很多初次接触到StructuredStreaming 应该会写一个这样的案例
- py脚本不断产生数据写入linux本地, 通过hdfs dfs 建目录文件来实时存储到HDFS中
1. 指定数据schema: 实时json数据
2. 数据源地址:HDFS
3. 结果落地位置: HDFS
这个小案例重点在于数据传输
- item源码:
// 1. 创建sparksession
val spark: SparkSession = SparkSession.builder().appName("HDFS_source")
.master("local[4]").getOrCreate()
// 1. 指定data源schema---json
val schema = new StructType()
.add("name", dataType = "string")
.add("age", dataType = "integer")
// 2.指定源址hdfssource
val source = spark.readStream
.schema(schema)
.json("hdfs://hadoop102:8020/dataset/dataset")
// 3.结果
val outputPath = "hdfs://hadoop102:8020/filetmp" // 结果存储路径hdfs
source.writeStream
.outputMode(OutputMode.Append())
.format("json")
.option("checkpointLocation", "hdfs://hadoop102:8020/checkpoint") // hdfs检查点的位置
.start(outputPath)
.awaitTermination()
报错信息:java.lang.IllegalArgumentException: 'path' is not specified
就是没有指定流处理的sink path在start()中传入sink path 即可;
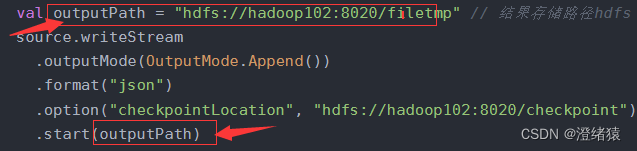
指定checkpointLocation 地址做容错(也就是检查点)
format落地格式 (parquet , json ...)具体场景具体分析
如果只是对数据进行处理然后打印到console 不用指定sink path