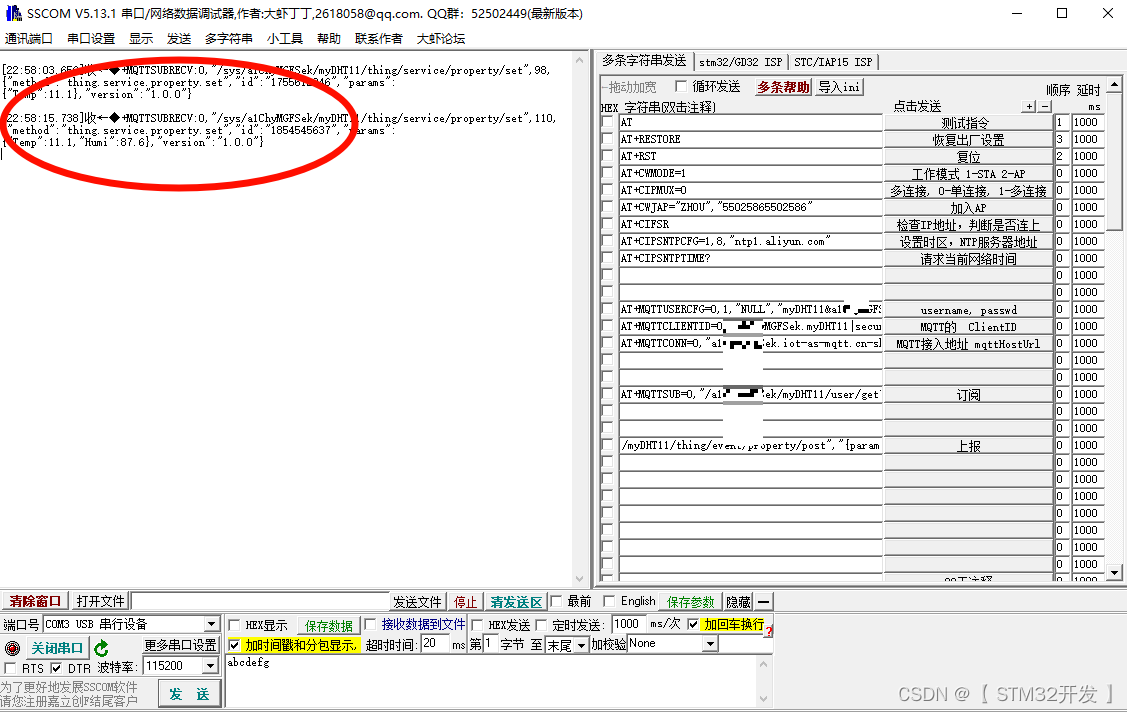
1.终端运行scrapy startproject movie,创建项目
2.接口查找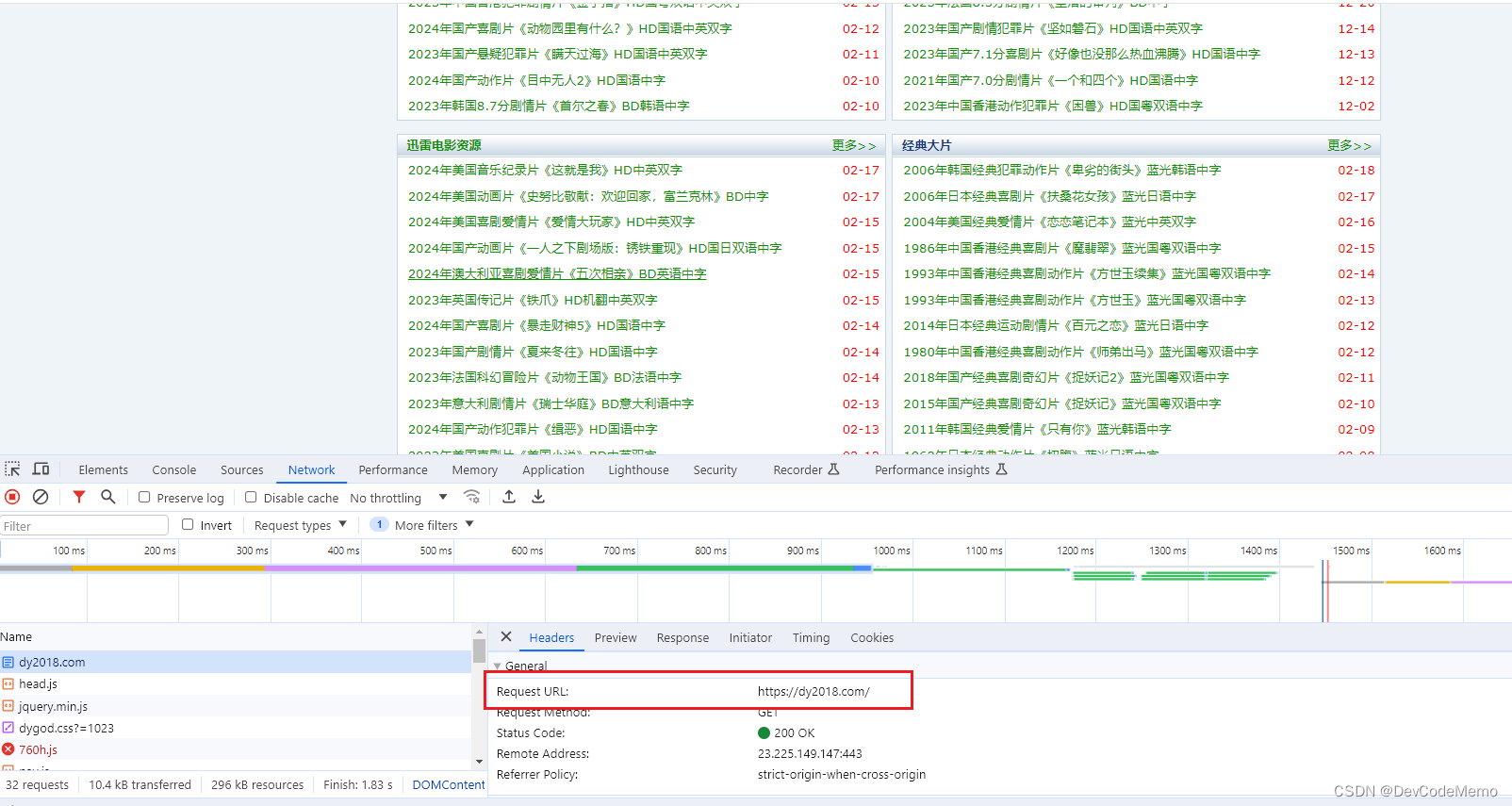
3.终端cd到spiders,cd scrapy_carhome/scrapy_movie/spiders,运行 scrapy genspider mv https://dy2018.com/
4.打开mv,编写代码,爬取电影名和网址

5.用爬取的网址请求,使用meta属性传递name ,callback调用自定义的parse_second
6.导入ScrapyMovieItem,将movie对象传递给管道下载
7.settings开启管道

8.下载爬取的movie对象存储到movie.json中

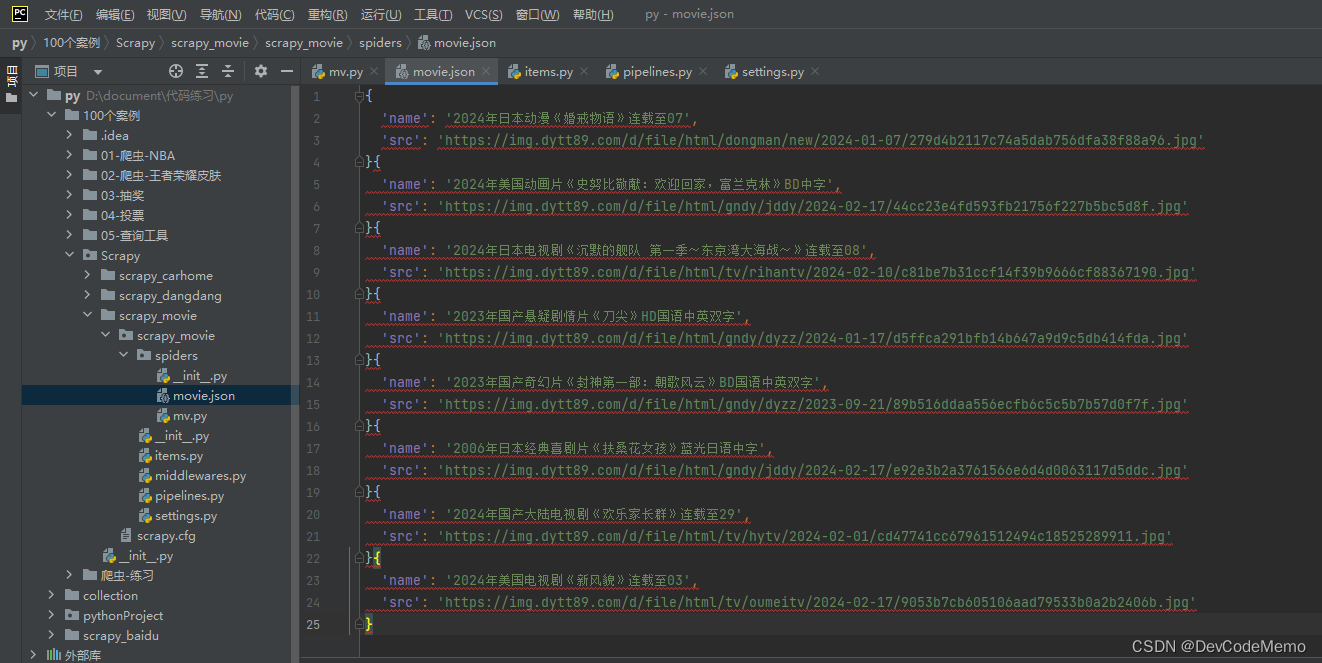
9.爬取的结果
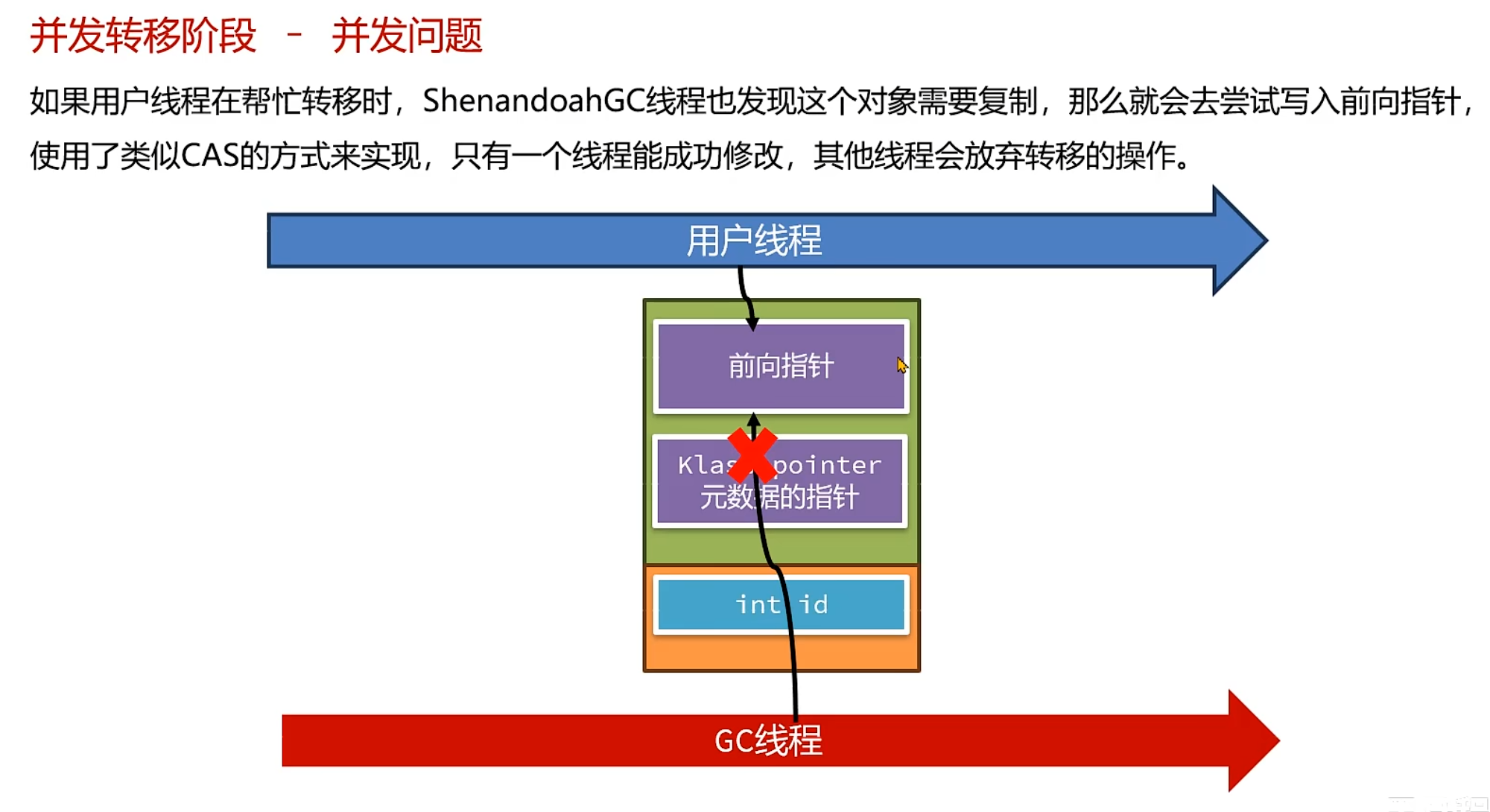







![[计算机网络]---UDP协议](https://img-blog.csdnimg.cn/direct/0ae9c96e2be34572b3f51203ac4bc6bf.png)