于老师团队又有新作!!
0 Abstract
- 现有的步态识别任务严重依赖上游任务所使用的多种显示步态表征(剪影图、姿态图、点云…),会导致严高额标注成本以及累计错误;
- 文章提出了BigGait框架:
- 挖掘基于多用途知识(all-purpose knowledge)的高效步态表征;
- GRE(Gait Representation Extractor)将步态序列图通过无监督方式转化为隐式步态特征;
- 在大部分的self-domain和cross-domain任务上取得sota。
![[图片]](https://img-blog.csdnimg.cn/direct/6f117ce5d88645f8acb37d744c947e42.png)
1 Introduction
- 目前,多数步态识别的方法有以下流程:
- 首先使用上游模型对RGB的人体步态序列进行过滤,目的是去除无关背景等的影响;
- 其次使用一些归纳偏置对步态表征进行精炼,例如size alignment、coordinate normalization;
- 与以往的方式不同,文章基于Large Vision Models产生的task-agnostic knowledge隐式地构建步态表征,这受启发于:
- LVM产生的多用途特征具有强大的判别性和泛化性;
- LVM的自监督预训练避免了对特定任务的上游模型对使用,从而需不要昂贵的数据标注成本;
- LVM的预训练式来自于web-scale data(任务无关),避免了上游任务的错误累积。
- 文章提出的BigGait框架主要包括以下组成部分:
- 以DINOv2作为任务无关的上游模型;
- 以GaitBase作为下游模型;
- 为了链接上下游模型,将多用途特征转化为有效的步态特征,提出了GRE作为链接:
- Mask Branch:自主推断前景信息(人体步态),过滤背景信息的影响;
- Appearance Branch:该分支直接来自于DINOv2的特征,其会引入纹理相关的特征,这对于步态识别来说是一种噪声;
- Denoising Branch:沿空间维度引入平滑度约束(soft constraints),以减少高频纹理特征,更好保留步态特征。
![[图片]](https://img-blog.csdnimg.cn/direct/3795c21536334dd4a21b9714995386c3.png)
2 Related Work
…
3 Method
3.1 Overview
![[图片]](https://img-blog.csdnimg.cn/direct/57c8b6f1388049f99a70cdce0ca1f6e4.png)
- Input:使用pad and resize将帧序列每一帧图像的大小转化为224 * 448;
- Upstream Model:DINOv2中的冻结ViT,使用ViT-S/14 (21M) 和 ViT-L/14 (300M);
- Central Model:GRE module将all-purpose features转化为useful gait representations;
- Downstream Model:对GaitBase进行小改进以接受双流输入;
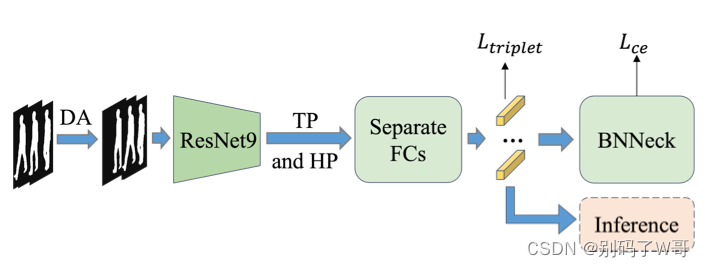
3.2 Gait Representation Extractor
-
Mask Branch:不仅去除背景的影响,同时让前景信息足够diverse和discriminative
- m是一个双通道特征,模型选择激活更多位于图像中心的通道作为前景遮罩;
- 采用二值化和闭操作减少潜在的空腔和断点(前景遮罩的质量更好);
![[图片]](https://img-blog.csdnimg.cn/direct/c018dc4e6b6a4feeb4fe8528803ff768.png)
-
Appearance Branch:步态模型倾向于强调明显不变的步态无关线索,而不是微妙的步态模式
- Eap:通道卷积操作
- fap保留了外观特征,对于步态识别用处不大,因此需要去噪
-
Denoising Branch:过滤无关特征,捕捉相关特征
-
smooth-loss,索贝尔算子,用于消除明显的高频信息,例如服饰图案和明显的条纹信息:
![[图片]](https://img-blog.csdnimg.cn/direct/e81b74ba11d44305a20eecc1d4740198.png)
-
单纯依靠索贝尔算子会造成像素特征过于相似从而失去多样性,为解决这个问题引入了基于信息熵的额外多样性损失(信息熵减少,维持通道特征多样性):
![[图片]](https://img-blog.csdnimg.cn/direct/6c792a31d738451fadd79d1e457b6e09.png)
-
3.3 Visualization of Intermediate Representation
- gait represen- tation based on soft geometrical constraints还需要更多的物理解释
![[图片]](https://img-blog.csdnimg.cn/direct/678627f6249c49579f5d69b5824f4eb4.png)
4 Experiments
-
self-domain:训练测试集统一
![[图片]](https://img-blog.csdnimg.cn/direct/b56f960aae7347a480d4007282f2ed3e.png)
-
cross-domain:训练测试集不统一(步态识别数据集的跨域问题比较严重,因此模型大部分泛化性能不强)
![[图片]](https://img-blog.csdnimg.cn/direct/1f0ce87655444d498150b6cfff17e516.png)
-
Attention map:BigGait只关注身体,特别fde关注运动部位,且在cross-domain体现出良好的泛化性
![[图片]](https://img-blog.csdnimg.cn/direct/5dffd409d8b34180a725746aa2daf8f1.png)
-
消融实验:
-
不同分支的影响
![[图片]](https://img-blog.csdnimg.cn/direct/245c8280b1754f81aa4e5e9e1bc32e21.png)
-
去噪分支
![[图片]](https://img-blog.csdnimg.cn/direct/31b4b12f64224692ba7157851131c0bf.png)
-
更换上游模型
![[图片]](https://img-blog.csdnimg.cn/direct/2f7bdca97f224771a329d6d1f4dd13c2.png)
-
5 Challenges and Limitations
- 挑战:
- 可解释性:本文方法与由清晰直观的物理属性定义的传统步态表示相比可解释性不足;
- 纯度:在直接将RGB视频作为输入的步态方法中,反复出现的挑战涉及在步行序列中有效减少与步态无关的噪音。当试图在没有明确监督的情况下在基于LVM的步态识别中保持步态特征的纯度时(即没有mask或者本文介绍的约束进行辅助的时候),这项任务变得更加艰巨。
- 本文局限性:
- 不同的上游LVM对BigGait的影响只是初步探讨。这个问题值得持续研究;
- GRE模块缺乏时空设计。








![[RoarCTF 2019]Easy Java -不会编程的崽](https://img-blog.csdnimg.cn/direct/c30290a9ed854ab4a2ab07f053fd9a32.png)