文章目录
- 前言
- 一、简介
- 1.1 need_resched标志
- 1.2 try_to_wake_up
- 二、抢占调度
- 2.1 抢占简介
- 2.2 用户态抢占
- 2.2.1 从系统调用返回用户空间
- 2.2.2 从中断返回用户空间
- 2.3 内核态抢占
- 2.2.1 preempt_count
- 2.2.2 调用preempt_enable()
- 2.2.3 从中断返回内核空间时
- 总结
- 参考资料
前言
在这片文章说了进程进入阻塞态,主动发起调度,也就是主调度器:Linux 进程调度之schdule主调度器,接下来这篇文章描述抢占调度。
一、简介
1.1 need_resched标志
抢占调度指的是一个高优先级进程是否可以强行夺取低优先级进程的处理器资源。如果可以强行夺取,就是可抢占的调度。
内核使用 need_resched标志(TIF_NEED_RESCHED ) 来表明是否需要重新执行一次调度,该标志对于内核来说表明有其他进程应当被运行了,要尽快调用调度程序__schedule()。
每个进程都包含一个need_resched标志:
struct task_struct {
#ifdef CONFIG_THREAD_INFO_IN_TASK
/*
* For reasons of header soup (see current_thread_info()), this
* must be the first element of task_struct.
*/
struct thread_info thread_info;
}
#define TIF_NEED_RESCHED 3 /* rescheduling necessary */
struct thread_info {
unsigned long flags; /* low level flags */
};
当某个进程应该被抢占时,周期性调度器scheduler_tick()会设置这个标志位。
当一个优先级高的进程进入可执行状态的时候,try_to_wake_up()会设置这个标志位。
注意周期性调度器scheduler_tick()和 try_to_wake_up()设置TIF_NEED_RESCHED标志来对进程进行标记需要被抢占,设置该位则表明需要进行调度切换,没有进行实际的抢占,只是将当前进程标记为应该被抢占。而实际的切换将在抢占执行点来完成。
抢占式调度有两种场景:
(1)scheduler_tick()
周期性调度器scheduler_tick()以固定的频率检测是否有必要进行进程调度和切换。在CFS调度类中,scheduler_tick会检测一个进程执行的时间是否过长,以避免过程的延时,是时候让其他CFS就绪队列中的进程运行,这里不讨论周期性调度器scheduler_tick()。
(2)try_to_wake_up()
当一个进程在等待一个 I/O 的时候,会主动放弃 CPU,加入到等待队列中。但是当 I/O 到来的时候,进程往往会被唤醒,当处于等待队列中的这个进程被唤醒的时候,这个时候是一个抢占的时机。当被唤醒的进程优先级高于 CPU 上的当前进程,就会触发抢占。
内核中用于访问和操作need_resched标志的函数:
static inline void set_tsk_need_resched(struct task_struct *tsk)
{
set_tsk_thread_flag(tsk,TIF_NEED_RESCHED);
}
static inline void clear_tsk_need_resched(struct task_struct *tsk)
{
clear_tsk_thread_flag(tsk,TIF_NEED_RESCHED);
}
static inline int test_tsk_need_resched(struct task_struct *tsk)
{
return unlikely(test_tsk_thread_flag(tsk,TIF_NEED_RESCHED));
}
static __always_inline bool need_resched(void)
{
return unlikely(tif_need_resched());
}
#define tif_need_resched() test_thread_flag(TIF_NEED_RESCHED)
#define test_thread_flag(flag) \
test_ti_thread_flag(current_thread_info(), flag)
| 函数 | 功能 |
|---|---|
| set_tsk_need_resched | 设置指定进程的struct thread_info的 flags为need_resched标志:TIF_NEED_RESCHED |
| clear_tsk_need_resched | 清除指定进程的struct thread_info的 flags为need_resched标志:TIF_NEED_RESCHED |
| test_tsk_need_resched 、need_resched | 判断进程的 struct thread_info的 flags 是否为need_resched标志:TIF_NEED_RESCHED |
1.2 try_to_wake_up
try_to_wake_up() 调用 ttwu_queue 将这个唤醒的任务添加到队列当中。ttwu_queue 中调用 ttwu_do_activate 激活这个任务。ttwu_do_activate 调用 ttwu_do_wakeup。这里面调用了 check_preempt_curr 检查是否应该发生抢占。如果应该发生抢占,也不是直接发生调度,切换当前正在运行的进程,而是将当前进程标记为应该被抢占。这里只是标识当前运行中的进程应该被抢占了,该轮到其他的进程运行了,但是真正的抢占动作并没有发生。
如下所示:
/**
* try_to_wake_up - wake up a thread
* @p: the thread to be awakened
* @state: the mask of task states that can be woken
* @wake_flags: wake modifier flags (WF_*)
*
* Put it on the run-queue if it's not already there. The "current"
* thread is always on the run-queue (except when the actual
* re-schedule is in progress), and as such you're allowed to do
* the simpler "current->state = TASK_RUNNING" to mark yourself
* runnable without the overhead of this.
*
* Returns %true if @p was woken up, %false if it was already running
* or @state didn't match @p's state.
*/
static int
try_to_wake_up(struct task_struct *p, unsigned int state, int wake_flags)
{
unsigned long flags;
int cpu, success = 0;
#ifdef CONFIG_SMP
//给唤醒的进程选择一个合适的处理器
cpu = select_task_rq(p, SD_BALANCE_WAKE, wake_flags);
if (task_cpu(p) != cpu) {
wake_flags |= WF_MIGRATED;
set_task_cpu(p, cpu);
}
#endif /* CONFIG_SMP */
//将唤醒的进程加入到CFS就绪队列中
ttwu_queue(p, cpu);
return success;
}
ttwu_queue将唤醒的进程加入到CFS就绪队列中:
static void ttwu_queue(struct task_struct *p, int cpu)
{
struct rq *rq = cpu_rq(cpu);
raw_spin_lock(&rq->lock);
ttwu_do_activate(rq, p, 0);
raw_spin_unlock(&rq->lock);
}
static void
ttwu_do_activate(struct rq *rq, struct task_struct *p, int wake_flags)
{
(1)
//将唤醒的进程加入CFS就绪队列中,也就是将进程调度实体加入红黑树中
ttwu_activate(rq, p, ENQUEUE_WAKEUP | ENQUEUE_WAKING);
(2)
//检查唤醒的进程是否应该发生抢占
ttwu_do_wakeup(rq, p, wake_flags);
}
(1) ttwu_activate
ttwu_activate将唤醒的进程加入CFS就绪队列中,也就是将进程调度实体加入红黑树中
static void ttwu_activate(struct rq *rq, struct task_struct *p, int en_flags)
{
activate_task(rq, p, en_flags);
}
static void enqueue_task(struct rq *rq, struct task_struct *p, int flags)
{
p->sched_class->enqueue_task(rq, p, flags);
}
void activate_task(struct rq *rq, struct task_struct *p, int flags)
{
enqueue_task(rq, p, flags);
}
/*
* The enqueue_task method is called before nr_running is
* increased. Here we update the fair scheduling stats and
* then put the task into the rbtree:
*/
static void
enqueue_task_fair(struct rq *rq, struct task_struct *p, int flags)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se;
for_each_sched_entity(se) {
if (se->on_rq)
break;
cfs_rq = cfs_rq_of(se);
//将唤醒的进程调度实体加入CFS就绪队列中
enqueue_entity(cfs_rq, se, flags);
}
}
/*
* All the scheduling class methods:
*/
const struct sched_class fair_sched_class = {
.enqueue_task = enqueue_task_fair,
};
#define ENQUEUE_WAKEUP 1
struct sched_class {
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
};
extern const struct sched_class fair_sched_class;
(2)ttwu_do_wakeup
/*
* Mark the task runnable and perform wakeup-preemption.
*/
static void
ttwu_do_wakeup(struct rq *rq, struct task_struct *p, int wake_flags)
{
//调用了 check_preempt_curr 检查是否应该发生抢占
check_preempt_curr(rq, p, wake_flags);
trace_sched_wakeup(p, true);
p->state = TASK_RUNNING;
}
void check_preempt_curr(struct rq *rq, struct task_struct *p, int flags)
{
const struct sched_class *class;
if (p->sched_class == rq->curr->sched_class) {
rq->curr->sched_class->check_preempt_curr(rq, p, flags);
}
}
/*
* All the scheduling class methods:
*/
const struct sched_class fair_sched_class = {
.check_preempt_curr = check_preempt_wakeup,
}
这里面调用了 check_preempt_curr(check_preempt_wakeup) 检查唤醒的进程是否应该发生抢占,抢占正在当前处理器运行的进程:rq->curr。如果应该发生抢占,也不是直接踢走当前进程,而是将当前进程标记为应该被抢占。
/*
* Preempt the current task with a newly woken task if needed:
*/
static void check_preempt_wakeup(struct rq *rq, struct task_struct *p, int wake_flags)
{
(1)
//获取当前处理器运行队列正在运行的进程:rq->curr
struct task_struct *curr = rq->curr;
(2)
//获取当前处理器运行队列正在运行的进程调度实体:&curr->se
//获取唤醒进程的调度实体&p->se
struct sched_entity *se = &curr->se, *pse = &p->se;
struct cfs_rq *cfs_rq = task_cfs_rq(curr);
int scale = cfs_rq->nr_running >= sched_nr_latency;
/*
* We can come here with TIF_NEED_RESCHED already set from new task
* wake up path.
*
* Note: this also catches the edge-case of curr being in a throttled
* group (e.g. via set_curr_task), since update_curr() (in the
* enqueue of curr) will have resulted in resched being set. This
* prevents us from potentially nominating it as a false LAST_BUDDY
* below.
*/
if (test_tsk_need_resched(curr))
return;
(3)
//如果当前任务是空闲进程,那么唤醒的进程就应该发起抢占,因为空闲进程的优先级最低
/* Idle tasks are by definition preempted by non-idle tasks. */
if (unlikely(curr->policy == SCHED_IDLE) &&
likely(p->policy != SCHED_IDLE))
goto preempt;
/*
* Batch and idle tasks do not preempt non-idle tasks (their preemption
* is driven by the tick):
*/
if (unlikely(p->policy != SCHED_NORMAL) || !sched_feat(WAKEUP_PREEMPTION))
return;
//与任务调度组有关:CONFIG_FAIR_GROUP_SCHED
find_matching_se(&se, &pse);
(4)
//更行当前处理器正在运行进程的 vruntime
update_curr(cfs_rq_of(se));
BUG_ON(!pse);
(5)
//调用wakeup_preempt_entity判断唤醒的进程是否发生抢占
if (wakeup_preempt_entity(se, pse) == 1) {
/*
* Bias pick_next to pick the sched entity that is
* triggering this preemption.
*/
if (!next_buddy_marked)
set_next_buddy(pse);
//唤醒的进程应该发起抢占
goto preempt;
}
return;
(6)
//将当前进程标记为应该被抢占
preempt:
resched_task(curr);
/*
* Only set the backward buddy when the current task is still
* on the rq. This can happen when a wakeup gets interleaved
* with schedule on the ->pre_schedule() or idle_balance()
* point, either of which can * drop the rq lock.
*
* Also, during early boot the idle thread is in the fair class,
* for obvious reasons its a bad idea to schedule back to it.
*/
if (unlikely(!se->on_rq || curr == rq->idle))
return;
if (sched_feat(LAST_BUDDY) && scale && entity_is_task(se))
set_last_buddy(se);
}
(1)获取当前处理器运行队列正在运行的进程:rq->curr
(2)获取当前处理器运行队列正在运行的进程调度实体:&curr->se,获取唤醒进程的调度实体&p->se
(3)如果当前任务是空闲进程,那么唤醒的进程就应该发起抢占,因为空闲进程的优先级最低
(4)更新当前处理器正在运行进程的 vruntime
(5) 调用wakeup_preempt_entity判断唤醒的进程是否发生抢占
这里调用wakeup_preempt_entity函数计算是否将当前正在运行的进程标记为应该被抢占时,如果当前处理器正在运行的进程的 vruntime 大于唤醒进程的 vruntime,不是直接就确定将当前正在运行的进程标记为应该被抢占,而是增加了一个时间缓冲,如果唤醒的进程 vruntime 加上进程最小运行时间(sysctl_sched_wakeup_granularity = 1ms转化为虚拟时间)仍然小于当前处理器正在运行的进程的 vruntime,那么就确定当前处理器正在运行的进程应该被抢占,增加一个时间缓冲避免进程切换过于频繁,花费过多的时间再上下文切换中。
(6)如果计算出当前进程应该被抢占,那么调用resched_task将当前进程标记为应该被抢占,请求重新调度。
注意这里只是当前进程标记为应该被抢占,请求重新调度,但是真正的抢占动作并没有发生。
resched_task将进程的struct thread_info的flags成员设置为:TIF_NEED_RESCHED。
/*
* resched_task - mark a task 'to be rescheduled now'.
*
* On UP this means the setting of the need_resched flag, on SMP it
* might also involve a cross-CPU call to trigger the scheduler on
* the target CPU.
*/
#ifdef CONFIG_SMP
void resched_task(struct task_struct *p)
{
if (test_tsk_need_resched(p))
return;
set_tsk_need_resched(p);
}
static inline void set_tsk_need_resched(struct task_struct *tsk)
{
set_tsk_thread_flag(tsk,TIF_NEED_RESCHED);
}
/* set thread flags in other task's structures
* - see asm/thread_info.h for TIF_xxxx flags available
*/
static inline void set_tsk_thread_flag(struct task_struct *tsk, int flag)
{
set_ti_thread_flag(task_thread_info(tsk), flag);
}
/*
* flag set/clear/test wrappers
* - pass TIF_xxxx constants to these functions
*/
static inline void set_ti_thread_flag(struct thread_info *ti, int flag)
{
set_bit(flag, (unsigned long *)&ti->flags);
}
/*
* thread information flags
* - these are process state flags that various assembly files
* may need to access
* - pending work-to-be-done flags are in LSW
* - other flags in MSW
* Warning: layout of LSW is hardcoded in entry.S
*/
#define TIF_NEED_RESCHED 3 /* rescheduling necessary */
struct thread_info {
__u32 flags; /* low level flags */
};
抢占的时机:真正的抢占还需要时机,也就是需要那么一个时刻,让正在运行中的进程有机会调用 __schedule。抢占的时机主要分为用户态抢占时机和内核态抢占时间。
二、抢占调度
2.1 抢占简介
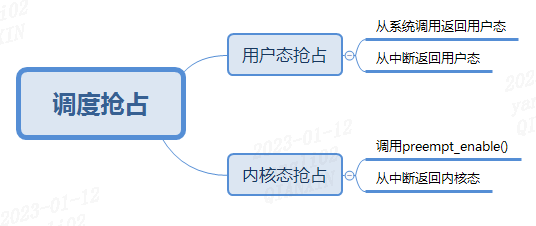
抢占分为用户态抢占和内核态抢占:
用户态抢占:Linux-2.4以及更早版本的内核的调度器只允许用户态抢占,指的是当某个进程运行在用户态时,一个更高优先级的进程可以抢占该进程的时间片。然而,内核不可能随时随地检测是否有更高优先级的进程产生,而是在特定的时间点检测,这些时间点不妨称为检查点(CheckPoint)。对于用户态抢占,其检查点是“异常、中断或者系统调用处理完成后返回用户态的时候”。允许用户态抢占是现代操作系统内核设计的底线,Linux内核配置选项中的“不抢占”(CONFIG_PREEMPT_NONE)实际上指的是用户态抢占。
内核态抢占:Linux-2.6以及更新版本的内核的调度器允许内核态抢占,指的是某个进程不管是运行在用户态还是内核态,一个更高优先级的进程都可以抢占该进程的时间片。同样,随时随地的检查是不可能的,允许内核态抢占无非是在用户态抢占的基础上,又增加了更多的抢占检查点而已。一般来说,内核态抢占的检查点是“异常、中断或者系统调用处理完成后返回的时候”。请注意,异常中断或系统调用处理完成后,既可以返回到内核态,也可以返回到用户态,因此内核态抢占是用户态抢占的超集。
2.2 用户态抢占
用户态的抢占时机:
(1)从系统调用返回用户空间时
(2)从中断返回用户空间时
2.2.1 从系统调用返回用户空间
x86_64 位的系统调用的链路: do_syscall_64->syscall_return_slowpath->prepare_exit_to_usermode->exit_to_usermode_loop
在exit_to_usermode_loop中,如果设置了_TIF_NEED_RESCHED,调用 schedule 进行调度:
// linux-4.10.1/arch/x86/entry/common.c
static void exit_to_usermode_loop(struct pt_regs *regs, u32 cached_flags)
{
while (true) {
/* We have work to do. */
local_irq_enable();
if (cached_flags & _TIF_NEED_RESCHED)
schedule();
/* Disable IRQs and retry */
local_irq_disable();
}
}
对于ARM64,ARMv8有4个Exception Level:EL0,EL1,EL2,EL3,其中用户程序运行在EL0,内核运行在EL1。ARM64提供一个系统调用指令SVC,应用程序调用系统调用指令SVC时,处理器触发一个异常从EL0陷入到EL1,将会跳到ENTRY(vectors)向量表处开始执行:
// linux-4.10.1/arch/arm64/kernel/entry.S
ENTRY(vectors)
-->ventry el0_sync // Synchronous 64-bit EL0
-->el0_svc
-->ret_fast_syscall
-->do_notify_resume
在do_notify_resume中,如果设置了_TIF_NEED_RESCHED,调用 schedule 进行调度:
// linux-4.10.1/arch/arm64/kernel/signal.c
asmlinkage void do_notify_resume(struct pt_regs *regs,
unsigned int thread_flags)
{
/*
* The assembly code enters us with IRQs off, but it hasn't
* informed the tracing code of that for efficiency reasons.
* Update the trace code with the current status.
*/
trace_hardirqs_off();
do {
if (thread_flags & _TIF_NEED_RESCHED) {
schedule();
}
} while (thread_flags & _TIF_WORK_MASK);
}
2.2.2 从中断返回用户空间
对于x86_64,中断处理调用的是 do_IRQ 函数,中断完毕后分为两种情况,一个是返回用户态,一个是返回内核态。
retint_user 会调用 prepare_exit_to_usermode,prepare_exit_to_usermode调用 exit_to_usermode_loop,在exit_to_usermode_loop中,如果设置了_TIF_NEED_RESCHED,调用 schedule 进行调度:
// linux-4.10.1/arch/x86/entry/entry_64.S
common_interrupt:
/* Interrupt came from user space */
GLOBAL(retint_user)
call prepare_exit_to_usermode
// linux-4.10.1/arch/x86/entry/common.c
/* Called with IRQs disabled. */
__visible inline void prepare_exit_to_usermode(struct pt_regs *regs)
{
exit_to_usermode_loop(regs, cached_flags);
}
// linux-4.10.1/arch/x86/entry/common.c
static void exit_to_usermode_loop(struct pt_regs *regs, u32 cached_flags)
{
while (true) {
/* We have work to do. */
local_irq_enable();
if (cached_flags & _TIF_NEED_RESCHED)
schedule();
/* Disable IRQs and retry */
local_irq_disable();
}
}
对于ARM64:
ENTRY(vectors)
-->ventry el0_irq // IRQ 64-bit EL0
-->ret_to_user
-->do_notify_resume
在do_notify_resume中,如果设置了_TIF_NEED_RESCHED,调用 schedule 进行调度:
asmlinkage void do_notify_resume(struct pt_regs *regs,
unsigned int thread_flags)
{
/*
* The assembly code enters us with IRQs off, but it hasn't
* informed the tracing code of that for efficiency reasons.
* Update the trace code with the current status.
*/
trace_hardirqs_off();
do {
if (thread_flags & _TIF_NEED_RESCHED) {
schedule();
}
} while (thread_flags & _TIF_WORK_MASK);
}
2.3 内核态抢占
内核态的抢占时机:
(1)调用preempt_enable()
(2)从中断返回内核空间时
2.2.1 preempt_count
在内核中只要没有持有锁,就可以就行内核抢占,锁是内核态是否抢占的标志,因此引入了一个preempt_count值,preempt_count初始值为0,每当使用锁时,该值就加1,释放锁时,该值就减1。preempt_count等于0代表内核可抢占。
因此对于内核态抢占来说,除了要判断是否设置了_TIF_NEED_RESCHED标志位,还需要判断preempt_count值是否等于0,内核中使用preempt_count来控制内核抢占。只有设置了_TIF_NEED_RESCHED标志位和preempt_count值等于0才能发起内核态抢占。
对于x86_64来说:
低版本比如 3.10.0,preempt_count位于struct thread_info结构体中:
struct thread_info {
int preempt_count; /* 0 => preemptable,
};
高版本比如4.10.1,preempt_count(__preempt_count)是一个 per-cpu变量:
DECLARE_PER_CPU(int, __preempt_count);
/*
* We mask the PREEMPT_NEED_RESCHED bit so as not to confuse all current users
* that think a non-zero value indicates we cannot preempt.
*/
static __always_inline int preempt_count(void)
{
return raw_cpu_read_4(__preempt_count) & ~PREEMPT_NEED_RESCHED;
}
对于ARM64来说,preempt_count位于struct thread_info结构体中:
/*
* low level task data that entry.S needs immediate access to.
*/
struct thread_info {
int preempt_count; /* 0 => preemptable, <0 => bug */
};
static __always_inline int preempt_count(void)
{
return READ_ONCE(current_thread_info()->preempt_count);
}
preempt_count()用来计算preempt_count值。
2.2.2 调用preempt_enable()
对内核态的执行中,被抢占的时机一般发生在 preempt_enable() 中。在内核态的执行中,有的操作是不能被中断的,所以在进行这些操作之前,总是先调用 preempt_disable() 关闭抢占,当再次打开的时候,就是一次内核态代码被抢占的机会。preempt_enable() 会调用 preempt_count_dec_and_test(),判断 preempt_count 和 TIF_NEED_RESCHED 是否可以被抢占。如果可以,就调用 __preempt_schedule->preempt_schedule->preempt_schedule_common->__schedule 进行调度。
#ifdef CONFIG_PREEMPT
#define preempt_enable() \
do { \
barrier(); \
//判断 preempt_count 和 TIF_NEED_RESCHED 是否可以被抢占
if (unlikely(preempt_count_dec_and_test())) \
__preempt_schedule(); \
} while (0)
#define preempt_count_dec_and_test() \
({ preempt_count_sub(1); should_resched(0); })
/*
* Returns true when we need to resched and can (barring IRQ state).
*/
static __always_inline bool should_resched(int preempt_offset)
{
return unlikely(preempt_count() == preempt_offset &&
tif_need_resched());
}
#define tif_need_resched() test_thread_flag(TIF_NEED_RESCHED)
static void __sched notrace preempt_schedule_common(void)
{
do {
/*
* Because the function tracer can trace preempt_count_sub()
* and it also uses preempt_enable/disable_notrace(), if
* NEED_RESCHED is set, the preempt_enable_notrace() called
* by the function tracer will call this function again and
* cause infinite recursion.
*
* Preemption must be disabled here before the function
* tracer can trace. Break up preempt_disable() into two
* calls. One to disable preemption without fear of being
* traced. The other to still record the preemption latency,
* which can also be traced by the function tracer.
*/
preempt_disable_notrace();
preempt_latency_start(1);
__schedule(true);
preempt_latency_stop(1);
preempt_enable_no_resched_notrace();
/*
* Check again in case we missed a preemption opportunity
* between schedule and now.
*/
} while (need_resched());
}
2.2.3 从中断返回内核空间时
在内核态也会遇到中断的情况,当中断返回的时候,返回的仍然是内核态,这个时候也是一个执行抢占的时机。
对于x86_64:
common_interrupt:
/* Returning to kernel space */
retint_kernel:
call preempt_schedule_irq
/*
* this is the entry point to schedule() from kernel preemption
* off of irq context.
* Note, that this is called and return with irqs disabled. This will
* protect us against recursive calling from irq.
*/
asmlinkage __visible void __sched preempt_schedule_irq(void)
{
enum ctx_state prev_state;
/* Catch callers which need to be fixed */
BUG_ON(preempt_count() || !irqs_disabled());
prev_state = exception_enter();
do {
preempt_disable();
local_irq_enable();
__schedule(true);
local_irq_disable();
sched_preempt_enable_no_resched();
} while (need_resched());
exception_exit(prev_state);
}
对于ARM64:
ENTRY(vectors)
-->ventry el1_irq // IRQ EL1h
-->el1_preempt
-->preempt_schedule_irq // irq en/disable is done inside
/*
* this is the entry point to schedule() from kernel preemption
* off of irq context.
* Note, that this is called and return with irqs disabled. This will
* protect us against recursive calling from irq.
*/
asmlinkage __visible void __sched preempt_schedule_irq(void)
{
enum ctx_state prev_state;
/* Catch callers which need to be fixed */
BUG_ON(preempt_count() || !irqs_disabled());
prev_state = exception_enter();
do {
preempt_disable();
local_irq_enable();
__schedule(true);
local_irq_disable();
sched_preempt_enable_no_resched();
} while (need_resched());
exception_exit(prev_state);
}
总结

参考资料
Linux 4.10.1
极客时间:趣谈Linux操作系统
https://www.cnblogs.com/LoyenWang/p/12386281.html
https://kernel.blog.csdn.net/article/details/51872618
https://pwl999.blog.csdn.net/article/details/78817899