1.参考文献
《Contrastive Clustering》
2.深度聚类方法
深度聚类方法大致分为以下几类:
①分阶段:使用深度网络进行对比学习or自动编码器完成表征学习(目的:把同类样本集中到一起,拉开不同类样本的聚类),然后使用聚类模型把不同簇的样本进行归类,并且使用后续赋值对深度网络进行更新。
这种交替学习方法在表征学习和聚类的交替阶段中存在累积的误差,会导致聚类性能次优。
②端到端:即在完成表征学习的同时,同样完成聚类。
根据数据集使用情况,又可分为:
①离线学习:要使用整个数据集才能进行聚类;
②在线学习:使用数据集的部分就能进行聚类;
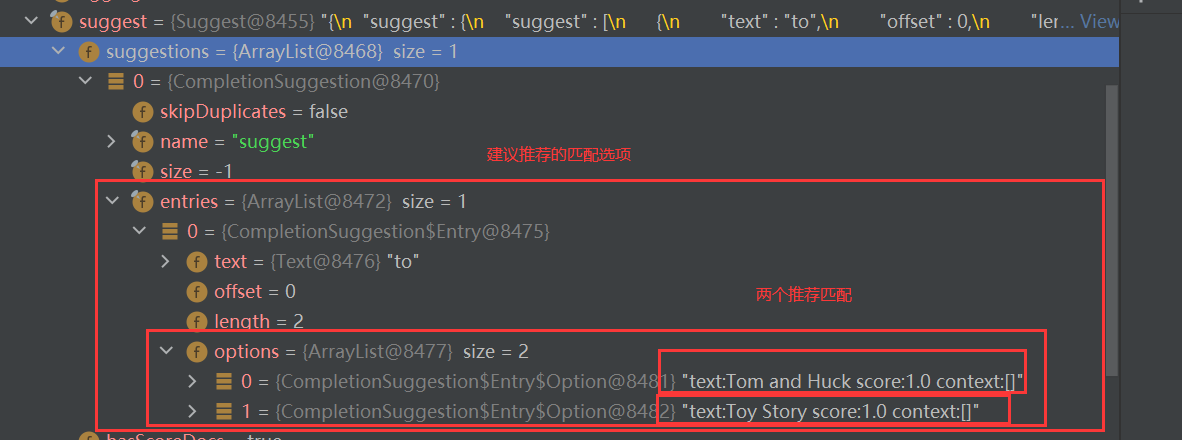
3.对比聚类(Contrastive Clustering,CC)
对比聚类该方法是既可以分阶段,也可以端到端,同时也是在线学习的。
总的来讲是在对比学习基础上,拓展为对比聚类,其思路如下图
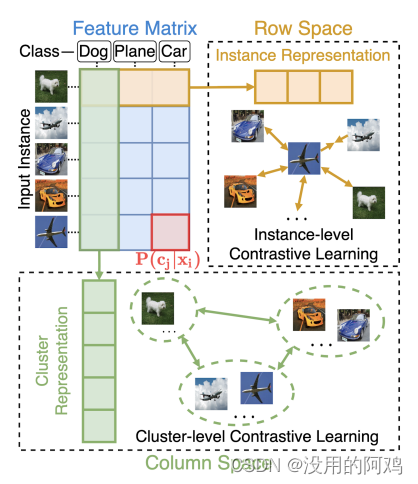
通过将特征矩阵的行视为实例的软标签(即表示样本
属于簇
的概率),可以据此将列解释为分布在数据集上的聚类表示。
因此,可以在特征矩阵的行空间和列空间中分别进行表征学习和聚类的对比学习。
详细流程如下图
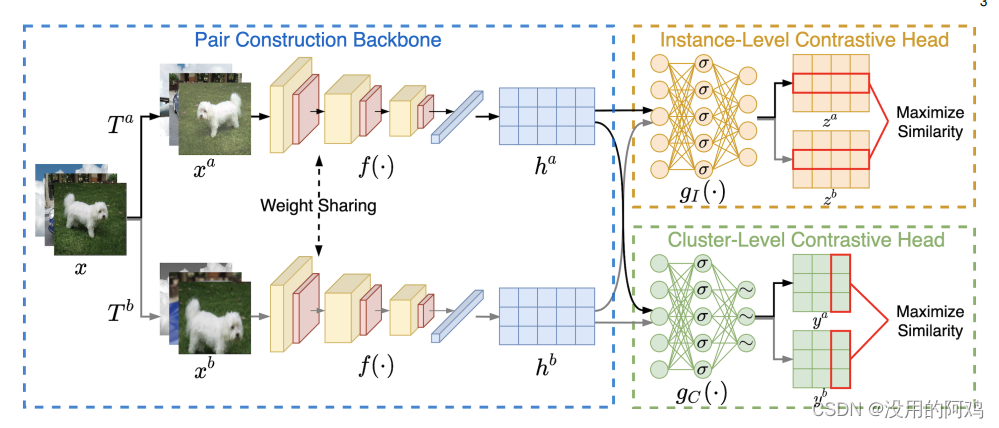
使用两个数据扩充来构造数据对。给定数据对,一个共享的深度神经网络被用来从不同的增强中提取特征。使用两个独立的MLPs(σ表示ReLU激活,∼表示Softmax操作以产生软标签)将特征投影到行和列空间,其中分别进行表征学习和聚类的对比学习。
主要使用了ResNet34做为主干网络
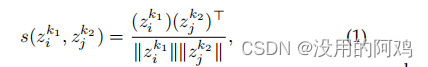
损失函数如下
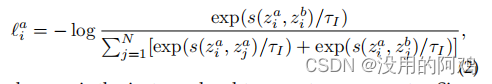
由于希望识别数据集上的所有正对,因此在每个增强样本上计算实例级的对比损失,即,
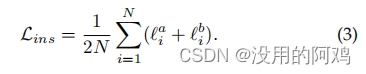
这里跟对比学习是一样的。
③Cluster-level Contrastive Head
使用余弦距离来衡量聚类对之间的相似性,即
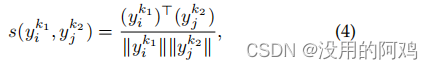
采用以下损失函数来区分簇与除簇
外的所有其他簇
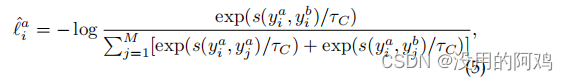
最后计算了簇级对比损失
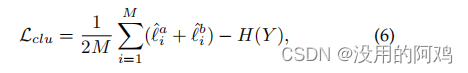
其中,![]()
这个有助于避免了大多数实例被分配给同一个集群的琐碎解决方案。
④目标函数
![]()
具体算法流程如下图

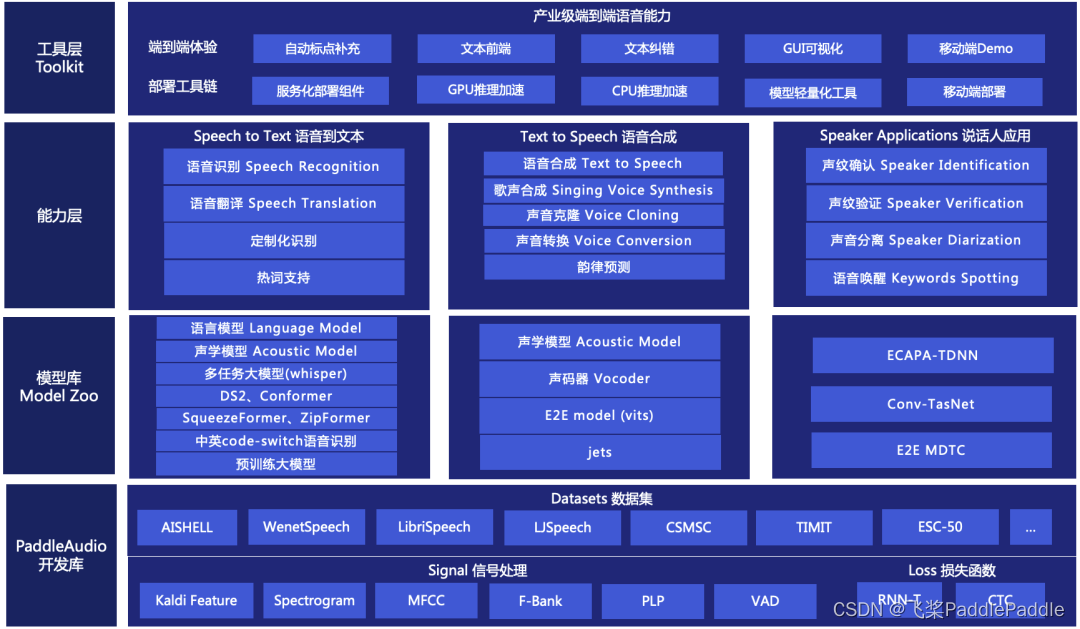
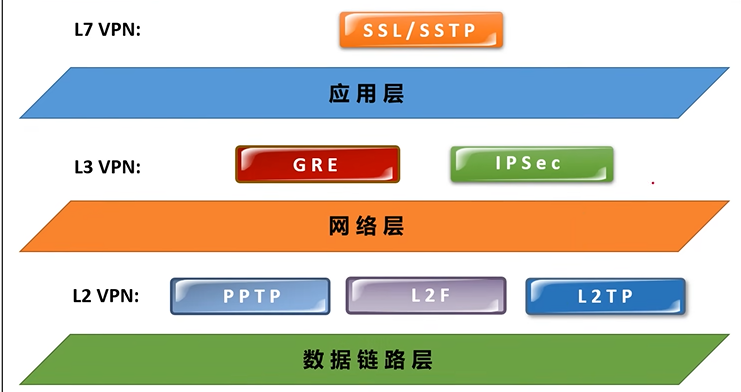
4.应用
迁移学习或者半监督学习



![sqlserver连接时报错 [IM002] [Microsoft][ODBC 驱动程序管理器] 未发现数据源名称并且未指定默认驱动程序](https://img-blog.csdnimg.cn/b7531b45aed64f3db1bc0ba11f1ac354.png)