| java数据结构与算法刷题目录(剑指Offer、LeetCode、ACM)-----主目录-----持续更新(进不去说明我没写完):https://blog.csdn.net/grd_java/article/details/123063846 |
|---|
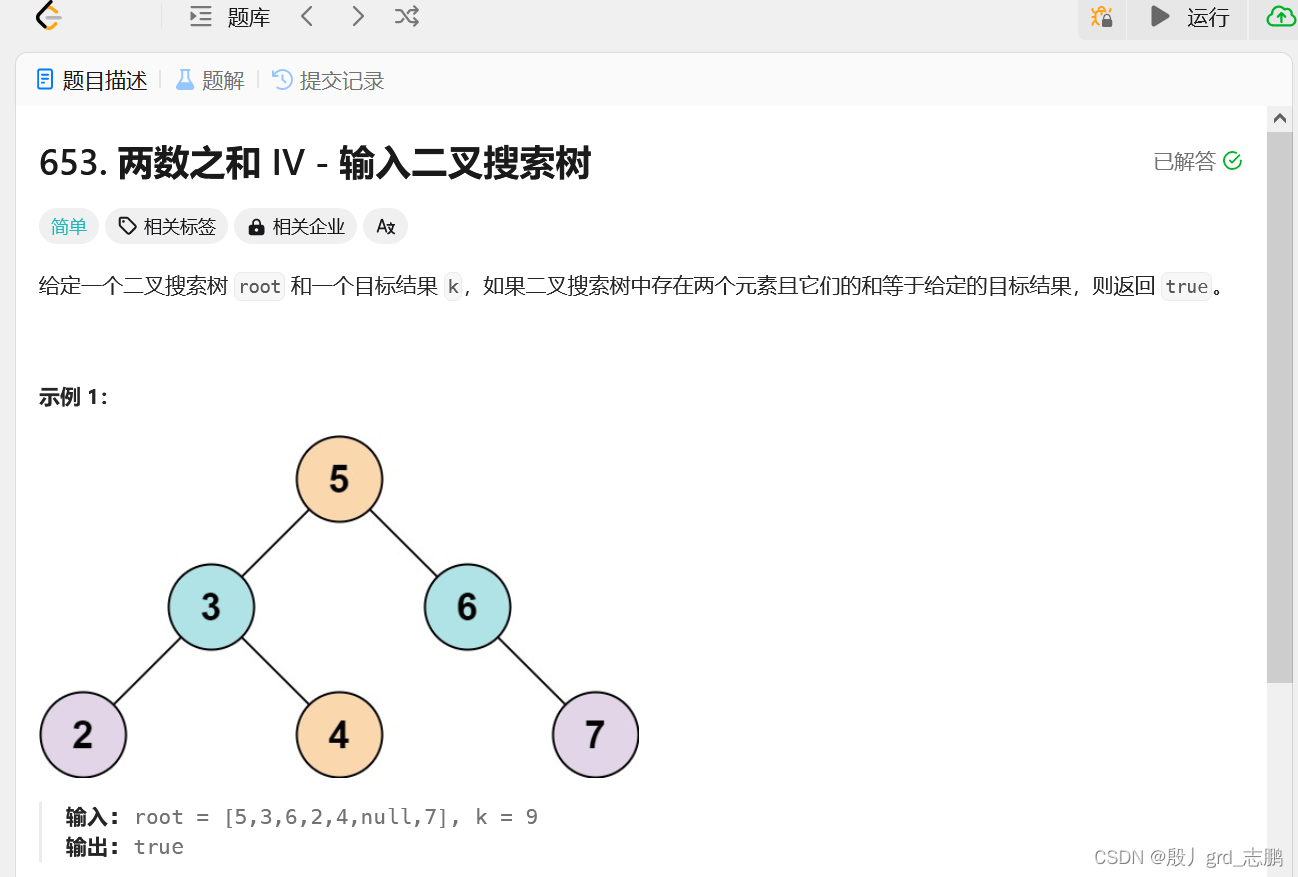
1. 前序遍历加hash
- 使用hash表存储每个结点值
- 每次遍历新结点时,查找hash表是否包含一个数a,和当前结点的值b能组成目标值target
| 代码:使用编程语言自带的hash表,因为健壮性考虑,这些处理会需要额外的时间开销,所以耗时会多一点 |
|---|
class Solution {
Set<Integer> set = new HashSet<Integer>();
public boolean findTarget(TreeNode root, int k) {
if (root == null) return false;
if (set.contains(k - root.val)) return true;
set.add(root.val);
return findTarget(root.left, k) || findTarget(root.right, k);
}
}
2. 中序遍历+双指针
- 因为是二叉搜索树,中序遍历结果正好是一个有序的升序序列
- 先获取中序遍历结果,然后使用双指针找目标值
- 左右两边之和a,如果a小于目标值target,则left++,如果a大于target,则right–
class Solution {
public boolean findTarget(TreeNode root, int k) {
ArrayList<Integer> list = new ArrayList<Integer>();
dfs(root,list);
int left = 0,right = list.size()-1;
while(left<right){
int num = list.get(left)+list.get(right);
if(num == k) return true;
else if(num < k)left++;
else right--;
}
return false;
}
public void dfs(TreeNode root , ArrayList<Integer> list){
if(root == null) return;
dfs(root.left,list);
list.add(root.val);
dfs(root.right,list);
}
}