目录
五.pandas常见操作
1.pandas处理字符串
以上演示
1-大小写转换
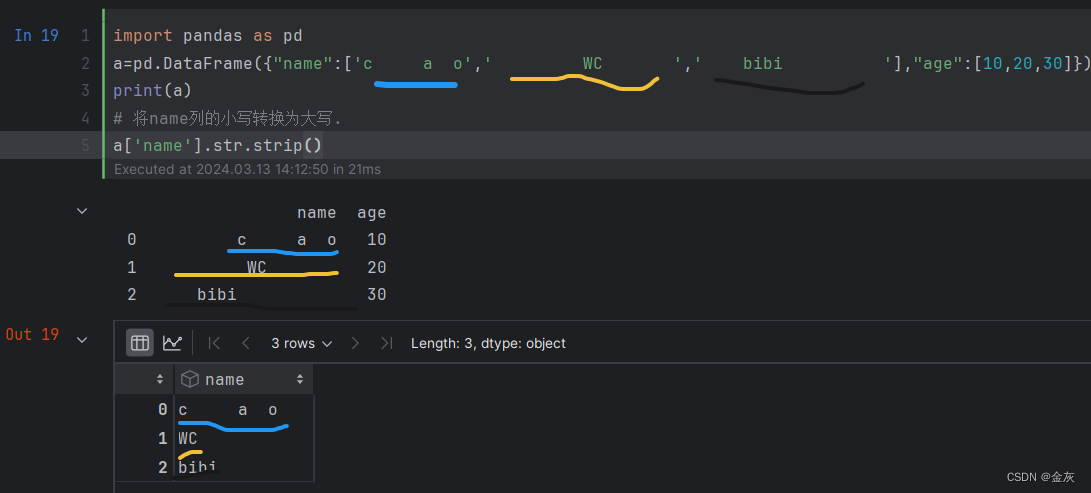
2-去空格(两边) .str.strip()
3-切割
4-连接 .str.cat()
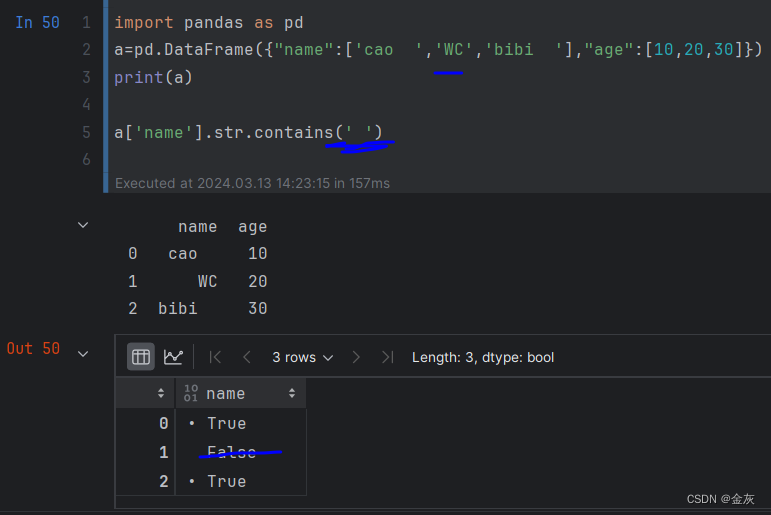
5-空格检测 .str.contains(" ")
6-替换
7-count()--返回元素出现次数
8-repeat()
2.查询操作
2.1 query(" ")
2.2 isin()
2.3 apply()
3.缺失值处理
演示代码
3.1 dropna()
3.2 fillna()
五.pandas常见操作
1.pandas处理字符串
Pandas 提供了一系列的字符串函数,因此能够很方便地对字符串进行处理。
| 函数名称 | 函数功能和描述 |
|---|---|
| lower() | 将的字符串转换为小写。 |
| upper() | 将的字符串转换为大写。 |
| len() | 得出字符串的长度。 |
| strip() | 去除字符串两边的空格(包含换行符)。 |
| split() | 用指定的分割符分割字符串。 |
| cat(sep="") | 用给定的分隔符连接字符串元素。 |
| contains(pattern) | 如果空子字串包含在元素中,则为每个元素返回一个布尔值 True,否则为 False。 |
| replace(a,b) | 将值 a 替换为值 b。 |
| count(pattern) | 返回每个字符串元素出现的次数。 |
| findall(pattern) | 以列表的形式返出现的字符串。 |
| isnumeric() | 返回布尔值,检查 Series 中组成每个字符串的所有字符是否都为数字。 |
| repeat(value) | 以指定的次数重复每个元素。 |
| find(pattern) | 返回字符串第一次出现的索引位置. |
以上演示
1-大小写转换
import pandas as pd
a=pd.DataFrame({"name":['cao','WC','bibi'],"age":[10,20,30]})
print(a)
# 将name列的小写转换为大写.
a['name'].str.upper()

2-去空格(两边) .str.strip()
3-切割

4-连接 .str.cat()

5-空格检测 .str.contains(" ")
6-替换

7-count()--返回元素出现次数
a['name'].str.count('i')
8-repeat()
2.查询操作
2.1 query(" ")
df_data = pd.DataFrame(
{"demo":["python","java","php","javascript"],
"A":[10,11,11,12],
"B":[8,15,11,13],
"C":[12,12,14,15],
"D":[11,13,15,11],
})
print(df_data)
# 按条件筛选
# df_data.query("(A>10) and (B>12)")
# 筛选指定列
# df_data.query("(A>10) & (B>12)")[["demo","C","D"]]
# 筛选某一列
# df_data[df_data["demo"] == "python"]
# df_data.query('demo == "python"')

2.2 isin()

2.3 apply()
apply 函数是 pandas 库中 DataFrame 和 Series 对象的一个方法,它允许你对这些对象中的数据应用一个函数。
df_data = pd.DataFrame({
'A': [1, 2, 3],
'B': [4.000023, 5.000021, 6.000054],
'C': [7, 8, 9]
})
df_data
# 对每一列进行求和操作
df_data.apply(lambda x:x.sum(),axis="index")
# 对每一行进行求和操作
df_data.apply(lambda x:x.sum(),axis="columns")
df_data.apply(lambda x:x.sum()-x.max(),axis="index")
#mean()求均值---对每一列求均值。
df_data.apply(lambda x:x.mean(),axis="index")
# map关系映射
# B列保留两位小数
df_data["B"].map(lambda x:"%.2f"%x)
3.缺失值处理
演示代码
df_data = pd.DataFrame({
"姓名":["张三","李四","王五","赵六"],
"性别":["男",np.nan,"男","男"],
"身高":[180,175,178,np.nan],
},index=[1,3,5,6])
df = df_data.reindex([1,2,3,4,5,6])
3.1 dropna()
DataFrame.dropna(axis=0, how=‘any’, thresh=None, subset=None, inplace=False)
-
axis:默认为0,表示删除行还是列,也可以用“index”和“columns”表示
-
how:{‘any’, ‘all’}, 默认为 ‘any’;any表示只要该行(列)出现空值就删除整行(列),all表示整行(列)都出现空值才会删除整行(列)
-
thresh:表示删除非空值小于thresh个数时删除
-
subset:列表类型,表示哪些列里有空值才删除行或列
# 检查缺失值 df.isnull() # 检查某列缺失值 df["姓名"].isnull() # 删除缺失值 df.dropna(thresh=2) # 全部为空时删除 df.dropna(axis="index",how="all") # 指定列进行空值删除 df.dropna(subset=["身高"])
3.2 fillna()
fillna()的作用是填充缺失值。
# 常量填充缺失值 df.fillna(0) # 计算填充 df["身高"].fillna(df["身高"].mean())