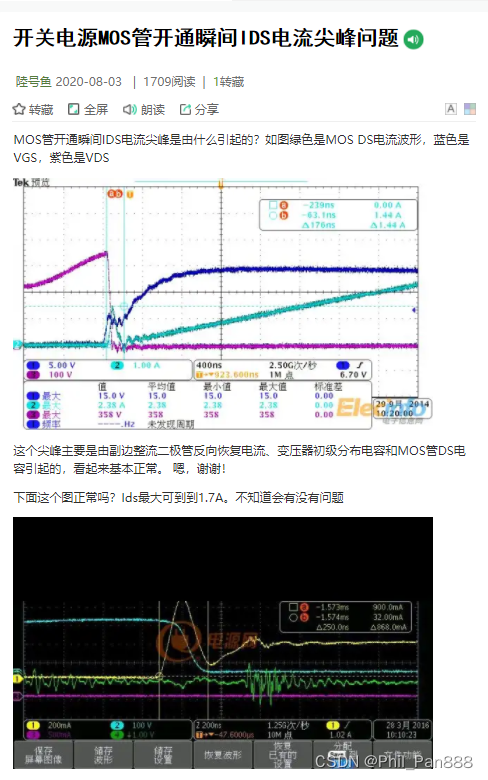
最大池化层
- 最大池化,也叫上采样,是池化核在输入图像上不断移动,并取对应区域中的最大值,目的是:在保留输入特征的同时,减小输入数据量,加快训练。
- 参数设置如下:
- kernel_size:池化核的高宽(整数或元组),整数时表示高宽都为该整数,元组时表示分别在水平和垂直方向上的长度。
- stride:池化核每次移动的步长(整数或元组),整数时表示在水平和垂直方向上使用相同的步长。元组时分别表示在水平和垂直方向上的步长。默认为池化核的高宽。
- padding:控制在输入张量的边界周围添加的零填充的数量(为整数或元组),如果是整数,表示在水平和垂直方向上使用相同的填充数量。如果是元组,分别表示在水平和垂直方向上的填充数量。默认为0
- dilation:卷积核内部元素之间的距离,空洞卷积,如图:

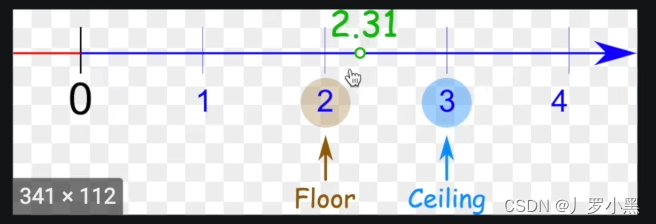
- ceil_mode:True表示ceil模式,即向上取整,保留未满部分。False表示floor模式,即向下取整,舍去未满部分。默认为False,如图:
- 如下是示意图:
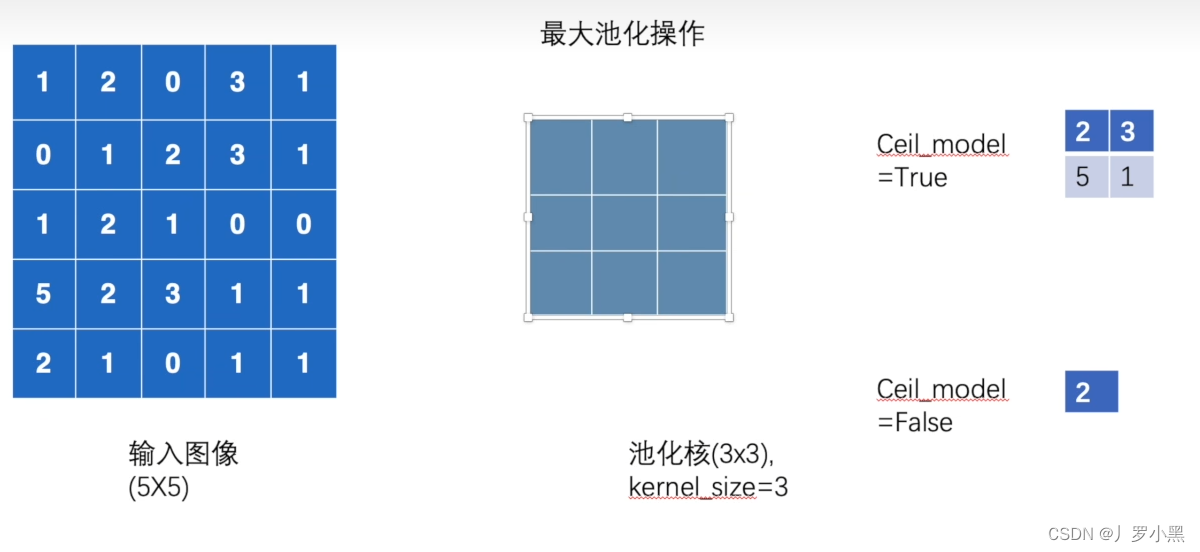
- 以下是代码实现:
- 注意:部分版本的MaxPool2d不支持int类型,所以需要指定数据类型为浮点数
import torch
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]], dtype=torch.float32) # 由于部分版本的MaxPool2d不支持int类型,所以这里需要指定数据类型为float32
input = torch.reshape(input, (-1, 1, 5, 5)) # 将input从二维张量变成(N, C, H, W)的四维张量
print(input.shape)
class Tudui(torch.nn.Module):
def __init__(self):
super().__init__()
self.pool1 = torch.nn.MaxPool2d(kernel_size=3, ceil_mode=True) # 最大池化层,池化核大小3*3,向上取整
def forward(self, input):
output = self.pool1(input)
return output
tudui = Tudui()
output = tudui(input)
print(output)
# 输出结果为
# torch.Size([1, 1, 5, 5])
# tensor([[[[2., 3.],
# [5., 1.]]]])
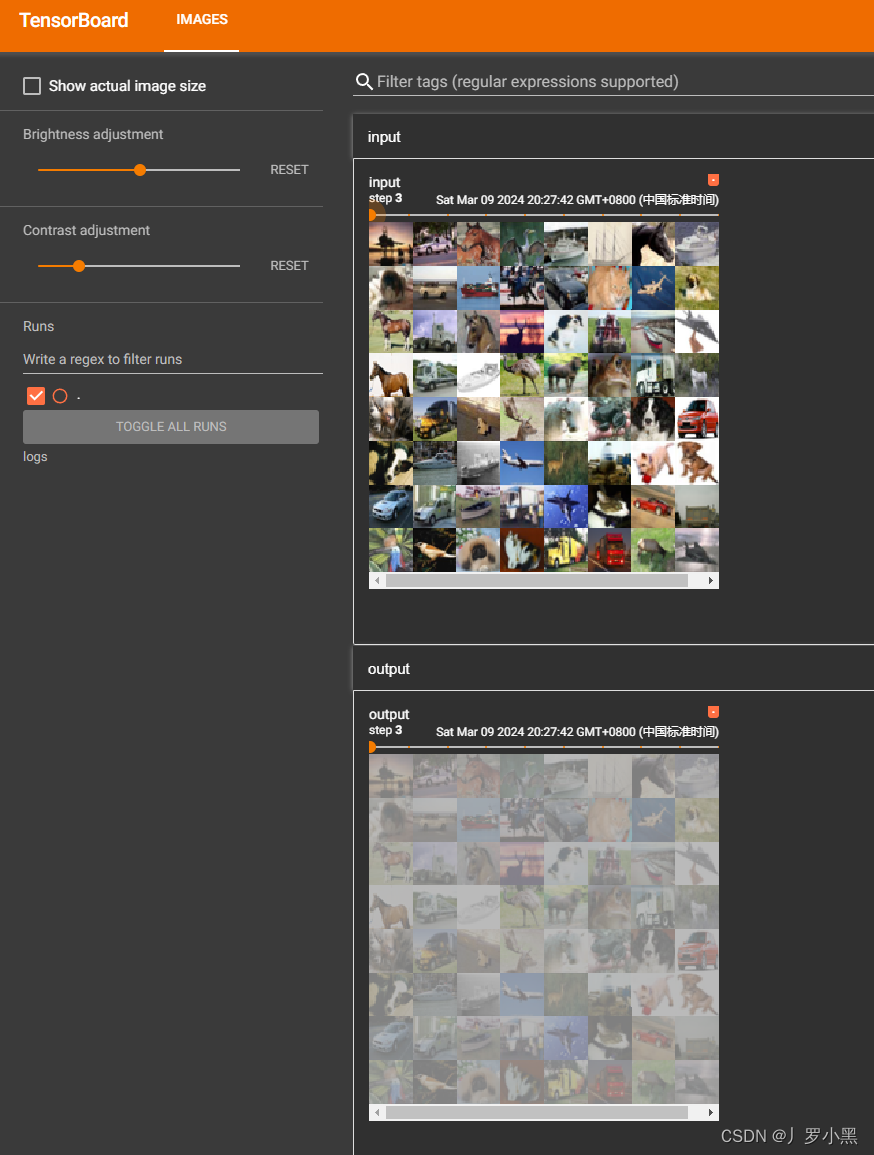
- 同样可以通过tensorboard进行展示输入输出结果,代码如下:
- 由于最大池化层不会改变channel,所以不需要对输出进行reshape()操作
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
test_dataset = torchvision.datasets.CIFAR10(root='Dataset', train=False, download=True, transform=torchvision.transforms.ToTensor())
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=4, shuffle=False, num_workers=0)
class Tudui(torch.nn.Module):
def __init__(self):
super().__init__()
self.pool1 = torch.nn.MaxPool2d(kernel_size=3, ceil_mode=True) # 最大池化层,池化核大小3*3,向上取整
def forward(self, input):
output = self.pool1(input)
return output
tudui = Tudui()
writer = SummaryWriter("logs") # 创建一个SummaryWriter对象,指定日志文件保存路径
step = 0
for data in test_loader:
imgs, targets = data # 获取输入数据
outputs = tudui(imgs) # 调用网络模型进行前向传播
writer.add_images("input", imgs, step) # 将输入数据imgs写入日志文件
# 由于最大池化层不会改变通道数,所以不需要对outputs进行reshape()操作
writer.add_images("output", outputs, step) # 将输出数据outputs写入日志文件
step += 1
writer.close()
- 结果如下:
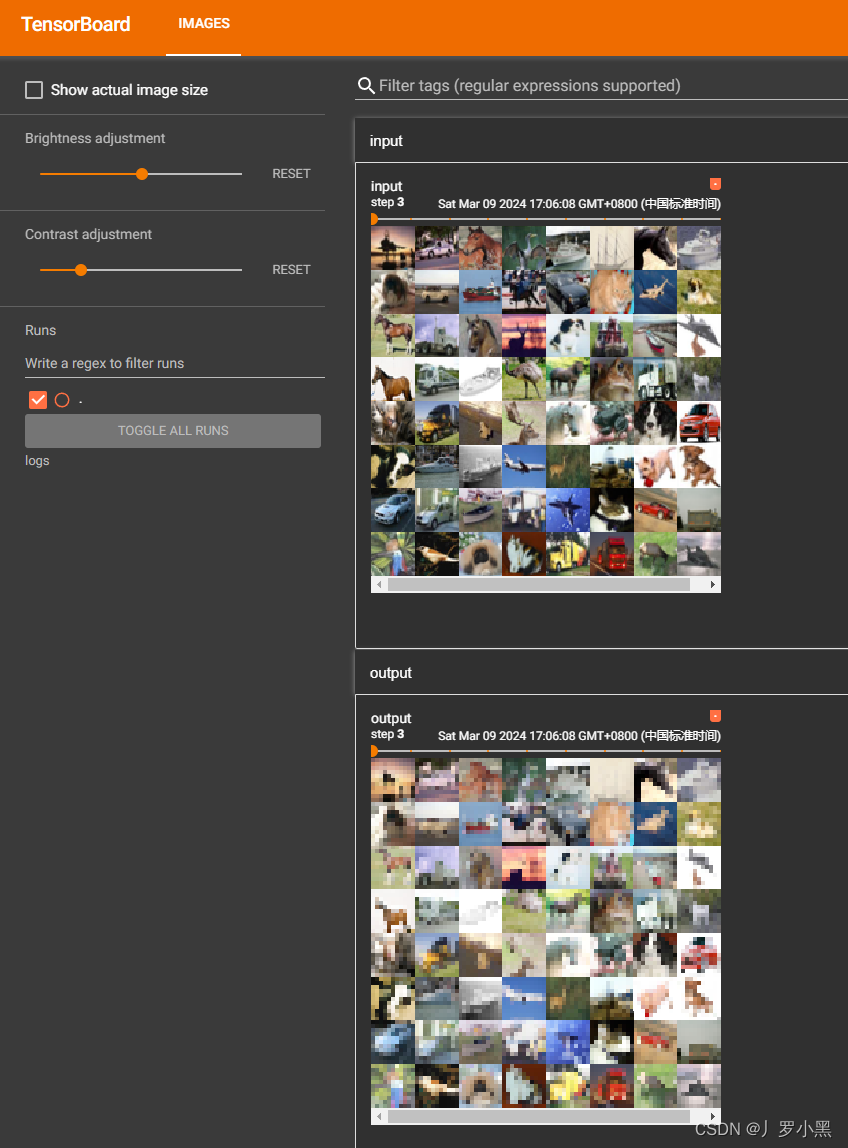
非线性激活层
- 主要目的是向网络中引入一些非线性特征,非线性越多,才能训练出符合复杂数据集的模型,提高模型的泛化性
- 常用的非线性激活层有:ReLU、Sigmoid,如下:
-
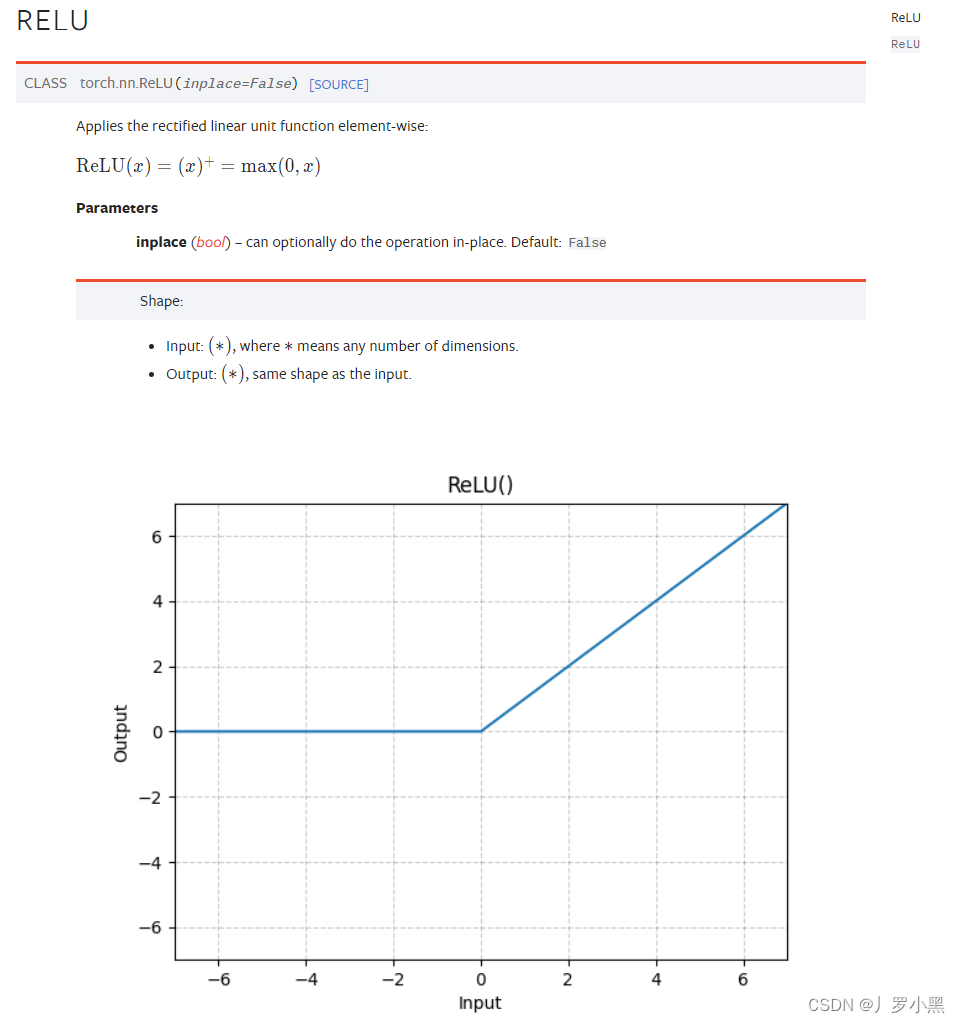
ReLU:当输入大于0时,输出等于输入。当输入小于0时,输出等于0。
-
注意:输入的第一个位置要是batch_size,之后的不做限制
-
inplace:是否对输入进行结果替换,默认为False(不替换),并返回输出

-
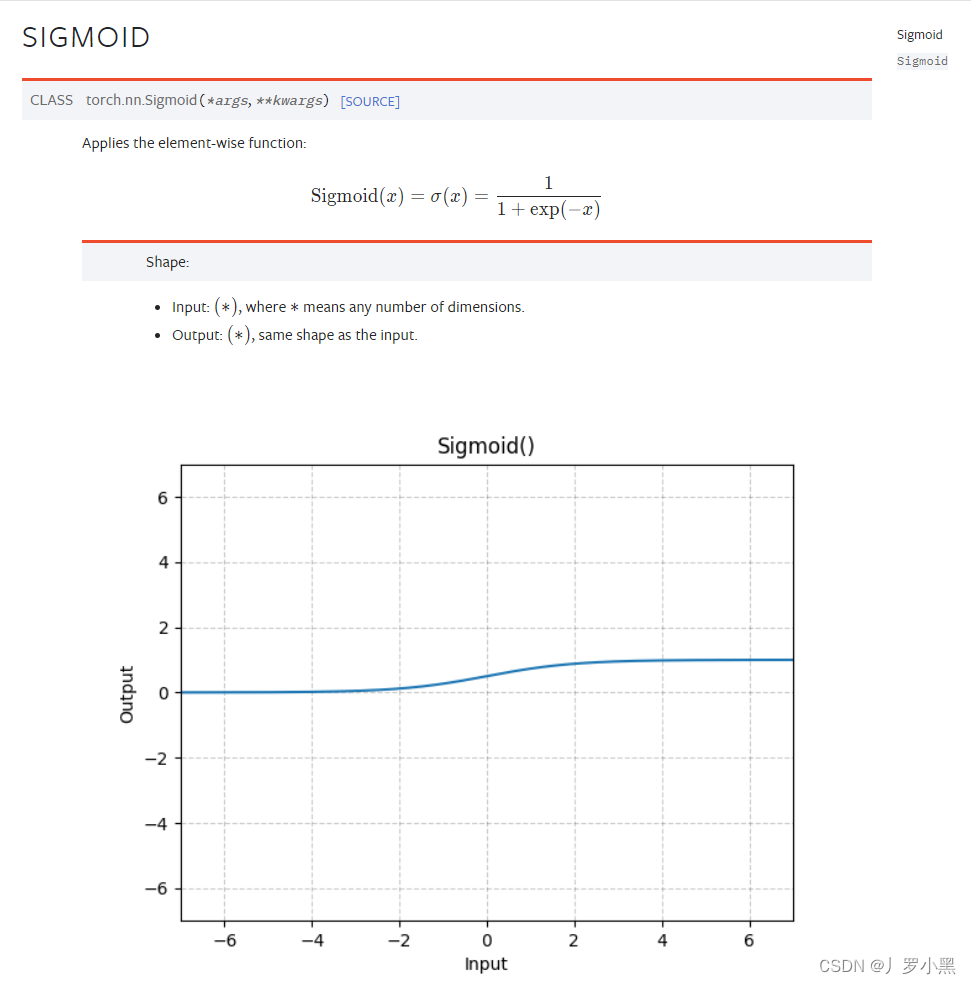
Sigmoid:将输入经过以下公式,得到输出。
-
注意:第一个位置也要是batch_size,之后的不做限制:
-
- ReLU激活函数代码如下:
import torch
from torch import nn
input = torch.tensor([[1, -0.5],
[-1, 3]])
# 由于ReLU激活函数需要第一个维度为batch_size,所以需要对输入input进行reshape操作
input = torch.reshape(input, (-1, 1, 2, 2))
class Tudui(nn.Module):
def __init__(self): # 初始化
super().__init__() # 继承父类的初始化
self.relu1 = nn.ReLU() # ReLU激活函数
def forward(self, input):
output = self.relu1(input) # 调用ReLU激活函数对输入input进行激活
return output
tudui = Tudui()
output = tudui(input)
print(output)
# 输出结果:
# tensor([[[[1., 0.],
# [0., 3.]]]])
- Sigmoid激活函数代码如下:
import torch
import torchvision
from torch import nn
from torch.utils.tensorboard import SummaryWriter
test_dataset = torchvision.datasets.CIFAR10(root='Dataset', train=False, download=True, transform=torchvision.transforms.ToTensor())
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False, num_workers=0)
writer = SummaryWriter("logs") # 创建一个SummaryWriter对象,指定日志文件保存路径
class Tudui(nn.Module):
def __init__(self): # 初始化
super().__init__() # 继承父类的初始化
self.sigmoid1 = nn.Sigmoid() # Sigmoid激活函数
def forward(self, input):
output = self.sigmoid1(input) # 调用Sigmoid激活函数
return output
step = 0
for data in test_loader:
imgs, targets = data
tudui = Tudui() # 实例化网络模型
writer.add_images("input", imgs, step) # 将输入数据imgs写入日志文件
outputs = tudui(imgs) # 调用网络模型进行前向传播
writer.add_images("output", outputs, step) # 将输出数据outputs写入日志文件
step += 1
writer.close() # 关闭日志文件
- 结果如下:
正则化层
- 用的不是很多,但是有篇论文说,采用正则化层可以加快神经网络的训练速度,参数设置如下:
- num_features:输入中的channel数

- num_features:输入中的channel数
循环层
- 一种特定的网络结构,在文字识别中用的比较多
Transform层
- Pytorch把Transform封装成网络层
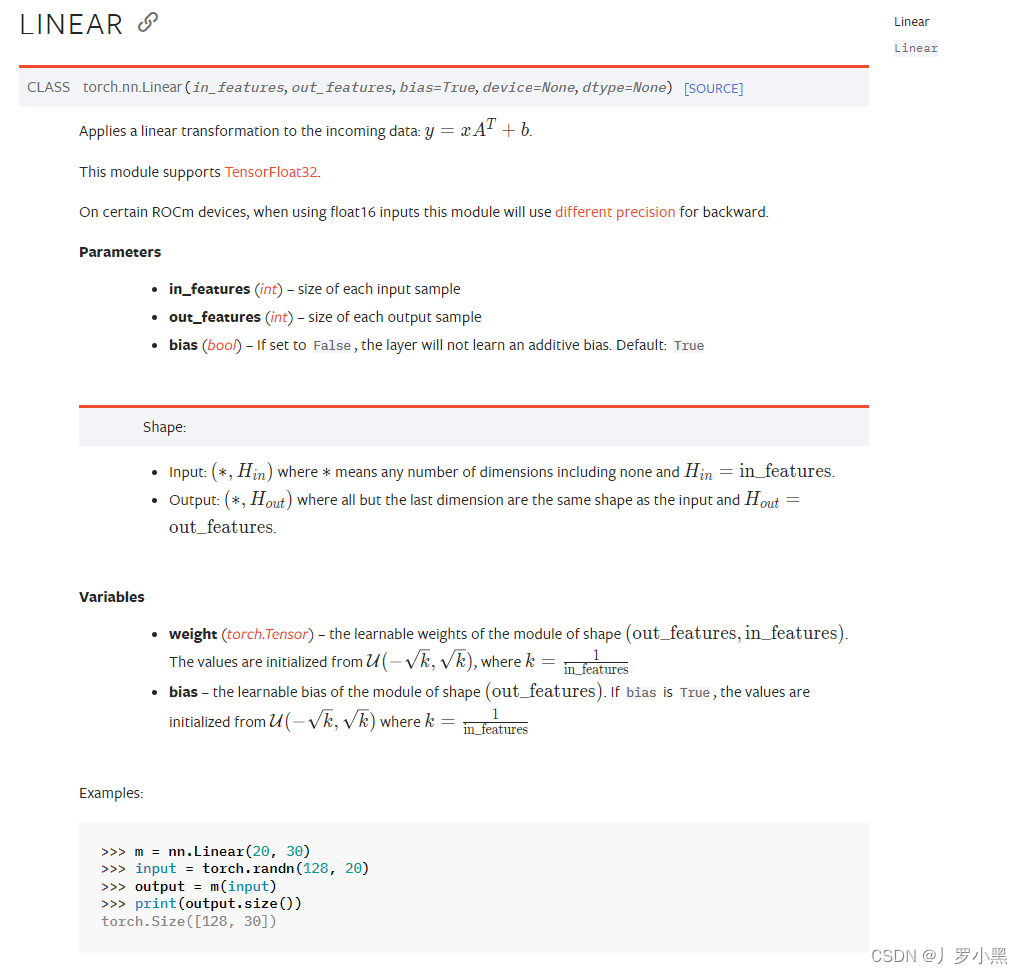
线性层
-
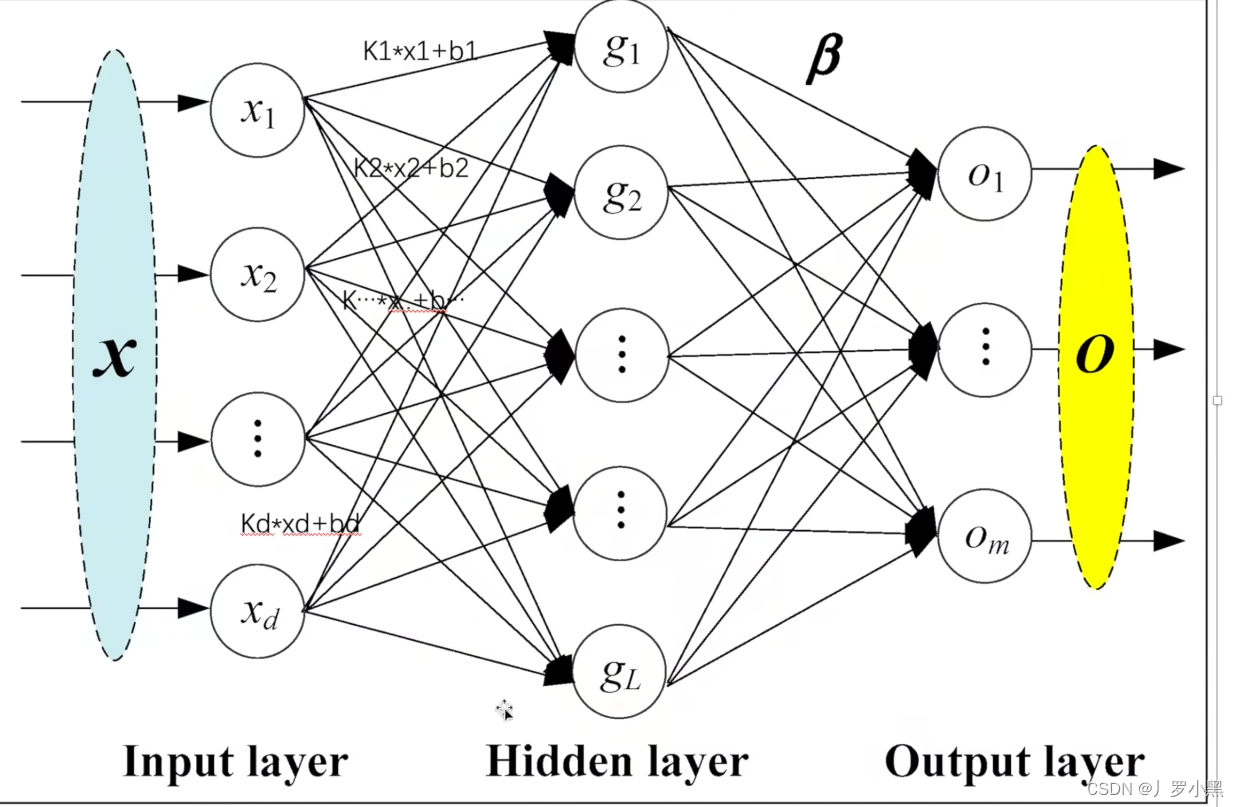
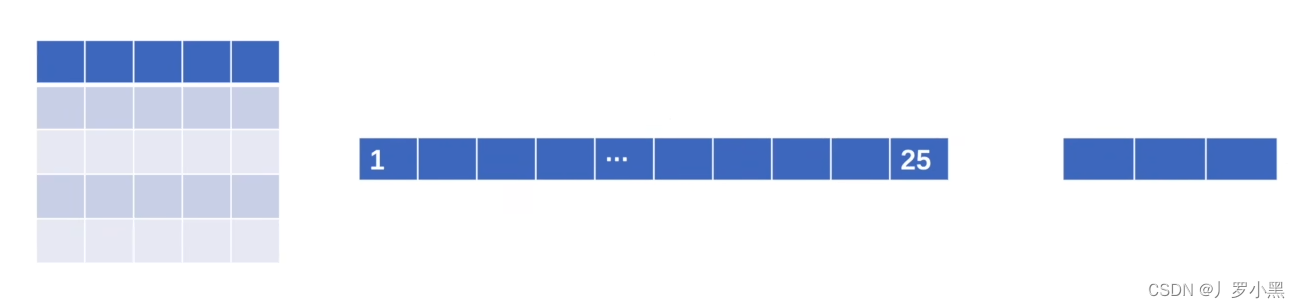
其作用是将输入的数据进行线性变换,即将输入数据乘以权重矩阵,并加上偏置向量,以生成输出数据,如下图所示,从x到g的过程就是经历了一个线性层:
- 注意:线性层需要输入数据为一维,所以对于图像数据,我们先要进行拉直操作
- 由下图可以看出:线性层会对每个输入元素进行kx+b的操作,而如果输入数据是一维的,那么只需要定义两个数组(权重数组、偏置数组)即可,虽然会丢失一些空间信息,但是简化了模型的实现和参数的管理,所以线性层需要输入数据为一维。
-
以下是参数设置:
- in_features:(可以有多位,但是最好满足是一维向量的形式,且最后一位是输入特征数,也可以只有一位,即只有输入特征数)输入特征数,即上图的x的个数d
- out_features:输出特征数,即上图的g的个数L
- bias:偏置,即上图的b,默认为True,即加一个偏置
-
代码实现如下:
- 注意:由于我们定义的线性层的输入特征要是196608,所以我们要在test_loader中设置drop_last=True,如果我们不设置drop_last=True,最后一个batch的样本数不足64,输入特征不满足196608,就会报错
- 可以使用reshape()对输入进行格式转换,同时由于输入可以仅仅只有输入特征数,所以flatten()也可以用来对输入进行格式转换
import torch
import torchvision
from torch import nn
# input = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# print(input.shape)
# input = torch.reshape(input, (1,1,1,-1))
# print(input.shape)
test_dataset = torchvision.datasets.CIFAR10(root='Dataset', train=False, download=True, transform=torchvision.transforms.ToTensor())
# 由于我们定义的线性层的输入特征要是196608,所以如果我们不设置drop_last=True,最后一个batch的样本数不足64,输入特征不满足196608,就会报错
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False, num_workers=0, drop_last=True) # drop_last=True表示如果最后一个batch的样本数少于batch_size,则丢弃
class Tudui(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(196608,3) # 输入特征数为196608,输出特征数为3
def forward(self, input):
output = self.linear1(input)
return output
tudui = Tudui()
for data in test_loader:
imgs, targets = data
# 可以使用torch.reshape()函数将输入数据imgs的shape从[64, 3, 32, 32]变为[1, 1, 1, 196608]
# imgs = torch.reshape(imgs, (1,1,1,-1)) # 将输入数据imgs的shape从[64, 3, 32, 32]变为[1, 1, 1, 196608]
# 也可以使用torch.flatten()函数将输入数据imgs的shape从[64, 3, 32, 32]变为[196608]
imgs = torch.flatten(imgs) # 将输入数据imgs的shape从[64, 3, 32, 32]变为[196608]
outputs = tudui(imgs) # 得到输出,且输出的shape为[3]
print(outputs.shape)
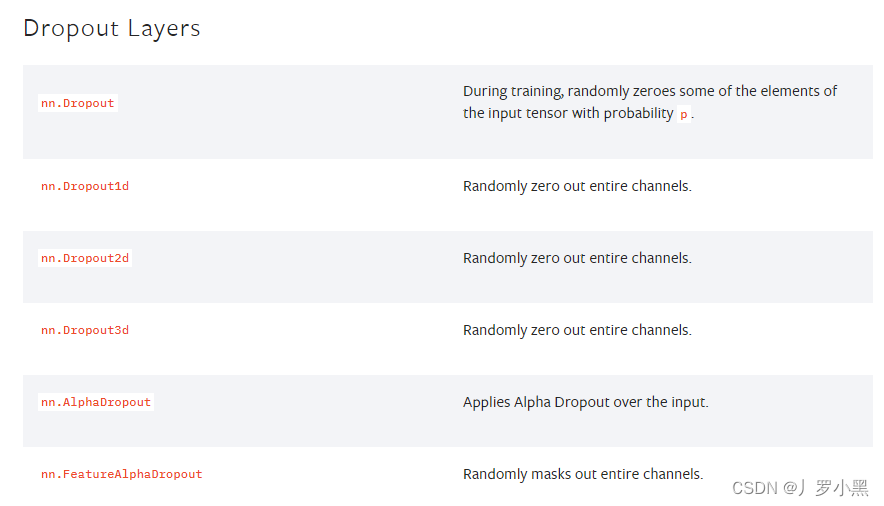
Dropout层
- 在训练中,以一定概率将输入中的随机元素变成0,为了防止过拟合