目录
一、Windows环境部署Hadoop-3.3.2
1.CMD管理员解压Hadoop压缩包
2.配置系统环境变量
3.下载hadoop winutils文件
4.修改D:\server\hadoop-3.3.2\etc\hadoop目录下的配置文件
(1)core-site.xml
(2)hdfs-site.xml
(3)mapred-site.xml
(4)yarn-site.xml
(5)workers
(6)hadoop-env.cmd
5.初始化hadoop
6.启动Hadoop
7.进入浏览器查看
二、Windows环境部署Spark-3.3.2
1.下载压缩包
2.解压后配置环境变量
3.进入spark-shell
4.进入浏览器
一、Windows环境部署Hadoop-3.3.2
1.CMD管理员解压Hadoop压缩包
不可以直接用winRAR,会报错
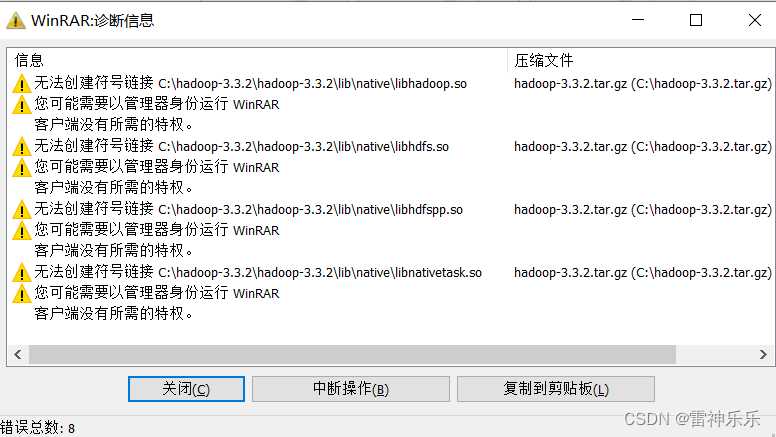
输入命令
start winrar x -y 压缩包 压缩路径
例如,将xx.tar.gz解压到当前目录
cd xxx // 进入到xx.tar.gz目录下
start winrar x -y xx.tar.gz ./ // 即可
##############################################
start winrar x -y hadoop-3.3.2.tar.gz ./2.配置系统环境变量

PATH中添加
3.下载hadoop winutils文件
下载链接:https://github.com/cdarlint/winutils
选择hadoop3.2.2的bin包即可
下载并解压后,将winutils里面的bin目录中所有的文件复制到hadoop-3.3.2/bin目录下,注意不要直接替换整个bin目录,是把bin下的文件复制过去
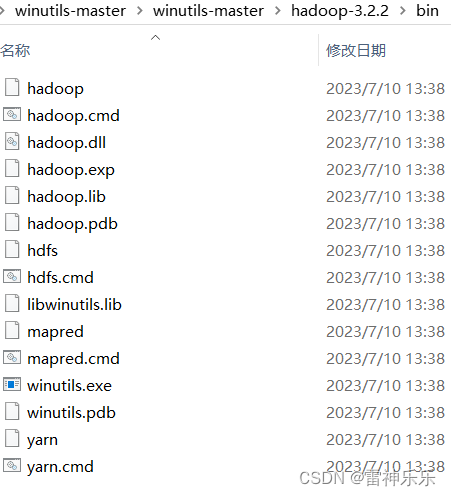
4.修改D:\server\hadoop-3.3.2\etc\hadoop目录下的配置文件
(1)core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/D:/server/hadoop-3.3.2/data/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>(2)hdfs-site.xml
<configuration>
<!-- 这个参数设置为1,因为是单机版hadoop -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/D:/server/hadoop-3.3.2/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/D:/server/hadoop-3.3.2/data/datanode</value>
</property>
</configuration>(3)mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>hdfs://localhost:9001</value>
</property>
</configuration>(4)yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hahoop.mapred.ShuffleHandler</value>
</property>
</configuration>(5)workers
localhost(6)hadoop-env.cmd
# 大约在24行左右
@rem The java implementation to use. Required.
set JAVA_HOME=C:\PROGRA~1\Java\jdk1.8.0_333
# 注意java目录要改成PROGRA~1的位置
# 大约在在最后一行
set HADOOP_IDENT_STRING=%"USERNAME"%5.初始化hadoop
管理员运行CMD
Microsoft Windows [版本 10.0.19045.4046]
(c) Microsoft Corporation。保留所有权利。
C:\WINDOWS\system32>D:
D:\>cd server\hadoop-3.3.2
D:\server\hadoop-3.3.2>hadoop version
Hadoop 3.3.2
Source code repository git@github.com:apache/hadoop.git -r 0bcb014209e219273cb6fd4152df7df713cbac61
Compiled by chao on 2022-02-21T18:39Z
Compiled with protoc 3.7.1
From source with checksum 4b40fff8bb27201ba07b6fa5651217fb
This command was run using /D:/server/hadoop-3.3.2/share/hadoop/common/hadoop-common-3.3.2.jar
D:\server\hadoop-3.3.2>hdfs namenode -format6.启动Hadoop
D:\server\hadoop-3.3.2>cd sbin
D:\server\hadoop-3.3.2\sbin>start-all.cmd
This script is Deprecated. Instead use start-dfs.cmd and start-yarn.cmd
starting yarn daemons
会出现4个窗口
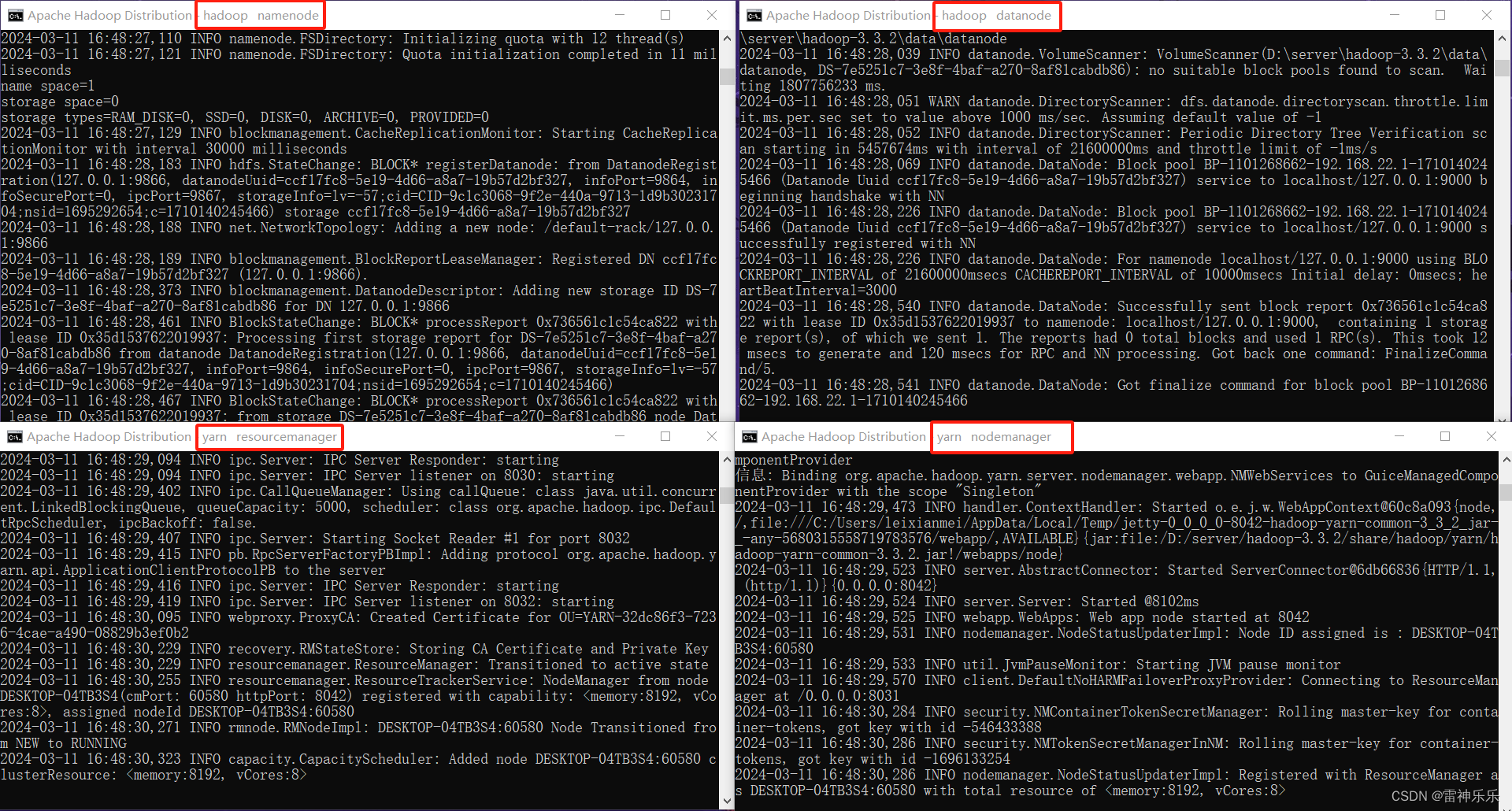
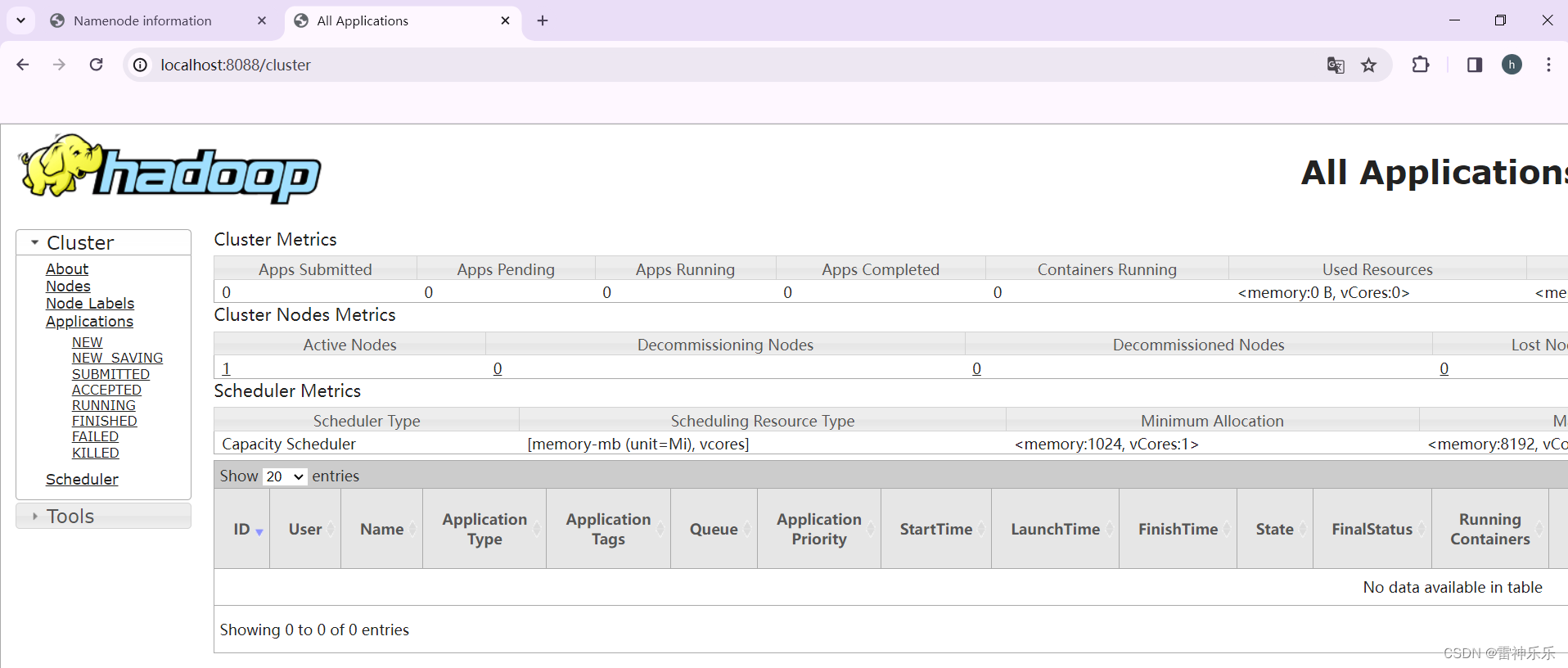
7.进入浏览器查看
localhost:9870

localhost:8088
二、Windows环境部署Spark-3.3.2
1.下载压缩包
Index of /dist/spark/spark-3.3.2

2.解压后配置环境变量
解压命令和上面的解压hadoop命令一样
配置环境变量:
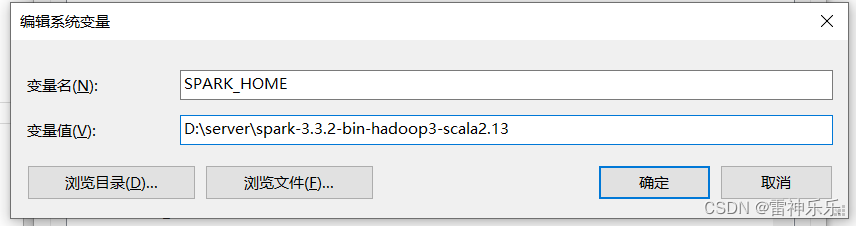
PATH路径添加%SPARK_HOME%\bin
3.进入spark-shell
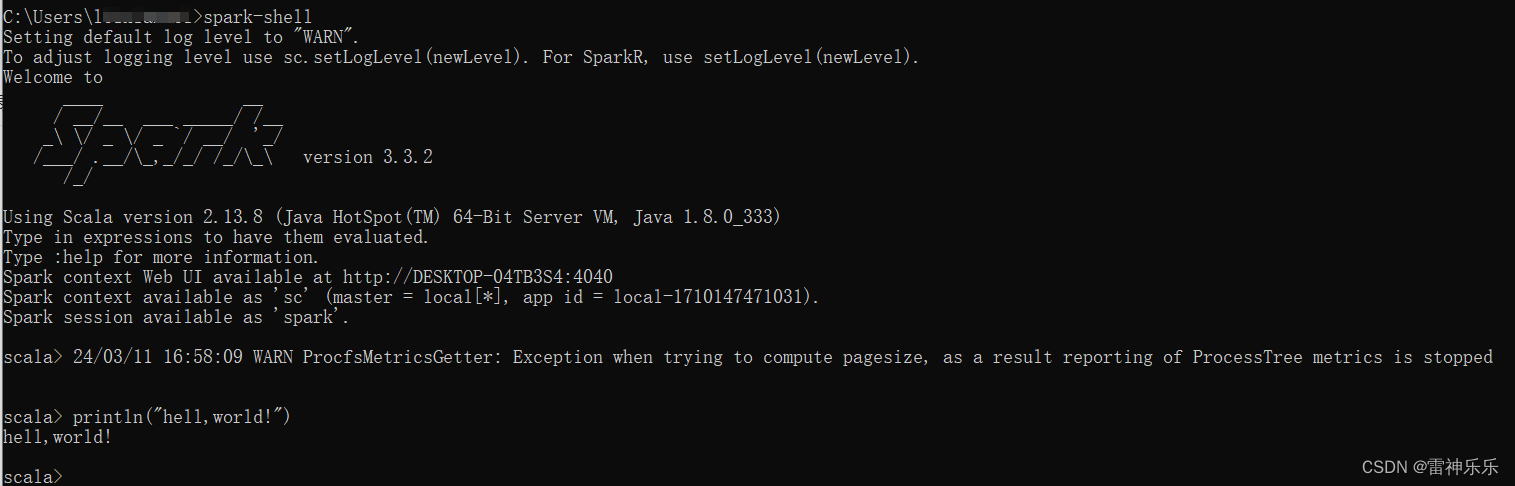
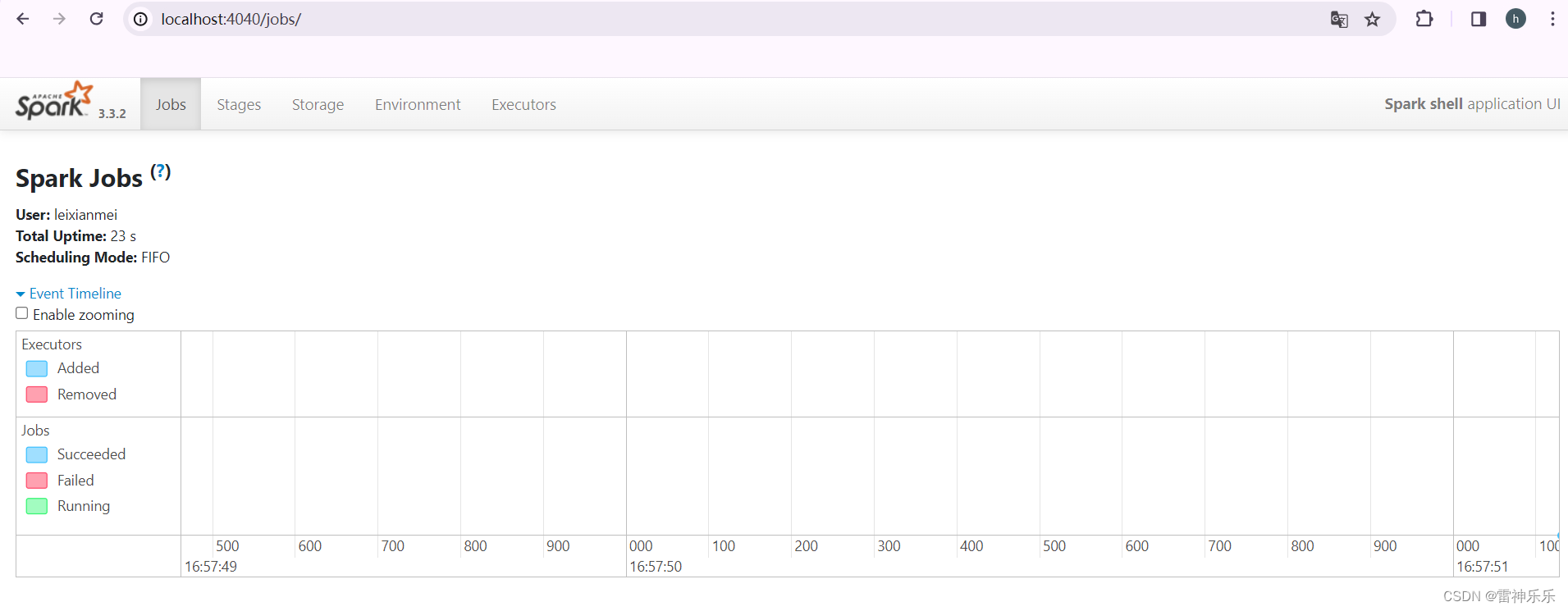
4.进入浏览器
localhost:4040