💡💡💡本文改进内容: YOLOv9如何魔改卷积进一步提升检测精度?提出了一种卷积的变体,称为DSConv(分布偏移卷积),其可以容易地替换进标准神经网络体系结构并且实现较低的存储器使用和较高的计算速度。 DSConv将传统的卷积内核分解为两个组件:可变量化内核(VQK)和分布偏移
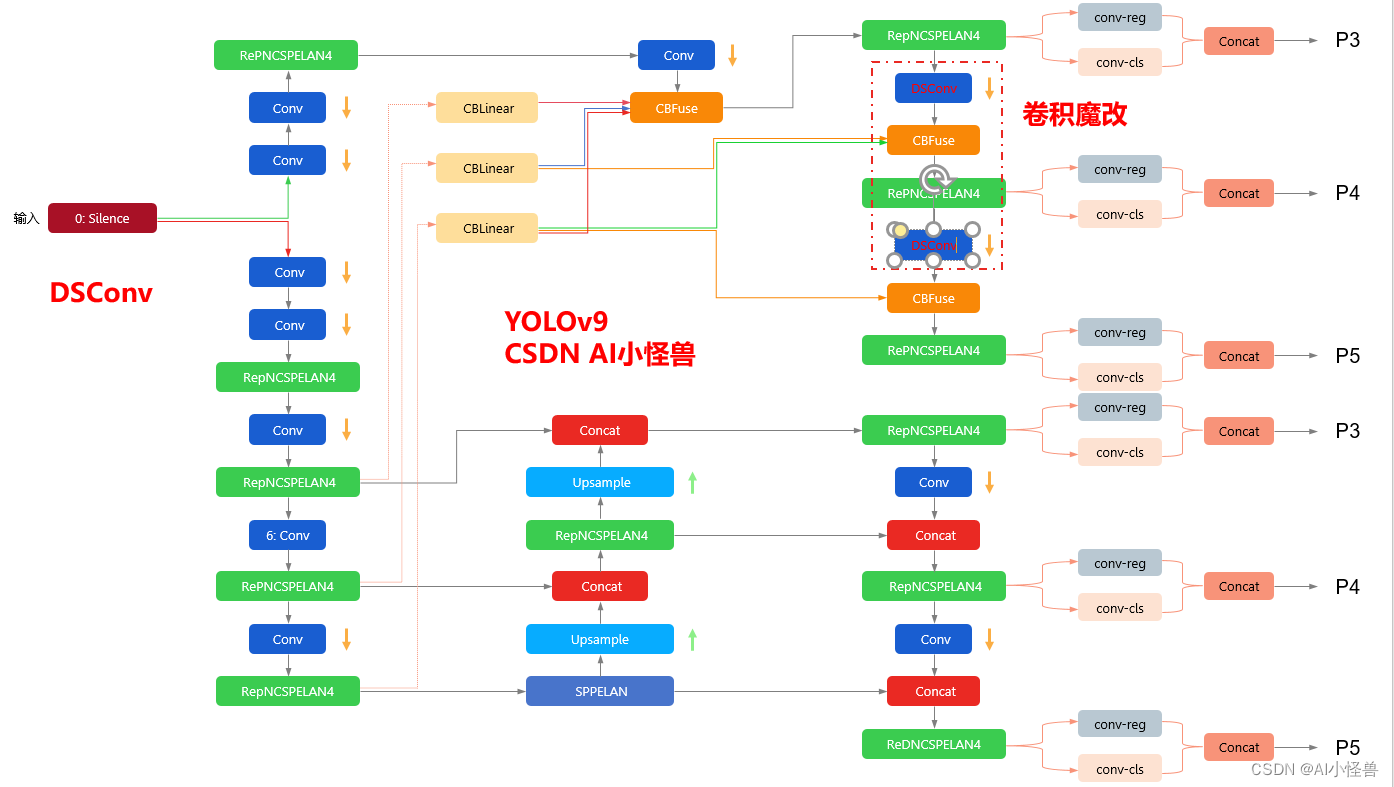
yolov9-c-DSConv summary: 962 layers, 50999590 parameters, 50999558 gradients, 234.7 GFLOPs改进结构图如下:
YOLOv9魔术师专栏
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
包含注意力机制魔改、卷积魔改、检测头创新、损失&IOU优化、block优化&多层特征融合、 轻量级网络设计、24年最新顶会改进思路、原创自研paper级创新等
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
✨✨✨ 新开专栏暂定免费限时开放,后续每月调价一次✨✨✨
🚀🚀🚀 本项目持续更新 | 更新完结保底≥50+ ,冲刺100+🚀🚀🚀
🍉🍉🍉 联系WX: AI_CV_0624 欢迎交流!🍉🍉🍉

YOLOv9魔改:注意力机制、检测头、blcok魔改、自研原创等
YOLOv9魔术师
💡💡💡全网独家首发创新(原创),适合paper !!!
💡💡💡 2024年计算机视觉顶会创新点适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
1.YOLOv9原理介绍

论文: 2402.13616.pdf (arxiv.org)
代码:GitHub - WongKinYiu/yolov9: Implementation of paper - YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information摘要: 如今的深度学习方法重点关注如何设计最合适的目标函数,从而使得模型的预测结果能够最接近真实情况。同时,必须设计一个适当的架构,可以帮助获取足够的信息进行预测。然而,现有方法忽略了一个事实,即当输入数据经过逐层特征提取和空间变换时,大量信息将会丢失。因此,YOLOv9 深入研究了数据通过深度网络传输时数据丢失的重要问题,即信息瓶颈和可逆函数。作者提出了可编程梯度信息(programmable gradient information,PGI)的概念,来应对深度网络实现多个目标所需要的各种变化。PGI 可以为目标任务计算目标函数提供完整的输入信息,从而获得可靠的梯度信息来更新网络权值。此外,研究者基于梯度路径规划设计了一种新的轻量级网络架构,即通用高效层聚合网络(Generalized Efficient Layer Aggregation Network,GELAN)。该架构证实了 PGI 可以在轻量级模型上取得优异的结果。研究者在基于 MS COCO 数据集的目标检测任务上验证所提出的 GELAN 和 PGI。结果表明,与其他 SOTA 方法相比,GELAN 仅使用传统卷积算子即可实现更好的参数利用率。对于 PGI 而言,它的适用性很强,可用于从轻型到大型的各种模型。我们可以用它来获取完整的信息,从而使从头开始训练的模型能够比使用大型数据集预训练的 SOTA 模型获得更好的结果。对比结果如图1所示。

YOLOv9框架图
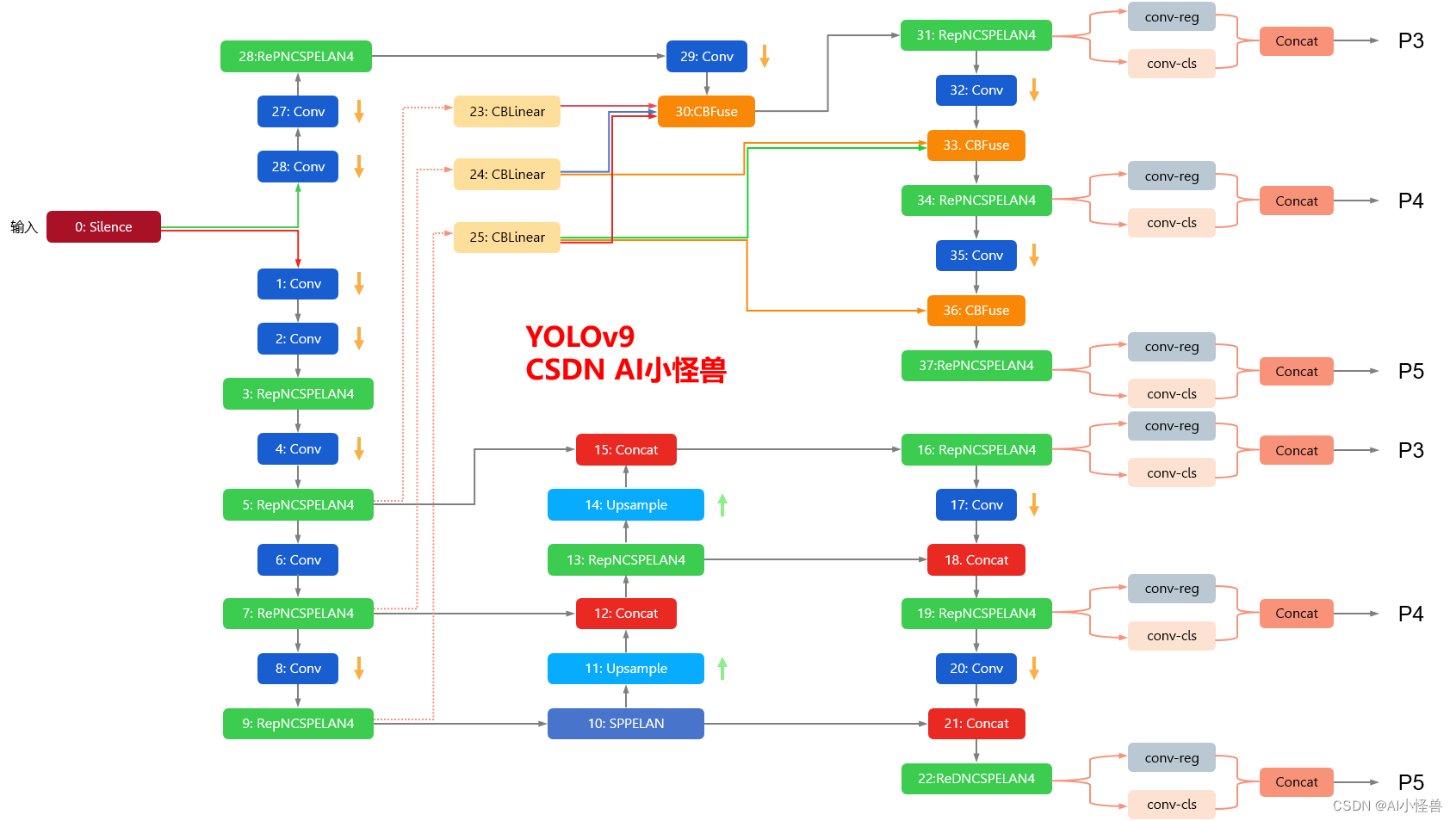
1.1 YOLOv9框架介绍
YOLOv9各个模型介绍

2.DSConv介绍
论文: https://arxiv.org/pdf/1901.01928v1.pdf
摘要:提出了一种卷积的变体,称为DSConv(分布偏移卷积),其可以容易地替换进标准神经网络体系结构并且实现较低的存储器使用和较高的计算速度。 DSConv将传统的卷积内核分解为两个组件:可变量化内核(VQK)和分布偏移。 通过在VQK中仅存储整数值来实现较低的存储器使用和较高的速度,同时通过应用基于内核和基于通道的分布偏移来保持与原始卷积相同的输出。 我们在ResNet50和34以及AlexNet和MobileNet上对ImageNet数据集测试了DSConv。 我们通过将浮点运算替换为整数运算,在卷积内核中实现了高达14x的内存使用量减少,并将运算速度提高了10倍。 此外,与其他量化方法不同,我们的工作允许对新任务和数据集进行一定程度的再训练。

DSConv是一种深度可分离卷积(Depthwise Separable Convolution)的变体,它在计算机视觉领域被广泛使用。深度可分离卷积是一种轻量级卷积,它将标准卷积拆分为两个步骤:深度卷积和逐点卷积。深度卷积只在单个通道上进行卷积,并在每个通道上应用一个独立的卷积核。逐点卷积在所有通道上应用一个卷积核,以组合深度卷积的结果。DSConv相比于深度可分离卷积的优势在于它使用了一个可学习的卷积核来进一步提高模型的表现。
3.DSConv加入到YOLOv9
3.1新建py文件,路径为models/Conv/DSConv.py
###################### DSConv #### start by AI&CV ###############################
import torch
import torch.nn.functional as F
from torch.nn.modules.conv import _ConvNd
from torch.nn.modules.utils import _pair
import math
from models.common import Conv,autopad
class DSConv(_ConvNd): #https://arxiv.org/pdf/1901.01928v1.pdf
def __init__(self, in_channels, out_channels, kernel_size, stride=1,
padding=None, dilation=1, groups=1, padding_mode='zeros', bias=False, block_size=32, KDSBias=False, CDS=False):
padding = _pair(autopad(kernel_size, padding, dilation))
kernel_size = _pair(kernel_size)
stride = _pair(stride)
dilation = _pair(dilation)
blck_numb = math.ceil(((in_channels)/(block_size*groups)))
super(DSConv, self).__init__(
in_channels, out_channels, kernel_size, stride, padding, dilation,
False, _pair(0), groups, bias, padding_mode)
# KDS weight From Paper
self.intweight = torch.Tensor(out_channels, in_channels, *kernel_size)
self.alpha = torch.Tensor(out_channels, blck_numb, *kernel_size)
# KDS bias From Paper
self.KDSBias = KDSBias
self.CDS = CDS
if KDSBias:
self.KDSb = torch.Tensor(out_channels, blck_numb, *kernel_size)
if CDS:
self.CDSw = torch.Tensor(out_channels)
self.CDSb = torch.Tensor(out_channels)
self.reset_parameters()
def get_weight_res(self):
# Include expansion of alpha and multiplication with weights to include in the convolution layer here
alpha_res = torch.zeros(self.weight.shape).to(self.alpha.device)
# Include KDSBias
if self.KDSBias:
KDSBias_res = torch.zeros(self.weight.shape).to(self.alpha.device)
# Handy definitions:
nmb_blocks = self.alpha.shape[1]
total_depth = self.weight.shape[1]
bs = total_depth//nmb_blocks
llb = total_depth-(nmb_blocks-1)*bs
# Casting the Alpha values as same tensor shape as weight
for i in range(nmb_blocks):
length_blk = llb if i==nmb_blocks-1 else bs
shp = self.alpha.shape # Notice this is the same shape for the bias as well
to_repeat=self.alpha[:, i, ...].view(shp[0],1,shp[2],shp[3]).clone()
repeated = to_repeat.expand(shp[0], length_blk, shp[2], shp[3]).clone()
alpha_res[:, i*bs:(i*bs+length_blk), ...] = repeated.clone()
if self.KDSBias:
to_repeat = self.KDSb[:, i, ...].view(shp[0], 1, shp[2], shp[3]).clone()
repeated = to_repeat.expand(shp[0], length_blk, shp[2], shp[3]).clone()
KDSBias_res[:, i*bs:(i*bs+length_blk), ...] = repeated.clone()
if self.CDS:
to_repeat = self.CDSw.view(-1, 1, 1, 1)
repeated = to_repeat.expand_as(self.weight)
print(repeated.shape)
# Element-wise multiplication of alpha and weight
weight_res = torch.mul(alpha_res, self.weight)
if self.KDSBias:
weight_res = torch.add(weight_res, KDSBias_res)
return weight_res
def forward(self, input):
# Get resulting weight
#weight_res = self.get_weight_res()
# Returning convolution
return F.conv2d(input, self.weight, self.bias,
self.stride, self.padding, self.dilation,
self.groups)
class DSConv2D(Conv):
def __init__(self, inc, ouc, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__(inc, ouc, k, s, p, g, d, act)
self.conv = DSConv(inc, ouc, k, s, p, g, d)
###################### DSConv #### END by AI&CV ###############################3.2修改yolo.py
1)首先进行引用
from models.Conv.DSConv import DSConv2D2)修改def parse_model(d, ch): # model_dict, input_channels(3)
在源码基础上加入DSConv2D
n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in {
Conv, AConv, ConvTranspose,
Bottleneck, SPP, SPPF, DWConv, BottleneckCSP, nn.ConvTranspose2d, DWConvTranspose2d, SPPCSPC, ADown,
RepNCSPELAN4, SPPELAN,DSConv2D}:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]3.3 yolov9-c-DSConv.yaml
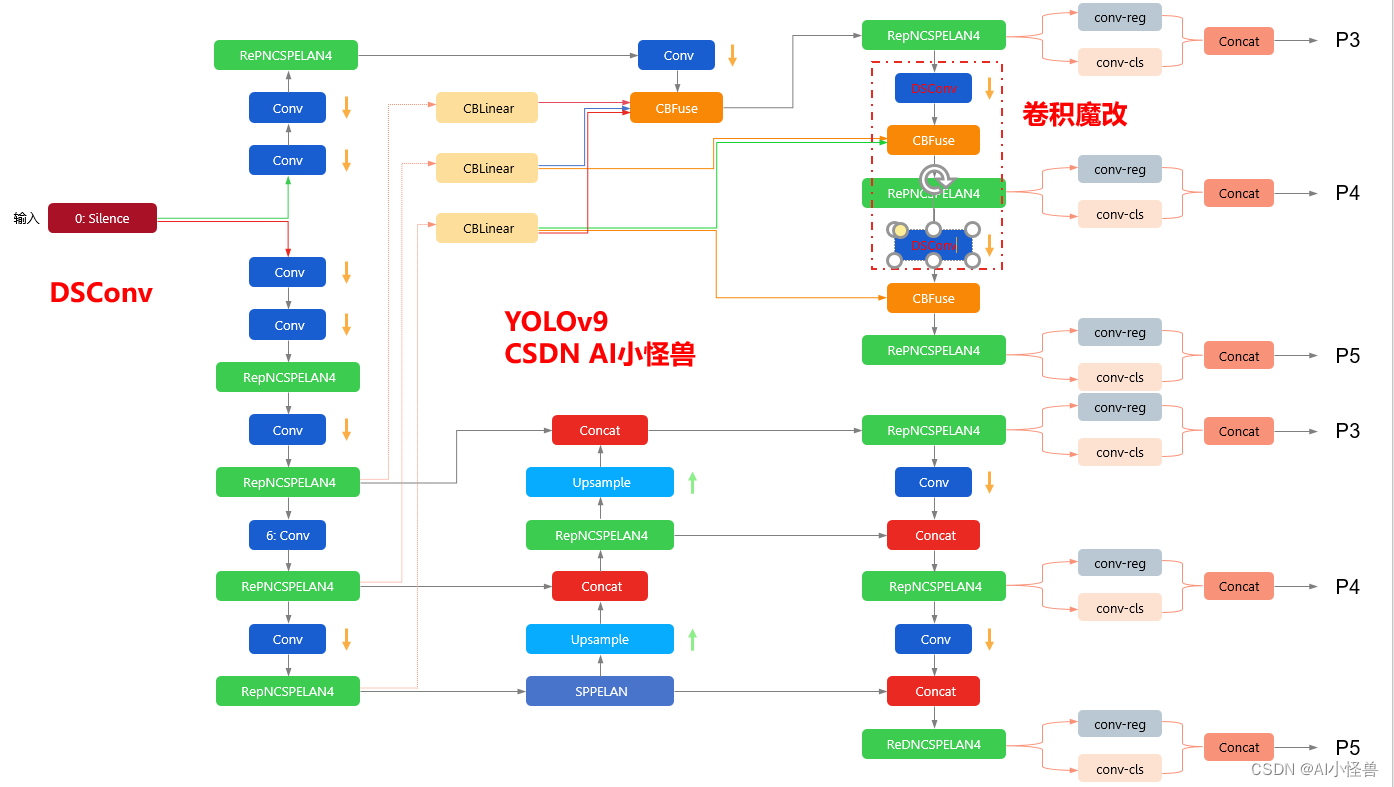
# YOLOv9
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
#activation: nn.LeakyReLU(0.1)
#activation: nn.ReLU()
# anchors
anchors: 3
# YOLOv9 backbone
backbone:
[
[-1, 1, Silence, []],
# conv down
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
# conv down
[-1, 1, Conv, [128, 3, 2]], # 2-P2/4
# elan-1 block
[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 3
# avg-conv down
[-1, 1, ADown, [256]], # 4-P3/8
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 5
# avg-conv down
[-1, 1, ADown, [512]], # 6-P4/16
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 7
# avg-conv down
[-1, 1, ADown, [512]], # 8-P5/32
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 9
]
# YOLOv9 head
head:
[
# elan-spp block
[-1, 1, SPPELAN, [512, 256]], # 10
# up-concat merge
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 7], 1, Concat, [1]], # cat backbone P4
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 13
# up-concat merge
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 5], 1, Concat, [1]], # cat backbone P3
# elan-2 block
[-1, 1, RepNCSPELAN4, [256, 256, 128, 1]], # 16 (P3/8-small)
# avg-conv-down merge
[-1, 1, ADown, [256]],
[[-1, 13], 1, Concat, [1]], # cat head P4
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 19 (P4/16-medium)
# avg-conv-down merge
[-1, 1, ADown, [512]],
[[-1, 10], 1, Concat, [1]], # cat head P5
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 22 (P5/32-large)
# multi-level reversible auxiliary branch
# routing
[5, 1, CBLinear, [[256]]], # 23
[7, 1, CBLinear, [[256, 512]]], # 24
[9, 1, CBLinear, [[256, 512, 512]]], # 25
# conv down
[0, 1, DSConv2D, [64, 3, 2]], # 26-P1/2
# conv down
[-1, 1, DSConv2D, [128, 3, 2]], # 27-P2/4
# elan-1 block
[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 28
# avg-conv down fuse
[-1, 1, ADown, [256]], # 29-P3/8
[[23, 24, 25, -1], 1, CBFuse, [[0, 0, 0]]], # 30
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 31
# avg-conv down fuse
[-1, 1, ADown, [512]], # 32-P4/16
[[24, 25, -1], 1, CBFuse, [[1, 1]]], # 33
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 34
# avg-conv down fuse
[-1, 1, ADown, [512]], # 35-P5/32
[[25, -1], 1, CBFuse, [[2]]], # 36
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 37
# detection head
# detect
[[31, 34, 37, 16, 19, 22], 1, DualDDetect, [nc]], # DualDDetect(A3, A4, A5, P3, P4, P5)
]