前面我们有提到,单向不带头循环链表的制作
这里我们介绍一个双向带头循环链表的制作方法
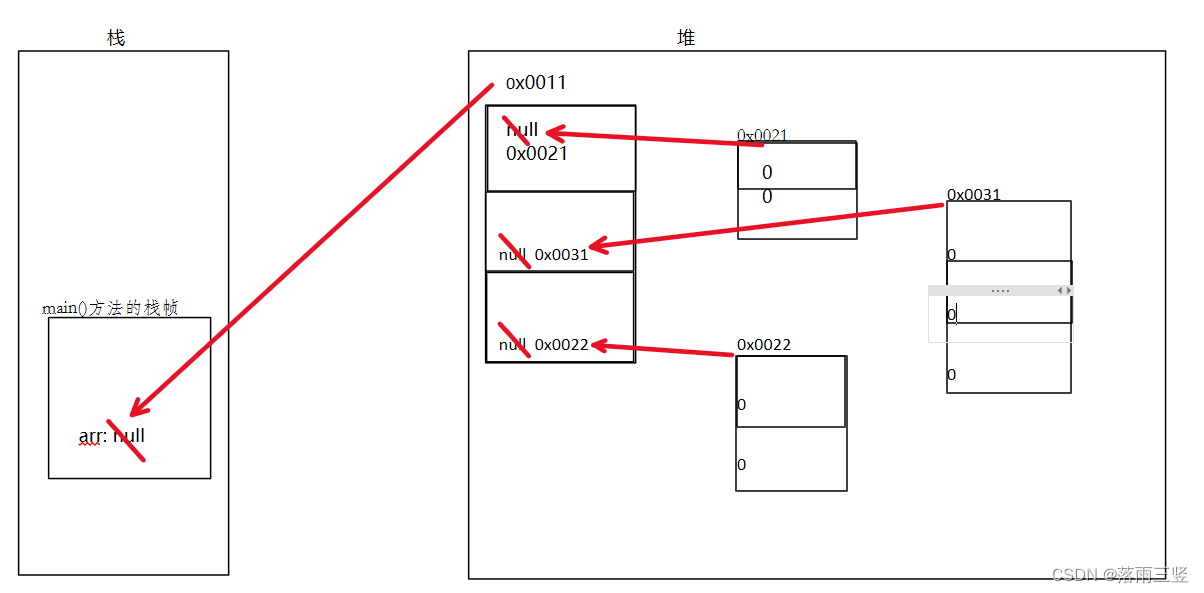
双向带头循环链表的示意图如下
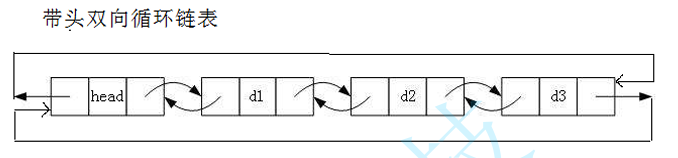
带头指针的作用体现在哪呢?
第一、防止头节点为空,既有头结点,头指针始终指向头结点,那么无论链表是否为空,头指针均不为空;没有头结点,头指针就为NULL
第二、有头结点时,插入/删除第一个结点时,空链表/非空链表操作逻辑一致,不需要额外判断
第三、插入或者删除头结点的时候不需要改变头节点,只需要改变头结点的下一个即可
带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都 是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带 来很多优势,实现反而简单了。
具体哪里简单我们可以来看一下双向循环列表的代码
Dlist.h文件
#pragma once
//带头双向循环链表
//实现增删查改功能
#include <stdio.h>
#include <stdlib.h>
#define datatype int
typedef struct Doublelist
{
struct Doublelist* pre;
datatype x;
struct Singlelist* next;
}DL;
//扩容动态内存
DL* buystorage();
//初始化带头双向循环链表
void init(DL** head);
//打印双向循环链表
void printDL(DL* head);
//查找输入值
DL* findlist(const DL* head, datatype input);
//前向输入
void pushfront(DL* head, datatype input);
//后向输入
void pushback(DL* head, datatype input);
//前向删除
void popfront(DL* head);
//后向删除
void popback(DL* head);
//插入指定位置
void insertpos(DL* head, int pos, datatype input);
//修改指定位置
void modifylist(DL* head, int pos);Dlist.c文件
#include "D_LIst.h"
DL* buystorage()
{
DL* temp = (DL*)malloc(sizeof(DL));
return temp;
}
void init(DL** head)
{
DL* temp = buystorage();
temp->next = temp;
temp->pre = temp;
*head = temp;
}
void printDL(DL* head)
{
DL* temp = head;
printf("HEAD -> ");
while (head->next != temp)
{
head = head->next;
printf("%d -> ", head->x);
}
printf("HEAD\n");
}
const DL* findpos(const DL* head, int pos)
{
int count = 1;
DL* temp = head;
while (count < pos)
{
count++;
temp = temp->next;
}
return temp;
}
const void insert(DL*pos, datatype input)
{
DL* temp = buystorage();
temp->x = input;
DL* pre = pos->pre;
pre->next = temp;
temp->next = pos;
pos->pre = temp;
temp->pre = pre;
}
void pushfront(DL* head, datatype input)
{
insert(head->next, input);
}
void pushback(DL* head, datatype input)
{
insert(head, input);
}
const void erase(DL* pos)
{
if (pos->next = pos)
{
printf("没有任何数据,请先输入数据");
return;
}
DL* temppre = pos->pre;
DL* tempnext = pos->next;
temppre->next = tempnext;
free(pos);
pos = NULL;
}
void popfront(DL*head)
{
erase(head->next);
}
void popback(DL* head)
{
erase(head->pre);
}
void insertpos(DL* head, int pos,datatype input)
{
DL* findedpos = findpos(head, pos+1);
insert(findedpos, input);
}
DL* findlist(const DL* head, datatype input)
{
DL* temp = head;
while (temp->next != head)
{
temp = temp->next;
if (input == temp->x)
{
printf("输入的%d找到了\n",input);
return temp;
}
}
printf("输入的%d没找到\n",input);
return NULL;
}
void modifylist(DL* head, int pos , datatype input)
{
DL* findedpos = findpos(head, pos + 1);
findedpos->x = input;
}test.c文件
#include "D_LIst.h"
void test1()
{
DL* Doublelist = NULL;
init(&Doublelist);
pushfront(Doublelist, 3);
pushfront(Doublelist, 4);
pushfront(Doublelist, 5);
pushfront(Doublelist, 6);
printDL(Doublelist);
pushback(Doublelist, 3);
pushback(Doublelist, 4);
pushback(Doublelist, 5);
pushback(Doublelist, 6);
printDL(Doublelist);
popfront(Doublelist);
printDL(Doublelist);
popback(Doublelist);
printDL(Doublelist);
insertpos(Doublelist, 3, 44);
printDL(Doublelist);
findlist(Doublelist, 44);
findlist(Doublelist, 10);
modifylist(Doublelist, 3, 1000);
printDL(Doublelist);
}
void main()
{
test1();
}这部分代码增删查改的步骤都比较简单,读者可以自行根据代码标识进行阅读,
需要注意的是,里面仍有一些判断可以完善,如有需要可以自行完善,这部分代码仅仅是一个简单的带头双向循环链表的制作