下面我将以如下代码来解释下XML的写法
<?xml version="1.0" encoding="UTF-8" ?>
<Steam>
<steam id="1">
<zhanghao>admin</zhanghao>
<mima>123</mima>
<num>120</num>
</steam>
<steam id="2">
<zhanghao>admin</zhanghao>
<mima>234</mima>
<num>200</num>
</steam>
</Steam>
以上是我的XML代码
<?xml version="1.0" encoding="UTF-8" ?>是XML文档的声明,一下是查到的XML作用
这串代码在idea工具,打个“<x”就能出现了,后面是编译格式是utf-8(中文)格式
<?xml version="1.0" encoding="UTF-8" ?> 是XML声明,它在XML文档中起到几个重要的作用:
-
指定XML版本:
version="1.0"表示该XML文档遵循XML 1.0规范。XML有多个版本,但这个声明指定了文档使用的是第一个广泛接受和实施的版本,即XML 1.0。 -
指定文档编码:
encoding="UTF-8"定义了文档中字符的编码方式。UTF-8是一种非常普遍且能够表示多种语言的字符编码方式。通过这个声明,解析器知道如何正确地读取和解释文档中的字符。 -
确认文档是XML:这个声明告诉解析器该文档是一个XML文档,而不是其他类型的文档。这对于处理混合内容(例如,当服务器返回的内容可能是HTML、XML或其他类型)的客户端来说尤其重要。
-
标准化:通过包含XML声明,文档遵循了XML标准,这使得文档可以在不同的系统、平台和应用程序之间更容易地交换和解析。
-
避免混淆:对于某些应用程序和解析器,如果没有XML声明,它们可能会混淆XML文档与其他类型的文档,如HTML。
总之,XML声明是XML文档的一个重要组成部分,它确保了文档的正确解析和跨平台的兼容性。在创建XML文档时,通常建议始终包含XML声明
所以说声明一般不要省略
声明完后,开始创建XML代码,这个可以看成是对象的声明,id是第几个的意思,zhanghao是账号的意思,mima是密码的意思,num是数量的意思,steam是对象,都是我随便起的。
然后我们看下test(测试类内容)
package com.bw.test;
import com.bw.domain.Steam;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.junit.Test;
import java.io.InputStream;
import java.util.List;
public class MyTest2 {
@Test
public void test2() throws DocumentException {
InputStream resource = MyTest2.class.getClassLoader().getResourceAsStream("steam.xml");
SAXReader reader = new SAXReader();
Document read = reader.read(resource);
Element element = read.getRootElement();
List<Element> elements = element.elements();
for (Element element1 : elements) {
Steam s=new Steam();
String id = element1.attributeValue("id");
s.setId(new Integer(id));
List<Element> elements1 = element1.elements();
for (Element element2 : elements1) {
String name = element2.getName();
String val = element2.getTextTrim();
if ("zhanghao".equals(name)){
s.setZhanghao(val);
} else if ("mima".equals(name)) {
s.setMima(val);
} else if ("num".equals(name)) {
s.setNum(new Integer(val));
}
}
System.out.println(s);
}
}
}
1. InputStream resource = MyTest2.class.getClassLoader().getResourceAsStream("steam.xml");
是获取文件流;
steam.xml是上方xml文件的文件名
2.SAXReader reader = new SAXReader();是创建解析对象;
3.Document read = reader.read(resource);使用解析对象的方法将文件流变成文档对象
4.Element element = read.getRootElement();获取根标签<Steam></Steam>
5.List<Element> elements = element.elements();获取跟标签的子标签<Steam id="1"></Steam>;
<Steam id="2"></Steam>
以下是代码产生的效果:
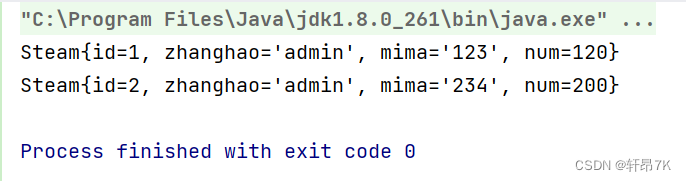
是不是很有意思!







![[面试] InnoDB中如何解决幻读?](https://img-blog.csdnimg.cn/direct/91b856a6e377405f986114313cdff571.png#pic_center)