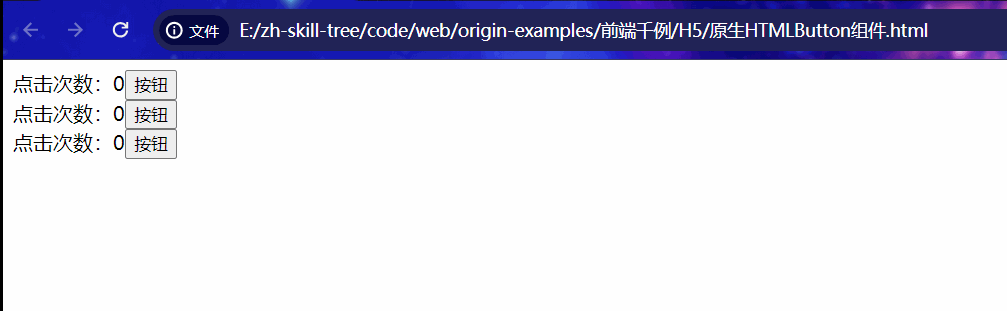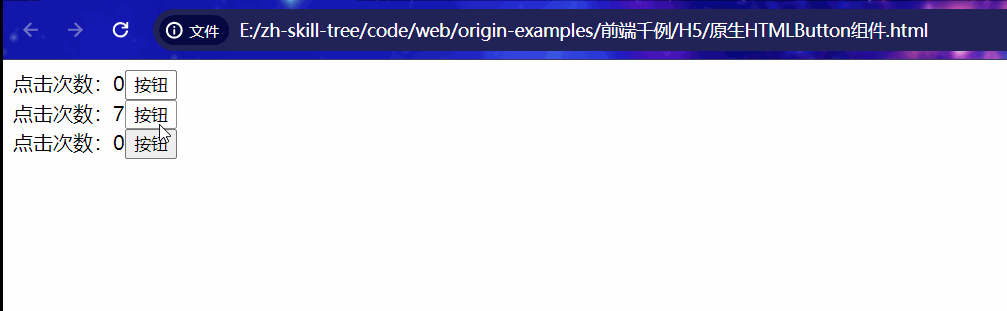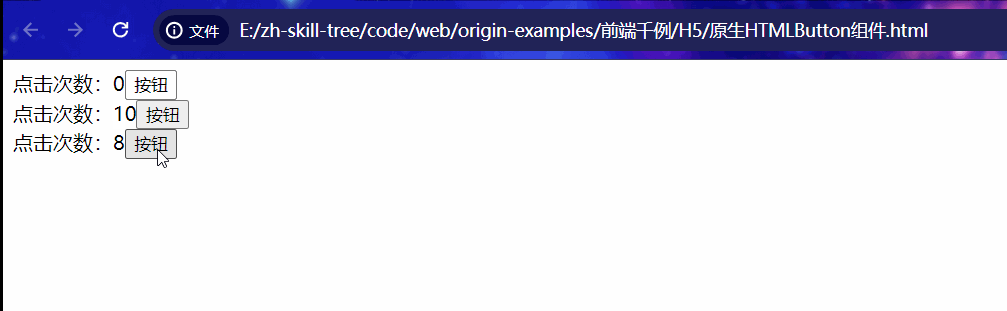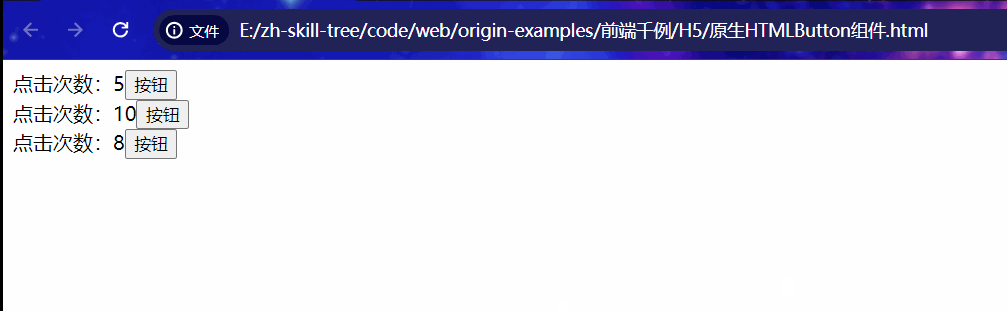
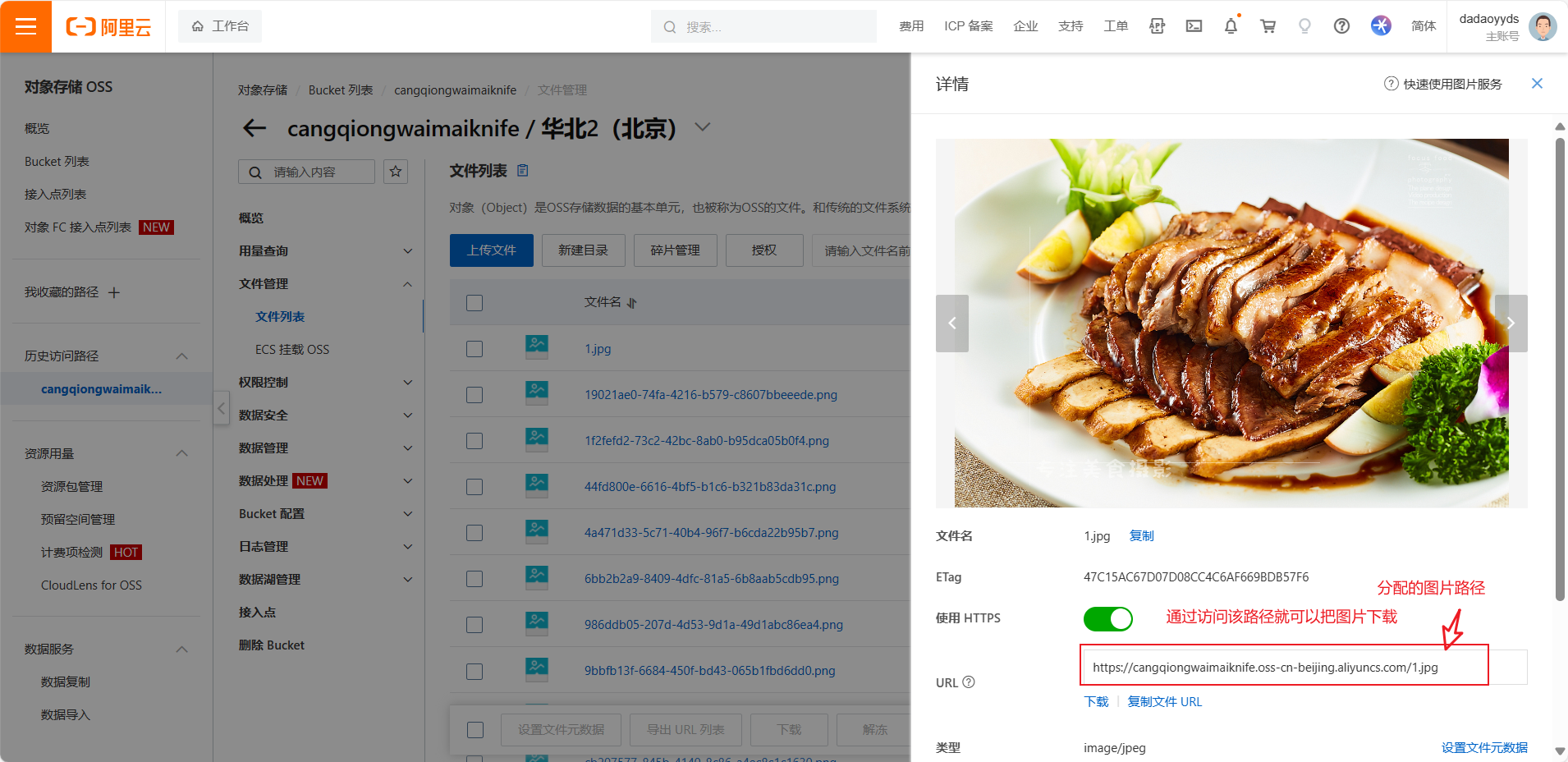
本篇来自于MuSe-GNN: Learning Unified Gene Representation From Multimodal Biological Graph Data的补充材料。主要目的是从多模态数据中构建共表达网络。作者概述了使用CS-CORE,scTransform和SPARK-X进行预处理步骤和网络构建的算法细节。
目前存在大量用于图谱级转录组和表观基因组数据分析的数据库(比如HCA,HuBMAP),作者收集了来自HCA的scRNA-seq,来自HuBMAP的scATAC-seq,以及来自其他数据库的高质量空间数据。对于不同的组学数据,作者实现了一个通用的过程。
在常规流程中,对于scRNAseq数据集,作者使用scTransform选择hvg并生成Pearson残差,将原始表达式替换为残差。scTransform是第一个将排序深度作为协变量而不是直接将大小因子应用于归一化的模型。它消除了由原始单细胞或空间表达数据的测序深度造成的混淆,从而生成正确的基因表达谱。这些优点使其成为广泛使用的归一化方法。
为了构建基于唯一分子标识符(Unique Molecular Identifier, UMI)的scRNA-seq数据集共表达网络,作者使用了CS-CORE,这是一种基于UMI计数数据的最先进的共表达推断工具。与其他工具相比,CS-CORE具有更高的鲁棒性和更低的假阳性率。对于scATAC-seq数据集,使用Seurat将原始细胞峰矩阵转换为细胞-基因活性矩阵,并纳入先验信息。细胞-基因活性矩阵的处理方法与scRNA-seq数据矩阵类似,因此后续的预处理步骤保持不变。
为了构建空间数据共表达网络,作者考虑了空间表达模式(SE基因或空间hvg),并将每个条形码作为一个样本。作者使用SPARK-X识别SE基因,然后基于scTransform和基于CS-CORE的共表达网络生成校正后的基因表达谱与共表达网络。
CS-CORE
由于数据为UMI类型,因此可以使用CS-CORE进行共表达网络构建。考虑有
n
n
n个细胞,对于细胞
i
i
i,表达谱可以表示为向量
(
x
i
1
,
.
.
.
,
x
i
p
)
(x_{i1},...,x_{ip})
(xi1,...,xip),
p
p
p是基因的数量。我们也可以使用
s
i
s_{i}
si表示细胞
i
i
i的测序深度。考虑到细胞
i
i
i中
p
p
p个基因的潜在表达水平为
(
z
i
1
,
.
.
.
,
z
i
p
)
(z_{i1},...,z_{ip})
(zi1,...,zip),CS-CORE的假设遵循:
(
z
i
1
,
.
.
.
,
z
i
p
)
∼
F
p
(
μ
,
Σ
)
,
x
i
j
∣
z
i
j
∼
P
o
i
s
s
o
n
(
s
i
z
i
j
)
(z_{i1},...,z_{ip})\sim F_{p}(\mu,\Sigma),\thinspace\thinspace x_{ij}|z_{ij}\sim Poisson(s_{i}z_{ij})
(zi1,...,zip)∼Fp(μ,Σ),xij∣zij∼Poisson(sizij)其中,
F
p
F_{p}
Fp是未知的非负p-variate分布,均值为
μ
\mu
μ,协方差矩阵为
Σ
\Sigma
Σ。CS-CORE采用一种基于矩的迭代加权最小二乘(IRLS)估计方法来估计协方差矩阵。一旦获得
Σ
p
×
p
=
[
σ
i
j
]
\Sigma_{p\times p}=[\sigma_{ij}]
Σp×p=[σij],就能估计基因
j
j
j和
j
′
j'
j′之间的共表达关系为
ρ
j
j
′
=
σ
j
j
′
σ
j
j
σ
j
′
j
′
\rho_{jj'}=\frac{\sigma_{jj'}}{\sqrt{\sigma_{jj}\sigma_{j'j'}}}
ρjj′=σjjσj′j′σjj′。
scTransform
为了消除测序深度对表达水平的混淆影响,作者首先使用scTransform对单细胞数据进行处理,得到Pearson残差,然后使用Pearson残差作为不同基因的初始embedding。假设UMI计数数据服从负二项分布,对于细胞
c
c
c中给定的基因
g
g
g,我们有:
x
g
c
∼
N
B
(
μ
g
c
,
θ
g
)
I
n
μ
g
c
=
β
g
0
+
I
n
s
c
x_{gc}\sim NB(\mu_{gc},\theta_{g})\\ In\thinspace\mu_{gc}=\beta_{g0}+In\thinspace s_{c}
xgc∼NB(μgc,θg)Inμgc=βg0+InscscTransform利用广义线性模型将
θ
\theta
θ正则化为基因均值
μ
\mu
μ的函数。进一步,可以估计未知参数,计算Pearson残差
Z
g
c
Z_{gc}
Zgc:
Z
g
c
=
x
g
c
−
μ
g
c
σ
g
c
μ
g
c
=
e
x
p
(
β
g
0
+
I
n
s
c
)
σ
g
c
=
μ
g
c
+
μ
g
c
2
θ
g
c
Z_{gc}=\frac{x_{gc}-\mu_{gc}}{\sigma_{gc}}\\ \mu_{gc}=exp(\beta_{g0}+In\thinspace s_{c})\\ \sigma_{gc}=\sqrt{\mu_{gc}+\frac{\mu_{gc}^{2}}{\theta_{gc}}}
Zgc=σgcxgc−μgcμgc=exp(βg0+Insc)σgc=μgc+θgcμgc2最后,可以用广义线性模型生成的残差矩阵
Z
Z
Z代替原始表达式矩阵,并将表达式矩阵和对应的Graph存储在scanpy文件中。
SPARK-X
单细胞转录组数据和空间转录组数据的主要区别包括两个方面:
- 1在大多数空间分辨数据中,每个条形码代表不同细胞的混合。
- 2额外的空间信息为空间数据引入了基因的空间表达模式(SE基因)。
为了在空间转录组数据中识别SE基因,SPARK-X采用了一种统计检验,利用位置构建的距离协方差矩阵和利用基因表达谱构建的表达协方差矩阵。
更具体地说,对于大小为 n × d n × d n×d的空间转录组基因表达矩阵,样本坐标的矩阵为: S = ( s 1 T , . . . , s n T ) , s i = ( s i 2 , s i 2 ) S=(s_{1}^{T},...,s_{n}^{T}),s_{i}=(s_{i2},s_{i2}) S=(s1T,...,snT),si=(si2,si2)。整个表达式矩阵可以表示为: y = ( y 1 ( s 1 ) , . . . , y n ( s n ) ) T y=(y_{1}(s_{1}),...,y_{n}(s_{n}))^{T} y=(y1(s1),...,yn(sn))T。目标是检验 y y y是否独立于 S S S,因此基于 E = y ( y T y ) − 1 y T E=y(y^{T}y)^{-1}y^{T} E=y(yTy)−1yT构造表达协方差矩阵,基于 Σ = S ( S T S ) − 1 S T \Sigma=S(S^{T}S)^{-1}S^{T} Σ=S(STS)−1ST构造距离协方差矩阵。对 E E E和 Σ \Sigma Σ检验,按照p值排序,选择前1000个基因进行归一化和共表达Graph构建。

- 多模态数据构建共表达网络的统一过程。





![MSF永恒之蓝漏洞利用详解[漏洞验证利用及后渗透]【详细版】](https://img-blog.csdnimg.cn/direct/fdb42af48fb746709be668159bed03c0.png)