最近正好做到人脸识别的一点工作,在查阅资料的时候看到了这篇文章,就想花点时间来读一下。这里是自己的阅读记录,英语水平不够借助翻译软件来读的,感兴趣可以看下,也可以自行阅读原始英文论文。
摘要
我们提出了一类非常有效的CNN模型MobileFaceNet,它使用的参数不到100万,专门为移动和嵌入式设备上的高精度实时人脸验证而定制。首先简单分析了常用移动网络人脸验证的不足。我们专门设计的移动电话网很好地克服了这一弱点。在相同的实验条件下,我们的MobileFaceNets比mobilenetw2具有更高的准确率和2倍以上的实际加速比。经过ArcFace loss在改进的MS-Celeb-1M上的训练,我们的4.0MB大小的单个MobileFaceNet在LFW和92.59%上分别达到99.55%和92.59%TAR@FAR1e-6在MegaFace上,它甚至可以与数百MB大小的最先进的大型CNN模型相媲美。最快的一个MobileFaceNets在手机上的实际推断时间为18毫秒。对于人脸验证,MobileFaceNets比以前最先进的移动cnn具有更高的效率。
关键词:移动网络,人脸验证,人脸识别,卷积神经网络,深度学习。
1、简介
人脸验证技术是一种重要的身份认证技术,越来越多的移动和嵌入式应用如设备解锁、应用登录、移动支付等,一些配备了人脸验证技术的移动应用如智能手机解锁等需要离线运行。为了在有限的计算资源下实现用户友好性,在移动设备上部署的人脸验证模型不仅要精确,而且要小巧快速。然而,现代高精度人脸验证模型是建立在深度和大卷积神经网络(CNN)的基础上,在训练阶段采用新的损失函数进行监督。需要大量计算资源的大型CNN模型不适用于许多移动和嵌入式应用。近年来,人们提出了几种高效的神经网络结构,如MobileNetV1[1]、ShuffleNet[2]和MobileNetV2[3],用于常见的视觉识别任务,而不是人脸验证。使用这些常见的CNN进行人脸验证是一种简单易行的方法,根据我们的实验,与最新的结果相比,这种方法只能获得非常低的精度(见表2)。
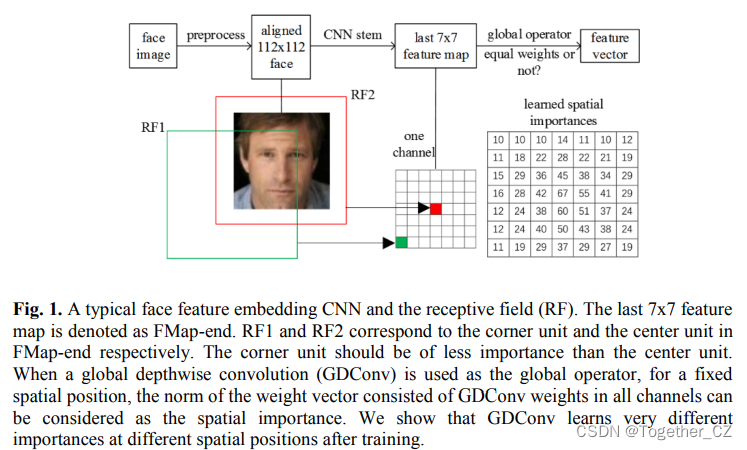
本文对常见移动网络在人脸验证方面的不足进行了简单的分析。我们专门设计的MobileFaceNets很好地克服了这一缺点,它是一类非常高效的CNN模型,专门用于在移动和嵌入式设备上进行高精度实时人脸验证。我们的MobileFaceNet使用的参数不到100万。在相同的实验条件下,我们的MobileFaceNets比mobilenetw2具有更高的准确率和2倍以上的实际加速比。在经过ArcFace loss从头开始的改进MS-Celeb-1M[4]训练后,我们的4.0MB大小的单个MobileFaceNet模型在LFW[6]和92.59%上实现了99.55%的人脸验证精度(见表3)TAR@FAR10-6(见表4)关于MegaFace Challenge 1[7],它甚至可以与数百MB大小的最新大型CNN模型相媲美。请注意,许多现有技术,如剪枝[37]、低比特量化[29]和知识提取[16]都能够提高移动通信网的效率,但这些技术不包括在本文的范围内。本文的主要贡献如下:
(1)在嵌入CNN人脸特征的最后一层(非全局)卷积层之后,我们使用全局深度卷积层而不是全局平均池层或全连通层来输出判别特征向量。从理论和实验两方面分析了这种选择的优越性。
(2) 我们精心设计了一类嵌入人脸特征的CNN,即MobileFaceNet,在移动和嵌入式设备上都具有极高的效率。
(3) 我们在LFW、AgeDB([8])和MegaFace上的实验表明,我们的MobileFaceNet在人脸验证方面比以前的先进移动CNN有显著提高。
2、相关工作
在过去几年中,调整深度神经结构以在精度和性能之间取得最佳平衡一直是一个活跃的研究领域[3]。对于常见的视觉识别任务,最近提出了许多有效的体系结构[1,2,3,9]。一些高效的体系结构可以从头开始训练。例如,SqueezeNet([9])使用瓶颈方法设计一个非常小的网络,并在ImageNet[11,12]上实现AlexNet级[10]精度,参数减少50倍(即125万)。MobileNet v1[1]使用深度可分离卷积构建轻量级深度神经网络,其中一个,即MobileNet-160(0.5x),在ImageNet上的精度比同等大小的SqueezeNet高4%。ShuffleNet[2]利用逐点分组卷积和信道混洗操作来降低计算成本并获得比MobileNetV1更高的效率。MobileNetV2[3]体系结构基于具有线性瓶颈的逆残差结构,提高了移动模型在多个任务和基准上的最新性能。移动NASNet[13]模型是一个具有强化学习的架构搜索结果,与MobileNetV1、ShuffleNet和MobileNetV2相比,它在移动设备上具有更复杂的结构和更多的实际推理时间。然而,当从头开始训练时,这些轻量级的基本架构对于人脸验证并不那么精确(参见表2)。专门为人脸验证设计的精确的轻量级体系结构很少被研究。[14] 提出了一种轻型CNN框架,用于学习大规模人脸数据的紧凑嵌入,其中轻型CNN-29模型在LFW上的人脸验证精度达到99.33%,参数为1260万。与MobileNetV1相比,Light CNN-29对于移动和嵌入式平台来说并不轻量级。轻型CNN-4和轻型CNN-9比轻型CNN-29精确得多。[15] 提出了一种基于ShiftNet-C模型的ShiftFaceNet,参数78万,在LFW上仅能达到96.0%的人脸验证精度。在[5]中,MobileNetV1的一个改进版本,即LMobileNetE,实现了与最先进的大模型相当的人脸验证精度。但LMobileNetE实际上是一个112MB大小的大模型,而不是一个轻量级模型。以上所有型号
从零开始训练。
获取轻量级人脸验证模型的另一种方法是通过知识蒸馏压缩预训练网络[16]。在[17]中,通过从教师网络DeepID2+[33]中提取知识来训练紧凑的学生网络(表示为MobileID),在模型大小为4.0MB的LFW上实现了97.32%的准确率。在[1]中,通过从预训练的FaceNet[18]模型中提取知识来训练几个用于人脸验证的小型MobileNetV1模型,并且只报告了作者私有测试数据集上的人脸验证精度。不管小型学生模型在公共测试数据集上的准确性如何,我们的MobileFaceNet在LFW(见表3)和MegaFace(见表4)上的准确性与强大的教师模型FaceNet相当。
3、方法
在这一节中,我们将描述我们的方法,非常有效的CNN模型,用于在移动设备上进行精确的实时人脸验证,这克服了普通移动网络用于人脸验证的弱点。为了使我们的结果完全可重复,我们使用ArcFace loss在公共数据集上训练所有人脸验证模型,遵循[5]中的实验设置。
3.1常用移动网络人脸验证的弱点
在为常见视觉识别任务(例如,MobileNetV1、ShuffleNet和MobileNetV2)而提出的最新最先进的移动网络中,存在全局平均池层。对于人脸验证和识别,一些研究者([14]、[5]等)观察到,具有全局平均池层的CNN比没有全局平均池层的CNN准确度低。然而,对这一现象还没有进行理论分析。本文用感受野理论对这一现象作了简单的分析。一个典型的深度人脸验证流程包括对人脸图像进行预处理,利用训练好的深度模型提取人脸特征,并根据特征间的相似度或距离进行匹配。按照文献[5,20,21,22]中的预处理方法,我们使用MTCNN[23]来检测图像中的人脸和五个人脸标志点。然后根据五个标志点进行相似变换,实现人脸对齐。对齐的人脸图像大小为112×112,RGB图像中的每个像素通过减去127.5然后除以128进行归一化。最后,面部特征嵌入CNN将每个对齐的面部映射到特征向量,如图1所示。在不丧失通用性的情况下,我们在下面的讨论中使用MobileNetV2作为嵌入CNN的人脸特征。为了保持输出特征图的大小与输入为224×224的原始网络相同,我们在第一个卷积层中使用步长为1的设置,而不是步长为2的设置,后者导致精度非常差。因此,在全局平均池层之前,最后一个卷积层的输出特征映射为FMap end,为方便起见,空间分辨率为7×7。虽然FMap端角部和中心部的理论感受野大小相同,但它们位于输入图像的不同位置。典型的深度人脸验证流程包括:预处理人脸图像、利用训练好的深度模型提取人脸特征、利用特征间的相似度或距离匹配两个人脸。按照文献[5,20,21,22]中的预处理方法,我们使用MTCNN[23]来检测图像中的人脸和五个人脸标志点。然后根据五个标志点进行相似变换,实现人脸对齐。对齐的人脸图像大小为112×112,RGB图像中的每个像素通过减去127.5然后除以128进行归一化。最后,面部特征嵌入CNN将每个对齐的面部映射到特征向量,如图1所示。在不丧失通用性的情况下,我们在下面的讨论中使用MobileNetV2作为嵌入CNN的人脸特征。为了保持输出特征图的大小与输入为224×224的原始网络相同,我们在第一个卷积层中使用步长为1的设置,而不是步长为2的设置,后者导致精度非常差。所以,在全局平均池层之前,最后一个卷积层的输出特征映射为FMap end,空间分辨率为7×7。虽然FMap端角部和中心部的理论感受野大小相同,但它们位于输入图像的不同位置。FMap端角单元的感受野中心位于输入图像的角部,FMend端中心单元的感受野中心位于输入图像的中心,如图1所示。根据文献[24],位于感受野中心的像素对输出具有更大的影响,并且感受野内对输出的影响的分布接近高斯分布。FMap末端的角部单位的有效感受野比FMap末端的中央单位小得多。当输入图像是一个对齐的面时,FMap端的角单元比中央单元承载的面信息少。因此,不同的FMap端点单元对于提取人脸特征向量具有不同的重要性。在MobileNetV2中,平坦的FMap端点不适合直接用作人脸特征向量,因为它的维数62720太高。使用全局平均池(表示为GAPool)层的输出作为人脸特征向量是一种自然的选择,在许多研究人员的实验[14,5]和我们的实验(见表2)中实现了较低的验证精度。全局平均池层对FMap端的所有单元都是同等重要的,从上面的分析来看这是不合理的。另一种常用的方法是用全连通层代替全局平均池层,将FMap端投影到一个紧凑的人脸特征向量上,为整个模型增加大量的参数。即使人脸特征向量为低维128,FMap-end后的全连通层也会为MobileNetV2增加800万个参数。我们不考虑这一选择,因为小型模型是我们追求的目标之一。
3.2全局深度卷积
为了处理具有不同重要性的FMap端的不同单元,我们将全局平均池层替换为全局深度卷积层(表示为GDConv)。GDConv层是一个深度卷积(c.f.[25,1])层,其内核大小等于输入大小,pad=0,step=1。全局深度卷积层的输出计算如下:

当FMap-end后在MobileNetV2中用于人脸特征嵌入时,核大小为7×7×1280的全局深度卷积层输出1280维人脸特征向量,计算代价为62720个MAdds(即,通过乘法相加测量的运算次数,c.f.[3]),62720个参数。设MobileNetV2-GDConv表示具有全局深度卷积层的MobileNetV2。当MobileNetV2和MobileNetV2 GDConv都在CIASIAWebface[26]上进行训练,以通过ArcFace loss进行人脸验证时,后者在LFW和AgeDB上的准确性显著提高(见表2)。全局深度卷积层是我们设计移动通信网的一种有效结构。
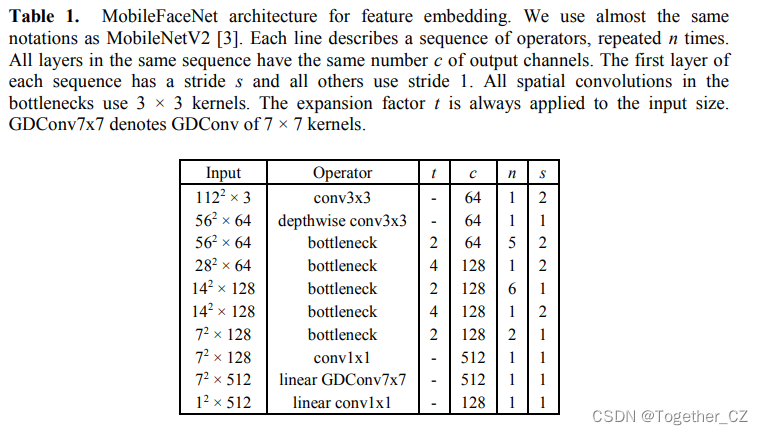
3.3 MobileFaceNet体系结构
现在我们详细描述我们的MobileFaceNet体系结构。MobileNetV2[3]中提出的剩余[38]瓶颈被用作我们的主要构建块。为了方便起见,我们使用了与[3]中相同的概念。我们的主要MobileFaceNet架构的详细结构如表1所示。特别是,我们的体系结构中瓶颈的扩展因子比MobileNetV2中的要小得多。我们使用PReLU[27]作为非线性,这比使用ReLU(见表2)用于人脸验证稍微好一些。此外,我们在网络的开始部分采用快速降采样策略,在最后几个卷积层采用早期降维策略,在线性全局深度卷积层之后采用线性1×1卷积层作为特征输出层。在训练期间使用批量标准化[28],部署前应用批量标准化折叠(c.f.[29]第3.2节)。我们的主要MobileFaceNet网络的计算成本为2.21亿mAds,使用99万个参数。我们进一步定制我们的主要架构如下。为了降低计算量,我们将输入分辨率从112×112改为112×96或96×96。为了减少参数的数目,我们在MobileFaceNet的线性GDConv层之后去掉线性1×1卷积层,得到的网络称为MobileFaceNet-M。在MobileFaceNet-M中,在线性GDConv层之前去掉1×1卷积层,得到最小的网络称为MobileFaceNet-S。下一节的实验验证了这些MobileFaceNet网络的有效性。
4、实验
在本节中,我们将首先描述MobileFaceNet模型和基线模型的培训设置。然后,我们将我们训练的人脸验证模型的性能与一些以前发表的人脸验证模型进行比较,包括一些最先进的大模型。
4.1 LFW和AgeDB的培训设置和准确性比较
我们使用MobileNetV1、ShuffleNet和MobileNetV2(对于它们的第一个卷积层,步幅=1,因为设置步幅=2会导致非常差的准确性)作为基线模型。所有MobileFaceNet模型和基线模型都通过ArcFace loss从头开始在CASIA Webface数据集上进行训练,以便进行性能比较。我们将权重衰减参数设置为4e-5,但全局操作符(GDConv或GAPool)之后最后一层的权重衰减参数为4e-4。我们使用动量为0.9的SGD优化模型,批量为512。学习率从0.1开始,在36K、52K和58K迭代中除以10。培训在60K次迭代时完成。然后,将LFW和AgeDB-30的人脸验证精度进行比较,如表2所示。
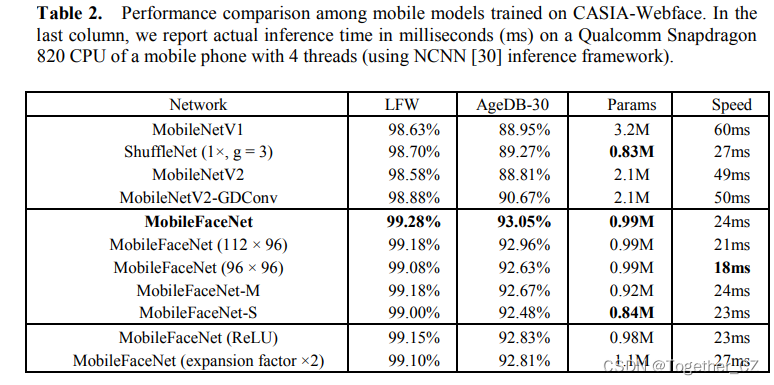
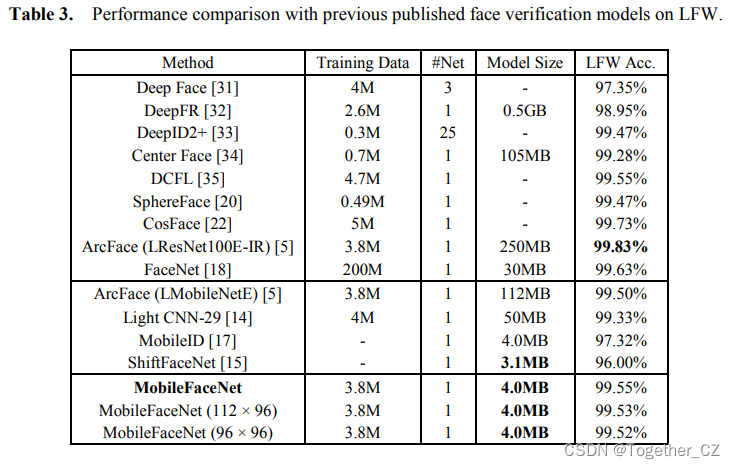
如表2所示,与普通移动网络的基线模型相比,我们的移动通信网具有更快的推理速度和更高的准确性。我们的主MobileFaceNet达到了最好的精度,输入分辨率为96×96的MobileFaceNet具有最快的推理速度。请注意,我们的MobileFaceNet比那些具有更大扩展因子的MobileFaceNet(扩展因子×2)和MobileNetV2-GDConv效率更高。为了追求最终的性能,MobileFaceNet、MobileFaceNet(112×96)和MobileFaceNet(96×96)也通过ArcFace loss在MS-Celeb-1M数据库[5]的清洁训练集上进行训练,其中包含85K受试者的3.8M图像。在LFW和AgeDB30上,我们的主要移动通信网的准确率分别提高到99.55%和96.07%。表3比较了三种训练模型在LFW上的精度,并将其与以前发表的人脸验证模型进行了比较。
4.2 MegaFace Challenge1评估
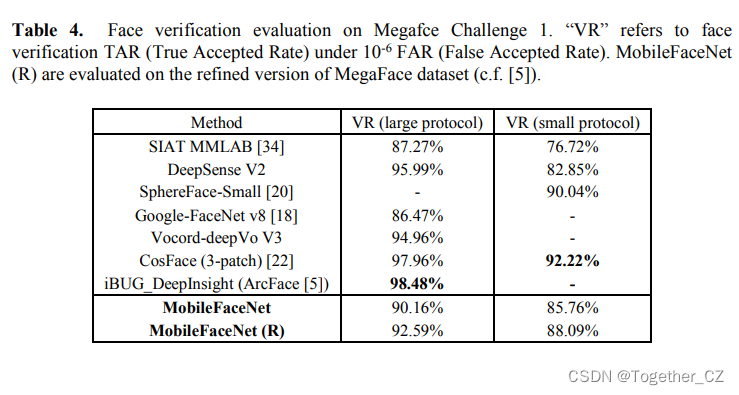
在本文中,我们使用Facescrub[36]数据集作为探测集来评估我们的主要MobileFaceNet在Megaface Challenge 1上的验证性能。表4总结了我们的模型在MegaFace的两个协议上训练的结果,其中,如果训练数据集的图像少于50万张,则视为较小,否则视为较大。我们的主要MobileFaceNet在两个协议上的验证任务显示出相当的准确性。
5、结论
我们提出了一种嵌入人脸特征的CNN,即MobileFaceNet,它可以非常有效地在移动和嵌入式设备上进行实时人脸验证。我们的实验表明,MobileFaceNets在人脸验证方面取得了显著的提高。
感兴趣的话可以自行阅读原论文,地址在这里。

![PC电脑技巧[笔记本通过网线访问设备CMW500]](https://img-blog.csdnimg.cn/direct/733dfa3867064b95aa55cf93653508bc.png)