前言
最近读一些公司的业务代码,发现近几年的java项目工程中都使用了lombok,lombok是一个可以自动生成get,set、toString等模板类方法的工具框架,程序再引入lombok后,添加一个注解便可以不写get\set\toString等方法。
Lombok示例
1、pom.xml中引入依赖
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.2.3</version>
</dependency>
2、一个简单的pojo类
@Getter
@Setter
public class Student {
private String name;
private int age;
}
3、使用
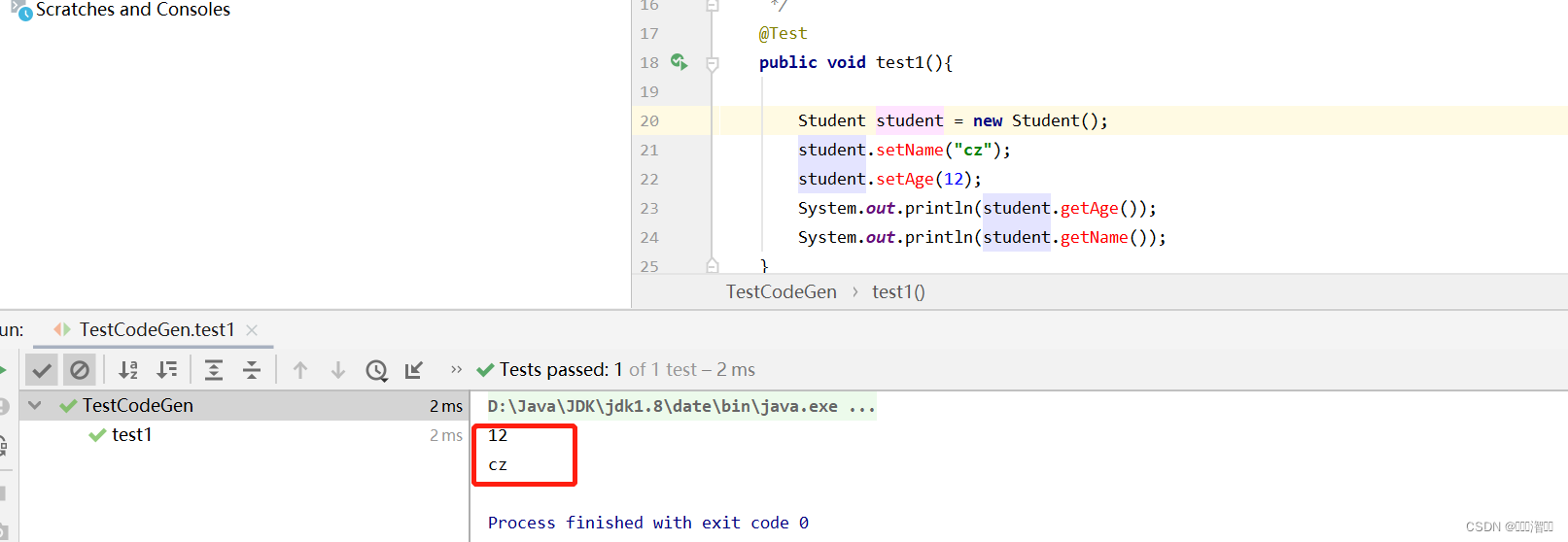
@Test
public void test1(){
Student student = new Student();
student.setName("cz");
student.setAge(12);
System.out.println(student.getAge());
System.out.println(student.getName());
}
效果:
原理分析
通过以上测试案例可以看出,源码中并没有setName()和getName()方法,但是调用后并没有报错,反而运行成功了。那咱们大胆的猜测一下,会不会是在运行或者编译时动态的生成了代码?那么假设是运行时生成了代码,那大概率会使用到ASM或者其他字节码框架。但是这样编译阶段必然会报错,因为java是先编译后运行的。排除了第一种假设之后,我们只能按照第二种猜测来探究一下了。
首先从注解入手。
1、注解的种类
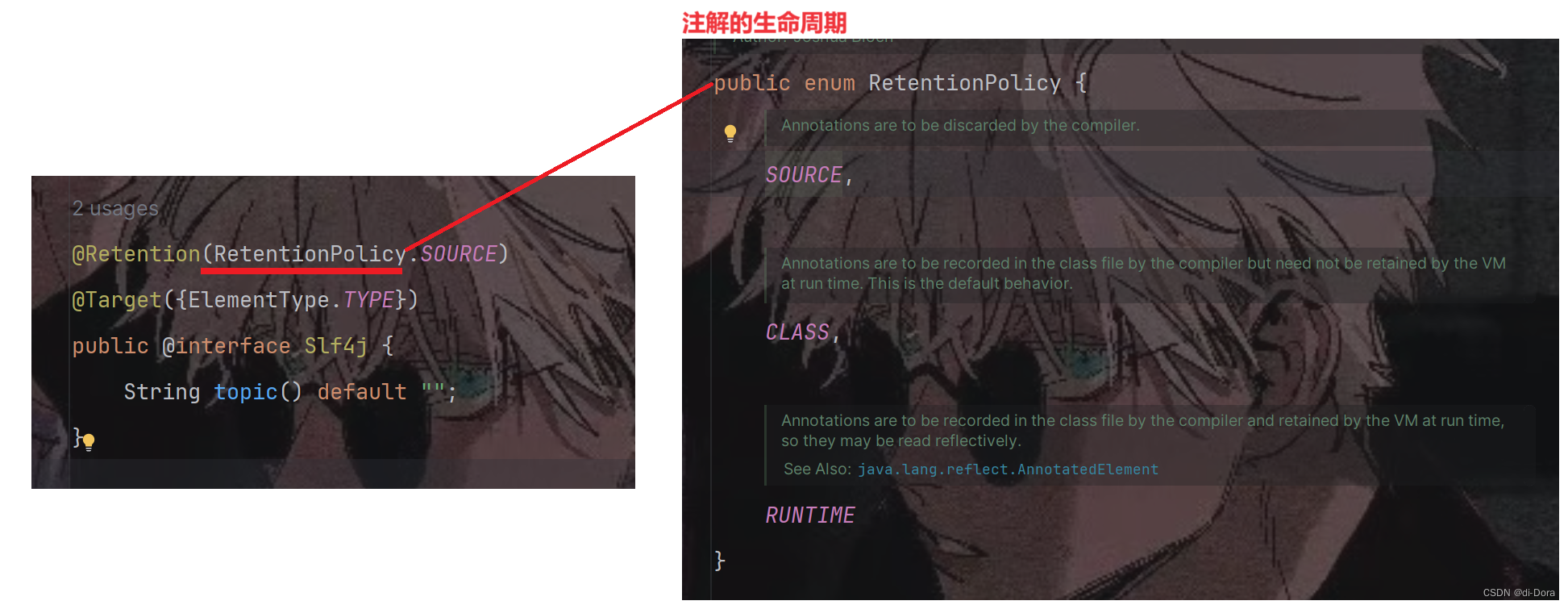
开发过程中经常用到注解,有时也会自定义注解,注解一般有两个重要的参数,一个是注解的作用域(Target)另一个是注解的保留策略(Retention),其中Retention有三个枚举分别如下:
1、SOURCE 表示注解只在源码阶段保留,编译成class后将不保留
2、CLASS 表示编译为class后也保留该注解,但是该注解运行时不能通过calzz.getAnnotation()获取到。
3、RUNTIME 表示class文件中保留该注解,同时也能使用getAnnotation获取到注解信息。
我在开发过程中一般使用的都是RUNTIME。

2、java编译器
《深入理解java虚拟机:JVM高级特性与最佳实践》这本书中描述了编译的几个关键步骤:
1、准备过程:初始化插入式注解处理器
2、解析与符号填充
3、插入式注解处理器的处理过程
4、分析与字节码的生成过程
其中上述的注解其实就是带有Retention(RetentionPolicy.SOURCE)保留策略的注解。Lombok的原理看到这里心里应该有了一个大概的认识了,lombok就是利用插入式注解同时自定义了注解处理器来干扰编译过程同时生成了目标代码。
3、java SPI机制
前文通过《深入理解java虚拟机》这本书了解到了lombok是如何通过注解来生成代码的,但是我还是有个疑问,lombok自定义的注解处理器是如何被程序找到并执行的呢? 答案就是Java的SPI机制。
SPI机制是JDK提供的一个服务发现机制,但是注意这里的服务发现机制并不是在分布式开发中接触到的类似zookeeper的服务注册和发现的中间件,而是一个针对本地interface接口的服务发现机制。下面用一个简单的例子展示一下。
3.1 编写接口
public interface TestSpiService {
public void say();
}
3.2 编写实现类
public class TestSpiServiceImpl implements TestSpiService{
@Override
public void say() {
System.out.println("我说了一句话");
}
}
3.3 注册接口
注意图中的文件路径(META-INF/services)和文件名称(接口的全路径做为文件名称)和配置内容(接口实现类的全路径)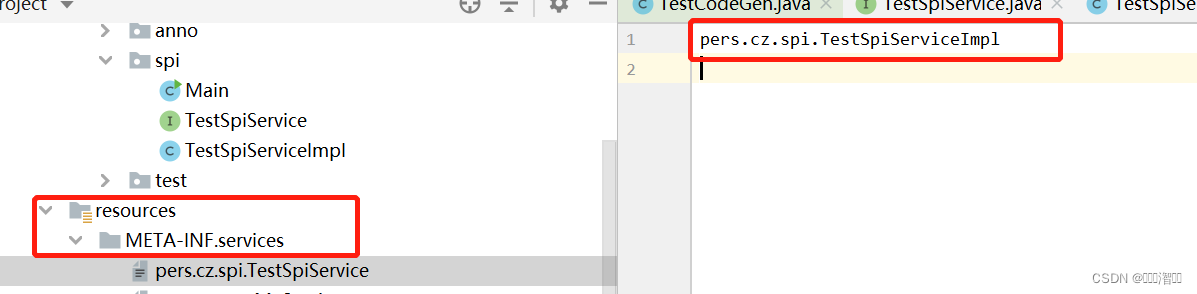
3.4 接口调用
public class Main {
public static void main(String[] args) {
ServiceLoader<TestSpiService> loader = ServiceLoader.load(TestSpiService.class);
for (TestSpiService spiService : loader) {
spiService.say();
}
}
}
Lombok是如何指定自定义注解处理器的?
通过上述案例,我们发现可以通过配置文件的方式指定接口的实现类,同理JDK也是使用了这样的方式为自定义注解处理器提供了条件,再来看一下JDK中注解处理器准备阶段的源码(下图),从源码可以看到JDK也是使用了SPI机制来获取注解处理器。
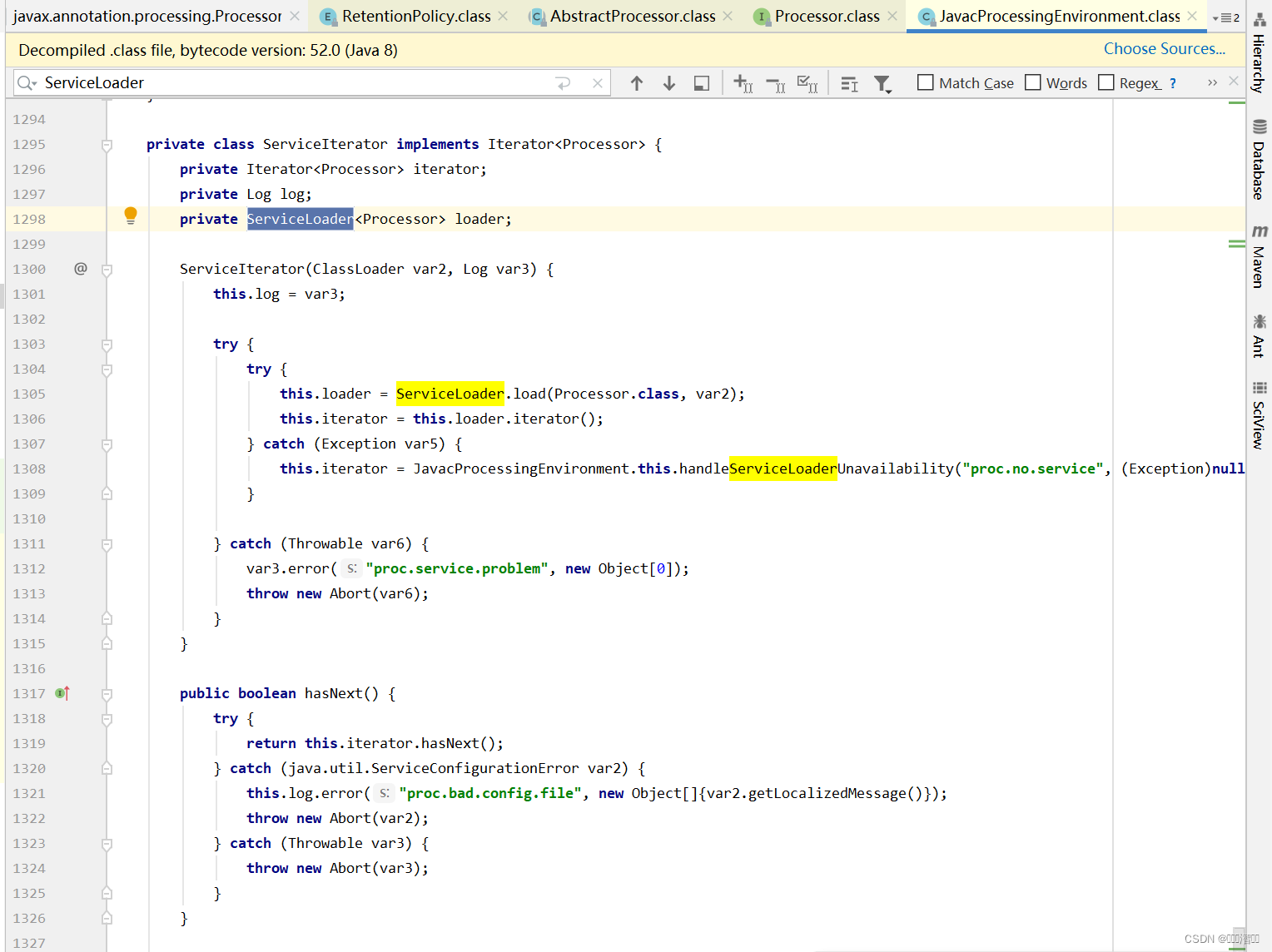
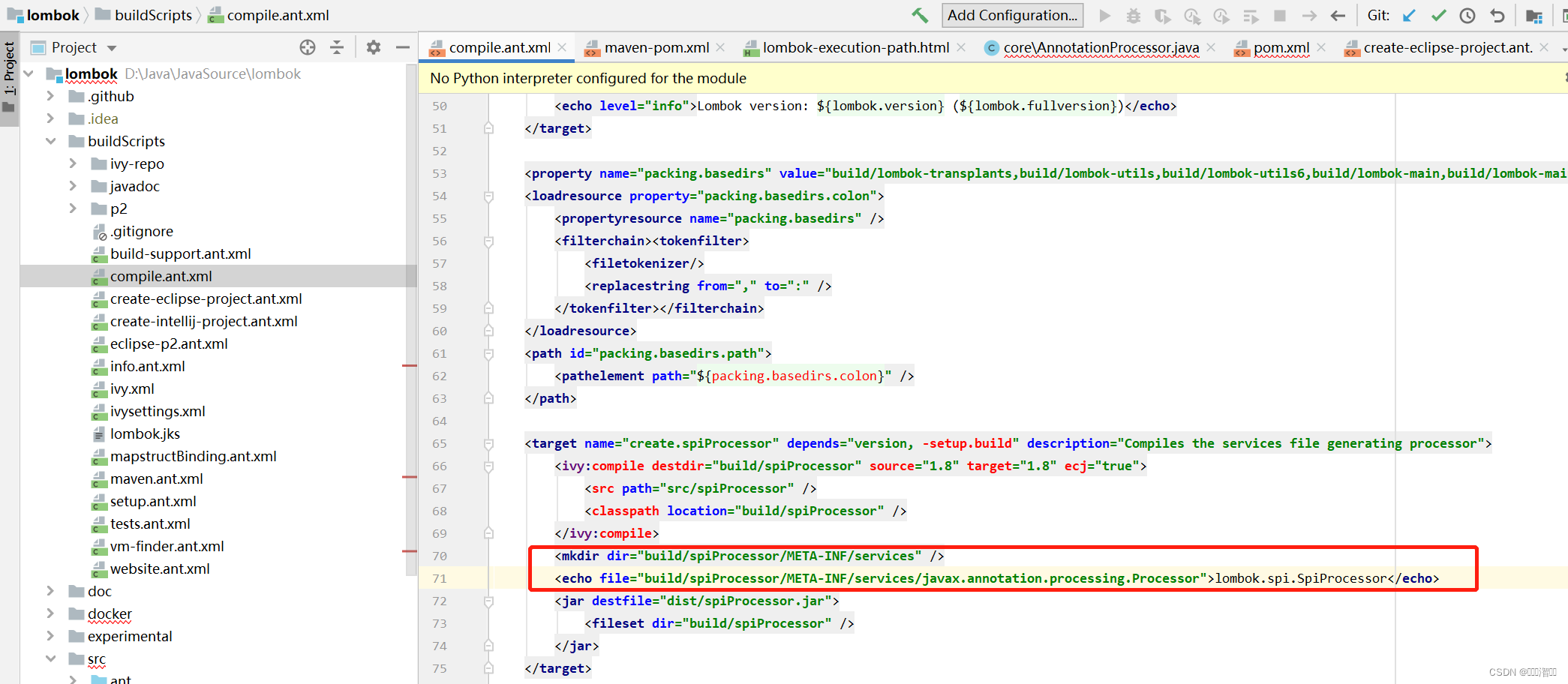
看到这里我猜测lombok源码中也应该有一个META-INF/services文件夹同时在文件夹中存在avax.annotation.processing.Processor文件用来指定@Getter、@Setter等等自定义的注解处理器实现类。可是当我打开源码翻了所有的文件并没有找到META-INF文件夹。但是在一个构建脚本中发现了秘密,原来源码构建打包为jar包时在生成的jar包中才会生成该文件。
知道了自定义注解以及注解处理器的实现后,我又想到了JDK自带的几个注解,比如@Override(方法重写)会不会也是通过SPI来指定处理器处理的?其实JDK自带的几个注解并没有使用SPI机制实现,而是直接处理的。







![[linux][xdp] xdp 入门](https://img-blog.csdnimg.cn/direct/defd49fdfb1e473fa7d37798ec1bd8a1.png)