C语言:自定义类型 - 结构体 & 联合体 & 枚举
- 结构体
- 结构体声明
- 结构体创建
- 匿名结构体
- 初始化
- 结构体的重命名
- 结构体访问
- 内存对齐
- 位段
- 联合体
- 枚举
在C语言中,自定义类型是指程序员可以通过一系列的定义和说明来创建的新的数据类型。这些自定义类型可以是基本类型的组合或者是基于现有类型的扩展。包括数组在内,C语言的自定义类型有:数组,结构体,联合体,枚举
结构体
结构体是一些不同类型值的集合,这些值称为成员变量
结构体声明
基本语法:
struct name
{
member-list;
}; //此处有分号
struct:结构体关键字,用于声明结构体
name:结构体名称
member - list:成员列表
比如描述一个学生:
struct Stu
{
char name[20];//名字
int age;//年龄
char sex[5];//性别
char id[20];//学号
};
此时这个结构体Stu内部就有四个变量name,age,sex,id,它们称为成员变量。
结构体创建
结构体是一种类型,类型就是用来创建变量的,那么我们要如何通过这个自定义的类型来创建变量?
以Stu结构体为例:
struct Stu
{
char name[20];
int age;
char sex[5];
char id[20];
};
此结构体的名称为Stu,其类型为struct Stu,也就是说结构体的类型是struct关键字 + 名称
直接创建:
我们创建一个整型变量为int a;,也就是类型 + 变量名。而结构体的类型为struct + 名称,所以创建Stu的变量语法为:
struct Stu a;
再比如创建该结构体的指针:
struct Stu* pa;
该结构体的数组:
struct Stu arr[10];
声明时创建:
结构体是可以在声明的同时创建变量的,只需要将变量写在结构体末尾的} 与;之间。
比如创建一个a变量:
struct Stu
{
char name[20];
int age;
char sex[5];
char id[20];
}a; //此处创建了a变量
如果需要创建多个变量,那就用逗号分开:
struct Stu
{
char name[20];
int age;
char sex[5];
char id[20];
}a, *p, arr[10];
此处创建了三个变量,分别是结构体a,该结构体的指针p,该结构体的数组arr。
注意:通过这种方式创建的变量为全局变量。
匿名结构体
结构体在声明时,其实名字是可以省略的,这种结构体叫匿名结构体。
匿名结构体必须在声明时定义变量。因为匿名结构体没有名称,后续无法通过这个匿名结构体的类型来定义变量,所以必须在声明时定义变量。
示例:
struct
{
int a;
double b;
char c;
}x;
上述代码就是一个匿名结构体,它在struct关键字后面没有名称,但是在声明时定义了一个变量x。后续我们可以使用这个x,但是无法创建一个与x相同类型的变量了。
看到一下代码:
struct
{
double b;
char c;
}x1;
struct
{
double b;
char c;
}x2;
请问:x1与x2是同一类型吗?
此处定义了两个匿名结构体,它们的成员变量完全一致,但是它们并不是同一种类型的变量。
匿名结构体之间,哪怕成员变量完全一致,也是两个不同类型的结构体
初始化
结构体的初始化分为两种:按照顺序,不按照顺序。
按照顺序初始化:
struct Stu a = {"zhangsan", 20, "男", "2023200512225"};
以上代码,将Stu结构体中的name = "zhangsan",age = 20,sex = “男”,id = "202320051225"。这就是按照顺序直接初始化,赋值也是如此。
不按照顺序初始化:
struct Stu a = { .age = 20, .id = "2023200512225", .name = "zhangsan",.sex = "男" };
如果不按照顺序,那么就要指定每一个成员的值是谁,注意成员名前面有一个.。
在声明时创建同理:
struct Stu
{
char name[20];
int age;
char sex[5];
char id[20];
}a = {"zhangsan", 20, "男", "2023200512225"};
结构体的重命名
结构体可以使用typedef进行重命名,但是其有不一样的语法规则。
一般形式:
struct A
{
double b;
char c;
};
typedef struct A sA;
最后一个typedef就是我们的结构体重命名,这是符合一般的typedef重命名规则的,此处将struct A重命名为了sA。
很多时候我们会这样做:
typedef struct A A;
很多人也许会疑惑:为什么要把结构体A重命名为A?
首先,此处重命名的不是A,而是struct A。
其次,这么做的意义是:我们平时利用结构体定义变量时要用struct A xxx;,而typedef为A后,就可以A xxx;这样创建变量,可以少写一个struct 关键字,所以很常用。
声明时重命名:
结构体还有特殊的重命名语法:在声明时重命名
typedef struct A
{
double b;
char c;
}sA;
将typedef写在struct的前面,将新名称sA写在}与;之间。
其效果和typedef struct A sA;一致。
结构体访问
访问结构体变量的成员,有两种方式:通过变量访问 与 通过指针访问。
通过变量访问:
结构体成员访问操作符.,可以访问到一个结构体成员变量。
依然以Stu结构体为例:
struct Stu
{
char name[20];
int age;
char sex[5];
char id[20];
};
访问:
struct Stu s = {"zhangsan", 20, "男", "2023200512225"};
char* c = s.name;
int a = s.age;
s.id = "202420101001";
以上示例中,我们通过.访问了三个成员变量,s.name访问了name成员,并它的值赋给c;s.id则是访问了id成员,并把它的值改为"202420101001"。
通过指针访问:
有的时候我们会得到结构体的指针,此时就要解引用后访问:
struct Stu s = {"zhangsan", 20, "男", "2023200512225"};
struct Stu* ps = &s;
此时我们得到了一个结构体指针ps,接下来我们尝试访问:
*ps.name = "lisi";
首先我们解引用了指针*ps,然后通过结构体访问操作符.访问了name成员。但是这个写法是错误的,因为*的优先级比.高,其会先通过ps访问ps.name,这就会发生错误,所以我们要用小括号()调整执行顺序,像这样:
*(ps).name = "lisi";
这样访问实在是太别扭了,C语言还有另外一种通过指针访问结构体成员的方式,另外一个结构体成员访问操作符->。其可以通过指针访问结构体:
ps->name = "lisi";
ps->age = 18;
这样就方便很多了。
内存对齐
请问以下结构体占用的内存是多大:
struct S1
{
char c1;
int i;
char c2;
};
经过粗略计算,我们得到char + int + char = 1 + 4 + 1 = 6,即6字节,我们试验一下看看:
printf("%d", sizeof(S1));
输出结果:12(vs2022环境下,其它编译器有可能得到不同结果)
这就奇怪了,为啥是12啊?这就涉及到结构体特殊的内存对齐规则了。
内存对齐规则:
- 结构体的第⼀个成员对⻬到相对结构体变量起始位置偏移量为0的地址处
- 其他成员变量要对⻬到对⻬数的整数倍的地址处。
- 结构体总⼤⼩为最⼤对⻬数的整数倍
- 如果嵌套了结构体的情况,嵌套的内层结构体成员对⻬到⾃⼰的成员中最⼤对⻬数的整数倍处,外层结构体的最⼤对⻬数就是内外层结构体中所有成员的最大对⻬数
这套规则光看文字比较晦涩,还是需要结合案例讲解,我们一条一条拆分出来:
现在有如下内存,左侧的数值为相对地址:

假设我们要在这里面存放结构体:
struct S1
{
char c1;
int i;
char c2;
};
规则1:第一个成员变量对齐到起始位置偏移量为0的地方,由于第一个成员是char类型,所以占一个字节,当前内存分布如下:

随后我们放置第二个变量i
规则2:其它成员变量对齐到对齐数的整数倍的地址处。
什么是对齐数?对齐数就是一个数值,其会限制一个成员的对齐规则。而不同编译器有自己的默认对齐数,在vs2022中,默认对齐数为8,在Linux中,没有默认对齐数。
成员对齐数 = 该成员的大小 与 默认对齐数的较小值
比如在当前的vs2022环境下,成员变量i的类型是int类型,其大小为4字节,而vs2022的默认对齐数为8字节,最后i的对齐数 = min(4, 8),也就是4。
现在我们得到了i的对齐数,现在就应该内存对齐了,再看一遍规则2:其它成员变量对齐到对齐数的整数倍的地址处。也就是是说,我们的i要落在4的倍数处。当前C1只占用了一个内存,下一个是4的倍数的地址就是4地址,i对齐到此处,而i占用四个字节,现在内存分布如下:
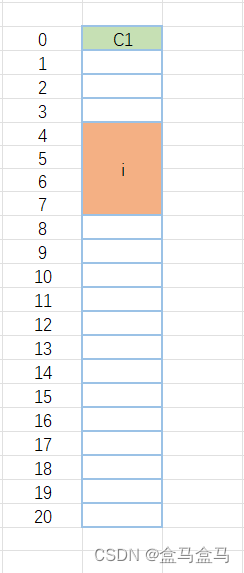
然后是最后一个变量C2的位置,首先根据规则2,其对齐数为char类型大小1以及默认对齐数8的较小值,即1。所以C2要对齐到1的倍数处。下一个1的倍数就是8内存处,而C2占用1字节,现在内存分配如下:

现在我们知道三个成员分别是如何对齐的了,那么结构体最后是多大呢?
三个成员对齐后,加起来共占用了9块内存,那么内存是9吗?
并不是的,这就要看到规则3:结构体的总大小为最大对齐数的整数倍。
我们回忆一下三个变量的对齐数:C1与C2的对齐数为1;i的对齐数为4。那么整个结构体的最大对齐数就是4。所以结构体的总大小必须是4的倍数,而下一个4的倍数为12,所以结构体的总大小为12。
最后结构体视图如下:

接着我们还要考虑一下结构体嵌套的问题:
现有如下结构体,求其内存大小:
struct S3
{
double d1;
char c1;
int i;
};
struct S4
{
char c2;
struct S3 s;
double d2;
};
对于S3这个结构体,我们前三条规则就可以解决,现在你可以暂停思考一下,然后与给出的结果比对:

对齐数为:
d = 8,c = 1,i = 4
最大对齐数为:8
总内存大小为:16
接下来我们讨论嵌套了S3的S4:
struct S4
{
char c2;
struct S3 s;
double d2;
};
首先对于C2,对齐数为2,对齐到0处:
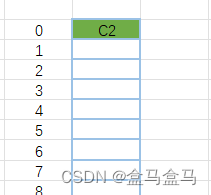
接着就是被嵌套的S3:
规则4前半段:如果嵌套了结构体的情况,嵌套的结构体成员对⻬到⾃⼰的最⼤对⻬数的整数倍处。
S3的最大对齐数为8,所以S3对齐到8的整数倍处,占用16哥字节,现在内存视图如下:

最后是d2,其大小为8,默认对齐数为8,最后对齐数为8。要对齐到8的整数倍处。我们先前嵌套了S3,其内存大小为16,也就是说i变量下面的一块内存24也是属于S3的,因为S3的内存是8的倍数,所以多补了一块内存。但是当这个S3被嵌套到这个S4中,为其补充的总内存就不作数了,此时24并不属于S3。
所以d2会对齐到下一个8的倍数24处,现在内存视图如下:

那么S4的总大小是多少?那就要问S4的最大对齐数是多少?
当结构体发生嵌套,那么最大对齐数的计算法则略有改变,规则4后半段:外层结构体的最⼤对⻬数就是内外层结构体中所有成员的最大对⻬数。
也就是说S4的最大对齐数是所有成员:C2,D,C,i,d2中对齐数的最大值。最后为8,所以S4的大小为8的倍数,当前大小为31,最后总大小就是32。
内存对齐的意义:
内存对齐会浪费这么多空间,为啥还要内存对齐呢?目前大部分资料给出以下两个原因:
平台原因:
不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
性能原因:
数据结构(尤其是栈)应该尽可能地在⾃然边界上对⻬。原因在于,为了访问未对⻬的内存,处理器需要作两次内存访问;⽽对⻬的内存访问仅需要⼀次访问。
比如这样:
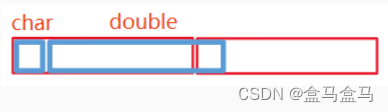
左侧蓝色框是一个char类型数据,右侧蓝色框是一个double数据,如果没有内存对齐,那么其状态如上,一个红色框代表8个字节。
计算机只能一次读取整个红色框的内容,如果没有内存对齐,为了读取这个double,处理器要把两个红色区域都读取,然后再把数据合并。这就会造成额外的计算开销。
内存对齐后:
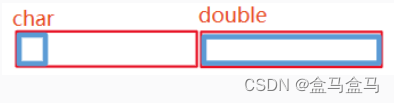
由于double对齐到了8的倍数,此时刚刚好与内存读取的范围重合,只需要直接读取第二个红色区域即可得到数据,因此内存对齐可以提高访问效率。
offsetof:
offsetof是一个宏,其可以检测到一个成员相对与结构体起始位置的偏移量。使用前需要包含头文件<stddef.h>
如下结构体:
struct S1
{
char c1;
int i;
char c2;
};
使用offsetof:
offsetof(S1, c1);//0
offsetof(S1, i);//4
设置对齐数:
我们也可以自己设定默认对齐数,语法为:
#pragma pack(1)
以上代码就把默认对齐数设置为1了。
我们也可以设置后还原:
#pragma pack()
当pack()内什么都不填,默认对齐数就会还原为默认值。
位段
C语言的结构体位段是一种用于控制结构体成员位数的特殊数据类型。它允许程序员指定结构体中每个成员变量所占的bit位数。
结构体位段的定义语法如下:
struct struct_name
{
type member_name : width;
};
其中,struct_name 是结构体的名称,member_name 是结构体中的成员变量名称,type 是成员变量的数据类型,width 是成员变量占用的bit位数。
使用结构体位段可以精确地控制结构体成员的位数,这对于节约内存空间是非常有用的。例如,如果某个成员变量的取值范围只有 0 到 3,那么可以用 2 位二进制数来表示,而不必使用整个字节来存储。
下面是一个使用结构体位段的示例:
#include <stdio.h>
struct Bits
{
unsigned int a : 2;
unsigned int b : 3;
unsigned int c : 7;
};
int main()
{
struct Bits bits;
bits.a = 2;
bits.b = 6;
bits.c = 63;
printf("a: %u\n", bits.a);
printf("b: %u\n", bits.b);
printf("c: %u\n", bits.c);
printf("Size of struct Bits: %zu bytes\n", sizeof(struct Bits));
return 0;
}
在这个示例中,结构体 Bits 中的成员变量 a 占用 2bit 位,b 占用 3bit 位,c 占用 7 bit位。程序输出如下:
a: 2
b: 6
c: 63
Size of struct Bits: 2 bytes
可以看到,成员变量 a、b、c 的取值范围会受到位数限制。另外,结构体 Bits 的大小为 2 字节,这是因为结构体中的成员变量在内存中按照对齐规则进行存储。
需要注意的是,结构体位段的位数必须小于或等于其数据类型的位数=。例如,对于 unsigned int 类型的成员变量,位数不能超过 32(32 位系统)或 64(64 位系统)。
结构体位段的位数可以是常量表达式,也可以是具体的整数值。如果位数是 0,则表示该成员变量不占用任何位,即没有实际的存储空间。
结构体位段在嵌入式系统和底层编程中经常使用,用于对硬件寄存器进行位级操作。但需要注意的是,结构体位段的行为在不同的编译器和体系结构下可能会有差异,可移植性非常差,因此在使用时应谨慎考虑兼容性问题。
联合体
联合体(union)是C语言中的一种特殊的数据类型,它允许在同一内存空间中存储不同类型的数据。联合体中的成员共享同一块内存空间,但在任意时刻只能存储其中的一个成员。它的定义形式如下:
union union_name
{
member1_type member1_name;
member2_type member2_name;
...
};
联合体由关键字union定义,其中,union_name是联合体的名称,memberX_type是成员的类型,memberX_name是成员的名称。联合体的大小与它最大的成员的大小相同。
联合体的使用方式与结构体类似,可以通过.运算符访问成员。不同之处在于联合体中的成员共享同一块内存,因此对某个成员的修改会影响到其他成员。
比如以下联合体:
union Un
{
char c;
int i;
};
其内存视图如下:
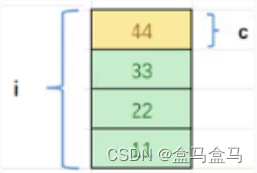
即i和c共用了一块空间。
下面是一个使用联合体的示例:
#include <stdio.h>
union myUnion
{
int i;
float f;
char c;
};
int main() {
union myUnion u;
u.i = 10;
printf("i: %d\n", u.i);
u.f = 3.14;
printf("f: %.2f\n", u.f);
printf("i: %d\n", u.i);
u.c = 'A';
printf("c: %c\n", u.c);
printf("i: %d\n", u.i);
printf("f: %.2f\n", u.f);
return 0;
}
输出结果:
i: 10
f: 3.14
i: 1078523331
c: A
i: 65
f: 2.96
在上面的示例中,我们定义了一个联合体myUnion,它包含一个int类型的成员i、一个float类型的成员f和一个char类型的成员c。在main函数中,我们声明了一个myUnion类型的变量u。
首先,我们将u的i成员赋值为10,并打印出来。然后,我们将u的f成员赋值为3.14,并再次打印出来。可以看到,u的i成员的值发生了变化,这是因为i和f共享同一块内存空间。
接着,我们将u的c成员赋值为字符’A’,并打印出来。同样地,u的i和f成员的值也发生了变化,这是因为c和i、f共享同一块内存空间。
需要注意的是,联合体的成员不要同时使用,即不要在同一时间对不同成员进行操作,除非你知道这样做的结果和意义。因为不同类型的成员可能占用不同数量的字节,同时访问可能会导致数据的错误解释。
总结一下,联合体是一种特殊的数据类型,可以在同一内存空间中存储不同类型的数据。通过共享内存空间,联合体能够节省内存,但需要注意成员的正确访问顺序和数据类型的正确解释。
枚举
在C语言中,枚举(enumeration)是一种用户定义的数据类型,用于定义一组具有离散取值的常量。枚举常量的取值范围是预先定义好的,且仅限于枚举定义中列举的值。
枚举的定义使用关键字enum,其语法如下:
enum 枚举类型名
{
枚举常量1,
枚举常量2,
...
};
其中,枚举类型名是用于声明枚举变量的标识符,可选的枚举常量是该枚举类型的取值。每个枚举常量都由标识符和可选的初始值组成,多个枚举常量之间使用逗号分隔,之前的结构体与联合体则通过分号分隔。
例如,我们可以定义一个表示星期的枚举类型:
enum Weekday
{
Monday = 1,
Tuesday,
Wednesday,
Thursday,
Friday,
Saturday,
Sunday
};
在上述示例中,枚举类型名是Weekday,枚举常量分别是Monday、Tuesday等,且Monday的初始值是1,其后的枚举常量没有指定初始值,它们的初始值会自动递增。
定义了枚举类型后,我们可以声明该类型的变量并赋值。枚举变量的赋值只能使用枚举常量或整型常量,例如:
enum Weekday today = Wednesday;
enum Weekday tomorrow = today + 1;
枚举类型的常用操作包括比较和遍历。可以使用==运算符比较两个枚举变量的值是否相等,也可根据枚举变量的取值进行相应的逻辑判断。
总结起来,C语言中的枚举提供了一种方便的方式,用于定义一组相关的常量,提高代码的可读性和可维护性。在实际应用中,枚举常常用于表示状态、选项或标志等有限的取值。