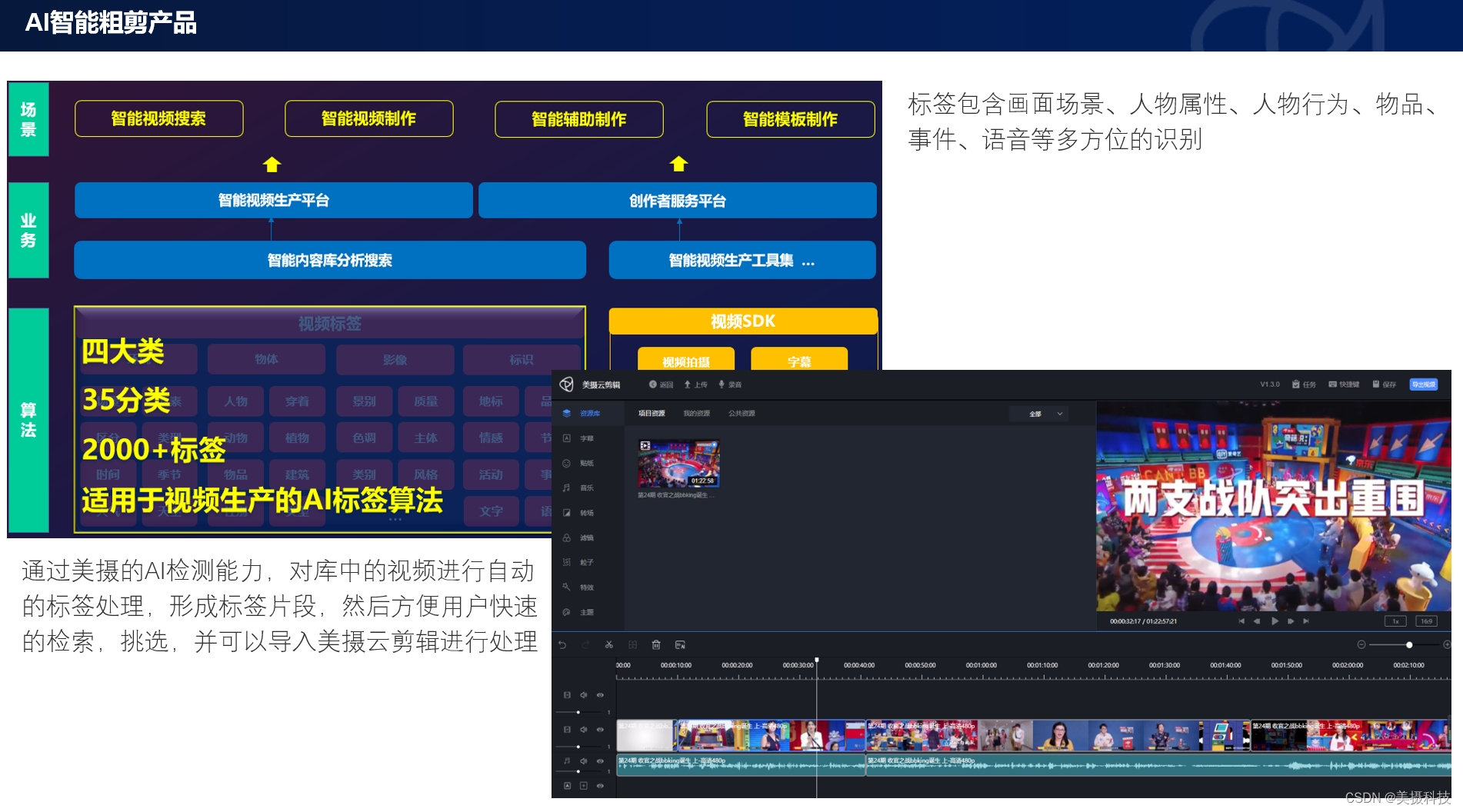
目录
- 1. 数据库建表
- 2. 搭建项目环境
- 创建项目
- 新建爬虫
- 虚拟环境中安装库
- 定义数据类型(item.py)
- 爬虫(spiders/csdn.py)
- 管道(pipelines.py)
- 中间件(middlewares.py)
- 项目设置(setting.py)
- 运行测试
- 总结
欢迎关注 『scrapy爬虫』 专栏,持续更新中
欢迎关注 『scrapy爬虫』 专栏,持续更新中
看完01-09的内容,实战一下,获取自己文章的访问量 收藏 点赞 数据信息
1. 数据库建表
标题字段2000,因为有些标题和符号确实长~
USE scrapy_csdn;
DROP TABLE IF EXISTS csdn_article;
CREATE TABLE csdn_article (
`id` INT UNSIGNED AUTO_INCREMENT COMMENT '编号',
`title` VARCHAR(2000) NOT NULL COMMENT '标题',
`views` int not null COMMENT '阅读量',
`star` int not null COMMENT '收藏',
`likes` int not null COMMENT '点赞数',
PRIMARY KEY (`id`)
) ENGINE=InnoDB COMMENT='文章信息';

2. 搭建项目环境
创建项目
创建一个名为csdn_scrapy的scrapy项目
scrapy startproject csdn_scrapy
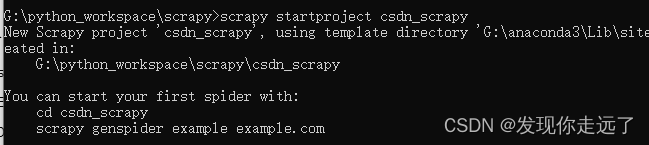
新建爬虫
新建名为csdn的spider
cd csdn_scrapy
scrapy genspider csdn blog.csdn.net
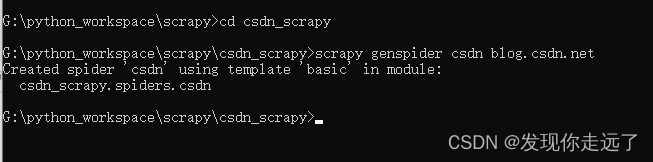
搭建成功
虚拟环境中安装库
import scrapy
import openpyxl
import pymysql
定义数据类型(item.py)
import scrapy
class CsdnScrapyItem(scrapy.Item):
title = scrapy.Field()
views = scrapy.Field()
star = scrapy.Field()
likes = scrapy.Field()
爬虫(spiders/csdn.py)
import scrapy
from scrapy import Selector,Request
from csdn_scrapy.items import CsdnScrapyItem
class CsdnSpider(scrapy.Spider):
name = "csdn"
allowed_domains = ["blog.csdn.net"]
start_urls = ["http://blog.csdn.net/"]
def start_requests(self) :
yield Request(
url=f'https://blog.csdn.net/u011027547',
# meta={'proxy':"socket5://127.0.0.1:1086"},#socket5代理
# meta={'proxy':"http://127.0.0.1:1086"}#购买的商业代理一般是http给一个api接口
callback=self.parse# 这一行是系统默认带有的,你不写也是默认这样
)
def parse(self,response, **kwargs):
myselector=Selector(text=response.text)
# 单个文章的选择器
# #userSkin > div.user-profile-body > div > div.user-profile-body-right > div.navList-box > div.mainContent > div > div > div:nth-child(1) > article
#拿到了所有文章div组成的list
list_items=myselector.css("#userSkin > div.user-profile-body > div > div.user-profile-body-right > div.navList-box > div.mainContent > div > div > div> article")
for list_item in list_items:
article_item=CsdnScrapyItem()#新建类的对象
# userSkin > div.user-profile-body > div > div.user-profile-body-right > div.navList-box > div.mainContent > div > div > div:nth-child(1) > article > a > div.list-box-cont > div:nth-child(1) > div.blog-list-box-top > h4
article_item['title'] = list_item.css("div.blog-list-box-top > h4::text").extract_first()
#标题会带有这些特殊符号导致异常,所以要进行数据清洗.strip() 是一个字符串方法,用于去除字符串开头和结尾的空格(包括空格、制表符和换行符等)
article_item['title']=article_item['title'].strip()
print(article_item['title'])
# 阅读
# <span data-v-6fe2b6a7="" class="view-num">385<span data-v-6fe2b6a7="" class="two-px"> 阅读 ·</span></span>
# 拿到类名是"view-num"的span标签的text文本
article_item['views']=list_item.css('span[class="view-num"]::text').extract_first()
print(article_item['views'])
# 收藏
# <span data-v-6fe2b6a7="" class="comment-num">21<span data-v-6fe2b6a7="" class="two-px"> 收藏</span></span>
article_item['star']=list_item.css('span[class="comment-num"]::text').extract_first()
print(article_item['star'])
# 点赞
# <span data-v-6fe2b6a7="" class="give-like-num">11<span data-v-6fe2b6a7="" class="two-px"> 点赞 ·</span></span>
article_item['likes']=list_item.css('span[class="give-like-num"]::text').extract_first()
print(article_item['likes'])
yield article_item#把整理得到的数据给管道
管道(pipelines.py)
对数据进行处理,上传数据到mysql和保存本地excel
import openpyxl
import pymysql
#用于将数据存入mysql的类
class DBPipeline:
# 初始化
def __init__(self):
self.conn=pymysql.connect(host='127.0.0.1',port=3306,
user='root',passwd='123456',database='scrapy_csdn',charset='utf8mb4')
self.cursor=self.conn.cursor()
self.data=[]#准备一个存放数据的容器
# 开始爬虫时候要进行的操作
def open_spider(self, spider):
pass
# 处理爬取到的数据并进行后续处理
def process_item(self, item, spider):
title=item.get('title',0)
views=item.get('views',0)#如果没有获取到评价默认0 因为我们数据是 int
star=item.get('star',0)#如果没有获取到评价默认0 因为我们数据是 int
likes=item.get('likes',0)#如果没有获取到评价默认0 因为我们数据是 int
self.data.append((title,views,star,likes)) #将得到的一行的电影相关数据放入列表
if len(self.data)>=5:
self._write_to_db()
return item #为什么是return? 我们要让这个管道先,return会把item数据传递给下一个管道用于保存excel的
def _write_to_db(self):
# execute->改为了 executemany 支持多条数据批量传入数据库
self.cursor.executemany(
'insert into csdn_article(title,views,star,likes) values (%s,%s,%s,%s)', self.data
)
self.conn.commit() # 把数据缓冲区的数据提交到数据库
self.data.clear() # 每次添加后清空data 避免重复添加数据
# 关闭爬虫时候要进行的操作
def close_spider(self, spider):
if len(self.data) >= 0:#如果还有残留的数据,但是因为不满100条没有传到数据库也要做好处理
self._write_to_db()
self.conn.close()
# 用于将数据存入excel的类
class CsdnScrapyPipeline:
# 初始化我们的excel文件
def __init__(self):
self.wb=openpyxl.Workbook()
self.ws=self.wb.active #拿到默认的被激活的工作表
self.ws.title="文章信息" #工作表的名字
self.ws.append(("文章标题","阅读量","收藏量",'点赞量')) #增加表头
# 开始爬虫时候要进行的操作
def open_spider(self,spider):
pass
# 关闭爬虫时候要进行的操作
def close_spider(self,spider):
#保存Excel文件
self.wb.save("文章信息.xlsx")
#关闭工作簿(Workbook)和工作表(Worksheet)
self.wb.close()
# 处理爬取到的数据 item是我们前面yeild返回的数据
def process_item(self, item, spider):
title=item.get('title',0)
views=item.get('views',0)#如果没有获取到评价默认0 因为我们数据是 int
star=item.get('star',0)#如果没有获取到评价默认0 因为我们数据是 int
likes=item.get('likes',0)#如果没有获取到评价默认0 因为我们数据是 int
self.ws.append((title,views,star,likes))#将得到的数据一行写入excel,注意这里一行是一个元组
return item
中间件(middlewares.py)
载入cookie,配置代理等等(这里没用代理)
from scrapy import signals
# useful for handling different item types with a single interface
from itemadapter import is_item, ItemAdapter
def get_cookies_dict():
# cookie字符串转为字典并返回
cookies_str=''
cookies_dict={}
for item in cookies_str.split('; '):# 用 "; "作为分隔符,分割字符串得到列表,比如说列表第一项 ll="118174
key,vlaue=item.split('=',maxsplit=1)# 用 "="作为分隔符,分割"ll="118174",得到的key和value分别是 li 和 118174
cookies_dict[key]=vlaue
return cookies_dict
COOKIES_DICT=get_cookies_dict #全局变量cookie字典
class CsdnScrapySpiderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, or item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Request or item objects.
pass
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info("Spider opened: %s" % spider.name)
class CsdnScrapyDownloaderMiddleware:
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
# 下载请求前的操作
def process_request(self, request, spider):
# request.meta={'proxy':"socket5://127.0.0.1:1086"}#在中间件中请求前拦截请求 添加代理
request.cookie=COOKIES_DICT #设置cookie
return None
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info("Spider opened: %s" % spider.name)
项目设置(setting.py)
基本的日志,随机等待延时,编码,请求头,并发数量,配置启用管道和中间件.
BOT_NAME = "csdn_scrapy"
SPIDER_MODULES = ["csdn_scrapy.spiders"]
NEWSPIDER_MODULE = "csdn_scrapy.spiders"
# USER_AGENT = "myscrapy (+http://www.yourdomain.com)"#告诉网站 我是爬虫,马上被枪毙~
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
# 是否遵守爬虫协议
ROBOTSTXT_OBEY = True
#设置 Scrapy 引擎同时处理的并发请求数量。 少设置一点不要给网站太大压力! (default: 16)
CONCURRENT_REQUESTS = 8
# 随机下载延迟
RANDOMIZE_DOWNLOAD_DELAY = True
#随机延时
DOWNLOAD_DELAY = 3
#配置日志
LOG_ENABLED = True #开启日志
LOG_LEVEL = 'DEBUG'#设置日志级别。例如,要将日志级别设置为输出所有信息,可以这样配置:通过将日志级别设置为 DEBUG,你可以获取爬虫程序执行过程中的所有详细信息,包括请求、响应、数据处理等各个环节的日志输出。当然,如果你只想获取部分信息,比如只关注警告和错误信息,也可以将日志级别设置为 WARNING 或 ERROR。在运行爬虫时,Scrapy 默认会将日志输出到控制台。如果你希望将日志保存到文件中,还可以设置 LOG_FILE 配置选项,例如:
LOG_FILE = None#设置日志none
# LOG_FILE = 'scrapy.log'#设置日志文件名字 上述配置会将日志输出到名为 scrapy.log 的文件中。
FEED_EXPORT_ENCODING = "utf-8"#通用编码
FEED_EXPORT_ENCODING = "gbk"#中文编码
FEED_OVERWRITE = True # 是否覆盖上次的数据,如果为false每次都是默认的在上次的csv文件后继续写入新的数据
# 配置数据管道
ITEM_PIPELINES = {
'csdn_scrapy.pipelines.DBPipeline': 200, #数据库管道
"csdn_scrapy.pipelines.CsdnScrapyPipeline": 300, #数字越小先执行,后期可以有多个管道
# '你的项目名.pipelines.刚刚管道的类名': 权重, #权重越小先执行,后期可以有多个管道
}
# 配置下载中间件
DOWNLOADER_MIDDLEWARES = {
"csdn_scrapy.middlewares.CsdnScrapyDownloaderMiddleware": 543,
}
# # 配置爬虫中间件
#SPIDER_MIDDLEWARES = {
# "csdn_scrapy.middlewares.CsdnScrapySpiderMiddleware": 543,
#}
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
运行测试
虚拟环境中运行~
scrapy crawl csdn
- 成功保存到数据库
如果没有进行数据清洗使用.strip()处理标题,你会看到下图,而且excel的标题会异常
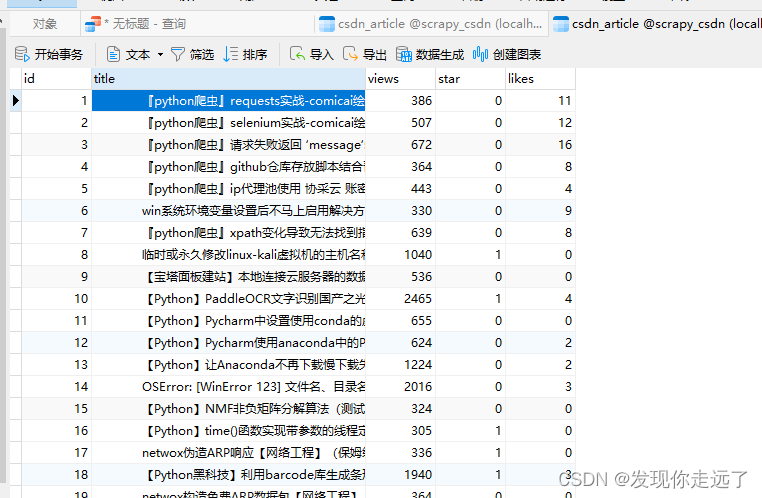
经过数据清洗后标题前后没有空白的换行符和空格了
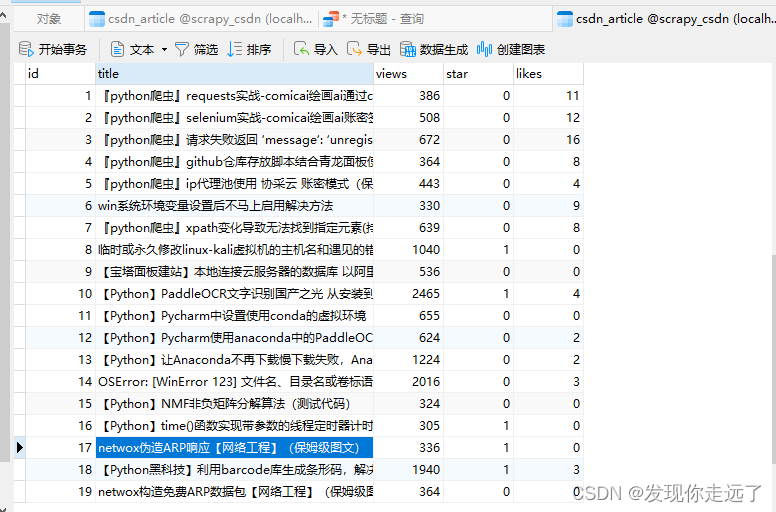
- 成功保存到excel
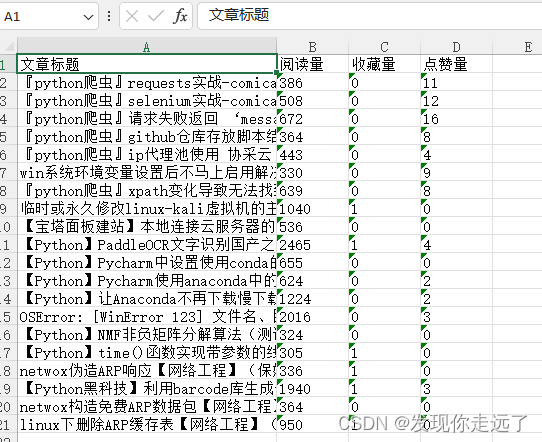
总结
大家喜欢的话,给个👍,点个关注!给大家分享更多计算机专业学生的求学之路!
版权声明:
发现你走远了@mzh原创作品,转载必须标注原文链接
Copyright 2024 mzh
Crated:2024-3-1
欢迎关注 『scrapy爬虫』 专栏,持续更新中
欢迎关注 『scrapy爬虫』 专栏,持续更新中
『未完待续』