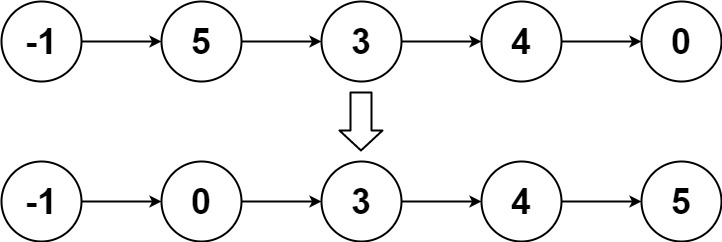
1.输入文件:
2.代码:
setwd("E:/R/Rscripts/rG4相关绘图")
# 加载所需的库
library(tidyverse)
# 读取CSV文件
data <- read.csv("box-cds-ABD-不同类型rg4-2.csv", stringsAsFactors = FALSE)
# 组合Type1和Type2:通过paste0函数创建一个新列CombinedType,这个列是Type1和Type2列值的组合,
# 目的是为了生成区分不同Type1分类下的Type2组(如AG2L1-2、BG2L1-2等)。
data$CombinedType <- paste0(data$Type1, data$Type2)
# 定义一个函数,用于进行两两t检验并计算均值,同时避免比较的重复
perform_analysis <- function(subset_data, type_prefix) {
# 使用组合类型进行分析
subset_data$Type2 <- as.character(subset_data$CombinedType)
unique_types <- unique(subset_data$Type2)
results <- tibble(
Type1 = character(),
Group1 = character(),
Group2 = character(),
Mean1 = numeric(),
Mean2 = numeric(),
TStatistic = numeric(),
PValue = numeric()
)
# 使用combn生成所有唯一的组合
combn(unique_types, 2, function(x) {
group1 <- x[1]
group2 <- x[2]
scores1 <- subset_data$Score[subset_data$Type2 == group1]
scores2 <- subset_data$Score[subset_data$Type2 == group2]
t_test_result <- t.test(scores1, scores2)
# 将每次比较的结果追加到结果集
results <<- bind_rows(results, tibble(
Type1 = type_prefix,
Group1 = group1,
Group2 = group2,
Mean1 = mean(scores1),
Mean2 = mean(scores2),
TStatistic = t_test_result$statistic,
PValue = t_test_result$p.value
))
}, simplify = FALSE)
return(results)
}
# 对每个Type1分类进行分析
results_list <- lapply(unique(data$Type1), function(type) {
subset_data <- subset(data, Type1 == type)
perform_analysis(subset_data, type)
})
# 整合结果并输出
all_results <- bind_rows(results_list)
print(all_results)
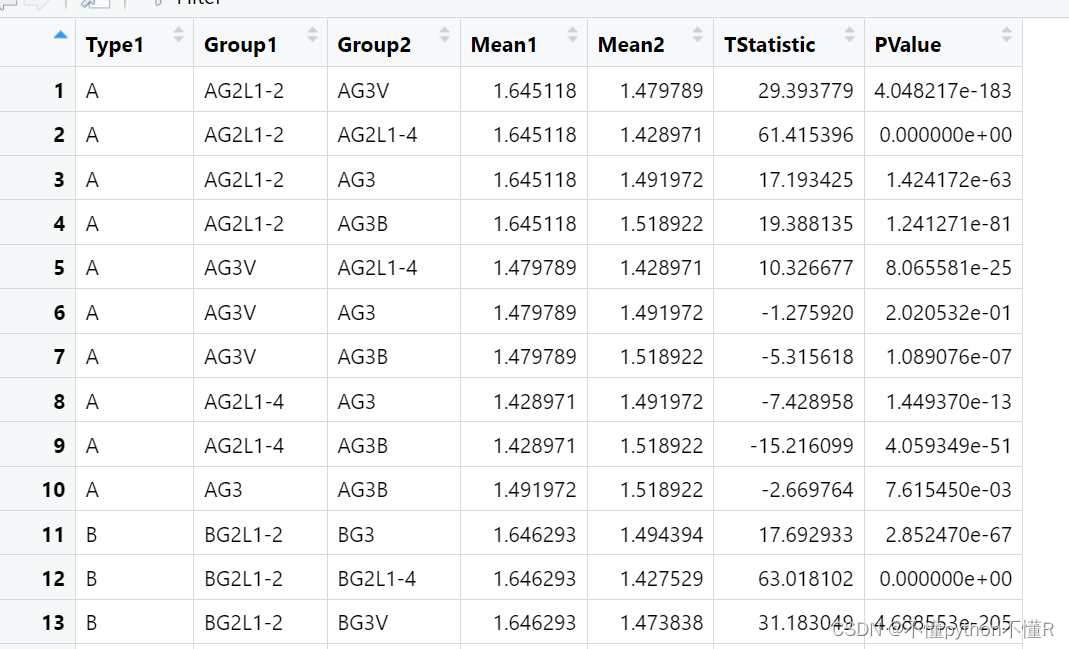
3.输出结果: