堆
- 1.堆的概念
- 2.堆的实现 (建小堆为例)
- 2.1 初始化和销毁
- 2.2 判空
- 2.3 获得堆顶元素和堆的大小
- 2.4 插入
- 2.5 删除
- 3.堆的构建(建小堆为例)
1.堆的概念
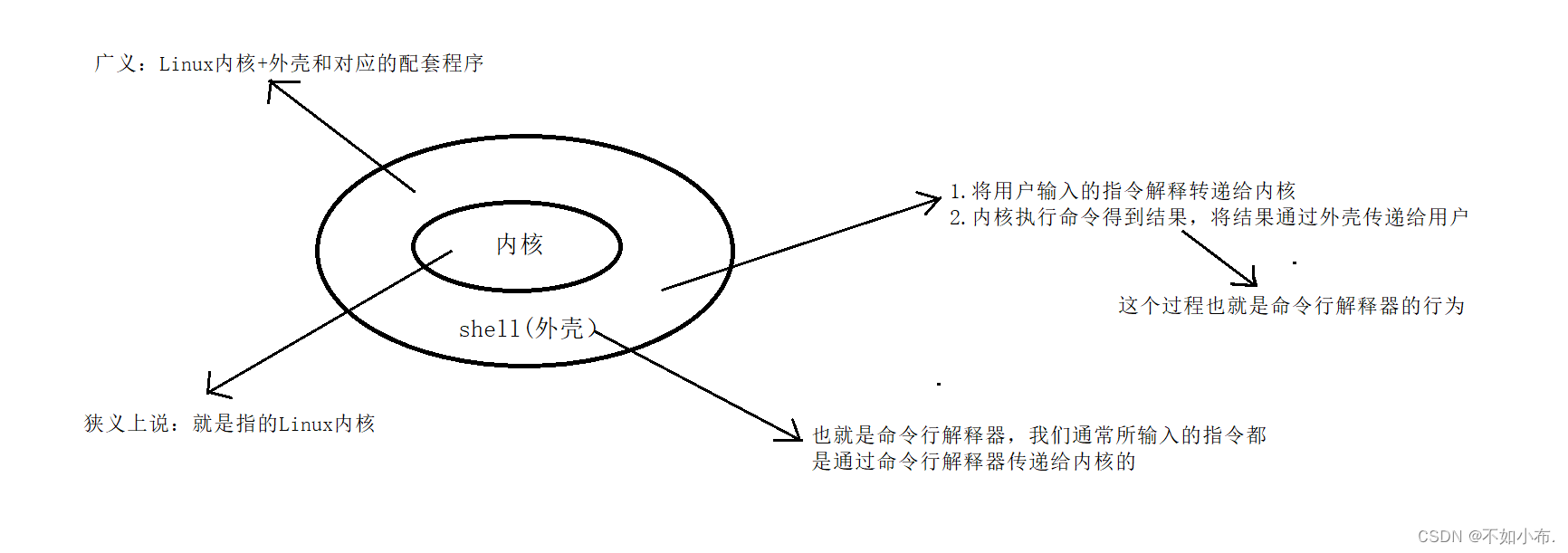
将若干数据或元素按照完全二叉树的存储方式顺序存储到一个一维数组中,在逻辑结构中(完全二叉树)满足每个根结点的值不大于或不小于它的左右孩子结点的值。满足上述条件称为小堆或大堆。
堆的性质:堆中某节点的值不大于或不小于双亲结点的值;堆在逻辑结构上是一棵完全二叉树。
比如下图是一个小堆 (数据的增删都以这个数组为例)
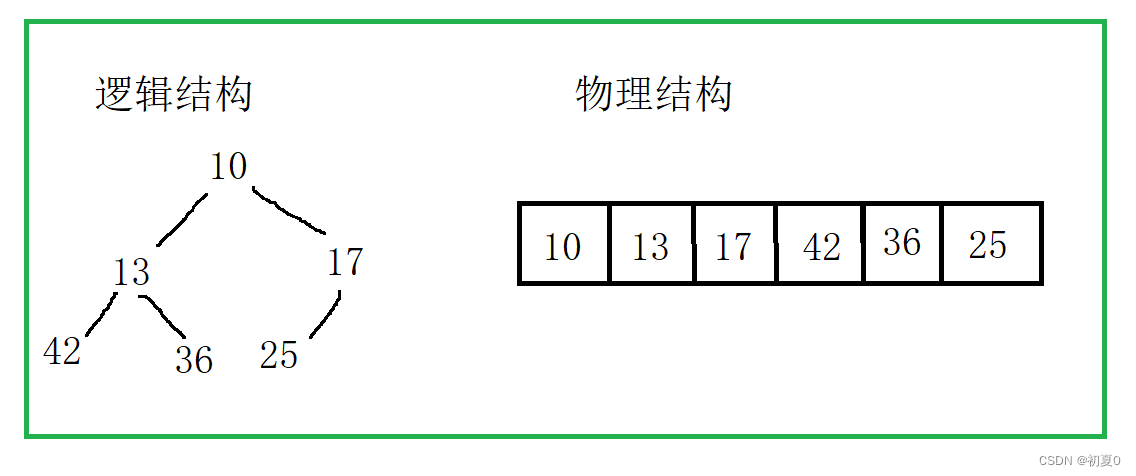
堆只需要满足双亲结点的值不大于或不小于孩子结点的值即可,左右孩子结点的值不做要求。比如上图的13和17互换位置依然是小堆。
注意,如果元素在数组中有序,则一定可以构成堆,反之不成立。
2.堆的实现 (建小堆为例)
由于堆的物理结构使用的是数组,因此定义的结构体和顺序表类似
typedef int heapDataType;
typedef struct heapNode
{
heapDataType* array;
int size;
int capacity;
}heapNode;
关于堆的接口,包括初始化和销毁,插入,删除,判空,以及获取堆顶元素和堆的大小。
2.1 初始化和销毁
和顺序表非常类似,就不赘述了,重点放在插入数据和删除数据。
//初始化堆
void heapInit(heapNode* hp)
{
assert(hp);
hp->array = NULL;
hp->capacity = hp->size = 0;
}
//销毁堆
void heapDestroy(heapNode* hp)
{
assert(hp);
hp->array = NULL;
hp->capacity = hp->size = 0;
}
2.2 判空
由于结构体内有成员变量size,直接返回size是否等于0即可
//判空
bool heapIsEmpty(heapNode* hp)
{
assert(hp);
return hp->size == 0;
}
2.3 获得堆顶元素和堆的大小
根就是堆顶,在物理结构上,堆顶就是数组的首元素。因此返回数组首元素即可。
//获得堆顶数据
heapDataType heapTop(heapNode* hp)
{
assert(hp);
//堆不能为空
assert(!heapIsEmpty(hp));
return hp->array[0];
}
//获得堆的大小
int heapSize(heapNode* hp)
{
assert(hp);
return hp->size;
}
2.4 插入
增加数据的时候,增加在数组的最后一个位置,增加数据前为堆,增加数据后也需要还是堆。
但数据的不同,可能影响结构。
在数组末尾增加一个大于或等于17的值时,堆的结构不会被破坏,如果增加的数据小于17,则需要将其调整为堆。
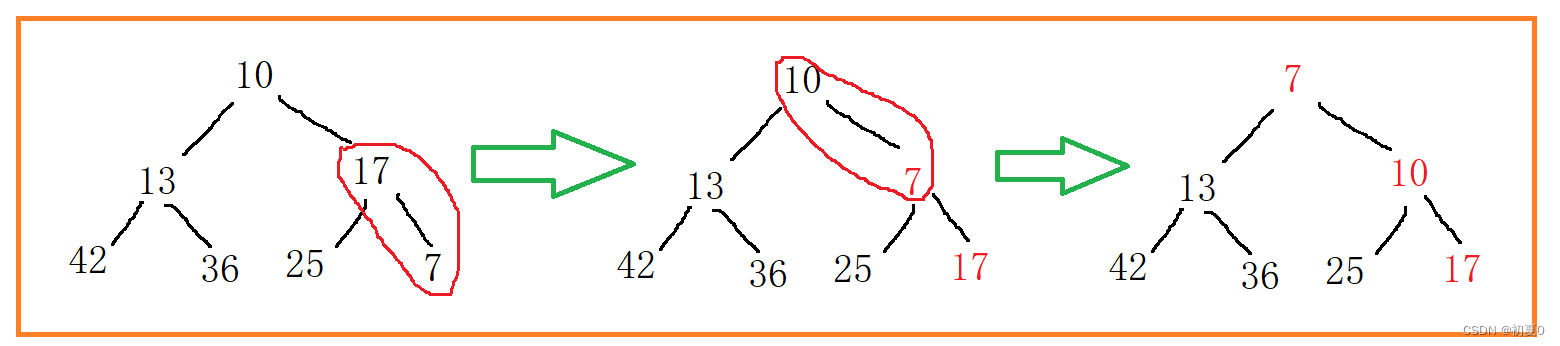
调整需要用到向上调整算法。指的是将符合条件的数据进行上移。
调整过程为,和该结点的双亲结点的值进行比较,如果小于双亲结点的值,那么进行交换,再作为新的孩子和新的双亲结点的值比对,直到换到根节点为止。
以插入一个7为例,调整过程如下图所示。
当调整的结点处于根节点时,则不需要进行下去了,即child下标为0
调整过程中可能涉及到的结点为从根节点到插入的新结点上的一条路径上的结点。
我们知道,在完全二叉树中,任一结点(设下标为k)的双亲结点的下标为(k-1)/ 2
代码实现如下
//交换
void swap(heapDataType* x1, heapDataType* x2)
{
heapDataType tmp = *x1;
*x1 = *x2;
*x2 = tmp;
}
//向上调整算法
void AdJustUp(heapDataType* array,int child)
{
//双亲节点的下标
int parent = (child - 1) / 2;
while (child > 0)
{
if (array[child] < array[parent])
{
//交换数据
swap(&array[child], &array[parent]);
//更新下标
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
//插入
void heapPush(heapNode* hp, heapDataType x)
{
assert(hp);
//容量不够,扩容
if (hp->size == hp->capacity)
{
int newCapacity = hp->capacity == 0 ? 4 : hp->capacity * 2;
//空间可能开辟失败,为保留原数据,创建新的指针变量
heapDataType* tmp = realloc(hp->array, sizeof(heapNode) * newCapacity);
if (tmp == NULL)
{
return;
}
//开辟成功
hp->capacity = newCapacity;
hp->array = tmp;
}
//插入数据
hp->array[hp->size++] = x;
//向上调整重新建堆
AdJustUp(hp->array,hp->size-1);
}
插入数据和顺序表中完全一样,只是多了一步向上调整。
2.5 删除
堆的删除指的是删除堆顶的数据。对于数组,我们比较容易想到的是数据的挪动覆盖,但是这样会导致一个问题,就是删除数据后,堆结构被破坏的很严重。使得难以将其恢复成堆。因此这种做法不合适。
这里的做法是,将堆顶数据和最后一个数据进行交换,然后在删除。这样做虽然也会破坏堆的结构,但是破坏的程度没有那么大,可以通过算法(向下调整算法)将其恢复成堆。
刚刚我们插入了一个7,现在我们在删除一次堆顶的数据。
首先,交换首尾数据并删除,从根节点开始向下调整,找到左右孩子结点中值小的那个进行交换,在作为新的双亲结点,找新的值较小的孩子结点进行交换,直到换到叶子结点。
举例删除7,删除过程如图所示。

如果25处数据是15,则在进行一次交换即可。
有几个小问题需要处理,1.怎么找到较小的孩子结点。2.调整的结束条件。
对于问题1:可以使用假设法,假设左孩子值较小,在和右孩子的值进行比较,如果存在右孩子且右孩子值小,则下标加一
对于问题2:在数组中,孩子结点的下标不会超过数组大小。如果孩子结点的下标已经超过数组,说明调整的结点已经是叶子结点,则不要在进行调整了。
代码如下
//向下调整
void AdJustDown(heapDataType* array, int num_array, int parent)
{
//孩子下标
int child = parent * 2 + 1;
while (child < num_array)
{
//找到值小的孩子,if条件1指存在右孩子,条件2指右孩子值小
if (child + 1 < num_array && array[child + 1] < array[child])
{
++child;
}
if (array[child] < array[parent])
{
//交换数据
swap(&array[child], &array[parent]);
//更新下标
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
//删除
void heapPop(heapNode* hp)
{
assert(hp);
//堆不能为空
assert(!heapIsEmpty(hp));
//交换堆的首尾数据
swap(&hp->array[0], &hp->array[hp->size - 1]);
hp->size--;
//向下调整重新建堆
AdJustDown(hp->array, hp->size, 0);
}
3.堆的构建(建小堆为例)
随机给一个数组,将这个数组构建成为堆。
这里有两种方法,第一种是依次插入数据,向上调整建堆。一个数据可以看作堆,依次插入数据后,堆结构被破坏,进行向上调整,数组遍历完全后,就构建成了堆。
int main()
{
srand(time(NULL));
heapNode hp;
heapInit(&hp);
//生成十个随机数,插入堆
for (int i = 0; i < 10; i++)
{
int j = rand() % 100;
heapPush(&hp, j);
}
//打印,数据符合小堆
for (int i = 0; i < 10; i++)
{
printf("%d ", hp.array[i]);
}
printf("\n\n");
//该操作为获取堆顶数据,打印后,在删除,最终结果为升序
while (!heapIsEmpty(&hp))
{
printf("%d ", heapTop(&hp));
heapPop(&hp);
}
heapDestroy(&hp);
return 0;
}
打印结果如图

第二种方法为向下调整建堆。
向下调整算法有一个前提,指的是调整的结点的左右子树需要是堆。因此从根节点开始调整的方法不适用了,一个值可以看成是堆,因此从倒数的第一个非叶子结点开始向下调整。
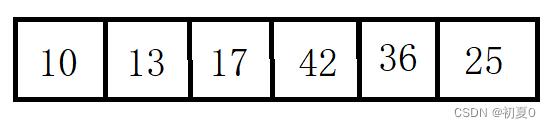
将该数组打乱成25,36,10,13,17,42
向下调整建堆的过程如下图所示
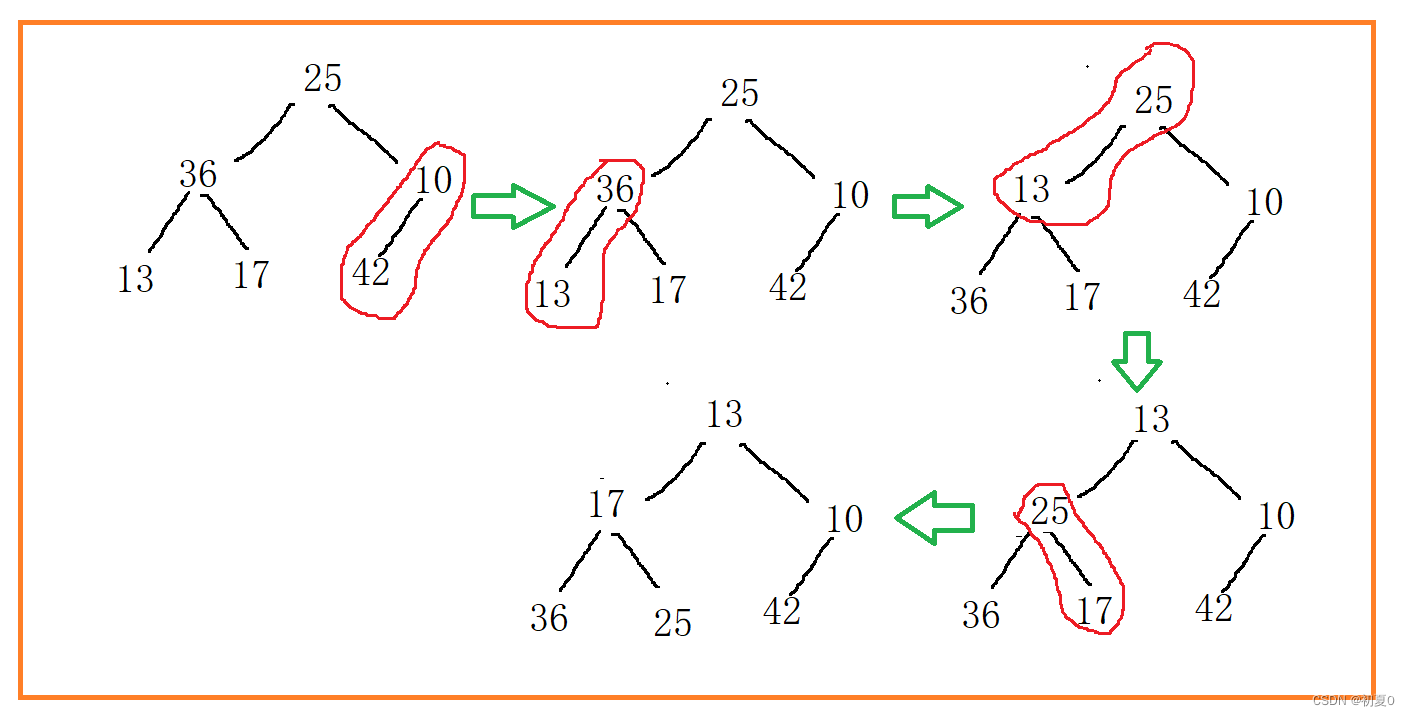
那么第一个非叶子结点下标是多少呢?
首先,最后一个非叶子结点是最后一个结点的双亲结点,下标需要结合数组和完全二叉树的性质来计算。假设数组中元素个数为n,则最后一个元素下标为n-1,完全二叉树中,下标为n-1的双亲结点的下标为[ ( n - 1 ) -1 ] / 2 即 ( n - 2)/ 2;
调整后数组就符合堆结构了。
int main()
{
int arr[10] = { 0 };
//随机生成二十个树
for (int i = 0; i < 10; i++)
{
arr[i] = rand() % 100 + 10;
}
//打印随机数
for (int i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
//向下调整建堆
for (int j = (10 - 2) / 2; j >= 0; --j)
{
AdJustDown(arr, 10, j);
}
printf("\n\n");
//打印调整后的数组
for (int i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
}
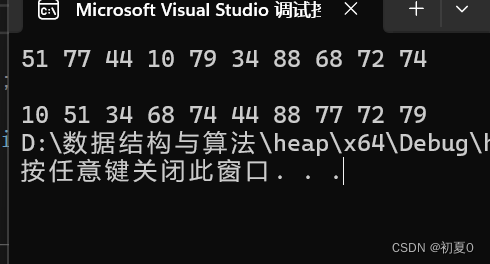
打印结果如图
堆的介绍就先到这里了。
本篇主要介绍二叉树的顺序存储,也就是堆了,关于堆的应用(堆排序,topk问题)就留到下次在介绍吧。