作者 / Keras 产品经理 Martin Görner
Keras 团队非常高兴地宣布,KerasNLP 集合现已支持 Gemma!Gemma 是先进的轻量级开放模型系列,采用了与构建 Gemini 模型相同的研究和技术。借助 Keras 3,Gemma 可以在 JAX、PyTorch 和 TensorFlow 上运行。在此版本中,Keras 还推出了专为大语言模型 (LLM) 而设计的几项新功能: 新的 LoRA API (低秩适应) 和大规模模型并行训练能力。
KerasNLP
https://keras.io/api/keras_nlp/
Gemma
http://ai.google.dev/gemma
Keras 3
https://keras.io/keras_3/
模型并行训练
https://keras.io/guides/distribution/
您可以访问以下页面,直接深入了解代码示例:
Gemma 模型入门指南
使用 LoRA 微调 Gemma 模型
在多个 GPU/TPU 上微调 Gemma 模型
Gemma 模型入门指南
https://colab.research.google.com/github/google/generative-ai-docs/blob/main/site/en/gemma/docs/get_started.ipynb
使用 LoRA 微调 Gemma 模型
https://colab.research.google.com/github/google/generative-ai-docs/blob/main/site/en/gemma/docs/lora_tuning.ipynb
在多个 GPU/TPU 上微调 Gemma 模型
https://www.kaggle.com/code/nilaychauhan/keras-gemma-distributed-finetuning-and-inference
开始了解
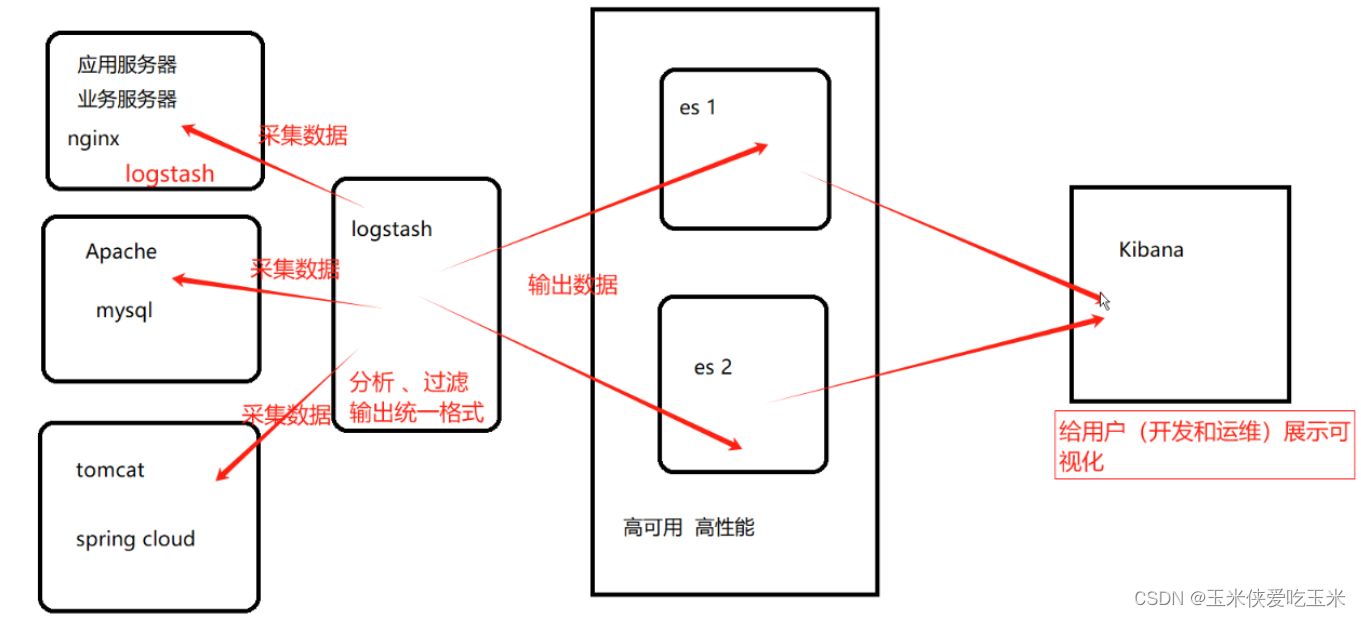
Gemma 模型有便携式的 2B 和 7B 两种权重规模。与同类开放模型,甚至一些更大的开放模型相比,Gemma 模型具有显著优势。例如:
在 MMLU 语言理解基准测试中,Gemma 7B 的答题正确率为 64.3% (相比之下,Mistral-7B 为 62.5%,Llama2-13B 为 54.8%),创下同类最佳成绩记录
Gemma 将小学数学问题 GSM8K 基准分数记录提升了至少 11 个百分点 (Gemma 7B 为 46.4%,Mistral-7B 为 35.4%,Llama2-13B 为 28.7%)
Gemma 将编码挑战 HumanEval 的答题正确率记录提升了至少 6.1 个百分点 (Gemma 7B 为 32.3%,Mistral 7B 为 26.2%,Llama2 13B 为 18.3%)
具有显著优势
https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf
Gemma 模型提供了大家熟悉的 KerasNLP API 和易读性极高的 Keras 实现。您只需使用一行代码,便可以实例化模型。代码如下所示:
gemma_lm = keras_nlp.models.GemmaCausalLM.from_preset("gemma_2b_en")然后直接在文本提示上运行模型。标记化是内置的,但您也可以根据需要轻松地将模型拆分出来。欢迎您阅读 Keras NLP 指南,了解如何操作。
gemma_lm.generate("Keras is a", max_length=32)
> "Keras is a popular deep learning framework for neural networks..."Keras NLP 指南
https://keras.io/guides/keras_nlp/getting_started/
欢迎您立即尝试: Gemma 模型入门指南
https://colab.research.google.com/github/google/generative-ai-docs/blob/main/site/en/gemma/docs/get_started.ipynb
使用 LoRA 微调 Gemma 模型
得益于 Keras 3,您可以自由选择运行模型的后端。切换方式如下:
os.environ["KERAS_BACKEND"] = "jax" # Or "tensorflow" or "torch".
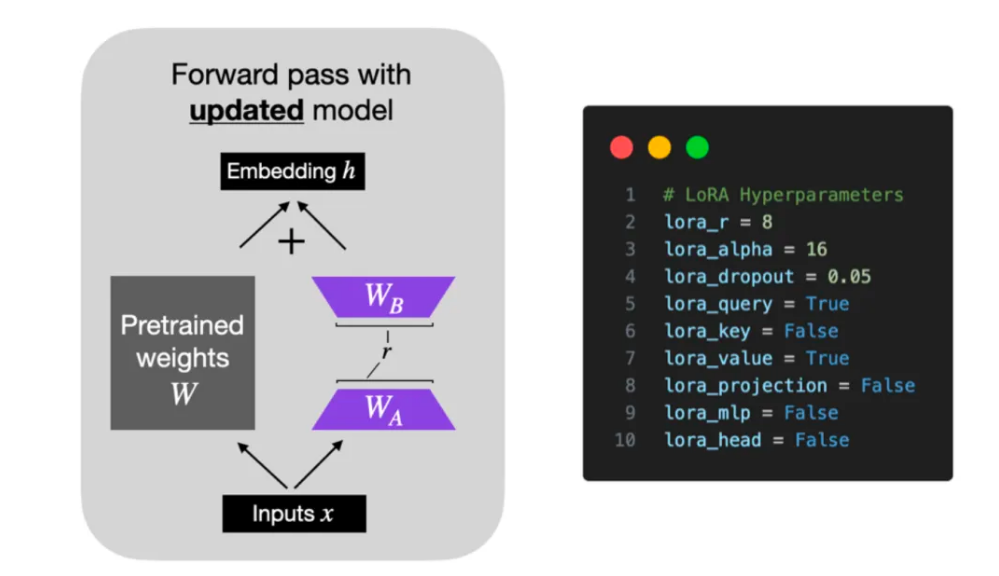
import keras # import keras after having selected the backendKeras 3 引入了多项专为大语言模型 (LLM) 而设计的新功能,其中最主要的功能是一个用于高效微调参数的新 LoRA API (低秩适应)。该功能的激活方式如下:
gemma_lm.backbone.enable_lora(rank=4)
# Note: rank=4 replaces the weights matrix of relevant layers with the
# product AxB of two matrices of rank 4, which reduces the number of
# trainable parameters.这行代码将可训练参数的数量从 25 亿减少到 130 万!
立即尝试: 使用 LoRA 微调 Gemma 模型
https://colab.research.google.com/github/google/generative-ai-docs/blob/main/site/en/gemma/docs/lora_tuning.ipynb
在多个 GPU/TPU 上微调 Gemma 模型
Keras 3 还支持大规模模型训练,而 Gemma 是尝试这类训练的理想模型。新的 Keras 分发 API 提供数据并行和模型并行两种分布式训练选项。这个新的 API 的设计初衷在于实现多后端兼容,但目前仅针对 JAX 后端实现,因为其可扩展性已被验证 (Gemma 模型就是使用 JAX 进行训练的)。
Keras 分发 API
https://keras.io/guides/distribution/
采用分布式设置对更大的 Gemma 7B 模型进行微调是非常有用的,例如在 Kaggle 上可以免费获得的具有 8 个 TPU 核心的 TPUv3,或 Google Cloud 上的 8-GPU 机器。以下是使用模型并行形式配置模型,从而实现分布式训练的方法:
device_mesh = keras.distribution.DeviceMesh(
(1, 8), # Mesh topology
["batch", "model"], # named mesh axes
devices=keras.distribution.list_devices() # actual accelerators
)
# Model config
layout_map = keras.distribution.LayoutMap(device_mesh)
layout_map["token_embedding/embeddings"] = (None, "model")
layout_map["decoder_block.*attention.*(query|key|value).*kernel"] = (
None, "model", None)
layout_map["decoder_block.*attention_output.*kernel"] = (
None, None, "model")
layout_map["decoder_block.*ffw_gating.*kernel"] = ("model", None)
layout_map["decoder_block.*ffw_linear.*kernel"] = (None, "model")
# Set the model config and load the model
model_parallel = keras.distribution.ModelParallel(
device_mesh, layout_map, batch_dim_name="batch")
keras.distribution.set_distribution(model_parallel)
gemma_lm = keras_nlp.models.GemmaCausalLM.from_preset("gemma_7b_en")
# Ready: you can now train with model.fit() or generate text with generate()此代码段的作用是将 8 个加速器设置为一个 1 x 8 矩阵,其中的两个维度分别被称为 "批处理 (batch)" 和 "模型 (model)"。模型权重在 "模型" 维度上进行分片 (shard),即在这 8 个加速器之间进行分割。而由于 "批处理" 维度为 1,所以数据批处理不会被分区。
立即尝试: 在多个 GPU/TPU 上微调 Gemma 模型
https://www.kaggle.com/code/nilaychauhan/keras-gemma-distributed-finetuning-and-inference
未来计划
我们即将发布一份指南,向您介绍如何正确地对 Transformer 模型进行分区并编写上述 6 行关于分区设置的代码。欢迎您持续关注我们的最新动态。
您可能已注意到,层的分区是通过层名称上的正则表达式定义的。您可以使用以下代码段查看层名称。我们运行此代码段来构建前文提到的 LayoutMap。
# This is for the first Transformer block only,
# but they all have the same structure
tlayer = gemma_lm.backbone.get_layer('decoder_block_0')
for variable in tlayer.weights:
print(f'{variable.path:<58} {str(variable.shape):<16}')这里只需一些分区提示,完整的 GSPMD 模型并行处理就可以运行,这是因为 Keras 将这些设置传递给功能强大的 XLA 编译器,该编译器会计算出分布式计算的所有其他详细信息。
GSPMD
https://arxiv.org/abs/2105.04663
XLA 编译器
https://github.com/openxla/xla
我们希望您拥有愉快的 Gemma 模型使用之旅,也希望这份指令微调教程能对您有所帮助。Kaggle 模型中心现已支持用户上传自己微调的权重 (Weights),您可以前往 Kaggle 上的 Gemma 模型页面,与社区分享微调后的权重 (Weights),或者查看其他用户创建的内容!
指令微调教程
https://ai.google.dev/gemma/docs/lora_tuning
Gemma 模型页面
https://www.kaggle.com/models/google/gemma