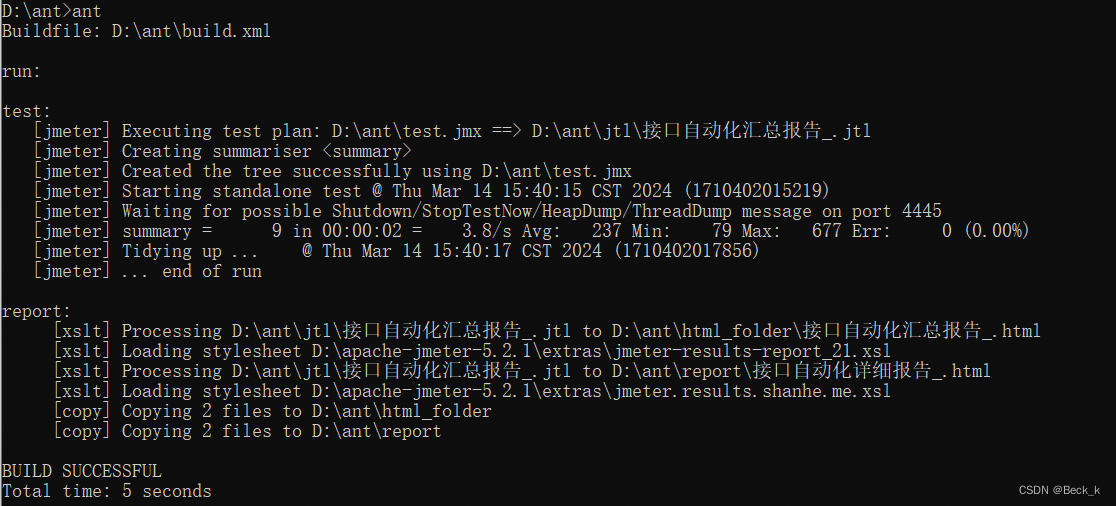
原因
调用了自定义的类,但是在自定义的类的__init__函数下面没有写super( XXX, self ).init()
错误案例
import torch
import torch.nn as nn
class SelfAttention(nn.Module):
""" Self-Attention """
def __init__(self, n_head, d_k, d_v, d_x, d_o):
#super(SelfAttention, self).__init__()#SelfAttention 是类名
self.wq = nn.Parameter(torch.Tensor(d_x, d_k))
self.wk = nn.Parameter(torch.Tensor(d_x, d_k))
self.wv = nn.Parameter(torch.Tensor(d_x, d_v))
self.mha = MultiHeadAttention(n_head=n_head, d_k_=d_k, d_v_=d_v, d_k=d_k, d_v=d_v, d_o=d_o)
self.init_parameters()
def init_parameters(self):
for param in self.parameters():
stdv = 1. / np.power(param.size(-1), 0.5)
param.data.uniform_(-stdv, stdv)
def forward(self, x, mask=None):
q = torch.matmul(x, self.wq)
k = torch.matmul(x, self.wk)
v = torch.matmul(x, self.wv)
attn, output = self.mha(q, k, v, mask=mask)
return attn, output
if __name__ == "__main__":
n_x = 4
d_x = 80
batch = 2
x = torch.randn(batch, n_x, d_x)
mask = torch.zeros(batch, n_x, n_x).bool()
selfattn = SelfAttention(n_head=8, d_k=128, d_v=64, d_x=80, d_o=80)
attn, output = selfattn(x, mask=mask)
print(attn.size())
print(output.size())
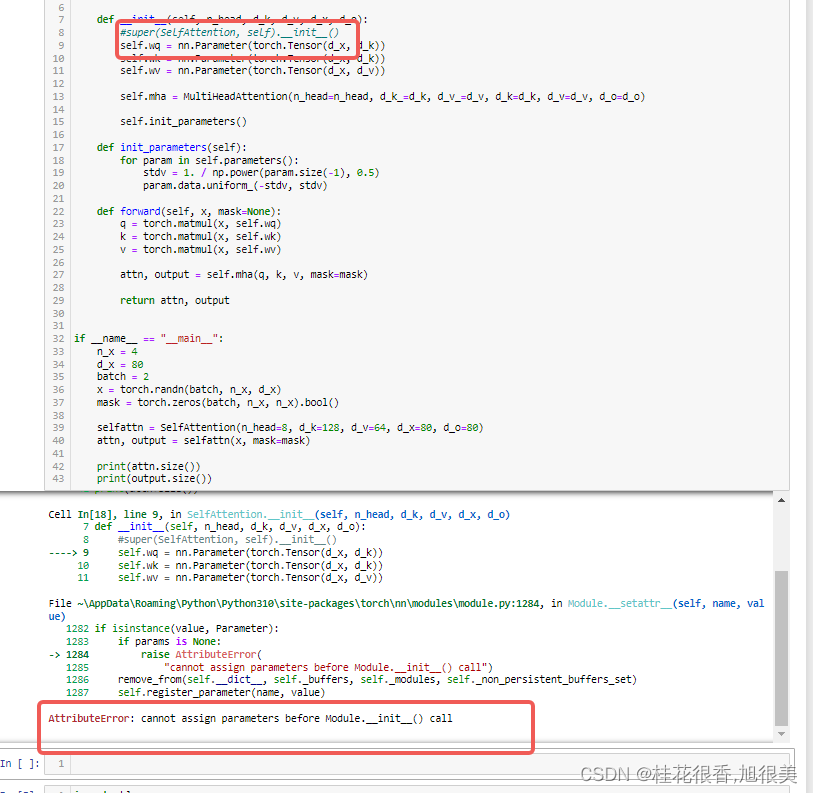
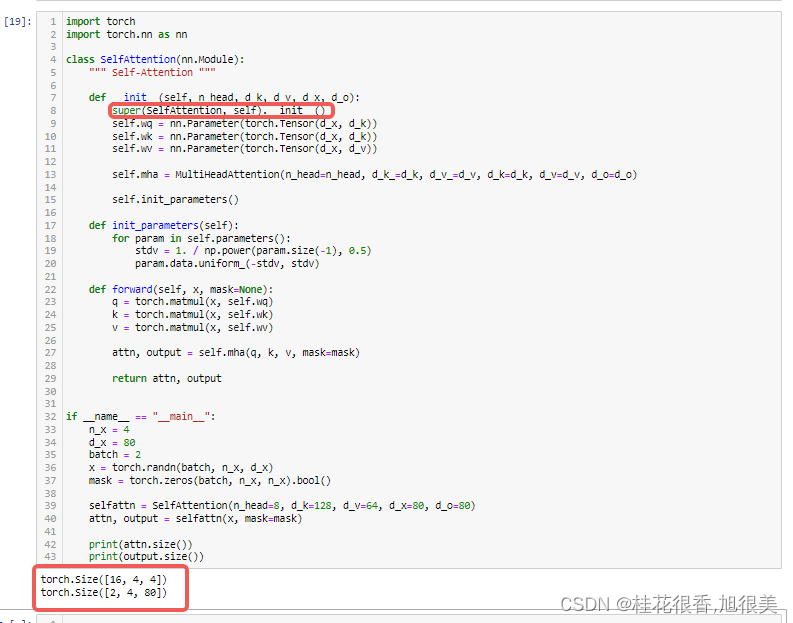
正确案例
import torch
import torch.nn as nn
class SelfAttention(nn.Module):
""" Self-Attention """
def __init__(self, n_head, d_k, d_v, d_x, d_o):
super(SelfAttention, self).__init__()#SelfAttention 是类名
self.wq = nn.Parameter(torch.Tensor(d_x, d_k))
self.wk = nn.Parameter(torch.Tensor(d_x, d_k))
self.wv = nn.Parameter(torch.Tensor(d_x, d_v))
self.mha = MultiHeadAttention(n_head=n_head, d_k_=d_k, d_v_=d_v, d_k=d_k, d_v=d_v, d_o=d_o)
self.init_parameters()
def init_parameters(self):
for param in self.parameters():
stdv = 1. / np.power(param.size(-1), 0.5)
param.data.uniform_(-stdv, stdv)
def forward(self, x, mask=None):
q = torch.matmul(x, self.wq)
k = torch.matmul(x, self.wk)
v = torch.matmul(x, self.wv)
attn, output = self.mha(q, k, v, mask=mask)
return attn, output
if __name__ == "__main__":
n_x = 4
d_x = 80
batch = 2
x = torch.randn(batch, n_x, d_x)
mask = torch.zeros(batch, n_x, n_x).bool()
selfattn = SelfAttention(n_head=8, d_k=128, d_v=64, d_x=80, d_o=80)
attn, output = selfattn(x, mask=mask)
print(attn.size())
print(output.size())