1. 系统启动部分
使用 python 中的 parser 库 为配置系统的参数设定, 和3DGS 类似,并且使用safe_state(args.quiet) 函数 为每一次的 log 输出加上对应的 时间戳
## 配置参数的设定
lp = ModelParams(parser)
op = OptimizationParams(parser)
pp = PipelineParams(parser)
## 指定随机数的种子,并且将 log 的 std::out 输出 加上对应的 时间戳
safe_state(args.quiet)
–lod 用于对 Train/Test 的图像进行划分,表示Test 的Image 的数量。 比如, lod=40, 那么表示 选择40张图像作为 Test,剩下的图像作为 Train
2. Training 函数
2.1 初始化 Gaussian 的设定:
gaussians = GaussianModel(dataset.feat_dim, dataset.n_offsets, dataset.voxel_size, dataset.update_depth, dataset.update_init_factor, dataset.update_hierachy_factor, dataset.use_feat_bank,
dataset.appearance_dim, dataset.ratio, dataset.add_opacity_dist, dataset.add_cov_dist, dataset.add_color_dist)
定义了网络的结构:
MLP_opacity:

MLP_cov:
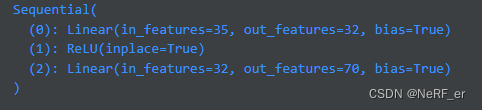
MLP_color
2.2 读取位姿和图像
读取 colmap 生成的图像和位姿:
首先对于colmap 图像的 所有图像和 Pose 进行 Train/Test 的划分, 其中默认是 每隔8张选择一张作为 Test Image( LLFF 的划分依据).
代码里也设置了 – lod 参数来指定 Test Image 的个数, 比如 设置 –lod = 20 , 那么就代表由20张图像作为 TestImage; 剩下的 图像作为 Train Image.
Pose 的 Normalize. [ 所有的相机相对于中心点来说 ]
之后,需要在 Mipnerf360 这种环绕拍摄的setting 对 Train Camera 的位姿进行处理,其目的是根据所有 camera 的 位置,确定 整个场景的 几何中心(center) 和整个场景的 半径 radius. 然后所有的相机的位置都要 减去这个 center 的坐标, 相对于对于Pose 进行了 【-1,1】 之间的映射。
直接读取了 PLY 格式的 3D Colmap 重建的点云
点云和相机的参数 都保存在 scene_info 这个对象里面,对应着点云的3个属性:

对于图像进行 降采样
降采样的参数是通过命令行的 参数 -r 去实现的. 将 -r 设置成4, 我们对于图像进行降采样 4倍;
需要注意的是,根据 视场角 fov 的定义,对于图像进行长和宽等比例的降采样之后,视场角FOV 是保持不变的 (如果考虑相机的主点不存在偏移的话)。因此 3DGS 使用的 projection Matrix 是没有变换的
根据相机的 Fov_x, Fov_y, z_near, z_far 构建相机透视投影矩阵:
透视投影矩阵 往往假设 视锥,假设一个对称的视锥,不直接考虑主点偏移, (cx,cy 位于图像的中心的地方)。
def getProjectionMatrix(znear, zfar, fovX, fovY):
tanHalfFovY = math.tan((fovY / 2))
tanHalfFovX = math.tan((fovX / 2))
top = tanHalfFovY * znear
bottom = -top
right = tanHalfFovX * znear
left = -right
P = torch.zeros(4, 4)
z_sign = 1.0
P[0, 0] = 2.0 * znear / (right - left)
P[1, 1] = 2.0 * znear / (top - bottom)
P[0, 2] = (right + left) / (right - left)
P[1, 2] = (top + bottom) / (top - bottom)
P[3, 2] = z_sign
P[2, 2] = z_sign * zfar / (zfar - znear)
P[2, 3] = -(zfar * znear) / (zfar - znear)
return P
为每个相机计算 内参 ProjectionMatrix, 外参 world_view_transform,两个4*4的矩阵。
2.3 从点云去创建场景的 3D Gaussian
首先对于 redundancy 点云 进行删除:
points = self.voxelize_sample(points, voxel_size=self.voxel_size)

然后去初始化 高斯球的一些属性, scale 的初始化 用到了 KNN 算法 去寻找最近的点。 旋转 rot 从 0 开始初始化, opacity 随机给定一个固定数值从 0.1 初始化. 初始化的 代码和原始的 3DGS 相似, 但是 却多了3个物理量
anchor: 实际上就是3D 点云的坐标 xyz
offset:: 一个 anchor point 会生成 k个 Gaussian, 其位置是 anchor point 的位置加上 offset 偏移量
**scaling ** : 每一个 anchor_point 额外有一个 scaling 的属性, 其初始化时每个3D点到最近3D点的距离, 但是却 repeat 了6次,因此 shape 时 (N,6). 这个 scaleing factor 不是高斯的属性,不能理解为 协方差中的 scale,而是一个缩放因子。
## 这里的 anchor 其实就是高斯球的中心点,由点云得到的
self._anchor = nn.Parameter(fused_point_cloud.requires_grad_(True))
## 代码里 offset 初始为10. offset shape 【N,10,3】
self._offset = nn.Parameter(offsets.requires_grad_(True))
self._anchor_feat = nn.Parameter(anchors_feat.requires_grad_(True))
self._scaling = nn.Parameter(scales.requires_grad_(True))
self._rotation = nn.Parameter(rots.requires_grad_(False))
self._opacity = nn.Parameter(opacities.requires_grad_(False))
## max_radii2D shape [N]
self.max_radii2D = torch.zeros((self.get_anchor.shape[0]), device="cuda")
2.3 每次随机选择一个相机 进行训练
# Pick a random Camera
if not viewpoint_stack:
viewpoint_stack = scene.getTrainCameras().copy()
viewpoint_cam = viewpoint_stack.pop(randint(0, len(viewpoint_stack)-1))
Mask 掉 frustum 之外的 Gaussian, 并且对于 alpha 的阈值具有一定的要求
为每一个 anchor point 生成 一个 Mask
voxel_visible_mask = prefilter_voxel(viewpoint_cam, gaussians, pipe,background)
根据 anchor_point 生成 新的 3D Gaussian
xyz, color, opacity, scaling, rot, neural_opacity, mask = generate_neural_gaussians(
viewpoint_camera, ## 相机的属性
pc, ## 3D高斯输入
visible_mask, ## 可见的Mask
is_training=is_training)
计算每个 3D gaussian 球到 相机的 距离 dist 和方向

ob_view = anchor - viewpoint_camera.camera_center
# dist
ob_dist = ob_view.norm(dim=1, keepdim=True)
# view
ob_view = ob_view / ob_dist
每个 anchor point 有 dim=32 的feature , 将这个 feature 和 距离 dist, 方向dir concat 起来。 实际的实现里面
pc.add_opacity_dist = False , 因此 预测 opacity 的 输入 ,只有 方向 dir 和 feature concat 起来,组成了 35 维度的 vector,
预测 Neural Gaussian 的 opacity
cat_local_view = torch.cat([feat, ob_view, ob_dist], dim=1) # [N, c+3+1]
cat_local_view_wodist = torch.cat([feat, ob_view], dim=1) # [N, c+3]
## MLP 预测,将feature 转换成 opacity
neural_opacity = pc.get_opacity_mlp(cat_local_view_wodist)
预测 Neural Gaussian 的 color
和前面一张,使用的 feature 是35 维度的, 不包括 dist ;
同样是 输入 35维度的向量,我们可以直接 通过MLP 推理得到 color 的数值:
## color 的output dim = 30
color = pc.get_color_mlp(cat_local_view_wodist)
## 将30 dim 的feature , reshape 成 [N,10,3]. 因为每一个 anchor point 会生成10个 Gaussian, 每个 Gaussian 有3个维度的 color
color = color.reshape([anchor.shape[0]*pc.n_offsets, 3])# [mask]
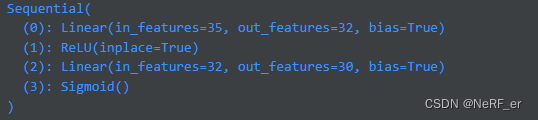
预测 Neural Gaussian 的 cov [ 旋转Rot 和缩放 scale ]

预测 协方差的 Cov_mlp 输入时35 维度(和前面保持一致),输出是70维度。
scale_rot = pc.get_cov_mlp(cat_local_view_wodist)
## reshape 成 [N,10,7]
scale_rot = scale_rot.reshape([anchor.shape[0]*pc.n_offsets, 7]) # [mask]
对于 Cov 进行后处理,得到每个高斯球的 scale 和 rot:
scaling repeat 是每一个 anchor point 的属性, shape 是 [N,6]. 6 个数字是一样的。 对应公式中的 l v l_v lv
scaling = scaling_repeat[:,3:] * torch.sigmoid(scale_rot[:,:3]) # 对于协方差的 scale 需要进行scaling
rot = pc.rotation_activation(scale_rot[:,3:7]) # 对于协方差的 rot 可以直接使用激活函数,进行激活
预测 Neural Gaussian 的 位置 xyz
从一个 anchor point 出发,加上 缩放之后的 offset, 可以确定 Neural Gaussian 的位置
# post-process offsets to get centers for gaussians
offsets = offsets * scaling_repeat[:,:3] ## 对于offset 同样需要 乘以 scaling
xyz = repeat_anchor + offsets

2. Render 函数. 根据生成的 3D Neural Gaussian 进行 Rasterize. 这一部分主要和3D GS 的实现保持一致。
这一部分是 CUDA 的代码,和3DGS 的渲染过程是一致的。
# Rasterize visible Gaussians to image, obtain their radii (on screen).
rendered_image, radii = rasterizer(
means3D = xyz, ## 3D Gaussian 的中心点
means2D = screenspace_points, ## output: 3DGS 投影到2D screen 上的点,用来记录梯度
shs = None,
colors_precomp = color, ## 3DGS 的颜色
opacities = opacity, ## 3DGS 的不透明度 alpha
scales = scaling, ## 3DGS 的 scaling
rotations = rot, ## 3DGS 的 旋转
cov3D_precomp = None)