interface 接口,分为有方法签名的接口和空接口
interface{fn()…} 有方法签名的接口,底层运行时结构 iface
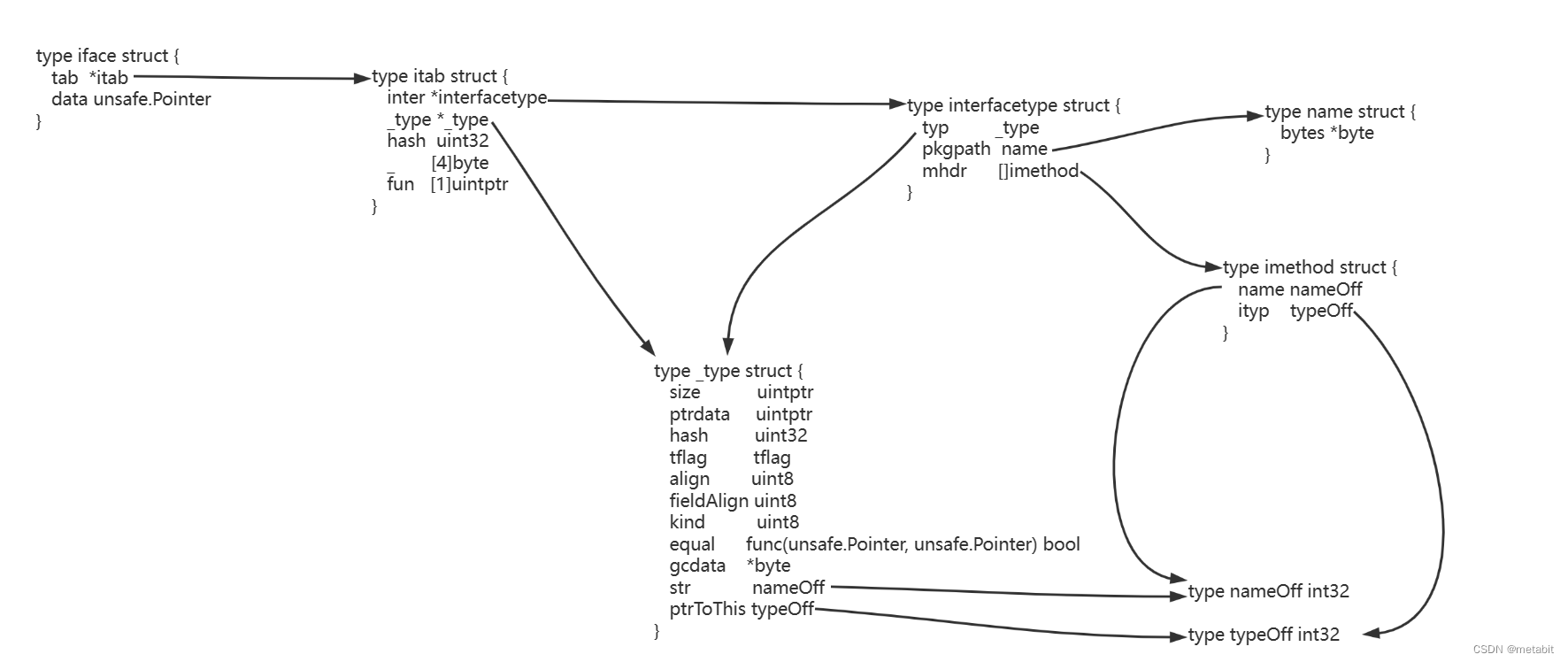
iface
src/runtime/runtime2.go
type iface struct {
tab *itab // 接口类型itab, i-table的缩写
data unsafe.Pointer // 接口值指针
}
itab
// layout of Itab known to compilers
// allocated in non-garbage-collected memory
// Needs to be in sync with
// ../cmd/compile/internal/reflectdata/reflect.go:/^func.WriteTabs.
type itab struct {
inter *interfacetype // 接口类型
_type *_type // 实体类型,具体的某个类型
hash uint32 // copy of _type.hash. Used for type switches. 哈希值
_ [4]byte // 内存对齐占位
fun [1]uintptr // variable sized. fun[0]==0 means _type does not implement inter. 第0个函数指针,其后保存一系列的函数入口
}
interfacetype
src/runtime/type.go
type interfacetype struct {
typ _type // 元类型,所有类型几乎都从_type开始封装,其可以是结构体等
pkgpath name // 包路径
mhdr []imethod// 对函数名与函数类型封装的列表,该列表也就是接口拥有的方法列表
}
_type
src/runtime/type.go
// Needs to be in sync with ../cmd/link/internal/ld/decodesym.go:/^func.commonsize,
// ../cmd/compile/internal/reflectdata/reflect.go:/^func.dcommontype and
// ../reflect/type.go:/^type.rtype.
// ../internal/reflectlite/type.go:/^type.rtype.
type _type struct {
size uintptr
ptrdata uintptr // size of memory prefix holding all pointers
hash uint32
tflag tflag
align uint8
fieldAlign uint8
kind uint8
// function for comparing objects of this type
// (ptr to object A, ptr to object B) -> ==?
equal func(unsafe.Pointer, unsafe.Pointer) bool
// gcdata stores the GC type data for the garbage collector.
// If the KindGCProg bit is set in kind, gcdata is a GC program.
// Otherwise it is a ptrmask bitmap. See mbitmap.go for details.
gcdata *byte
str nameOff
ptrToThis typeOff
}
name
src/runtime/type.go
// name is an encoded type name with optional extra data.
// See reflect/type.go for details.
type name struct {
bytes *byte
}
imethod
src/runtime/type.go
type imethod struct {
name nameOff // 方法名的偏移
ityp typeOff // 方法类型的偏移
}
nameOff, typeOff, textOff
src/runtime/type.go
type nameOff int32
type typeOff int32
type textOff int32
src/runtime/type.go
resolveNameOff和resolveTypeOff方法可以定位到方法的名称和类型
func resolveNameOff(ptrInModule unsafe.Pointer, off nameOff) name {
if off == 0 {
return name{}
}
base := uintptr(ptrInModule)
for md := &firstmoduledata; md != nil; md = md.next {
if base >= md.types && base < md.etypes {
res := md.types + uintptr(off)
if res > md.etypes {
println("runtime: nameOff", hex(off), "out of range", hex(md.types), "-", hex(md.etypes))
throw("runtime: name offset out of range")
}
return name{(*byte)(unsafe.Pointer(res))}
}
}
// No module found. see if it is a run time name.
reflectOffsLock()
res, found := reflectOffs.m[int32(off)]
reflectOffsUnlock()
if !found {
println("runtime: nameOff", hex(off), "base", hex(base), "not in ranges:")
for next := &firstmoduledata; next != nil; next = next.next {
println("\ttypes", hex(next.types), "etypes", hex(next.etypes))
}
throw("runtime: name offset base pointer out of range")
}
return name{(*byte)(res)}
}
func (t *_type) nameOff(off nameOff) name {
return resolveNameOff(unsafe.Pointer(t), off)
}
func resolveTypeOff(ptrInModule unsafe.Pointer, off typeOff) *_type {
if off == 0 || off == -1 {
// -1 is the sentinel value for unreachable code.
// See cmd/link/internal/ld/data.go:relocsym.
return nil
}
base := uintptr(ptrInModule)
var md *moduledata
for next := &firstmoduledata; next != nil; next = next.next {
if base >= next.types && base < next.etypes {
md = next
break
}
}
if md == nil {
reflectOffsLock()
res := reflectOffs.m[int32(off)]
reflectOffsUnlock()
if res == nil {
println("runtime: typeOff", hex(off), "base", hex(base), "not in ranges:")
for next := &firstmoduledata; next != nil; next = next.next {
println("\ttypes", hex(next.types), "etypes", hex(next.etypes))
}
throw("runtime: type offset base pointer out of range")
}
return (*_type)(res)
}
if t := md.typemap[off]; t != nil {
return t
}
res := md.types + uintptr(off)
if res > md.etypes {
println("runtime: typeOff", hex(off), "out of range", hex(md.types), "-", hex(md.etypes))
throw("runtime: type offset out of range")
}
return (*_type)(unsafe.Pointer(res))
}
func (t *_type) typeOff(off typeOff) *_type {
return resolveTypeOff(unsafe.Pointer(t), off)
}
interface{} 空接口,底层运行时结构 eface

eface
type eface struct {
_type *_type //接口类型,类型同上述类型
data unsafe.Pointer //接口值
}
接口原理
src/runtime/iface.go
const itabInitSize = 512
var (
itabLock mutex // lock for accessing itab table
itabTable = &itabTableInit // pointer to current table
itabTableInit = itabTableType{size: itabInitSize} // starter table
)
// Note: change the formula in the mallocgc call in itabAdd if you change these fields.
type itabTableType struct {
size uintptr // length of entries array. Always a power of 2.
count uintptr // current number of filled entries.
entries [itabInitSize]*itab // really [size] large
}
带有方法签名的接口,其底层维护了一个全局的itabTable变量,该变量中保存了*itab哈希表。接口的动态特性由其itab类型决定。Go语言中只要实现一个接口中的所有方法,那么即隐式的实现了该接口。
如何确定一个类型是否实现了某个接口呢?在Go的编译时,编译器会根据需要对接口中的方法按规则排序,同时对类型绑定的方法也按规则排序,此时只要很少的时间开销,就可以根据方法名和方法类型来确定某个类型是否实现了某个接口。
itabHashFunc 通过异或计算hash值
func itabHashFunc(inter *interfacetype, typ *_type) uintptr {
// compiler has provided some good hash codes for us.
return uintptr(inter.typ.hash ^ typ.hash)
}
getitab 获取itab指针
func getitab(inter *interfacetype, typ *_type, canfail bool) *itab {
if len(inter.mhdr) == 0 { //没有方法的摘要
throw("internal error - misuse of itab")
}
// easy case
if typ.tflag&tflagUncommon == 0 {
if canfail {
return nil
}
name := inter.typ.nameOff(inter.mhdr[0].name)
panic(&TypeAssertionError{nil, typ, &inter.typ, name.name()})
}
var m *itab
// First, look in the existing table to see if we can find the itab we need.
// This is by far the most common case, so do it without locks.
// Use atomic to ensure we see any previous writes done by the thread
// that updates the itabTable field (with atomic.Storep in itabAdd).
t := (*itabTableType)(atomic.Loadp(unsafe.Pointer(&itabTable)))
if m = t.find(inter, typ); m != nil { //寻找itab,找到则直接跳转finish
goto finish
}
// Not found. Grab the lock and try again. 没找到则上锁再找一遍
lock(&itabLock) //上锁
if m = itabTable.find(inter, typ); m != nil {
unlock(&itabLock)
goto finish
}
// Entry doesn't exist yet. Make a new entry & add it. 若仍未找到,则创建一个*itab,并加入全局变量
m = (*itab)(persistentalloc(unsafe.Sizeof(itab{})+uintptr(len(inter.mhdr)-1)*goarch.PtrSize, 0, &memstats.other_sys))
m.inter = inter
m._type = typ
// The hash is used in type switches. However, compiler statically generates itab's
// for all interface/type pairs used in switches (which are added to itabTable
// in itabsinit). The dynamically-generated itab's never participate in type switches,
// and thus the hash is irrelevant.
// Note: m.hash is _not_ the hash used for the runtime itabTable hash table.
m.hash = 0
m.init() //初始化操作
itabAdd(m) //加入全局变量
unlock(&itabLock) //解锁
finish:
if m.fun[0] != 0 { //方法有效
return m
}
if canfail {
return nil
}
// this can only happen if the conversion
// was already done once using the , ok form
// and we have a cached negative result.
// The cached result doesn't record which
// interface function was missing, so initialize
// the itab again to get the missing function name.
panic(&TypeAssertionError{concrete: typ, asserted: &inter.typ, missingMethod: m.init()})
}
find 根据给定类型寻找*itab
// find finds the given interface/type pair in t.
// Returns nil if the given interface/type pair isn't present.
func (t *itabTableType) find(inter *interfacetype, typ *_type) *itab {
// Implemented using quadratic probing.
// Probe sequence is h(i) = h0 + i*(i+1)/2 mod 2^k.
// We're guaranteed to hit all table entries using this probe sequence.
mask := t.size - 1 //掩码,防止越界
h := itabHashFunc(inter, typ) & mask //计算hash值
for i := uintptr(1); ; i++ { //在全局变量的hash表中,线性查找
p := (**itab)(add(unsafe.Pointer(&t.entries), h*goarch.PtrSize)) //获取hash中的地址
// Use atomic read here so if we see m != nil, we also see
// the initializations of the fields of m.
// m := *p
m := (*itab)(atomic.Loadp(unsafe.Pointer(p))) //加载地址的内容
if m == nil { //未找到,返回nil
return nil
}
if m.inter == inter && m._type == typ { //找到了
return m //返回m
}
h += i // 线性递增
h &= mask // 重新计算位置,防止越界
}
}
itabAdd 向全局变量的hash表中加入*itab
// itabAdd adds the given itab to the itab hash table.
// itabLock must be held.
func itabAdd(m *itab) {
// Bugs can lead to calling this while mallocing is set,
// typically because this is called while panicing.
// Crash reliably, rather than only when we need to grow
// the hash table.
if getg().m.mallocing != 0 {
throw("malloc deadlock")
}
t := itabTable //全局table
if t.count >= 3*(t.size/4) { // 75% load factor hash表中元素超过75%时,再次添加元素会引发扩容,大概二倍扩容
// Grow hash table.
// t2 = new(itabTableType) + some additional entries
// We lie and tell malloc we want pointer-free memory because
// all the pointed-to values are not in the heap.
t2 := (*itabTableType)(mallocgc((2+2*t.size)*goarch.PtrSize, nil, true)) //分配容量
t2.size = t.size * 2 //size扩大到2倍
// Copy over entries. 复制之前的成员到新地址
// Note: while copying, other threads may look for an itab and
// fail to find it. That's ok, they will then try to get the itab lock
// and as a consequence wait until this copying is complete.
iterate_itabs(t2.add)
if t2.count != t.count {
throw("mismatched count during itab table copy")
}
// Publish new hash table. Use an atomic write: see comment in getitab.
atomicstorep(unsafe.Pointer(&itabTable), unsafe.Pointer(t2))
// Adopt the new table as our own.
t = itabTable
// Note: the old table can be GC'ed here.
}
t.add(m) //执行添加逻辑
}
add 向全局hash表中添加*itab的逻辑
// add adds the given itab to itab table t.
// itabLock must be held.
func (t *itabTableType) add(m *itab) {
// See comment in find about the probe sequence.
// Insert new itab in the first empty spot in the probe sequence.
mask := t.size - 1 //计算掩码
h := itabHashFunc(m.inter, m._type) & mask //计算hash值
for i := uintptr(1); ; i++ {
p := (**itab)(add(unsafe.Pointer(&t.entries), h*goarch.PtrSize)) //计算地址
m2 := *p
if m2 == m { //全局hash表中已经由*itab,则直接返回,不做处理
// A given itab may be used in more than one module
// and thanks to the way global symbol resolution works, the
// pointed-to itab may already have been inserted into the
// global 'hash'.
return
}
if m2 == nil { //当前地址可用,则插入,并更新count,返回
// Use atomic write here so if a reader sees m, it also
// sees the correctly initialized fields of m.
// NoWB is ok because m is not in heap memory.
// *p = m
atomic.StorepNoWB(unsafe.Pointer(p), unsafe.Pointer(m))
t.count++
return
}
h += i //线性查找下一个位置
h &= mask //防止越界
}
}
init *itab的初始化,init使用所有的方法指针填充m.fun数组,若该类型没有实现接口,则将m.fun[0]设置为0,并返回缺少的接口函数的名称。
// init fills in the m.fun array with all the code pointers for
// the m.inter/m._type pair. If the type does not implement the interface,
// it sets m.fun[0] to 0 and returns the name of an interface function that is missing.
// It is ok to call this multiple times on the same m, even concurrently.
func (m *itab) init() string {
inter := m.inter
typ := m._type
x := typ.uncommon()
// both inter and typ have method sorted by name,
// and interface names are unique,
// so can iterate over both in lock step;
// the loop is O(ni+nt) not O(ni*nt).
ni := len(inter.mhdr)
nt := int(x.mcount)
xmhdr := (*[1 << 16]method)(add(unsafe.Pointer(x), uintptr(x.moff)))[:nt:nt]
j := 0
methods := (*[1 << 16]unsafe.Pointer)(unsafe.Pointer(&m.fun[0]))[:ni:ni]
var fun0 unsafe.Pointer
imethods:
for k := 0; k < ni; k++ {
i := &inter.mhdr[k]
itype := inter.typ.typeOff(i.ityp)
name := inter.typ.nameOff(i.name)
iname := name.name()
ipkg := name.pkgPath()
if ipkg == "" {
ipkg = inter.pkgpath.name()
}
for ; j < nt; j++ {
t := &xmhdr[j]
tname := typ.nameOff(t.name)
if typ.typeOff(t.mtyp) == itype && tname.name() == iname {
pkgPath := tname.pkgPath()
if pkgPath == "" {
pkgPath = typ.nameOff(x.pkgpath).name()
}
if tname.isExported() || pkgPath == ipkg {
if m != nil {
ifn := typ.textOff(t.ifn)
if k == 0 {
fun0 = ifn // we'll set m.fun[0] at the end
} else {
methods[k] = ifn
}
}
continue imethods
}
}
}
// didn't find method
m.fun[0] = 0
return iname
}
m.fun[0] = uintptr(fun0)
return ""
}
itabsinit 初始化itabs
func itabsinit() {
lockInit(&itabLock, lockRankItab) //初始化锁
lock(&itabLock) //上锁
for _, md := range activeModules() {
for _, i := range md.itablinks {
itabAdd(i) //加入itab全局hash表
}
}
unlock(&itabLock)
}
panic相关
// panicdottypeE is called when doing an e.(T) conversion and the conversion fails.
// have = the dynamic type we have.
// want = the static type we're trying to convert to.
// iface = the static type we're converting from.
func panicdottypeE(have, want, iface *_type) {
panic(&TypeAssertionError{iface, have, want, ""})
}
// panicdottypeI is called when doing an i.(T) conversion and the conversion fails.
// Same args as panicdottypeE, but "have" is the dynamic itab we have.
func panicdottypeI(have *itab, want, iface *_type) {
var t *_type
if have != nil {
t = have._type
}
panicdottypeE(t, want, iface)
}
// panicnildottype is called when doing a i.(T) conversion and the interface i is nil.
// want = the static type we're trying to convert to.
func panicnildottype(want *_type) {
panic(&TypeAssertionError{nil, nil, want, ""})
// TODO: Add the static type we're converting from as well.
// It might generate a better error message.
// Just to match other nil conversion errors, we don't for now.
}
常用数据类型初始化
// The specialized convTx routines need a type descriptor to use when calling mallocgc.
// We don't need the type to be exact, just to have the correct size, alignment, and pointer-ness.
// However, when debugging, it'd be nice to have some indication in mallocgc where the types came from,
// so we use named types here.
// We then construct interface values of these types,
// and then extract the type word to use as needed.
type (
uint16InterfacePtr uint16
uint32InterfacePtr uint32
uint64InterfacePtr uint64
stringInterfacePtr string
sliceInterfacePtr []byte
)
var (
uint16Eface any = uint16InterfacePtr(0)
uint32Eface any = uint32InterfacePtr(0)
uint64Eface any = uint64InterfacePtr(0)
stringEface any = stringInterfacePtr("")
sliceEface any = sliceInterfacePtr(nil)
uint16Type *_type = efaceOf(&uint16Eface)._type
uint32Type *_type = efaceOf(&uint32Eface)._type
uint64Type *_type = efaceOf(&uint64Eface)._type
stringType *_type = efaceOf(&stringEface)._type
sliceType *_type = efaceOf(&sliceEface)._type
)
efaceOf 类型转换
func efaceOf(ep *any) *eface {
return (*eface)(unsafe.Pointer(ep))
}
类型转换与类型断言
// The conv and assert functions below do very similar things.
// The convXXX functions are guaranteed by the compiler to succeed.
// The assertXXX functions may fail (either panicking or returning false,
// depending on whether they are 1-result or 2-result).
// The convXXX functions succeed on a nil input, whereas the assertXXX
// functions fail on a nil input.
// convT converts a value of type t, which is pointed to by v, to a pointer that can
// be used as the second word of an interface value.
func convT(t *_type, v unsafe.Pointer) unsafe.Pointer {
if raceenabled {
raceReadObjectPC(t, v, getcallerpc(), abi.FuncPCABIInternal(convT))
}
if msanenabled {
msanread(v, t.size)
}
if asanenabled {
asanread(v, t.size)
}
x := mallocgc(t.size, t, true)
typedmemmove(t, x, v)
return x
}
func convTnoptr(t *_type, v unsafe.Pointer) unsafe.Pointer {
// TODO: maybe take size instead of type?
if raceenabled {
raceReadObjectPC(t, v, getcallerpc(), abi.FuncPCABIInternal(convTnoptr))
}
if msanenabled {
msanread(v, t.size)
}
if asanenabled {
asanread(v, t.size)
}
x := mallocgc(t.size, t, false)
memmove(x, v, t.size)
return x
}
func convT16(val uint16) (x unsafe.Pointer) {
if val < uint16(len(staticuint64s)) {
x = unsafe.Pointer(&staticuint64s[val])
if goarch.BigEndian {
x = add(x, 6)
}
} else {
x = mallocgc(2, uint16Type, false)
*(*uint16)(x) = val
}
return
}
func convT32(val uint32) (x unsafe.Pointer) {
if val < uint32(len(staticuint64s)) {
x = unsafe.Pointer(&staticuint64s[val])
if goarch.BigEndian {
x = add(x, 4)
}
} else {
x = mallocgc(4, uint32Type, false)
*(*uint32)(x) = val
}
return
}
func convT64(val uint64) (x unsafe.Pointer) {
if val < uint64(len(staticuint64s)) {
x = unsafe.Pointer(&staticuint64s[val])
} else {
x = mallocgc(8, uint64Type, false)
*(*uint64)(x) = val
}
return
}
func convTstring(val string) (x unsafe.Pointer) {
if val == "" {
x = unsafe.Pointer(&zeroVal[0])
} else {
x = mallocgc(unsafe.Sizeof(val), stringType, true)
*(*string)(x) = val
}
return
}
func convTslice(val []byte) (x unsafe.Pointer) {
// Note: this must work for any element type, not just byte.
if (*slice)(unsafe.Pointer(&val)).array == nil {
x = unsafe.Pointer(&zeroVal[0])
} else {
x = mallocgc(unsafe.Sizeof(val), sliceType, true)
*(*[]byte)(x) = val
}
return
}
// convI2I returns the new itab to be used for the destination value
// when converting a value with itab src to the dst interface.
func convI2I(dst *interfacetype, src *itab) *itab {
if src == nil {
return nil
}
if src.inter == dst {
return src
}
return getitab(dst, src._type, false)
}
func assertI2I(inter *interfacetype, tab *itab) *itab {
if tab == nil {
// explicit conversions require non-nil interface value.
panic(&TypeAssertionError{nil, nil, &inter.typ, ""})
}
if tab.inter == inter {
return tab
}
return getitab(inter, tab._type, false)
}
func assertI2I2(inter *interfacetype, i iface) (r iface) {
tab := i.tab
if tab == nil {
return
}
if tab.inter != inter {
tab = getitab(inter, tab._type, true)
if tab == nil {
return
}
}
r.tab = tab
r.data = i.data
return
}
func assertE2I(inter *interfacetype, t *_type) *itab {
if t == nil {
// explicit conversions require non-nil interface value.
panic(&TypeAssertionError{nil, nil, &inter.typ, ""})
}
return getitab(inter, t, false)
}
func assertE2I2(inter *interfacetype, e eface) (r iface) {
t := e._type
if t == nil {
return
}
tab := getitab(inter, t, true)
if tab == nil {
return
}
r.tab = tab
r.data = e.data
return
}
reflect相关
//go:linkname reflect_ifaceE2I reflect.ifaceE2I
func reflect_ifaceE2I(inter *interfacetype, e eface, dst *iface) {
*dst = iface{assertE2I(inter, e._type), e.data}
}
//go:linkname reflectlite_ifaceE2I internal/reflectlite.ifaceE2I
func reflectlite_ifaceE2I(inter *interfacetype, e eface, dst *iface) {
*dst = iface{assertE2I(inter, e._type), e.data}
}
iterate_itabs 迭代itabs全局hash表
func iterate_itabs(fn func(*itab)) {
// Note: only runs during stop the world or with itabLock held,
// so no other locks/atomics needed.
t := itabTable
for i := uintptr(0); i < t.size; i++ {
m := *(**itab)(add(unsafe.Pointer(&t.entries), i*goarch.PtrSize))
if m != nil {
fn(m) //对m执行回调fn
}
}
}
全局数据表,staticuint64s用于避免在convTx中为小整数值分配
// staticuint64s is used to avoid allocating in convTx for small integer values.
var staticuint64s = [...]uint64{
0x00, 0x01, 0x02, 0x03, 0x04, 0x05, 0x06, 0x07,
0x08, 0x09, 0x0a, 0x0b, 0x0c, 0x0d, 0x0e, 0x0f,
0x10, 0x11, 0x12, 0x13, 0x14, 0x15, 0x16, 0x17,
0x18, 0x19, 0x1a, 0x1b, 0x1c, 0x1d, 0x1e, 0x1f,
0x20, 0x21, 0x22, 0x23, 0x24, 0x25, 0x26, 0x27,
0x28, 0x29, 0x2a, 0x2b, 0x2c, 0x2d, 0x2e, 0x2f,
0x30, 0x31, 0x32, 0x33, 0x34, 0x35, 0x36, 0x37,
0x38, 0x39, 0x3a, 0x3b, 0x3c, 0x3d, 0x3e, 0x3f,
0x40, 0x41, 0x42, 0x43, 0x44, 0x45, 0x46, 0x47,
0x48, 0x49, 0x4a, 0x4b, 0x4c, 0x4d, 0x4e, 0x4f,
0x50, 0x51, 0x52, 0x53, 0x54, 0x55, 0x56, 0x57,
0x58, 0x59, 0x5a, 0x5b, 0x5c, 0x5d, 0x5e, 0x5f,
0x60, 0x61, 0x62, 0x63, 0x64, 0x65, 0x66, 0x67,
0x68, 0x69, 0x6a, 0x6b, 0x6c, 0x6d, 0x6e, 0x6f,
0x70, 0x71, 0x72, 0x73, 0x74, 0x75, 0x76, 0x77,
0x78, 0x79, 0x7a, 0x7b, 0x7c, 0x7d, 0x7e, 0x7f,
0x80, 0x81, 0x82, 0x83, 0x84, 0x85, 0x86, 0x87,
0x88, 0x89, 0x8a, 0x8b, 0x8c, 0x8d, 0x8e, 0x8f,
0x90, 0x91, 0x92, 0x93, 0x94, 0x95, 0x96, 0x97,
0x98, 0x99, 0x9a, 0x9b, 0x9c, 0x9d, 0x9e, 0x9f,
0xa0, 0xa1, 0xa2, 0xa3, 0xa4, 0xa5, 0xa6, 0xa7,
0xa8, 0xa9, 0xaa, 0xab, 0xac, 0xad, 0xae, 0xaf,
0xb0, 0xb1, 0xb2, 0xb3, 0xb4, 0xb5, 0xb6, 0xb7,
0xb8, 0xb9, 0xba, 0xbb, 0xbc, 0xbd, 0xbe, 0xbf,
0xc0, 0xc1, 0xc2, 0xc3, 0xc4, 0xc5, 0xc6, 0xc7,
0xc8, 0xc9, 0xca, 0xcb, 0xcc, 0xcd, 0xce, 0xcf,
0xd0, 0xd1, 0xd2, 0xd3, 0xd4, 0xd5, 0xd6, 0xd7,
0xd8, 0xd9, 0xda, 0xdb, 0xdc, 0xdd, 0xde, 0xdf,
0xe0, 0xe1, 0xe2, 0xe3, 0xe4, 0xe5, 0xe6, 0xe7,
0xe8, 0xe9, 0xea, 0xeb, 0xec, 0xed, 0xee, 0xef,
0xf0, 0xf1, 0xf2, 0xf3, 0xf4, 0xf5, 0xf6, 0xf7,
0xf8, 0xf9, 0xfa, 0xfb, 0xfc, 0xfd, 0xfe, 0xff,
}
// The linker redirects a reference of a method that it determined
// unreachable to a reference to this function, so it will throw if
// ever called.
func unreachableMethod() {
throw("unreachable method called. linker bug?")
}
写在最后
由于时间关系,只能简单分析了,具体的分析过程可以放在以后。
所有接口的itab都会被加入到全局的hash表中,有些接口发生转换时会创建新的itab并加入全局hash表。全局hash表只增不减,当其中*itab个数到达其容量的75%时,会触发二倍的扩容。
接口中有动态类型和动态值的概念,在发生转换时,可能存在内存逃逸,调用接口中的方法与直接调用类型的方法之间是有性能差异的。
只有当一个接口的动态类型和动态值都是nil的时候,该接口才是nil的。
突然想到一个有趣的场景,在过去,每当“大促”来临前,很多电商网站后台都会尝试重启,之后用大量的测试数据来让运行中的代码分支“热”起来。即尽可能的触发各种场景,让代码在内存中是热的(比如我们接口转换的场景),这样一来,用户触发的操作就很少造成促销过程中临时加载代码的情况,从而保障网站运行的更加平稳,效率更高。









![阿拉伯数转中文与英文[找到规律,抽象问题,转换成代码]](https://img-blog.csdnimg.cn/18f8f3cb1f444667aeacdb9c0d379257.png)