上传的源码文件uploadedfile . py , 如图 4 - 19 所示 .
图 4 - 19 源码文件uploadedfile . py
源码文件uploadedfile . py定义了 4 个功能类 , 每个类所实现的功能说明如下 :
● UploadedFile ( 上传的文件 ) : 文件上传的基本功能类 , 继承父类File , 该类主要获取文件的文件名 , 大小和类型等基本信息 .
● TemporaryUploadedFile ( 临时上传的文件 ) : 将文件数据临时存放在服务器所指定的文件夹里 , 适用于大文件的上传 .
● InMemoryUploadedFile ( 内存中上传的文件 ) : 将文件数据存放在服务器的内存里 , 适用于小文件的上传 .
● SimpleUploadedFile ( 简单上载的文件 ) : 将文件的文件名 , 大小和类型生成字典格式 .
从上述内容得知 , 当使用my_file . read ( ) 和my_file . chunks ( ) 读取文件内容时 ,
其实质是分别调用InMemoryUploadedFile或TemporaryUploadedFile来实现文件上传 ,
两者的区别在于保存上传文件之前 , 文件数据需要存放在某个位置 .
默认情况下 , 当上传的文件小于 2.5 MB时 , Django通过InMemoryUploadedFile把上传的文件的全部内容读进内存 ;
当上传的文件大于 2.5 MB时 , Django会使用TemporaryUploadedFile把上传的文件写到临时文件中 ,
然后存放到系统临时文件夹中 , 从而节省内存的开销 .
在这 4 个功能类的基础上 , Django进一步完善了文件上传处理过程 , 主要完善了文件的创建 , 读写和关闭处理等 .
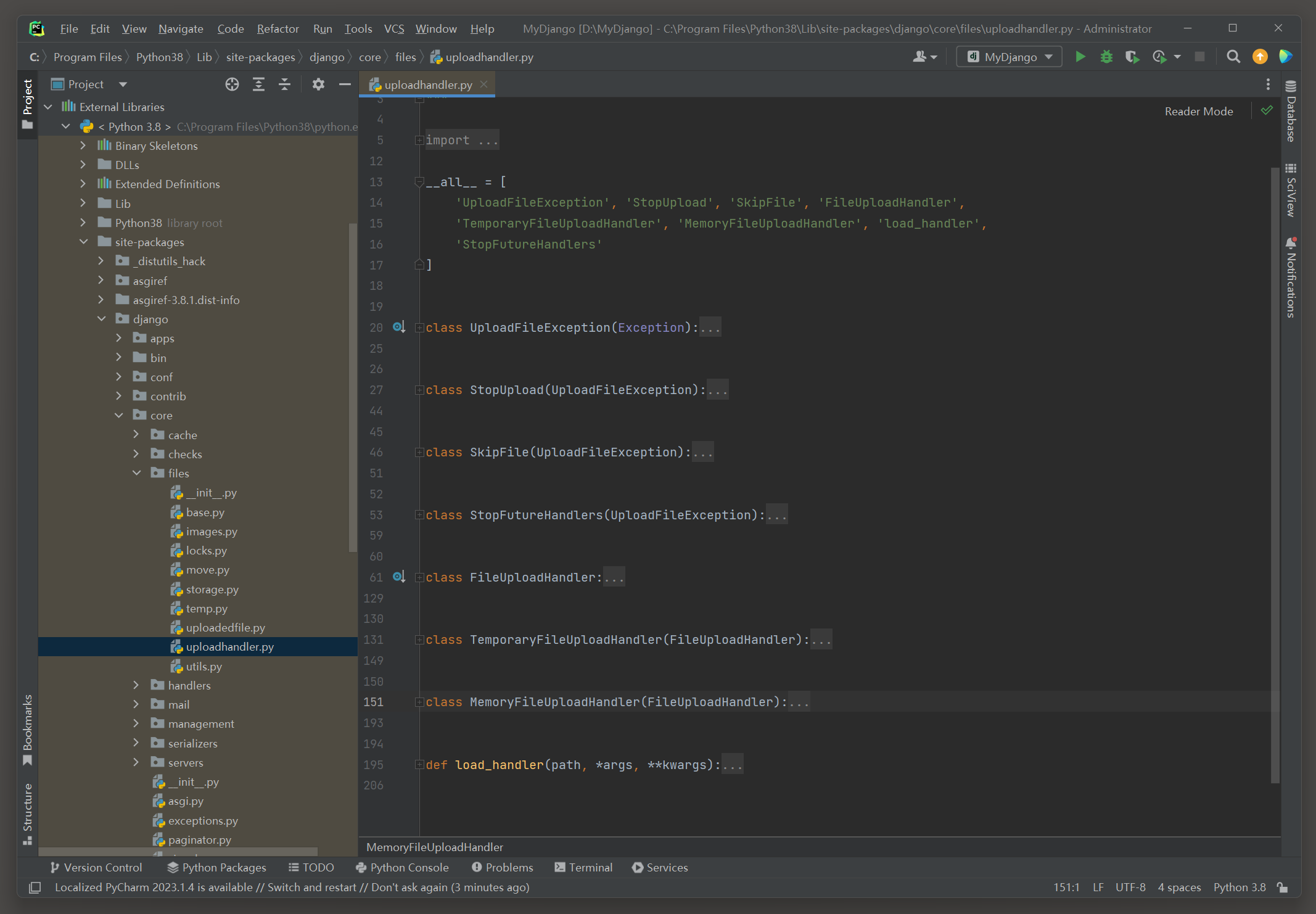
处理过程可以在源码文件uploadhandler . py中找到 , 该文件共定义了 7 个Handler类和一个函数 , 如图 4 - 20 所示 .
图 4 - 20 源码文件uploadhandler . py
图 4 - 20 所示的 7 个Handler类可以划分为两类 : 异常处理和程序处理 .
异常处理是处理文件上传的过程中出现的异常情况 , 如中断上传 , 网络延迟和上传失败等情况 .
程序处理是实现文件上传过程 , 其中TemporaryFileUploadHandler调用TemporaryUploadedFile来实现上传过程 ,
MemoryFileUploadHandler则调用InMemoryUploadedFile .
无论是哪个Handler类 , Django都为文件上传机制设有 4 个配置属性 , 分别说明如下 :
● FILE_UPLOAD_MAX_MEMORY_SIZE : 判断文件大小的条件 ( 以字节数表示 ) , 默认值为 2.5 MB .
● FILE_UPLOAD_PERMISSIONS : 可以在源码文件storage . py中找到 , 用于配置文件上传的用户权限 .
● FILE_UPLOAD_TEMP_DIR : 可以在源码文件uploadedfile . py中找到 , 用于配置文件数据的临时存放文件夹 .
● FILE_UPLOAD_HANDLERS : 设置文件上传的处理过程 .
配置属性FILE_UPLOAD_HANDLERS用于修改文件上传的处理过程 , 这一配置属性在开发过程中非常重要 .
当Django内置的文件上传机制不能满足开发需求时 , 我们可以自定义文件上传的处理过程 .
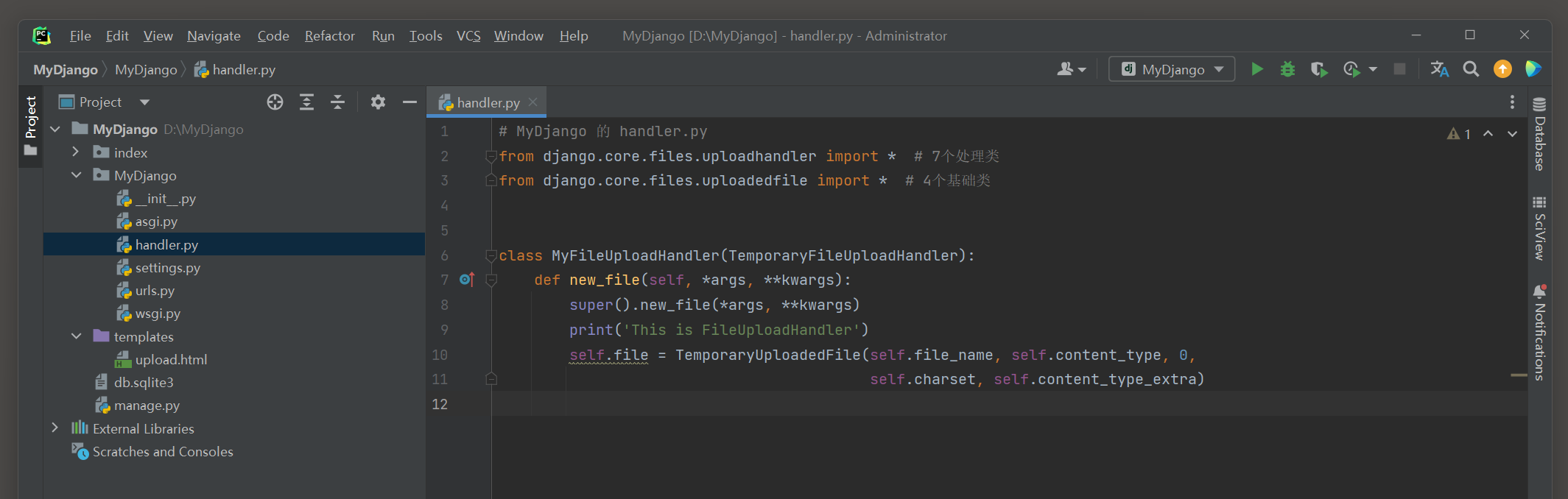
以MyDjango为例 , 在MyDjango文件夹里新增handler . py文件 ,
在该文件里定义myFileUploadHandler类并继承TemporaryFileUploadHandler , 代码如下 :
from django. core. files. uploadhandler import *
from django. core. files. uploadedfile import *
class MyFileUploadHandler ( TemporaryFileUploadHandler) :
def new_file ( self, * args, ** kwargs) :
super ( ) . new_file( * args, ** kwargs)
print ( 'This is FileUploadHandler' )
self. file = TemporaryUploadedFile( self. file_name, self. content_type, 0 ,
self. charset, self. content_type_extra)
自定义类MyFileUploadHandler继承TemporaryFileUploadHandler ,
并在new_file方法里添加print函数 , 通过print的输出来验证类MyFileUploadHandler是否生效 .
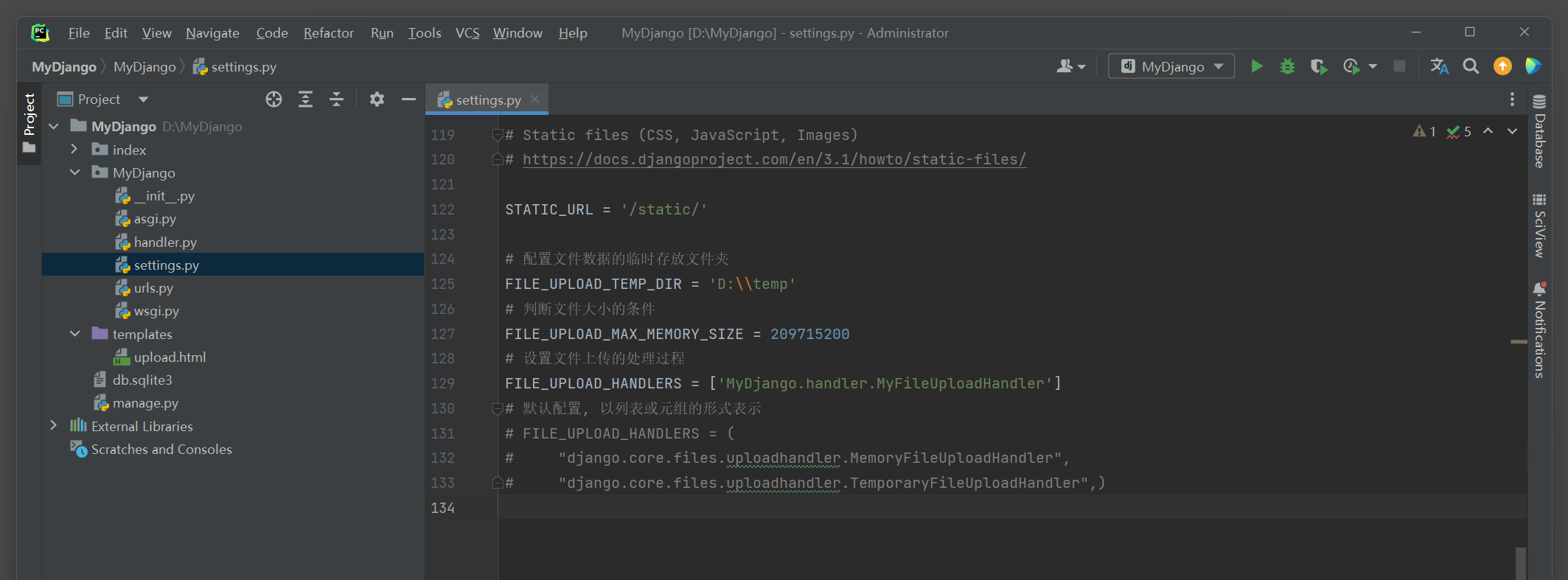
最后在配置文件settings . py中设置文件上传的配置属性 , 代码如下 :
FILE_UPLOAD_TEMP_DIR = 'D:\\temp'
FILE_UPLOAD_MAX_MEMORY_SIZE = 209715200
FILE_UPLOAD_HANDLERS = [ 'MyDjango.handler.MyFileUploadHandler' ]
在D盘下创建temp目录 .
运行MyDjango项目并访问 127.0 .0 .1 : 8000 , 在文件上传页面完成文件上传操作 , 发现在PyCharm的正下方有数据输出 ,
并与类MyFileUploadHandler添加print函数的数据一致 , 如图 4 - 21 所示 .
图 4 - 21 运行结果
我们知道 , Django接收的HTTP请求信息里带有Cookie信息 , Cookie的作用是为了识别当前用户的身份 , 通过以下例子来说明Cookie的作用 .
浏览器向服务器 ( Django ) 发送请求 , 服务器做出响应之后 , 二者便会断开连接 ( 会话结束 ) ,
下次用户再来请求服务器 , 服务器没有办法识别此用户是谁 .
比如用户登录功能 , 如果没有Cookie机制支持 , 那么只能通过查询数据库实现 ,
并且每次刷新页面都要重新操作一次用户登录才可以识别用户 , 这会给开发人员带来大量的冗余工作 ,
简单的用户登录功能会给服务器带来巨大的负载压力 .
Cookie是从浏览器向服务器传递数据 , 让服务器能够识别当前用户 , 而服务器对Cookie的识别机制是通过Session实现的 ,
Session存储了当前用户的基本信息 , 如姓名 , 年龄和性别等 .
由于Cookie存储在浏览器里面 , 而且Cookie的数据是由服务器提供的 , 如果服务器将用户信息直接保存在浏览器中 ,
就很容易泄露用户信息 , 并且Cookie大小不能超过 4 KB , 不能支持中文 ,
因此需要一种机制在服务器的某个域中存储用户数据 , 这个域就是Session .
总而言之 , Cookie和Session是为了解决HTTP协议无状态的弊端 , 为了让浏览器和服务端建立长久联系的会话而出现的 .
Cookie除了解决HTTP协议无状态的弊端之外 , 还可以利用Cookie实现反爬虫机制 .
随着大数据和人工智能的发展 , 爬虫技术日益完善 , 网站为了保护自身数据的安全性和负载能力 , 都会在网站里设置反爬虫机制 .
本小节将讲述如何在Cookie里设置反爬虫机制 , 但在此之前 , 我们首先学习如何使用Django的Cookie .
由于Cookie是通过HTTP协议从浏览器传递到服务器的 ,
因此从视图函数的请求对象request可以获取Cookie对象 , 而Django提供以下方法来操作Cookie对象 :
request. COOKIES[ 'uuid' ]
request. COOKIES. get( 'uuid' )
return HttpResponse( 'Hello world' )
response. set_cookie( 'key' , 'value' )
return response
return HttpResponse( 'Hello world' )
response. delete_cookie( 'key' )
return response
操作Cookie对象无非就是对Cookie进行获取 , 添加和删除处理 .
添加Cookie信息是使用set_cookie方法实现的 , 该方法是由响应类HttpResponseBase定义的 ,
在PyCharm里打开Django的源码文件response . py , 查看set_cookie方法的定义过程 , 如图 4 - 22 所示 .
图 4 - 22 源码文件response . py
set_cookie方法定义了 9 个函数参数 , 每个参数的说明如下 :
● key : 设置Cookie的key , 类似字典的key .
● value : 设置Cookie的value , 类似字典的value .
● max_age : 设置Cookie的有效时间 , 以秒为单位 .
● expires : 设置Cookie的有效时间 , 以日期格式为单位 .
● path : 设置Cookie的生效路径 , 默认值为根目录 ( 网站首页 ) .
● domain : 设置Cookie生效的域名 .
● secure : 设置传输方式 , 若为False , 则使用HTTP , 否则使用HTTPS .
● httponly : 设置是否只能使用HTTP协议传输 .
● samesite : 设置强制模式 , 可选值为lax或strict , 主要防止CSRF攻击 .
常见的反爬虫主要是设置参数max_age , expires和path .
参数max_age或expires用于设置Cookie的有效性 , 使爬虫程序无法长时间爬取网站数据 ;
参数path用于将Cookie的生成过程隐藏起来 , 不容易让爬虫开发者找到并破解 .
除此之外 , 我们在源码文件response . py里也能找到delete_cookie方法 ,
该方法设有函数参数key , path和domain , 这些参数的作用与set_cookie的参数相同 , 此处不详细讲述 .
Cookie的数据信息一般都是经过加密处理的 , 若使用set_cookie方法设置Cookie , 则参数value需要自行加密 ,
如果数据加密过于简单 , 就很容易被爬虫开发者破解 , 但是过于复杂又不利于日后的维护 .
为了简化这个过程 , Django内置Cookie的加密方法set_signed_cookie , 该方法可以在源码文件response . py里找到 , 如图 4 - 23 所示 .
图 4 - 23 源码文件response . py
set_signed_cookie是将参数value进行加密处理 , 再将加密后的value传递给set_cookie , 从而实现Cookie加密与添加 .
set_signed_cookie设有 4 个参数 , 参数说明如下 :
● key : 设置Cookie的key , 类似字典的key .
● value : 设置Cookie的value , 类似字典的value .
● salt : 设置加密盐 , 用于数据的加密处理 .
● * * kwargs : 设置可选参数 , 用于设置set_cookie的参数 .
Cookie的加密过程是调用get_cookie_signer方法实现的 , 该方法来自于源码文件signing . py , 如图 4 - 24 所示 .
图 4 - 24 get_cookie_signer的源码信息
从图 4 - 24 得知 , 变量Signer用于获取项目配置文件settings . py的Cookie数据加密 ( 解密 ) 引擎SIGNING_BACKEND ,
默认值为django . core . signing . TimestampSigner , 即源码文件signing . py定义的TimestampSigner类 , 如图 4 - 25 所示 ;
变量key用于获取项目配置文件settings . py的配置属性SECRET_KEY .
图 4 - 25 TimestampSigner的源码信息
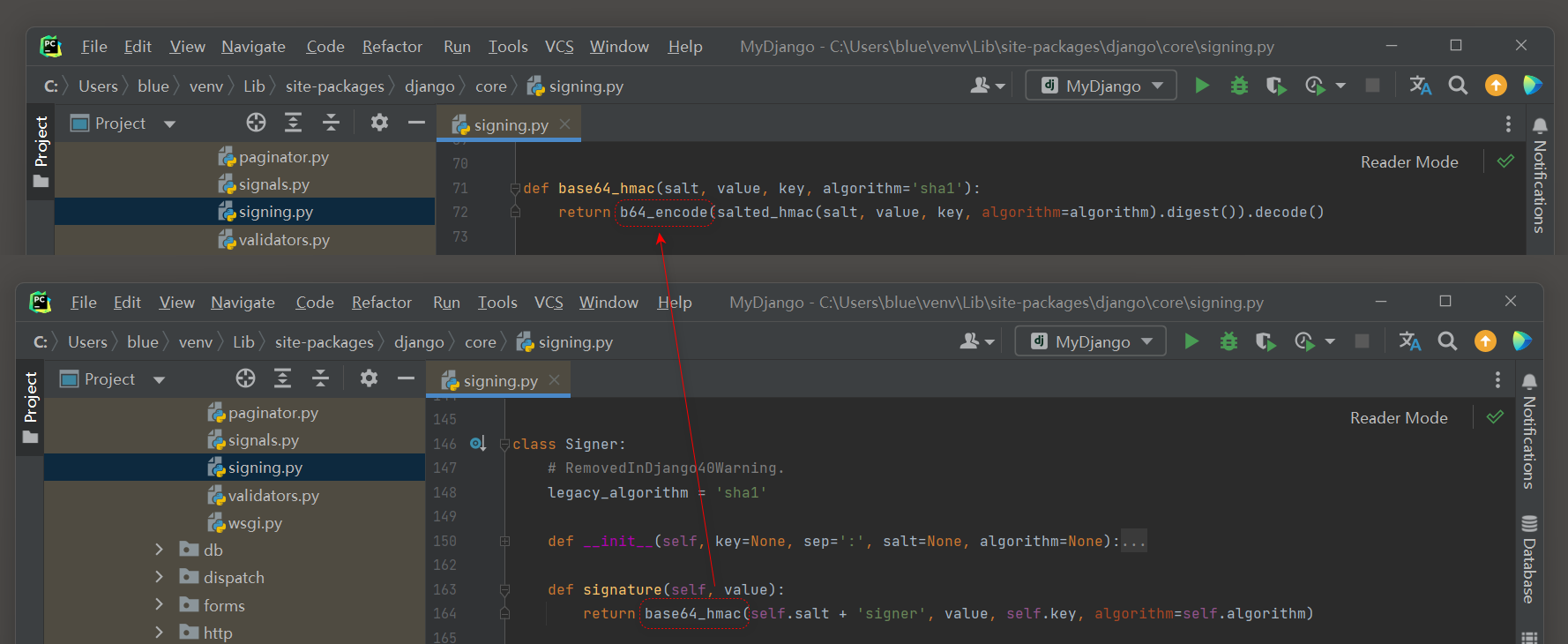
由于get_cookie_signer的返回值调用TimestampSigner类 , 因此可以在源码文件signing . py中找到TimestampSigner类 .
在该类中找到加密方法sign , 加密过程继承父类Signer的sign方法 , 而父类的sign方法是调用signature方法执行加密计算的 ,
这时采用b64_encode的加密算法 , 如图 4 - 26 所示 .
加密数据由set_signed_cookie的参数key , 参数value , 参数salt ,
配置文件settings . py的SECRET_KEY , get_cookie_signer的字符串 ( django . http . cookies )
和TimestampSigner的时间戳函数timestamp组成 .
图 4 - 26 Cookie的加密算法
从TimestampSigner类或Signer类可以看到 , 类方法unsign用于Cookie解密处理 ,
主要是接收浏览器传递的Cookie并进行解密处理 , 解密过程与加密过程是相反的 , 此处不再详细讲述 .
了解了Django的Cookie机制后 , 我们以MyDjango项目为例中讲述如何使用Cookie实现反爬虫机制 .
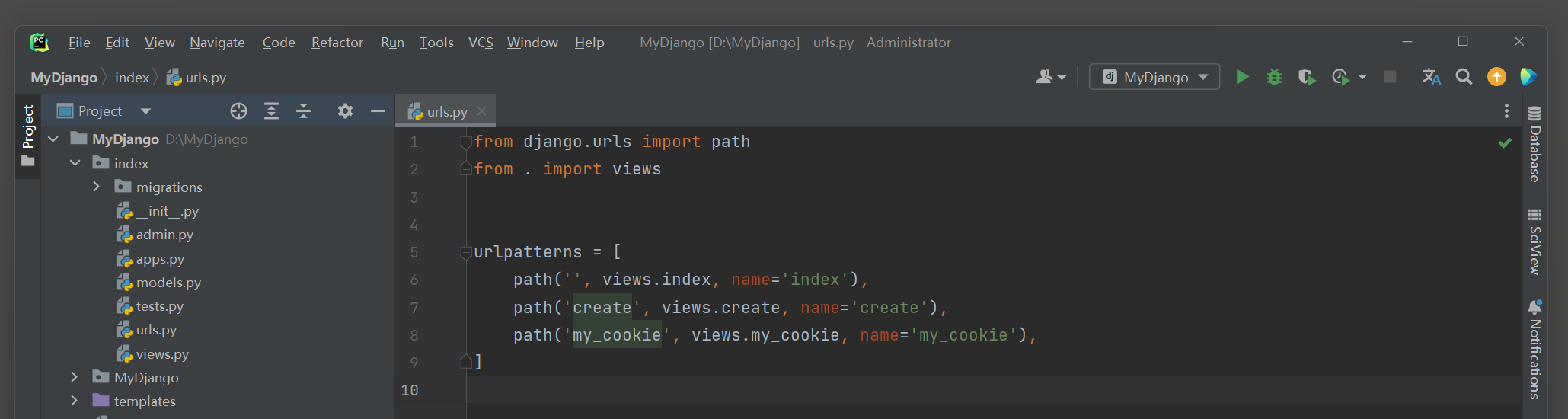
在index的urls . py , views . py和templates的index . html中分别编写以下代码 :
from django. urls import path
from . import views
urlpatterns = [
path( '' , views. index, name= 'index' ) ,
path( 'create' , views. create, name= 'create' ) ,
path( 'my_cookie' , views. my_cookie, name= 'my_cookie' ) ,
]
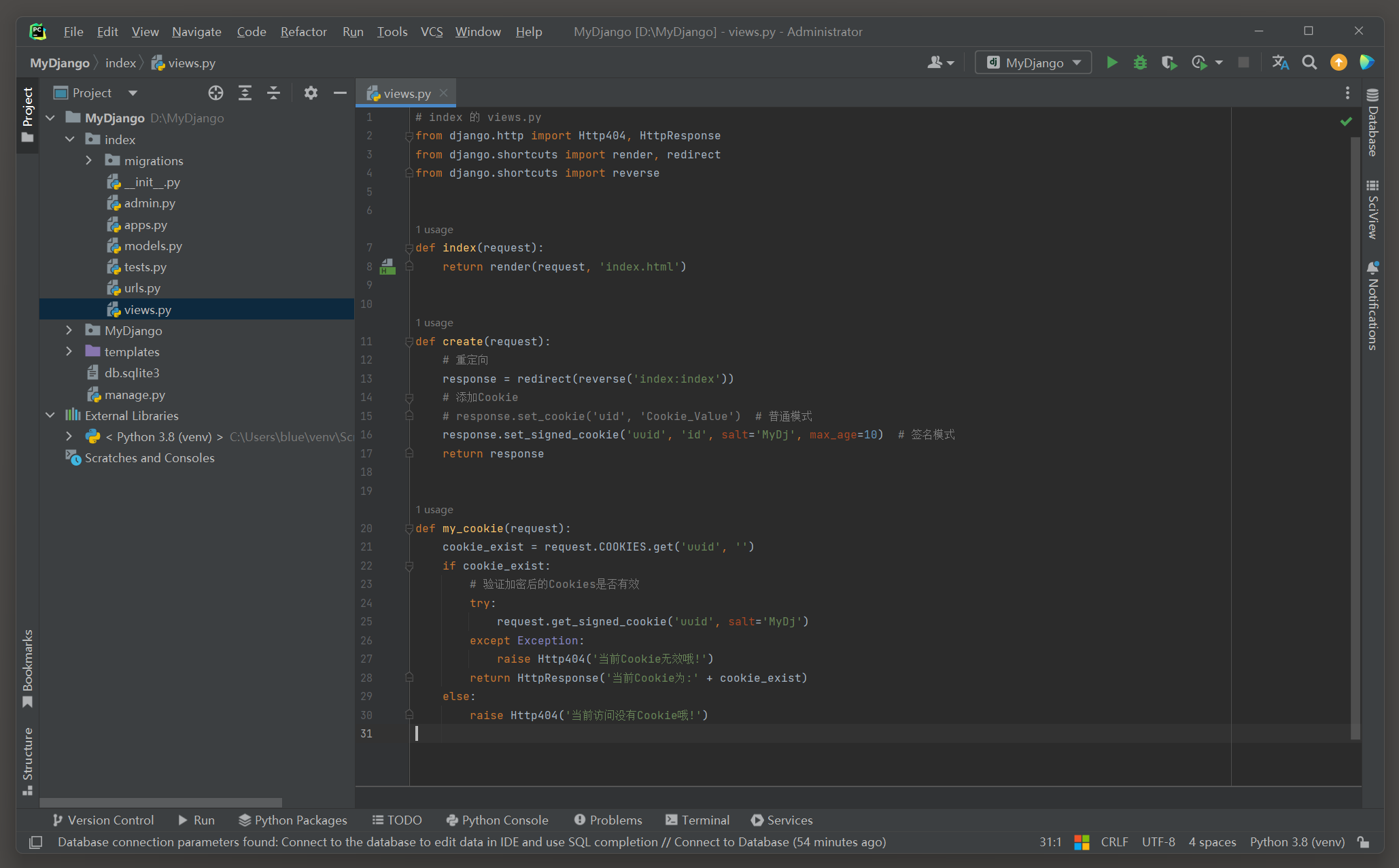
from django. http import Http404, HttpResponse
from django. shortcuts import render, redirect
from django. shortcuts import reverse
def index ( request) :
return render( request, 'index.html' )
def create ( request) :
response = redirect( reverse( 'index:index' ) )
response. set_signed_cookie( 'uuid' , 'id' , salt= 'MyDj' , max_age= 10 )
return response
def my_cookie ( request) :
cookie_exist = request. COOKIES. get( 'uuid' , '' )
if cookie_exist:
try :
request. get_signed_cookie( 'uuid' , salt= 'MyDj' )
except Exception:
raise Http404( '当前Cookie无效哦!' )
return HttpResponse( '当前Cookie为:' + cookie_exist)
else :
raise Http404( '当前访问没有Cookie哦!' )
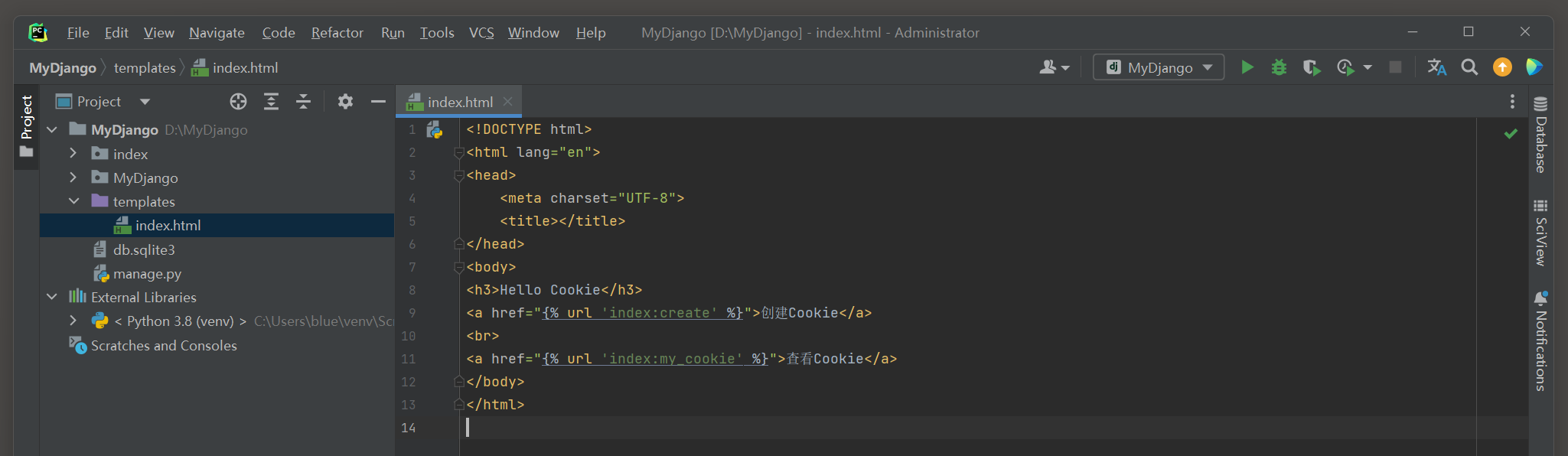
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < body> < h3> </ h3> < ahref = " {% url 'index:create' %}" > </ a> < br> < ahref = " {% url 'index:my_cookie' %}" > </ a> </ body> </ html>
index的urls . py中定义了 3 条路由信息 , 每条路由对应某个视图函数 , 其实现的功能说明如下 :
● 路由index对应视图函数index , 它把模板文件index . html返回并生成相应的网页内容 .
index . html使用模板语法url分别将路由create和myCookie在网页上生成相应的路由地址 .
● 路由create对应视图函数create , 它的响应内容是重定向路由index , 在重定向的过程中 , 使用set_signed_cookie方法添加Cookie信息 .
● 路由myCookie对应视图函数myCookie , 用于判断当前请求是否有特定的Cookie信息 ,
如果没有 , 就抛出 404 异常并提示异常信息 ( 当前访问没有Cookie ) ,
如果有 , 就对Cookie使用get_signed_cookie方法进行解密处理 , 如果解密成功 , 就说明Cookie是正确的 , 并将Cookie信息返回到网页上 ;
否则抛出 404 异常并提示相关的异常信息 ( 当前Cookie无效 ) .
从上述例子可以看出 , 路由my_cookie是我们设置反爬虫机制的页面的路由地址 , 反爬虫机制通常只设定在某些网页上 ,
如果整个网站都设置反爬虫 , 就会影响用户体验 , 因为用户操作过快或操作不当时 ,
网站很容易将真实用户视为爬虫程序 , 从而禁止用户正常访问 .
反爬虫机制的实质是对特定的Cookie进行解密和判断 , 解密过程必须与加密过程相符 ,
然后根据Cookie解密后的数据进行判断 , 主要判断数据是否符合加密前的数据 , 从而执行相应操作 .
总的来说 , Cookie的反爬虫机制是判断特定的Cookie信息是否合理地执行相应的响应操作 .
一般而言 , 网站在生成特定Cookie时 , 都会将这个生成过程隐藏起来 , 从而增加爬虫开发者的破解难度 ,
比如使用前端的AJAX方式或者隐藏请求信息等 .
上述例子是将Cookie的生成过程由路由create实现 , 并且将其响应方式设为重定向 , 从而起到隐藏的作用 .
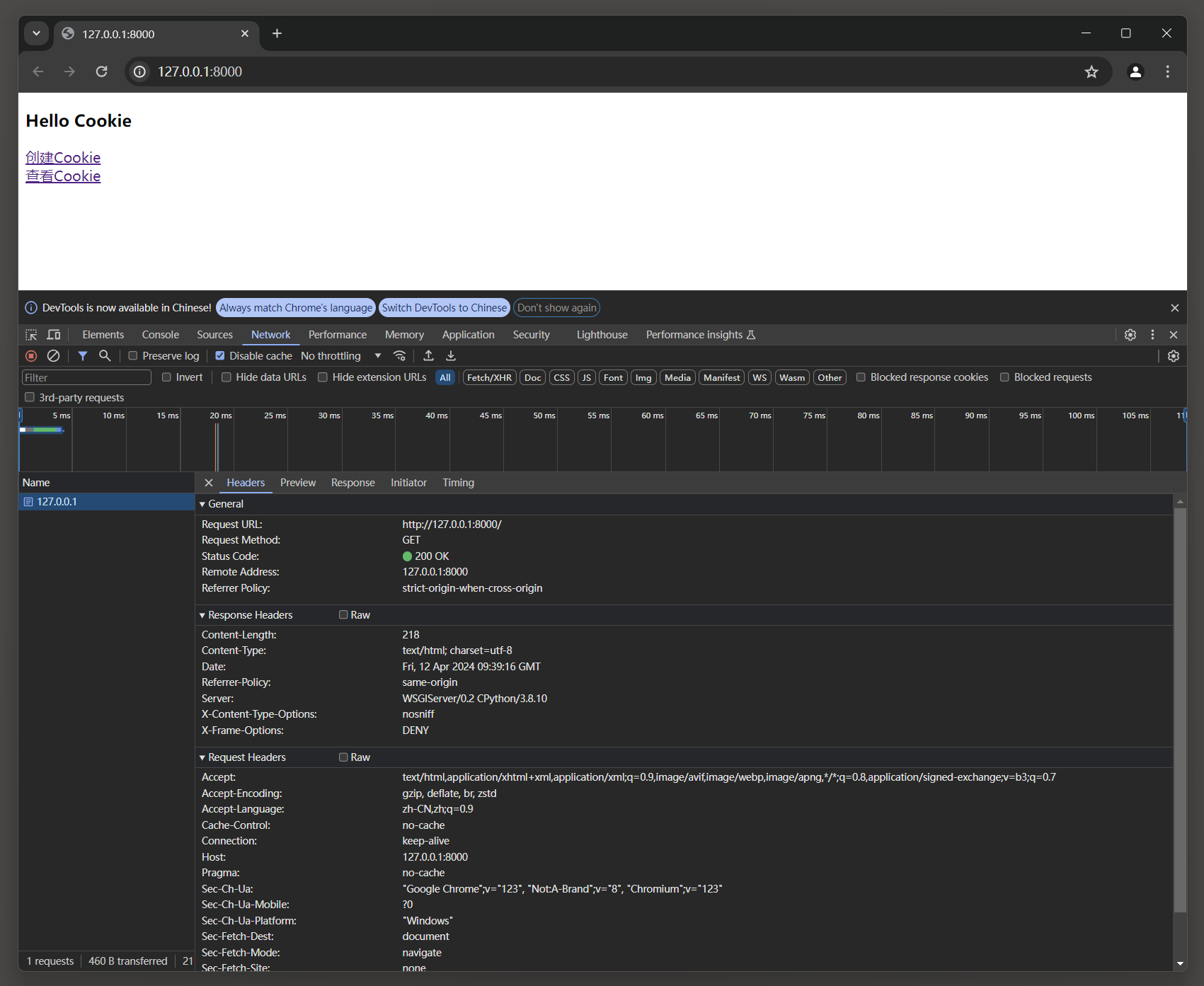
运行MyDjango项目 , 在浏览器中打开开发者工具 , 然后访问 127.0 .0 .1 : 8000 , 在Network查看当前请求信息 , 如图 4 - 27 所示 .
图 4 - 27 请求信息
首次访问MyDjango的首页是没有Cookie信息的 , 若存在Cookie信息 , 则说明曾经访问过路由create , 可在浏览器中删除历史记录 .
接着在网页里单击 '查看Cookie' , 发现网页提示 404 , 并提示 '当前访问没有Cookie哦!' , 如图 4 - 28 所示 .
图 4 - 28 查看Cookie
回到网站首页并单击 '创建Cookie' , 发现网页会自动刷新 ,
但在开发者工具里可以看到两个请求信息 , 查看请求信息create , 发现它已经创建Cookie信息 , 如图 4 - 29 所示 .
图 4 - 29 创建Cookie
10 秒内在点击 '查看Cookit' .
再次在首页单击 '查看Cookie' , 如果在 '创建Cookie' 的操作后 10 秒内 '查看Cookie' , 网页就会显示当前的Cookie信息 ;
如果超出 10 秒 , 就说明Cookie已失效 , 这时单击 '查看Cookie' 将会提示 404 异常 ,
异常信息提示当前访问没有Cookie , 而不是提示当前Cookie无效 , 因为Cookie失效时 ,
在浏览器里触发的HTTP请求是不会将失效的Cookie发送到服务器的 .
只有使用爬虫程序模拟HTTP请求并发送Cookie的时候才会提示当前Cookie无效 .
上述例子使用Django内置的Cookie加密 ( 解密 ) 机制 , 这种内置机制有时难以满足开发需求 ,
为了解决复杂多变的开发需求 , Django允许开发者自定义Cookie加密 ( 解密 ) 机制 .
由于Cookie加密 ( 解密 ) 机制是由源码文件signing . py的TimestampSigner类实现的 ,
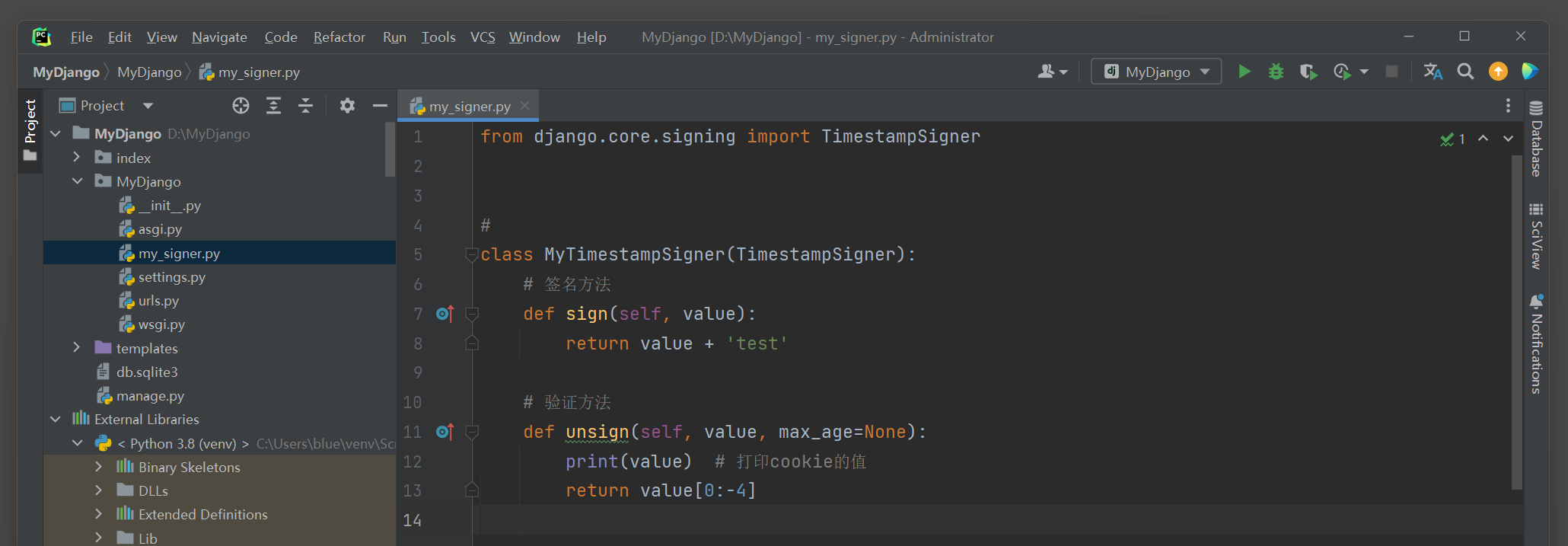
若要自定义Cookie加密 ( 解密 ) 机制 , 则只需定义TimestampSigner的子类并重写sign和unsign方法即可 .
以MyDjango项目为例 , 在MyDjango文件夹里创建mySigner . py文件 ,
然后分别在配置文件settings . py和my_signer . py中编写以下代码即可自定义Cookie加密 ( 解密 ) 机制 :
from django. core. signing import TimestampSigner
class MyTimestampSigner ( TimestampSigner) :
def sign ( self, value) :
return value + 'test'
def unsign ( self, value, max_age= None ) :
print ( value)
return value[ 0 : - 4 ]
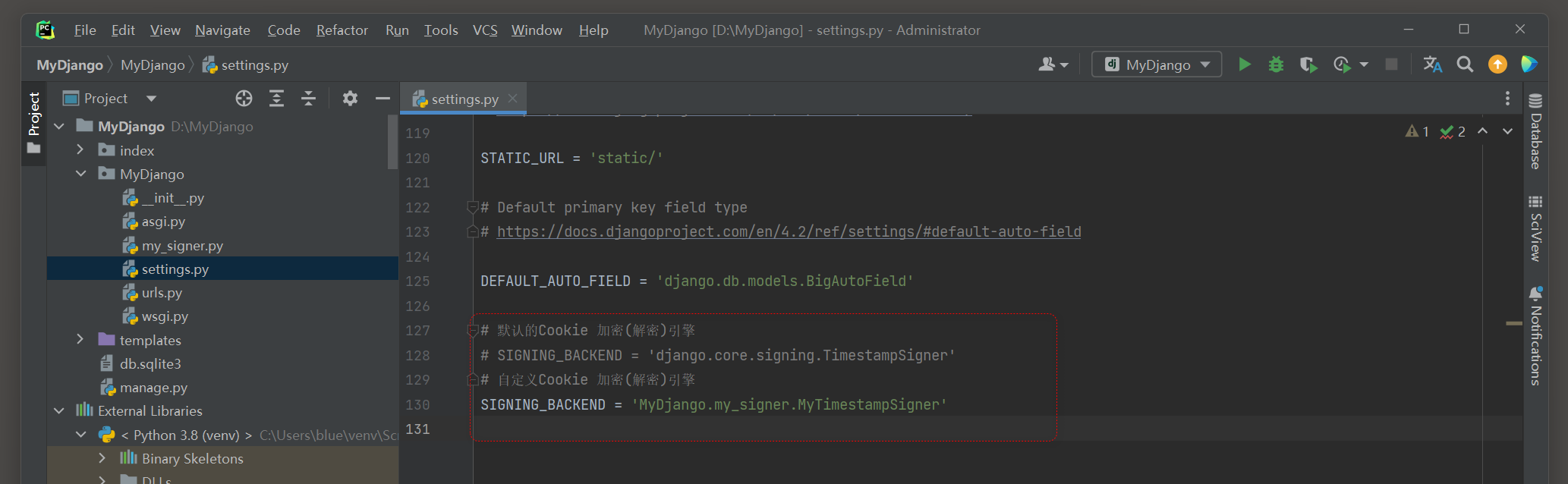
SIGNING_BACKEND = 'MyDjango.my_signer.MyTimestampSigner'
上述代码可以看出 , 配置文件settings . py中设置了配置属性SIGNING_BACKEND ,
属性值指向MyDjango的mySigner . py所定义的myTimestampSigner类 ,
而myTimestampSigner类继承TimestampSigner并重写sign和unsign方法 .
当Django执行Cookie加密 ( 解密 ) 处理时 , 它首先在settings . py中查找是否设有配置属性SIGNING_BACKEND ,
若已设有配置属性 , 则由该配置属性的属性值来完成Cookie加密 ( 解密 ) 处理 ;
否则由源码文件signing . py的TimestampSigner类完成Cookie加密 ( 解密 ) 处理 .
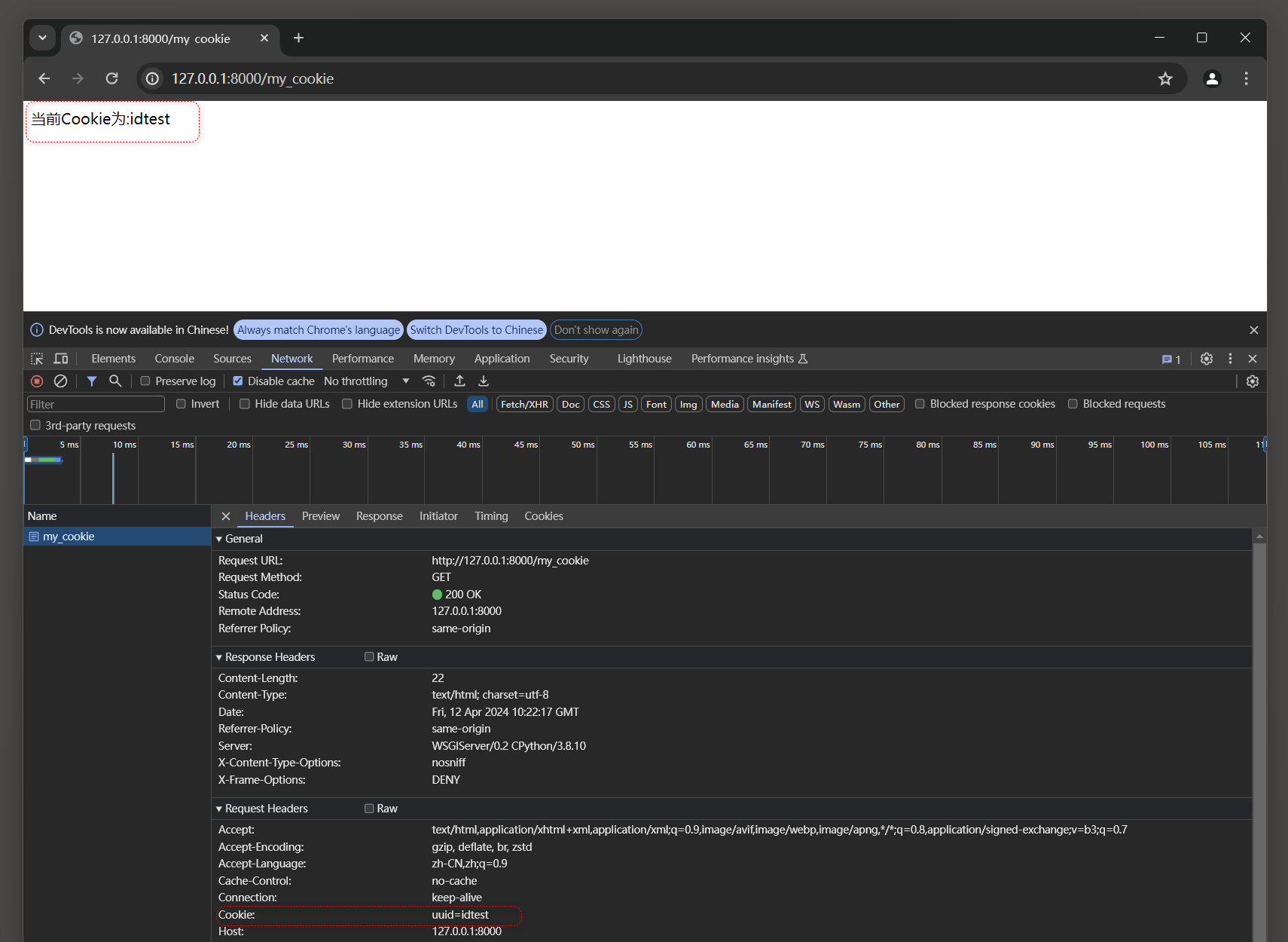
运行MyDjango项目 , 在浏览器上打开开发者工具并访问 : 127.0 .0 .1 : 8000 首页 ,
1. 点击 '创建Cookie'
2. 点击 '查看Cookie' .
在开发者工具中查看 127.0 .0 .1 请求的Cookie信息 , 可以发现Cookie的加密处理是由自定义的myTimestampSigner类执行的 , 如图 4 - 30 所示 .
我们知道 , 视图的参数request是由类WSGIRequest根据用户请求而生成的实例化对象 .
由于类WSGIRequest是继承并重写类HttpRequest , 而类HttpRequest设置META属性 ,
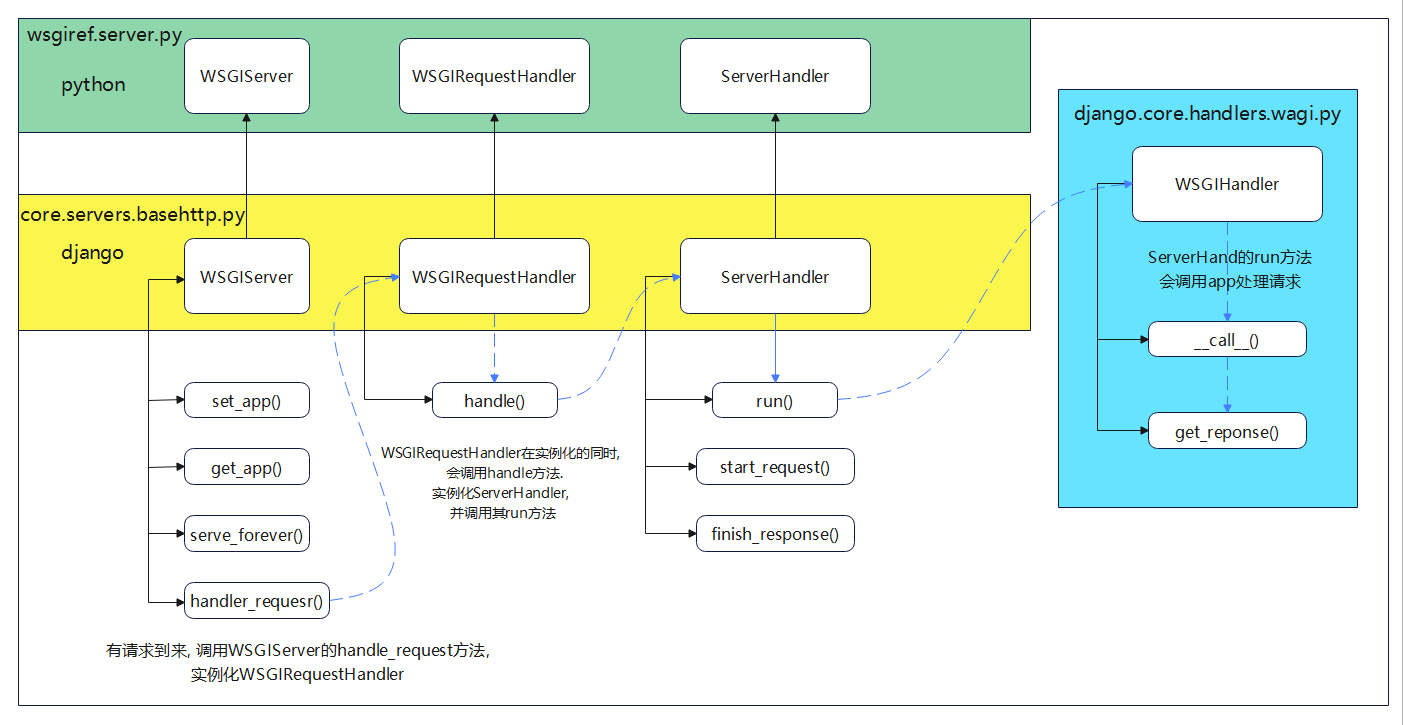
因此当用户在浏览器中访问Django时 , 会由WSGI协议实现两者的通信 ,
浏览器的请求头信息来自类WSGIRequest的属性environ , 而属性environ来自类WSGIHandler .
总的来说 , 属性environ经过类WSGIHandler传递给类WSGIRequest , 如图 4 - 31 所示 .
Django处理用户请求的流程 :
* 1. 用户发起HTTP请求 : 用户在浏览器中输入URL并按下回车 , 浏览器会发起一个HTTP请求到目标Web服务器 .
* 2. Web服务器接收请求 : Web服务器 ( 如Gunicorn , uWSGI等 ) 接收到用户的HTTP请求 .
* 3. WSGIHandler介入 : Web服务器使用WSGI ( Web Server Gateway Interface ) 协议来与Django通信 .
Django的WSGIHandler类作为WSGI应用程序的入口点 , 接收来自Web服务器的请求 .
* 4. 解析请求并准备环境 : WSGIHandler解析HTTP请求 , 提取请求头 , 请求体等信息 .
它创建一个包含请求相关信息的环境 ( environ ) , 这个环境是一个字典 , 包含了所有必要的变量和值 .
* 5. 创建WSGIRequest实例 : 使用解析后的环境信息 , Django创建一个WSGIRequest实例 .
WSGIRequest是Django中用于表示HTTP请求的特殊类 , 它继承自HttpRequest并添加了与WSGI相关的功能 .
* 6. 传递请求给视图 : Django根据请求的URL确定应该调用哪个视图函数或类视图来处理该请求 .
WSGIRequest实例被传递给相应的视图函数或类视图 , 作为第一个参数 ( 通常命名为request ) .
* 7. 视图处理请求 : 视图函数或类视图接收request对象 , 并从中提取所需的信息 ( 如请求方法 , 路径 , 参数 , 请求头等 ) .
图 4 - 31 请求头信息
上述提及的WSGI协议是一种描述服务器如何与浏览器通信的规范 .
Django的运行原理是在此规范上建立的 , 其运行原理如图 4 - 32 所示 .
大致了解Django的运行原理后 , 我们得知HTTP的请求头信息来自属性environ ,
请求头信息是动态变化的 , 它可以自定义属性 , 因此常用于制定反爬虫机制 .
请求头信息只能由浏览器进行设置 , 服务器只能读取请求头信息 , 通过请求头实现的反爬虫机制一般需要借助前端的AJAX实现 .
图 4 - 32 Django的运行原理
以MyDjango为例 , 在index文件夹里创建static文件夹 , 并在static文件夹里放置jquery . js脚本文件 ,
这时在模板文件index . html中使用jQuery实现AJAX发送HTTP请求 .
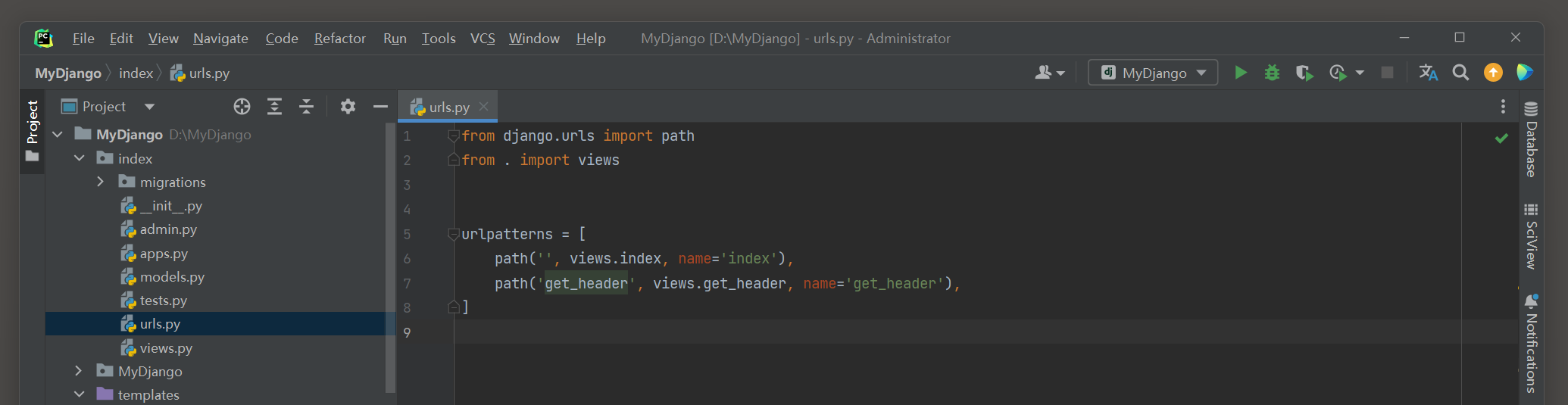
然后在index的urls . py , views . py和模板文件index . html中编写以下代码 :
from django. urls import path
from . import views
urlpatterns = [
path( '' , views. index, name= 'index' ) ,
path( 'get_header' , views. get_header, name= 'get_header' ) ,
]
from django. http import JsonResponse
from django. shortcuts import render
def index ( request) :
return render( request, 'index.html' )
def get_header ( request) :
header = request. META. get( 'HTTP_SIGN' , '' )
if header:
value = { 'header' : header}
else :
value = { 'header' : 'null' }
return JsonResponse( value)
文件中就不下下载jquery了 , 使用百度的CDN地址 , 配套资源中会上传jquery文件 .
<! DOCTYPE html > < htmllang = " en" > < head> < metacharset = " UTF-8" > < title> </ title> </ head> < scriptsrc = " {% static 'jquery.js' %}" > </ script> < scriptsrc = " http://libs.baidu.com/jquery/2.0.0/jquery.min.js" > </ script> < script>
$ ( function ( ) {
$ ( '#bt01' ) . click (
function ( ) {
var value = $. ajax ( {
type : 'GET' ,
url : '/get_header' ,
dataType : 'json' ,
async : false ,
headers : {
'sign' : '123' ,
}
} ) . responseJSON;
{ # 出发AJAX , 获取视图函数get_hander的数据 #}
value = '<h2>' + value[ 'header' ] + '</h2>'
$ ( '#my_div' ) . html ( value) ;
} ) ;
} ) ;
</ script> < body> < h3> </ h3> < divid = " my_div" > < h2> </ h2> </ div> < buttonid = " bt01" type = " button" > </ button> </ body> </ html>
视图函数getHeader判断请求头的自定义属性sign是否存在 , 若存在 , 则将该属性值返回网页 , 否则返回null .
Django获取请求头是有固定格式的 , 必须为 'HTTP_XXX' , 其中XXX代表请求头的某个属性 , 必须为大写字母 .
上述的例子中 , 请求头属性sign设置为 123 , 一般情况下 , 自定义请求头必须有一套完整的加密 ( 解密 ) 机制 ,
前端的AJAX负责数据加密 , 服务器后台负责数据解密 , 从而提高爬虫开发者的破解难度 .
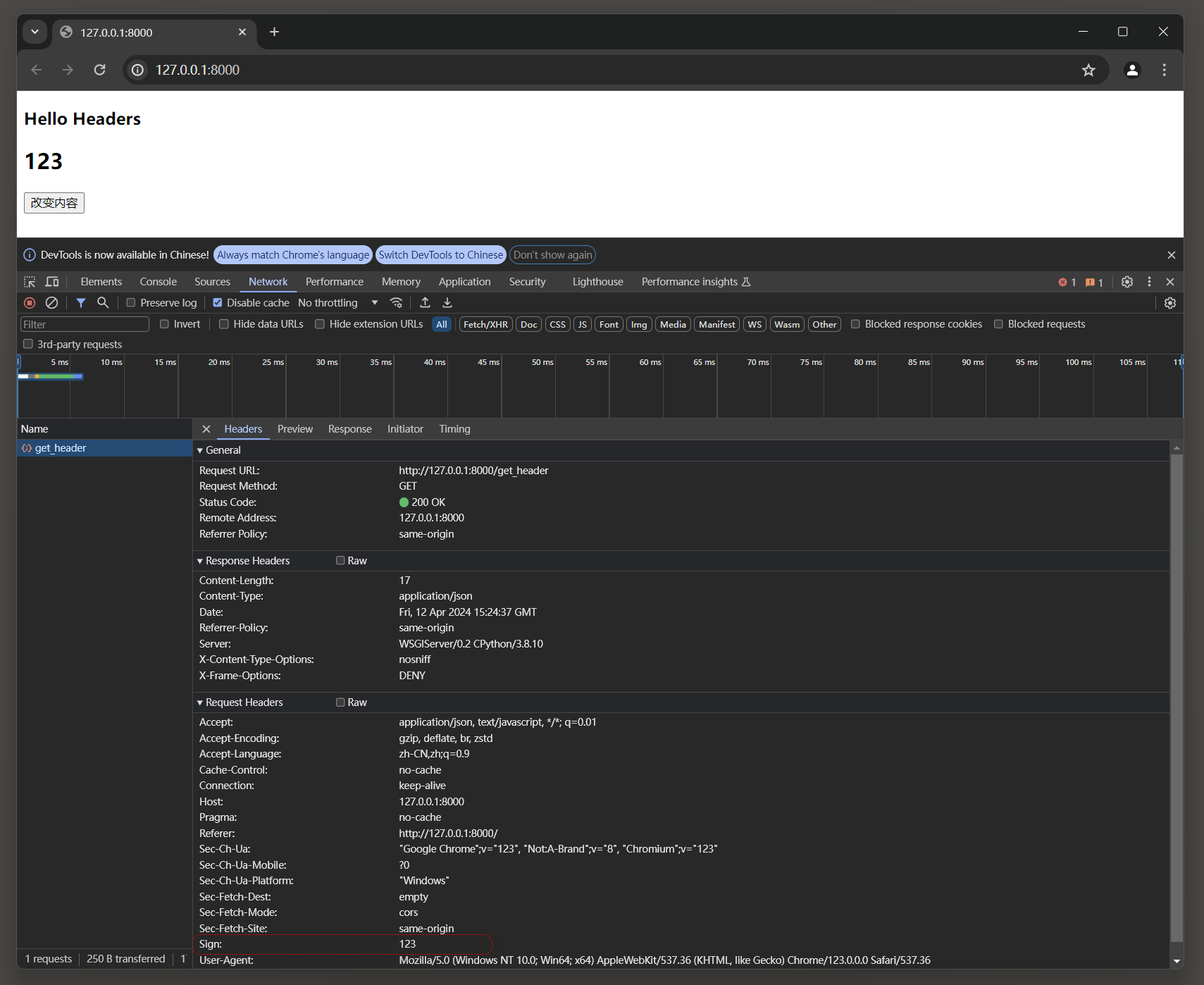
运行MyDjango项目 , 在浏览器里打开开发者工具 , 然后访问 : 127.0 .0 .1 : 8000 并单击 '改变内容' 按钮 ,
在开发者工具的Network选项卡可以看到AJAX的请求信息 , 如图 4 - 33 所示 .
图 4 - 33 AJAX的请求信息
从图 4 - 33 可以看到 , AJAX的请求信息是向视图函数getHeader发送GET请求 ,
而视图函数getHeader从请求信息里获取请求头属性sign , 通过判断其属性值是否正确来返回相应的JSON数据 .
视图 ( Views ) 是Django的MTV架构模式的V部分 , 主要负责处理用户请求和生成相应的响应内容 , 然后在页面或其他类型的文档中显示 .
也可以理解为视图是MVC架构里面的C部分 ( 控制器 ) , 主要处理功能和业务上的逻辑 .
我们习惯使用视图函数处理HTTP请求 , 即在视图里定义def函数 , 这种方式称为FBV .
render的参数request和template_name是必需参数 , 其余的参数是可选参数 .
各个参数说明如下 :
● request : 浏览器向服务器发送的请求对象 , 包含用户信息 , 请求内容和请求方式等 .
● template_name : 设置模板文件名 , 用于生成网页内容 .
● context : 对模板上下文 ( 模板变量 ) 赋值 , 以字典形式表示 , 默认情况下是一个空字典 .
● content_type : 响应内容的数据格式 , 一般情况下使用默认值即可 .
● status : HTTP状态码 , 默认为 200.
● using : 设置模板引擎 , 用于解析模板文件 , 生成网页内容 .
从函数redirect的定义过程可以看出 , 该函数的运行原理如下 :
● 判断参数permanent的真假性来选择重定向的函数 .
若参数permanent为True , 则调用HttpResponsePermanentRedirect来完成重定向过程 ;
若为False , 则调用HttpResponseRedirect .
● 由于HttpResponseRedirect和HttpResponsePermanentRedirect只支持路由地址的传入 ,
因此函数redirect调用resolve_url方法对参数to进行判断 .
若参数to是路由地址 , 则直接将参数to的参数值返回 ;
若参数to是路由命名 , 则使用reverse函数转换路由地址 ;
若参数to是模型对象 , 则将模型转换为相应的路由地址 ( 这种方法的使用频率相对较低 ) .
异常响应是指HTTP状态码为 404 或 500 的响应状态 , 它与正常的响应过程 ( HTTP状态码为 200 的响应过程 ) 是一样的 ,
只是HTTP状态码有所不同 , 因此使用函数render作为响应过程 , 并且设置参数status的状态码 ( 404 或 500 ) 即可实现异常响应 .
从请求方式里获取请求信息 , 只需从类WSGIRequest读取相关的类属性即可 .
下面对一些常用的属性进行说明 .
● COOKIE : 获取客户端 ( 浏览器 ) 的Cookie信息 , 以字典形式表示 , 并且键值对都是字符串类型的 .
● FILES : django . http . request . QueryDict对象 , 包含所有的文件上传信息 .
● GET : 获取GET请求的请求参数 , 它是django . http . request . QueryDict对象 , 操作起来类似于字典 .
● POST : 获取POST请求的请求参数 , 它是django . http . request . QueryDict对象 , 操作起来类似于字典 .
● META : 获取客户端 ( 浏览器 ) 的请求头信息 , 以字典形式存储 .
● method : 获取当前请求的请求方式 ( GET请求或POST请求 ) .
● path : 获取当前请求的路由地址 .
● session : 一个类似于字典的对象 , 用来操作服务器的会话信息 , 可临时存放用户信息 .
● user : 当Django启用AuthenticationMiddleware中间件时才可用 .
它的值是内置数据模型User的对象 , 表示当前登录的用户 .
如果用户当前没有登录 , 那么user将设为django . contrib . auth . models . AnonymousUser的一个实例 .
文件上传功能是由Django的源码文件uploadedfile . py实现的 , 它定义了 4 个功能类 , 每个类所实现的功能说明如下 :
● UploadedFile : 文件上传的基本功能类 , 继承父类File , 主要获取文件的文件名 , 大小和类型等基本信息 .
● TemporaryUploadedFile : 将文件数据临时存放在服务器所指定的文件夹里 , 适用于大文件的上传 .
● InMemoryUploadedFile : 将文件数据存放在服务器的内存里 , 适用于小文件的上传 .
● SimpleUploadedFile : 将文件的文件名 , 大小和类型生成字典格式 .
Cookie的反爬虫机制的实质是对特定的Cookie进行解密和判断 , 解密过程必须与加密过程相符 , 然后根据Cookie解密后的数据进行判断 ,
主要判断数据是否符合加密前的数据 , 从而执行相应的操作 .
总的来说 , Cookie的反爬虫机制是判断特定的Cookie信息是否合理地执行相应的响应操作 .
Django获取请求头是有固定格式的 , 必须为 'HTTP_XXX' , 其中XXX代表请求头的某个属性 , 而且必须为大写字母 .
一般情况下 , 自定义请求头必须有一套完整的加密 ( 解密 ) 机制 ,
前端的AJAX负责数据加密 , 服务器后台负责数据解密 , 从而提高爬虫开发者的破解难度 .