目录
简述
前馈神经网络结构
计算输出
初始化权重
径向基函数神经网络
径向基函数
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: 政安晨的机器学习笔记
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
简述
由于其用途广泛,前馈神经网络架构非常受欢迎。因此,我们将探索如何训练它,以及它如何处理模式。
“前馈”一词描述了该神经网络如何处理和记忆模式。在前馈神经网络中,神经网络的每一层都包含到下一层的连接。如这些连接从输入向前延伸到隐藏层,但是没有向后的连接。后面,我们也将分析前馈神经网络的结构及其记忆模式的方式。
我们可以使用多种反向传播算法中的各种技术来训练前馈神经网络,这是一种有监督的训练形式。本文重点介绍应用优化算法来训练神经网络的权重。尽管可以用几种优化算法来训练权重,但我们主要将注意力集中在模拟退火上。
优化算法会调整一个数字向量,旨在根据一个目标函数获得良好的得分。目标函数基于该神经网络的输出与预期输出的匹配程度,为神经网络提供得分。该得分允许用任何优化算法来训练神经网络。
优化算法会调整一个数字向量,旨在根据一个目标函数获得良好的得分。目标函数基于该神经网络的输出与预期输出的匹配程度,为神经网络提供得分。该得分允许用任何优化算法来训练神经网络。
前馈神经网络类似于我们已经探讨过的神经网络。其从一个输入层开始,可能连接到隐藏层或输出层。如果连接到隐藏层,则该隐藏层可以随后连接到另一个隐藏层或输出层。隐藏层可以有任意多层。
前馈神经网络结构
我们讨论了神经网络可以具有多个隐藏层,并分析了这些层的用途。我们将从输出层的结构开始,聚焦于输入神经元和输出神经元的结构。问题的类型决定了输出层的结构。分类神经网络将为每个类别提供一个输出神经元,而回归神经网络将只有一个输出神经元。
用于回归的单输出神经网络
管前馈神经网络可以具有多个输出神经元,但我们将从回归问题中的单输出神经网络开始。用于回归的单输出神经网络能够预测单个数值。
下图展示了一个单输出前馈神经网络。
(单输出前馈神经网络)

这个神经网络将输出一个数值。我们可以通过以下方式使用这种类型的神经网络。
● 回归:根据输入计算数值(如特定类型的汽车每加仑可行驶多少英里)。
● 二元分类:根据输入确定两个选项(如在给定的特征下,哪个是恶性肿瘤)。
我们在本文中提供了一个回归示例,该示例利用有关各种汽车模型的数据,预测汽车的MPG。
有关各种汽车模型的数据来自于汽车MPG数据集,这个数据集的一小部分示例如下:
mpg,cylinders,displacement,horsepower,weight,acceleration,model_year,origin,car_name
18,8,307,130,3504,12,70,1,"chevrolet chevelle malibu"
15,8,350,165,3693,11,70,1,"buick skylark 320"
18,8,318,150,3436,11,70,1,"plymouth satellite"
16,8,304,150,3433,12,70,1,"amc rebel sst"对于回归问题,神经网络将创建气缸数、排量、马力和车重等列来预测MPG。
这些值是上面数据集示例中使用的所有字段,用于指定每辆汽车的特征。
在这个例子中,目标是预测MPG。但是,我们也可以利用MPG、汽缸数、马力、车重和加速等来预测排量。
为了用神经网络对多个值执行回归,可以使用多个输出神经元。
如气缸、排量和马力可以预测MPG和车重。尽管多输出神经网络可以对两个变量进行回归,但我们不建议使用此技术。对于要预测的每个回归结果,通常使用单独的神经网络可以获得更好的结果。
计算输出
单个神经元的输出就是其输入和偏置的加权和。
该和被传递给一个激活函数。下面公式总结了神经网络的计算输出:
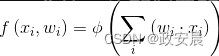
神经元将输入向量(x)乘以权重(w),然后将结果传递给一个激活函数(φ)。偏置是权重向量(w)中的最后一个值,添加偏置的方法是将值1.0连接到输入之后。如考虑具有两个输入和一个偏置的神经元,如果输入为0.1和0.2,则输入向量如下所示:
[0.1, 0.2, 1.0]在这个示例中,添加值1.0以支持偏置权重。
我们也可以用以下权重向量来计算该值:
[0.01, 0.02, 0.3]值0.01和0.02是神经元两个输入的权重,值0.3是偏置的权重。计算加权和:
(0.1 * 0.01) + (0.2 * 0.02) + (1.0 * 0.3)
然后将计算结果0.305传递给激活函数。
计算整个神经网络的输出本质上是对神经网络中的每个神经元都执行这个相同的过程。这个过程使你可以从输入神经元一直计算到输出神经元。你可以为神经网络中的每个连接创建对象,或将这些连接值安排到矩阵中,从而实现这个过程。
面向对象的编程让你可以为每个神经元及其权重定义一个对象。
这种方法能产生可读性强的代码,但是它有两个重要的问题:
● 权重存储在许多对象中;
● 性能受影响,因为需要许多函数调用和内存访问才能将所有权重加在一起。
在神经网络中,将权重作为单个向量创建很有价值。各种不同的优化算法可以调整一个向量,让得分函数产生最优的结果。在后文,我们将看到模拟退火如何优化神经网络的权重向量。
为了创建一个权重向量,我们首先来看一个具有以下特征的神经网络。
● 输入层:2个神经元,1个偏置。
● 隐藏层:2个神经元,1个偏置。
● 输出层:1个神经元。
这些特征使得该神经网络共有7个神经元。
为了创建该向量,可以用以下方式对这些神经元编号:
Neuron 0: Output 1
Neuron 1: Hidden 1
Neuron 2: Hidden 2
Neuron 3: Bias 2 (set to 1, usually)
Neuron 4: Input 1
Neuron 5: Input 2
Neuron 6: Bias 1 (set to 1, usually)
用图形方式表示该简单神经网络,如下图所示:
(简单神经网络)

你可以创建几个其他向量来定义神经网络的结构。
这些向量保存索引值,以便快速访问权重向量。这些向量在这里列出:
layerFeedCounts: [1, 2, 2]
layerCounts: [1, 3, 3]
layerIndex: [0, 1, 4]
layerOutput: [0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0]
weightIndex: [0, 3, 9]每个向量中保存值的顺序是首先输出层,然后向上直到输入层。
layerFeedCounts向量保存每一层中非偏置神经元的计数。
该特征实际上是非偏置神经元的数量。
layerOutput向量保存每个神经元的当前值。
最初,所有神经元都从0.0开始,除了偏置神经元从1.0开始。
layerIndex向量保存每个层在layerOuput向量中的起始位置的索引。
weightIndex保存指向权重向量中每一层位置的索引。
权重存储在它们自己的向量中,其结构如下:
Weight 0 : H1−>01
Weight 1 : H2−>01
Weight 2 : B2−>01
Weight 3 : I1−>H1
Weight 4 : I2−>H1
Weight 5 : B1−>H1
Weight 6 : I1−>H2
Weight 7 : I2−>H2
Weight 8 : B1−>H2
一旦安排好向量,计算神经网络的输出就相对容易了。
如下代码可以完成这种计算。
(计算前馈输出)
def compute(net, input):
sourceIndex = len(net.layerOutput)
- net.layerCounts[len(net.layerCounts) - 1]
# Copy the input into the layerOutput vector
array_copy(input, 0, net.layerOutput, sourceIndex,
net.inputCount)
# Calculate each layer
for i in reversed(range(0,len(layerIndex))):
compute_layer(i)
# update context values
offset = net.contextTargetOffset[0]
# Create result
result = vector(net.outputCount)
array_copy(net.layerOutput, 0, result, 0, net.outputCount)
return result
def compute_layer(net,currentLayer):
inputIndex = net.layerIndex[currentLayer]
outputIndex = net.layerIndex[currentLayer - 1]
inputSize = net.layerCounts[currentLayer]
outputSize = net.layerFeedCounts[currentLayer - 1]
index = this.weightIndex[currentLayer - 1]
limit_x = outputIndex + outputSize
limit_y = inputIndex + inputSize
# weight values
for x in range(outputIndex,limit_x):
sum = 0;
for y in range(inputIndex,limit_y):
sum += net.weights[index] * net.layerOutput[y]
net.layerSums[x] = sum
net.layerOutput[x] = sum
index = index + 1
net.activationFunctions[currentLayer - 1]
.activation_function(
net.layerOutput, outputIndex, outputSize)初始化权重
神经网络的权重决定了神经网络的输出。训练过程可以调整这些权重,使得神经网络产生有用的输出。大多数神经网络训练算法开始都将权重初始化为随机值。然后,训练通过一系列迭代进行,这些迭代不断改进权重,以产生更好的输出。
神经网络的随机权重会影响神经网络的训练水平。
如果神经网络无法训练,你可以通过重新设置一组新的随机权重来解决问题。
但是,当你尝试不同的神经网络的架构,并尝试不同的隐藏层和神经元组合时,这个解决方案可能会令人沮丧。
如果添加新层后,神经网络性能得到改善,你就必须考虑,这种改进是由新层产生的,还是由一组新的权重产生的。
由于存在这种不确定性,我们在权重初始化算法中关注两个关键属性。
● 该算法提供良好权重的一致性如何?
● 该算法提供的权重有多少优势?
权重初始化最常见(但最无效)的方法之一,是将权重设置为特定范围内的随机值,通常选择−1~+1或−5~+5的数字。如果要确保每次都获得相同的随机权重集,则应使用种子。种子指定了要使用的一组预定义随机权重。如种子为1 000,可能会产生0.5、0.75和0.2的随机权重。这些值仍然是随机出现的,你无法预测,但是当你选择1 000作为种子时,总是会获得这些值。
并非所有种子都是生而平等的。随机权重初始化有一个问题,即某些种子创建的随机权重比其他种子更难训练。实际上,权重可能非常糟糕,而无法进行训练。如果发现无法使用特定的权重集训练神经网络,则应使用其他种子生成一组新的权重。
由于权重初始化存在的问题,人们围绕它进行了大量研究。多年来,我们已经考察了这方面的研究,并在Encog项目中添加了6个不同的权重初始化例程。根据我们的研究,由Glorot和Bengio于2006年引入的Xavier权重初始化算法可以产生具有合理一致性的良好权重。这种相对简单的算法使用正态分布的随机数。
要使用Xavier权重初始化,必须了解正态分布的随机数不是大多数编程语言生成的0~1的典型随机数。
实际上,正态分布的随机数以均值μ(mu)为中心,它通常为0。如果以0为中心(均值),那么你将获得数量相等的大于0和小于0的随机数。
下一个问题是这些随机数将从0偏离到多远。
理论上,你可能得到正随机数和负随机数都接近计算机支持的最大正数和负数范围。
但现实情况是,你很可能会看到一些随机数,它们与中心的偏差为0~3个标准差。
标准差σ(sigma)参数指定这个标准差的大小。如果你将标准差指定为10,那么你主要会看到−30~+30的随机数,较接近0的数字具有更高的选择概率。
下图展示了正态分布。(正态分布)

上图展示了中心(在这个例子中为0)将以0.4(40%)的概率生成。另外,在−2或+2个标准差之外,概率降低得非常快。通过定义中心和标准差的大小,你可以控制生成的随机数的范围。
大多数编程语言都具有生成正态分布的随机数的能力。通常,Box-Muller算法是这种能力的基础。本书中的示例将使用内置的正态随机数发生器,或用Box-Muller算法将规则的、均匀分布的随机数转换为正态分布。
Xavier权重初始化将所有权重设置为正态分布的随机数,这些权重总是以0为中心。它们的标准差取决于当前权重层存在多少个连接。具体来说,下面公式可以确定方差:
![]()
上面公式展示了如何获得所有权重的方差。方差的平方根是标准差。大多数随机数生成器接受标准差,而不是方差。因此,你通常需要取如上公式的平方根。
下图展示了一层的Xavier初始化过程。

神经网络中的每一层,都要完成这个过程。
径向基函数神经网络
径向基函数(Radial-Basis Function,RBF)神经网络是Broomhead和Lowe(1988)引入的一种前馈神经网络。该神经网络可用于分类和回归。
尽管它们可以解决各种问题,但RBF神经网络的受欢迎程度似乎正在降低。根据其定义,RBF神经网络不能与深度学习结合使用。
RBF神经网络利用一个参数向量(一个指定权重和系数的模型),来允许输入生成正确的输出。通过调整一个随机参数向量,RBF神经网络可产生与鸢尾花数据集一致的输出。
调整该参数向量以产生所需输出的过程称为训练。
训练RBF神经网络有许多不同的方法。
参数向量也代表了RBF神经网络的长期记忆。
我们将简要回顾RBF,并描述这些向量的确切组成。
径向基函数
由于许多AI算法都利用了径向基函数,因此它们是一个非常重要的概念。RBF相对其中心对称,该中心通常在[插图]轴上。RBF将在中心达到其最大值,即峰值。RBF神经网络中典型的峰值通常设置为1,中心会相应地变化。
RBF可以有许多维度。无论传递给RBF的向量维度是多少,它的输出总是单个标量值。
RBF在AI中很常见。我们将从最流行的高斯函数开始讲解。下图展示了以0为中心的一维高斯函数的图像。
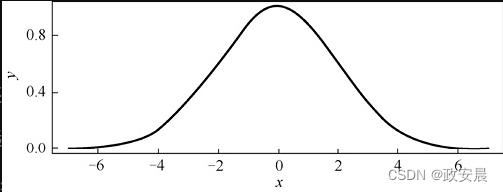
你可能认为上述曲线是正态分布或钟形曲线,而这其实是一个RBF。RBF(如高斯函数)可以有选择地缩放数值。请考虑下图所示函数,如果你用这个函数缩放一些数值,那么结果将在中心具有最大强度。从中心向两侧移动时,强度会沿正向或负向减小。










![[SystemVerilog]常见设计模式/实践](https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=https%3A%2F%2Fsystemverilog.dev%2Fimages%2F04%2Fwishbone_diagram.svg&pos_id=HJ7nmITM)
